

Ijraset Journal For Research in Applied Science and Engineering Technology
Heart Disease Prediction Using Machine Learning Technique
Authors: Dr. Hareesh K, Ganesh N, Chetan Kumar V P, Pavan Naik, Gowtham M
DOI Link: https://doi.org/10.22214/ijraset.2022.45923
Certificate: View Certificate
Abstract
Heart sickness has been a significant dangerous issue in a person. Because of a few reasons like dietary patterns, absence of activity, becoming overweight and smoking, and unfortunate way of life propensities cause heart sicknesses. This propels us to find out about the put factors in our life in extreme danger in regards to the reason for coronary illness. The proposed strategy recommends the degrees of chance elements agreeing with the patient\'s information, with the goal that one can deal with their wellbeing appropriately to forestall the coronary illness. In this examination work, the proposed procedure is to isolate coronary illness patients in light of their gamble factors. As a matter of some importance applying the half assurance is to diminish the records of knowledge and to line up the model speedier. The 5 classifiers area unit strategic relapse, support vector machine, K-closest neighbor, selection tree, and irregular backwoods area unit applied. beyond applying the classifiers, a projected model can disengage the coronary illness patients considering their bet factors in line with the Age of the patients. this may assist the consultants with researching the card-playing parts of the patients.
Introduction
I. INTRODUCTION
Heart jumble is presently an intense disease. Various causes add to coronary illness, that as elevated cholesterol, high BP, harm to blood supply routes, on the off chance that a heart that doesn't work however much it could that prompts coronary illness. Heart harm may likewise cause by an undesirable eating routine, like smoking, drinking a lot of liquor, or eating a lot of sugar, any of which might prompt hypertension. There are different types of coronary illness, like coronary corridor infection, angina, valve sickness, and so on.
The fundamental test in the present way of life in regards to medical care is to get exact medical services and administration. AI and man-made consciousness articulation a principal part in medical services. In light of the upgrades in the field of medical care framework will have on such countless people. What's more, their capacity to save a great many lives and assets, medical services has turned into a center industry for a venture.
In our examination, first, remove the information and undertake the element determination to that dataset. While making a prescient model, including choice is the technique that lessens the number of information factors. We will want to get six distinct elements. For the resultant component determination by utilizing the five managed methods.
II. EXISTING SYSTEM
The data nuances are gained from the patient. Then from the client inputs, it is analyzed to use ML procedures coronary sickness. The data on coronary sickness patients assembled from the UCI research focus is used to track down plans with NN, DT, LR, and Naive Bayes. The results are differentiated for execution and accuracy and these estimations. The proposed combination methodology returns 87% of the Results.
A. Disadvantage
- Expectation of cardiovascular disease results isn't precise.
- Information mining methods don't assist with giving powerful direction.
- Can't deal with tremendous datasets for patient records.
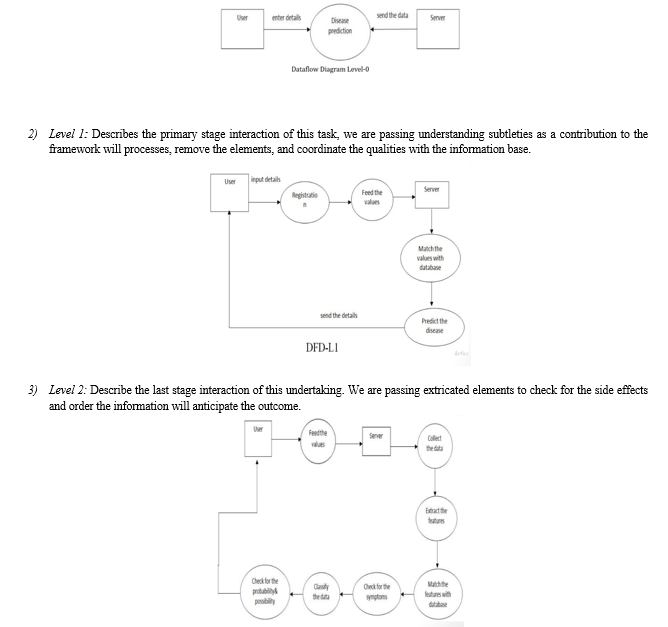
III. PROPOSED METHODOLOGY
Execution of python and pandas exercises to perform coronary sickness plan for the data. It gives an easy to-use visual depiction of the dataset.
A. Advantage
- Increased exactness for compelling coronary illness determination.
- Handles the most unpleasant measure of information utilizing SVM, KNN calculation, and component determination.
- Reduce the time intricacy of specialists.
- Cost-powerful for patients.
