

Ijraset Journal For Research in Applied Science and Engineering Technology
Heart Disease Prediction Using Machine Learning
Authors: Karanam Sai Jagadeesh, Raghavendra R
DOI Link: https://doi.org/10.22214/ijraset.2022.40918
Certificate: View Certificate
Abstract
In this modern times, Heart Disease prediction is one of the most critical tasks in the world. In recent times, a lot of people have died due to heart disease. Machine learning plays a very important role in training and testing the huge amount of data in the medical field. Heart disease prediction is a crucial task to create and evaluate the prediction process to avoid heart disease and alert the patient before he/she suffers from disease. This research predicts the chances of Heart Disease and says whether the patient has heart disease or not by implementing different machine learning techniques such as Decision Tree, Logistic Regression. Finally, this study shows a result of heart disease and Results are obtained and comparative experiments have shown that the proposed approach can be utilized to give the prediction to the patient.
Introduction
I. INTRODUCTION
The work proposed in this model focuses mainly on various methods that are employed in heart disease prediction. In the human body the heart is the main role and it regulates the blood to the whole body. Basically if the heart can't regulate proper blood it causes a huge problem to the body. Any misleading things can affect the heart disease and also the chance of getting a heart stroke. In today’s modern era, heart disease is one of the primary reasons for common deaths in this generation due to their luxury and unhealthy lifestyle like huge alcohol, fast food fat food and smoking and stress.(1)
World Health Organization said that in every year lakhs of people are suffering from this heart disease and they are losing their lives A good and healthy measures can safe from the heart disease earlier .The main effective is need to improve to create prediction system and help the poor to save from the lives. Heart diseases are found as the prime source of death in the world due to modern era luxury and unhealthy food. This proposed work makes an attempt to evaluate heart diseases at an early starting stage to avoid huge losses. In the medical field, machine learning algorithms and techniques can be used to predict various heart diseases. The main goal of this model is to provide a tool for doctors to detect heart disease at an early stage.This model will help to prevent and detect the patients earlier from the heart disease. (1)
II. LITERATURE REVIEW
Bo Jin, Chao Che (2018) Introduced a “Predicting the Risk of Heart Disease With EHR” model designed by applying Artificial neural networks. This paper used the electronic health record data from real-world datasets related to patients' heart disease to perform the analysis and predict the heart disease. We implemented a one-hot encryption model that diagnoses events and heart risk failure events victimization, the essential principles of an expanded memory in the neural network model. By analyzing the results, we predicted to reveal the importance of respecting the results of nature in the records (2)
Fahd Saleh has designed and introduced a ML model comparing five types of different algorithms. A Rapid Miner tool was used which resulted in higher accuracy compared to Matlab software and Weka tools for data mining. In this research the results of Decision Tree, Logistic Regression, Random forest, Naive Bayes and SVM classification algorithms were used. Decision tree algorithm comes with the highest accuracy(3)
Anjan Nikhil Repaka, ea tl., proposed a system that uses NB (Naïve Bayesian) techniques for classification of dataset and AES (Advanced Encryption Standard) algorithm for secure data transfer for prediction of disease.(4)
K.Prasanna Lakshmi, Dr. C.R.K.Reddy (2015) created and implemented the model called fast rule based heart disease prediction with associative technique the author used chi-square test to predict the disease with some associative techniques from the model.(5)
M.Satish, et al. created and done with naïve bayes and decision tree models to predict the heart disease model and he named this model called pure classifier association rule. He used a heart disease data warehousing dataset for this model.(6)
Aakash Chauhan (2018) introduced “Heart Disease Prediction using Evolutionary Rule Learning”. This study reduces the manual task that additionally helps in extracting the information (data) directly from the electronic records. To extract this type of rule, we have to apply some frequency of pattern growth with the data mining on the patient's dataset. This will evaluate and try to reduce the cost of services and shown that majority of the rules helps within the best prediction of heart disease (7)
Ashir Javeed (2017) introduced “A Effective Learning System based on Random Search Algorithm To Detect Heart Disease”. This project uses a random search algorithm to detect the disease from factor selection and random forest model for diagnosing cardiovascular and heart stroke disease by using the different algorithms called Random Search Algorithm by using the patient's dataset.This model is principally optimized for using grid search algorithmic programs. (8)
Two type forms of experiments are used in this cardiovascular disease prediction. In the first form, a random forest model is developed and used to predict the model and in the second form the proposed Random Search Algorithm based random forest model is developed. This methodology is efficient and less complex than conventional random forest models. Compared to conventional random forest it produces 3.3% higher accuracy than the random search algorithm. The proposed learning system can help the doctors to improve the quality of heart failure detection(9)
In this Project, a literature survey of review delivers the concept of machine learning techniques has been studied for heart disease from the above listed papers. Using some of the machine learning algorithms it can provide promising results to bring the most effective accuracy in analyzing the prediction model.
The main aim of this project/paper is predicting the heart disease/heart stroke of the patient by using machine learning algorithms like logistic regression to find the prediction in the form of 0 and 1’s. In this project the user can get to know the output from these 14 types of input attributes. Then 14 attributes are going to test and train data for the accurate and efficient results to predict the disease.
