

Ijraset Journal For Research in Applied Science and Engineering Technology
Heart Disease Prediction Based on Machine Learning
Authors: Aarya Shah, Rutvik Patel
DOI Link: https://doi.org/10.22214/ijraset.2022.46341
Certificate: View Certificate
Abstract
Now-a-days, if you know how to analyze the data and derive conclusions from it, then data becomes extremely valuable. And the main reason for that is the growing importance of using previous data to predict possible future scenarios with higher accuracy. We have used a dataset of around 70000 patients having symptoms related to heart diseases along with their daily activities and medical measurements like heart rate, cholesterol level, blood pressure and used 5 different binary prediction machine learning models for predicting the chances of a person getting heart related diseases in future based on the values entered by any person into our program. If you are a beginner in machine learning and you do not know where to begin or how to use machine learning then this paper will be extremely helpful for you to learn how machine learning works.
Introduction
I. INTRODUCTION
As more and more technology is evolving, data privacy debates are also increasing, but along with that data is extremely beneficial to us, because of the opportunity to predict the future based on historical data and outcomes with an higher accuracy gives us an edge to be prepared for the upcoming scenarios like the one we are dealing with in this paper. Just think how much more you will take care of yourselves if you can predict the chances of you being afflicted by a heart disease in future based on your current habits and medical report? There is an actual possibility that you can even avoid such situation in future if you knew your chances, and that is the actual power of data.
II. STEP BY STEP PROCESS
A. Developing Generic Program (Heading 2)
While implementing different models there was a set pattern of steps which we followed due to which we can make a generic program which anyone can use to predict the chances of getting a heart disease even with a different dataset and with minimal knowledge.
B. Importing the Data
Firstly, we imported the dataset and deleted the incomplete or blank data entries.
C. Data Pre-processing
Then we pre-processed each and every input parameter in which we tried to normalize data distribution of each parameter which basically removes the outliers and helps us improve our prediction accuracy as well.
???????D. Train Test Split
In this we basically separate the data that will be used for training the model and 20 random testing data entries, so that we can check whether our model can predict outcomes with accuracy outside of our training data or not and hence avoid over- fitting of the model on dataset (When testing accuracy and training accuracy are poles apart because the model is too focused on the data that we provided).
???????E. Implementing Different Models
Now we basically implement the machine learning model we want to implement.
???????F. Testing Accuracy of the Model
We will find out both training and testing accuracy (on data which the model has never seen before) of the model.
G. ??????????????Trying for real life patients
We will use the model which gives us the highest training and testing accuracy for getting real life patient data and predicting it
III. WHY WE SELECTED THE PARTICULAR DATASET
The dataset we selected contained data points of over 70000 patients which helped us to make accurate predictions. Along with that it had 11 different parameters which were extremely common, so anyone can use our program. Also, this dataset was genuine because all other datasets available online were showing weird insights like odds of getting heart disease increase with decrease in age, which makes no sense. That’s the reason we used this dataset and you can see the parameters in figure 1.

