

Ijraset Journal For Research in Applied Science and Engineering Technology
Review Paper on a Healthcare Prognosis Using Machine Learning
Authors: Miss. Dhanashri Belsare, Dr. G. R. Bamnote
DOI Link: https://doi.org/10.22214/ijraset.2022.40968
Certificate: View Certificate
Abstract
Diseases tracing plays important role in daily life. Every one cares about their own health. According to some social study, lot of people spends their time on online searching of health related issues. By browsing they get lot of information about the medical concepts and health related issues. Normally, people use Google to search their queries and that search engine respond them with the answer but that answer is in scattered format. User does not gets the exact answer for their queries. From previous work there has been vital work on the information needs of health seekers in terms of questions and then select those that ask for possible disease of their manifested symptoms for further analytic. To resolve such issues an extensive experiment on a real-world dataset labelled by online doctor’s show the significant performance. In this paper, we discussed the techniques for further restructuring of the question and answer has been done in order to get the exact answer of query. A tag mining framework for health seekers will be proposed; aim to identify discriminant features for each specific disease. In this paper we are going to use one of the most famous algorithm of machine learning that is decision tree. It is a type of supervised learning algorithm that is mostly used for classification problems. Surprisingly, it works for both categorical and continuous dependent variables. In this algorithm, we split the population into two or more homogeneous sets. This is done based on most significant attributes/ independent variables to make as distinct groups as possible.
Introduction
I. INTRODUCTION
Recent years have seen a flourishing of community-driven question answering (c QA) Portals, which have emerged as an effective paradigm for disseminating diverse knowledge, seeking precise information, and locating outstanding expert. Around 40% of the questions in the emerging social-oriented question answering forums have at most one manually labelled tag, which is caused by incomprehensive question understanding or informal tagging behaviours. Information extraction from medical text is the basis for other higher-order analytics, such as representation and classification. However, accurately and efficiently inferring diseases is non-trivial, especially for community-based health services due to the incomplete information, correlated medical concepts, and limited high quality training samples. To solve such problems of incomplete information and correlated medical concepts, the proposed dissertation will develop the scheme which studies the user information and health related data. It will infer a learning of the possible diseases given by the questions of health seekers [1]. The prime intention of learning comprises of two key components. The first globally mines the discriminant medical signatures from raw features. The raw features and their signatures serve as input nodes in one layer and hidden nodes in the subsequent layer, respectively. The second learns the inter-relations between these two layers via pre-training. With incremental and alternative repeating of these two components, our scheme builds a sparsely connected deep learning architecture with three hidden layers. In this project we are taking the symptoms as input and our system compares the symptoms and gives proper disease name with its related doctors.
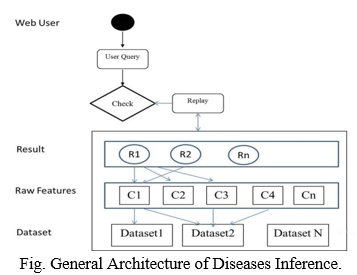
II. LITERATURE SURVEY
Because of the spreading aged community coupled with absence of medical services and health maintenance services in most of the developing countries, the conventional health- care system Difficulties events issue caused by its big operating price and un scalability compare on conventional health main systems, there is a need of more accurate and easy to access system to improve quality of health care services. The following are the some of the parameters we desired to be bettered for the health maintenance services. Develop the utilization of medical advice and care by enabling remote medical services, and promoting the improvements of the health industry. The actual system principally focuses on health maintenance service in a physiological and psychological aspect with the following two undesirable looks etc. The literature [3],[4],[2] following some earlier methods of health services.
David Barbella [1] designed a system the where SVM or the Support vector machines are a valuable and useful tool for making organizations. But their black-box nature means that they lack the natural explanatory cost that many other classifiers possess. In the first, we report the support vectors most touching in the final organization for a particular test location. To come we determine which quality of that test location would demand to be changed in order to be placed on the isolated surface between the two organizations. One or more technique is called “border organization.” in place to describe these explanatory techniques, we also present a free-for-download software tool that enables users to visualize these insights graphically. In other way, many helpful and great popular websites have shown recent success in explaining recommendations placed on nature of other users. Accepting by these plans, we recommend two novel methods for providing vision into local organizations produced by a SVM.
Here introduces two new techniques for explaining back in vector machines on continuous data. Both techniques explain the model on the local level, i.e. for separated test point, as a recommender system might. One involves searching the support vectors that make the major donation to the organization of a particular test point. The next technique is a related to inverse organization technique: the aim is to find a relatively minimal change in order to switch the organization of a test point. Any way instead of minimally switching the classification, we propose detecting the locally minimal change required to action the point to the different surface of the classes. Here these techniques add wide details to the results of an SVM classifier in a format with which users of online recommendation systems are compactly familiar .We have present software tool named SVM- zen that grants users to show these description graphically. A SVM requester can look at a particular test area and determine that the test area was classified in that class due to a specific group of highly weighted support vectors that is, this organization is based on the classification of a point of specific similarity threshold with another class.
F. Wang [2] developed a temporal knowledge representation and learning framework to perform large scale temporal signature mining of longitudinal different event data occurrences .We now a doubly constrained convolutional sparse coding architecture that learns understandable and shift invariant latent understandable thing signatures. Novel stochastic optimization architecture acts large-scale incremental learning of group-specific temporal event signatures. It evaluated the framework on synthetic data and on an electronic strength document dataset and its manipulation.