III. PROPOSED MODEL
The proposed work predicts heart disease by exploring the above mentioned four classification algorithms and does performance analysis. The objective of this study is to effectively predict if the patient suffers from heart disease. The health professional enters the input values from the patient's health report. The data is fed into a model which predicts the probability of having heart disease. Fig. 1 shows the entire process involved.
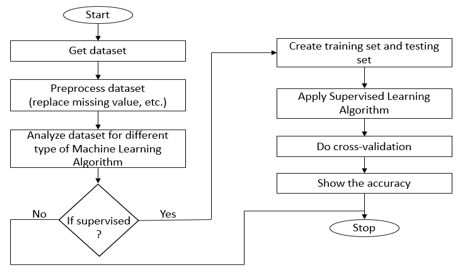
Data Collection and Preprocessing The dataset used was the Heart disease Dataset which is a combination of 4 different databases, but only the UCI Cleveland dataset was used. This database consists of a total of 900 attributes but all published experiments refer to using a subset of only 14 features. Therefore, we have used the UCI Cleveland dataset available in the Kaggle website for our analysis. The complete description of the 14 attributes used in the proposed work is mentioned below(10)


A. Flask Web App
Flask is a micro web framework written in Python. It is classified as a microframework because it does not require particular tools or libraries. It has no database abstraction layer, form validation, or any other components where pre-existing third-party libraries provide common functions.In this we used flask web applications we use pickling file to store the training dataset through the pickle file.“Pickling” is the process whereby a Python object hierarchy is converted into a byte stream, and “unpickling” is the inverse operation, whereby a byte stream (from a binary file or bytes-like object) is converted back into an object hierarchy.(11)
B. Preprocess Dataset
Data Preprocessing is a technique that is used to convert the raw data into a clean data set. In other words, whenever the data is gathered from different sources it is collected in raw format which is not feasible for the analysis.It is also an important step in data mining as we cannot work with raw data. The quality of the data should be checked before applying machine learning or data mining algorithms
C. Supervised Learning
Supervised learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples.
Supervised learning is a process of providing input data as well as correct output data to the machine learning model. The aim of a supervised learning algorithm is to find a mapping function to map the input variable(x) with the output variable(y).
D. Training and Testing
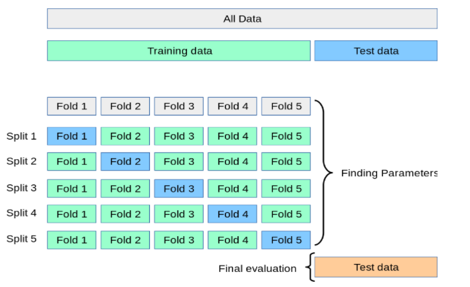
The attributes mentioned in Table 1 are provided as input to the different ML algorithms such as Random Forest, Decision Tree, Logistic Regression classification techniques The input dataset is split into 80% of the training dataset and the remaining 20% into the test dataset. Training dataset is the dataset which is used to train a model. Testing dataset is used to check the performance of the trained model. For each of the algorithms the performance is computed and analyzed based on different metrics used such as accuracy, precision, recall and F-measure scores as described further.
E. Supervised Learning Algorithms
- Random Forest: Random Forest algorithms are used for classification as well as regression. It creates a tree for the data and makes predictions based on that. Random Forest algorithm can be used on large datasets and can produce the same result even when large sets record values are missing. The generated samples from the decision tree can be saved so that it can be used on other data. In random forest there are two stages, firstly create a random forest then make a prediction using a random forest classifier created in the first stage. In this project we can get 75-80 percentage accuracy from the dataset.(12)
- Decision Tree: Decision Tree algorithm is in the form of a flowchart where the inner node represents the dataset attributes and the outer branches are the outcome. Decision Trees are chosen because they are fast, reliable, easy to interpret and very little data preparation is required.In Decision Tree, the prediction of class label originates from the root of the tree. The value of the root attribute is compared to the record's attribute. On the result of comparison, the corresponding branch is followed to that value and jump is made to the next node.
- Logistic Regression: Logistic Regression is a classification algorithm mostly used for binary classification problems. In logistic regression instead of fitting a straight line or hyper plane, the logistic regression algorithm uses the logistic function to squeeze the output of a linear equation between 0 and 1. There are 13 independent variables which makes logistic regression good for classification.