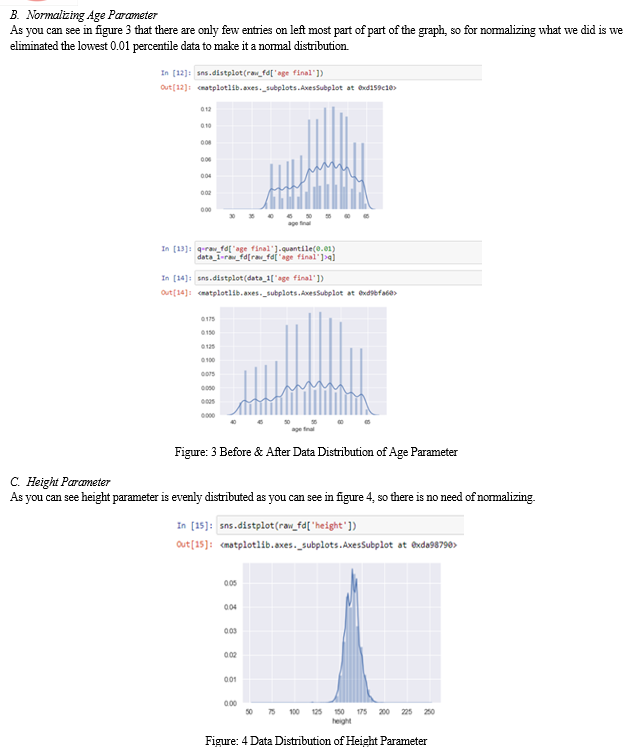
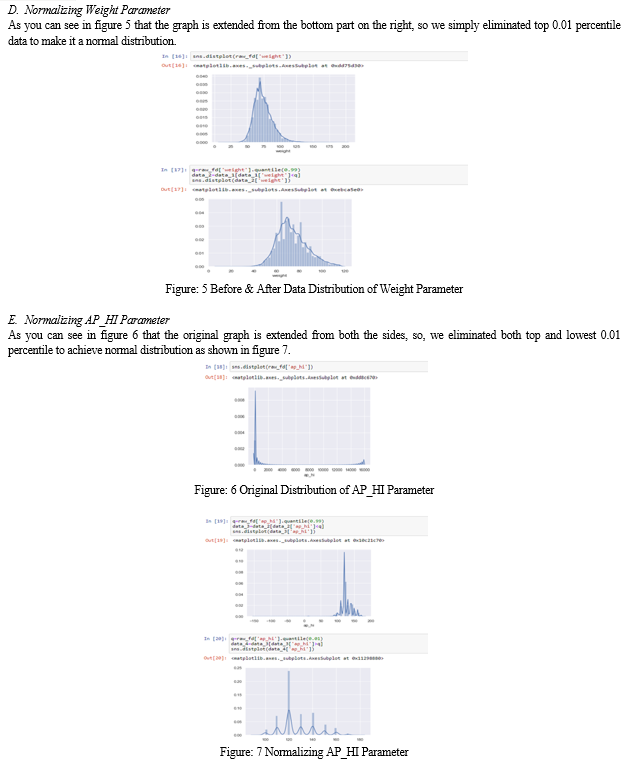





VI. ACKNOWLEDGEMENT
We would like to express gratitude to Prof. Sneh Soni (Assistant Professor, Department of Electronics & Instrumentation Engineering, Institute of Technology, Nirma University, Ahmedabad) for being our guide for this research project and helping us throughout our research.
Conclusion
A. Accuracy Comparison Sr No: Prediction Model Training Accuracy Testing Accuracy 1 Logistic Regression 71.79% 75% 2 Naive Bayesian Classifier 70.62% 66% 3 Decision Classifier Tree 97.08% 62% 4 Support Vector Machine 70.48% 68% 5 Random Forest Classification 96.48% 80% Table: 1 Accuracy Comparison B. Our Insights • As we can see from the table 1, even though over-fitting is slightly evident in Random Forest Classification Model, but it provides the best accuracy in comparison to all other models for this particular dataset. • The highest over-fitting is noticed in Decision Tree Model and the lowest is seen in Logistic Regression, Naïve Bayesian Classifier and Support Vector Machine. • Finally for our scenario of predicting heart disease possibility the most suitable model is Random Forest.
References
[1] Top 10 Binary Classification Algorithm | By Alex Ortner | Published on May 28, 2020 on Medium. [2] https://www.youtube.com/watch?v=Y6RRHw9uN9o [3] https://www.kaggle.com/datasets/sulianova/cardiovascular-disease-dataset [4] The Data Science Course 2022: Complete Data Science Bootcamp | 365 Careers | Udemy [5] Maryam Ajanabi, Mahmoud H. Qutqut and Mohammad Hijjawi, “Machine Learning Classification Techniques for Heart Disease Prediction: A Review” in International Journal of Engineering and Technology, October 2018,
Copyright
Copyright © 2022 Aarya Shah, Rutvik Patel. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET46341
Publish Date : 2022-08-16
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online