This architecture enables the descriptions, extraction, and mining of high- order latent event structure and relationships within single and multiple event sequences. This data descriptions point the different event series to a geometric image by encoding events as a structured spatial temporal shape process. It empirically showing that stochastic optimization diagram converges to a fixed point and we have demonstrated that our framework can learn the latent event patterns within a set. Future work will be developed to a thorough clinical assessment for optical interactive knowledge discovery in large electronic fitness record databases for users wish.
N. Lee [3] entrenched the expertise discovery in electronic fitness records (EHRs) as a central aspect for upgraded clinical decision making, prognosis, fitness data management and patient management. Where EHRs show big promise towards better data integration, automated connection, and clinical Progress on workflow, the detailed information they gather over time face challenges not only for medical practitioners, but also for the information inquiry by machines.
The focus of this is to inspire the importance of exploratory analytics that are commensurate with person potentiality and constraints to be meet. Here this architectonics on synthetic data and on EHRs well-balanced with an extensive validation involving many computed latent factor models. The present study is the first to link temporal patterns of health maintenance resource utilization (HRU) against a diabetic disease complications severity index to better figure out the relationships between disease severity and care delivery that will useful for further motivations. While using this realm we present a novel temporal event source representation and learning architectonics that discovers complex latent event patterns, which are easily interpretable by persons.
In Amit pande [4] SSIEEE, used integrated smartphone sensors (accelerometer and barometer sensor), case at low frequency, to accurately evaluate Energy Expenditure. Here also using a barometer sensor, in accession to an accelerometer sensor, greatly increase the efficincy of Energy Expenditure evaluation.
The Energy expenditure (EE) evaluation is an essential parameter in chasing certain activity and closing chronic diseases, such as obesity and diabetes. Eventual correct and timely EE evaluation utilizing defined wearable sensors is a challenging exercise , firstly because of the most existing schemes efforts offline or use experience.
Accurate EE evaluation for following the ambulatory policies (walking, standing, climbing up or down stairs) of a typical smartphone user. Considering bagged regression trees, a machine learning technique, here enhanced a generic regression model for EE evaluation that earning up to 96% alteration with actual Energy Expenditure. Here compare our results in opposition to the state-of-the-art calorie measuring meter equations and customer electronics devices (Fitbit and Nike+ Fuel Band are considered). The current establish EE evaluation algorithm demonstrated superior efficiency compared with currently convenient process.
Lejun Gong [5] planned a system where current disease holding genes could be exposed. Understanding the hand of genetics in diseases is one of the most extensive and greedy works. post genome era. Genetic association investigation and diversions have passed to be a successful tool to enhance the education about genetic risk components to a collection complex diseases. Measuring the serviceable similarity between known disease susceptibility genes that is unknown is to envision new disease susceptibility genes.
There are brod applications of computational methods in discovering gene answerable for person disease. Here ask an approach to prioritize disease susceptibility genes testing LSM/SVD. Measuring the functional analogy between known disease susceptibility genes and unknown genes is top rediact. New disease susceptibility genes. It could discover again current disease assets genes this new method of disease gene prioritization could lead to the discovery of new disease-causing genes.
III . ACKNOWLEDGEMENT
First and foremost, I would like to express my sincere gratitude to my Dr. G.R. Bamnote who has in the literal sense, guided and supervised me. I am indebted with a deep sense of gratitude for the constant inspiration and valuable guidance throughout the work.
Conclusion
This paper focuses on providing the overview about the various diseases inference techniques developed or proposed. Various categories in which diseases inference algorithms can be classified are discussed above. We discussed the techniques like SVM (Support Vector Machine), Sparse deep learning, Classifiers, Querying, Signature mining. Here mostly the sparse deep learning algorithm is used as the data mining technique.
References
[1] David Barbella1, Sami Benzaid2, Janara Christensen3, Bret Jackson4, X. Victor Qin “Understanding Support Vector Machine Classifications via a Recommender System-Like Approach” [2] F. Wang, N. Lee, J. Hu, J. Sun, S. Ebadollah , and A. Laine, “A framework for mining signatures from event sequences and its applications in healthcare data,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013. [3] F. Wang, N. Lee, J. Hu, J. Sun, and S. Ebadollahi, “Towards heterogeneous temporal clinical event pattern discovery: A convolutional approach,” in The ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2012. [4] Amitpande, JindanZhu1, Aveek K. Das1, Yunze Zeng1, Prasanth Mohapatra1, (Fellow, IEEE), and Jay J. Han “Using the Smartphone Sensors for Improving Energy Expenditure Estimation” [5] Lejun Gong?, Ronggen Yang, Qin Yan, and Xiao Sun, “Prioritization of Disease Susceptibility Genes Using LSM/SVD [6] M.Shouman, T. Turner, and R. Stocker, “Using decision tree for diagnosing heart disease patients,” in Proceedings of the Australasian Data Mining Conference, 2011. [7] Y. Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013. [8] Refinement of the Facility-Level Medical Technology Score to Reflect Key Disease Response Capacity and Personnel Availability, Olumurejiwa A. Fatunde (Student Member, IEEE)1, And Timothy W. KOTIN (Student Member, IEEE). [9] Gerberding, M.D., M.P.H.“Centres for Disease control and Prevention” Julie L. [10] AIWAC: Affective Interaction through Wearable Computing and Cloud Technology, Min Chen, Yin Zhang, Yong Li, Mohammad Mehedi Hassan, And Atif Alamri [11] Liqiang Nie, Meng Wang, Luming Zhang, Shuicheng Yan, Member, IEEE, Bo Zhang, Senior Member, IEEE, Tat-Seng Chua, Senior Member, IEEE ”Disease Inference from Health-Related Questions via Sparse Deep Learning”.
Copyright
Copyright © 2022 Miss. Dhanashri Belsare, Dr. G. R. Bamnote. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET40968
Publish Date : 2022-03-24
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online