- Scikit-Learn: Learning the parameters of a prediction function and testing it on the same data is a methodological mistake: a model that would just repeat the labels of the samples that it has just seen would have a perfect score but would fail to predict anything useful on yet-unseen data. This situation is called overfitting. To avoid it, it is common practice when performing a (supervised) machine learning experiment to hold out part of the available data as a test set x and y set. Note that the word “experiment” is not intended to denote academic use only, because even in commercial settings machine learning usually starts out experimentally. In scikit-learn a random split into training and test sets can be quickly computed with the train-test-split helper function
- Cross Validation K-fold: Cross-validation is a resampling procedure used to evaluate machine learning models on a limited data sample. The procedure has a single parameter called k that refers to the number of groups that a given data sample is to be split into. As such, the procedure is often called k-fold cross-validation. When a specific value for k is chosen, it may be used in place of k in the reference to the model, such as k=10 becoming 10-fold cross-validation.(13)
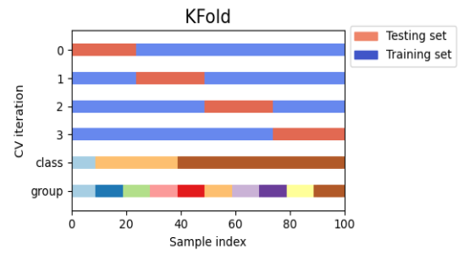
Cross-validation is primarily used in applied machine learning to estimate the skill of a machine learning model on unseen data. That is, to use a limited sample in order to estimate how the model is expected to perform in general when used to make predictions on data not used during the training of the model.Cross-Validation is a statistical method of evaluating and comparing learning algorithms by dividing data into two segments: one used to learn or train a model and the other used to validate the model.
When evaluating different settings (“hyperparameters”) for estimators, such as the C setting that must be manually set for an SVM, there is still a risk of overfitting on the test set because the parameters can be tweaked until the estimator performs optimally. This way, knowledge about the test set can “leak” into the model and evaluation metrics no longer report on generalization performance. To solve this problem, yet another part of the dataset can be held out as a so-called “validation set”: training proceeds on the training set, after which evaluation is done on the validation set, and when the experiment seems to be successful, final evaluation can be done on the test set.(14)
However, by partitioning the available data into three sets, we drastically reduce the number of samples which can be used for learning the model, and the results can depend on a particular random choice for the pair of (train, validation) sets.
A solution to this problem is a procedure called cross-validation (CV for short). A test set should still be held out for final evaluation, but the validation set is no longer needed when doing CV. In the basic approach, called k-fold CV, the training set is split into k
Conclusion
This component will help in predicting the severity of the heart stroke/cardiovascular disease. After the successful model user will input data, the weights will be cross checked with the given inputs. The prediction of this heart disease system will consist of 13 attribute values that will be input to the system. The target value is zero or one The predicted will be generated in the form of a ‘yes’ or ‘no’ format considering all the risk factors whether they lie in the criteria as per the model is trained
References
[1] Goel R Heart Disease Prediction Using Various Algorithms of Machine Learning, http://dx.doi.org/10.2139/ssrn.3884968 [2] Jin B, Che C, Liu Z, et al (2018), Predicting the Risk of Heart Failure With EHR Sequential Data Modeling, http://dx.doi.org/10.1109/access.2017.2789324 [3] Jensen K, Martinsen ACT, Tingberg A, et al (2014), Comparing five different iterative reconstruction algorithms for computed tomography in an ROC study, http://dx.doi.org/10.1007/s00330-014-3333-4 [4] Repaka AN, Ravikanti SD, and Franklin RG (2019), Design And Implementing Heart Disease Prediction Using Naives Bayesian, http://dx.doi.org/10.1109/icoei.2019.8862604 [5] Lakshmi KP, Prasanna Lakshmi K, and Reddy CRK (2015), Fast rule-based heart disease prediction using associative classification mining, http://dx.doi.org/10.1109/ic4.2015.7375725 [6] Al-Bayaty BFZ, Zopon Al-Bayaty BF, Bharati Vidyapeeth University, et al (2016), Comparative Analysis between Naïve Bayes Algorithm and Decision Tree to Solve WSD Using Empirical Approach, http://dx.doi.org/10.7763/lnse.2016.v4.228 [7] Chauhan A, Jain A, Sharma P, et al (2018), Heart Disease Prediction using Evolutionary Rule Learning, http://dx.doi.org/10.1109/ciact.2018.8480271 [8] Peyls N Learning curve for insertion of a peripherally introduced central catheter using echo guidance on a phantom model, http://dx.doi.org/10.26226/morressier.59dd3a6ad462b8029238a5db [9] Strom S (2019), Photophysiological responses of two dinoflagellate species used in natural high light exposure experiments (Protist Signaling project), http://dx.doi.org/10.1575/1912/bco-dmo.723266.1 [10] Williams G (2011) Data Mining with Rattle and R: The Art of Excavating Data for Knowledge Discovery, Springer Science & Business Media [11] Irsyad R Penggunaan Python Web Framework Flask Untuk Pemula. [12] Institute of Medicine, Board on Global Health, and Committee on Preventing the Global Epidemic of Cardiovascular Disease: Meeting the Challenges in Developing Countries (2010) Promoting Cardiovascular Health in the Developing World: A Critical Challenge to Achieve Global Health, National Academies Press [13] Vabalas A, Gowen E, Poliakoff E, et al (2019), Machine learning algorithm validation with a limited sample size. [14] Duarte E and Wainer J (2017), Empirical comparison of cross-validation and internal metrics for tuning SVM hyperparameters.
Copyright
Copyright © 2022 Karanam Sai Jagadeesh, Raghavendra R. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET40918
Publish Date : 2022-03-22
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online