IV. SYSTEM ARCHITECTURE
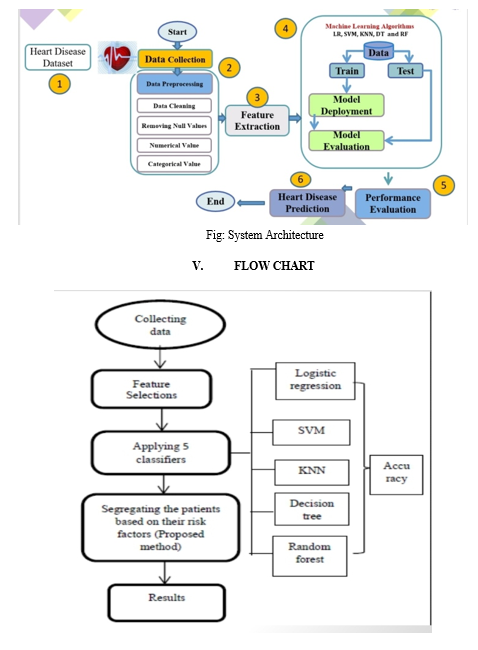
VI. DATAFLOW DIAGRAM
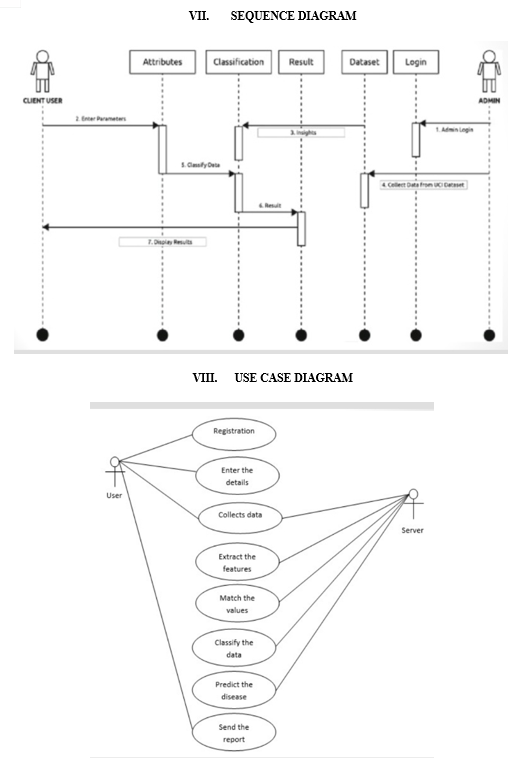
A data flow chart (DFD) could be a graphical depiction of the "stream" of knowledge through associate degree information structure, showing its cycle viewpoints demonstrating its cycle perspectives. A DFD is much of the time utilized as a primer move toward outlining the framework without carefully describing the situation, which can be utilized for the representation of information handling.
1) Level 0: Describes the general course of this undertaking. We are passing quiet subtleties as information; the framework will proficiently process and foresee the outcome utilizing AI calculations
IX. MODULES
A. Module 1: Data Collection
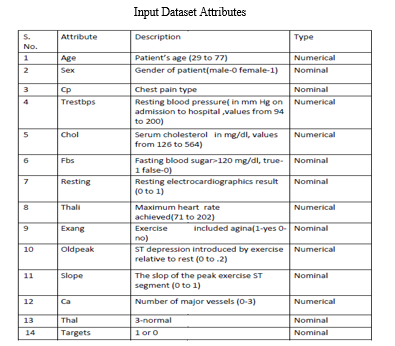
At first, we gather a dataset for our coronary illness expectation framework. After the range of the dataset, we have a tendency to split the knowledge set into designing knowledge and testing data. The readiness knowledge set is employed for assumption model learning and testing data is employed for evaluating the belief model. For this trip, seventieth of preparing knowledge is employed and half-hour of information is employed for testing. The dataset used for this trip is cardiovascular disease UCI. The dataset contains seventy six properties; out of that, fourteen credits area unit utilised for the framework.
B. Module 2: Data Preprocessing
Information pre-handling is a significant stage for the production of an AI model. At first, information may not be great or in the normal course of action for the model which can cause deceiving results. In the pre-treatment of data, we change data into our normal design. Overseeing commotions is used, copies, and missing upsides of the dataset. Information pre-handling has the exercises like bringing in datasets, parting datasets, quality scaling, and so on. Pre-handling of information is expected for working on the exactness of the model.
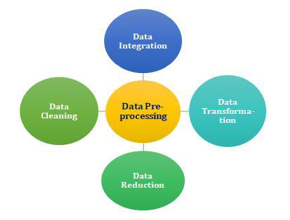
C. Module 3: Feature Extraction
Unessential elements frequently influence the model's preparation cycle, and some clamor includes even making the model digress from the right track. Highlight determination picks a subset of factors that can successfully depict the information and guarantee great forecast results.
Some component choice strategies are applied to lessen the impact of commotion or immaterial factors generally summed up into channel techniques, covering techniques, and inserted strategies.
D. Module 4: Machine Learning Model Deployment
Various Supervised Machine Learning Algorithms are used for classifications for example:
- Logistic Regression
- Support Vector Machines
- K-Nearest Neighbor
- Decision Tree
- Random Forest
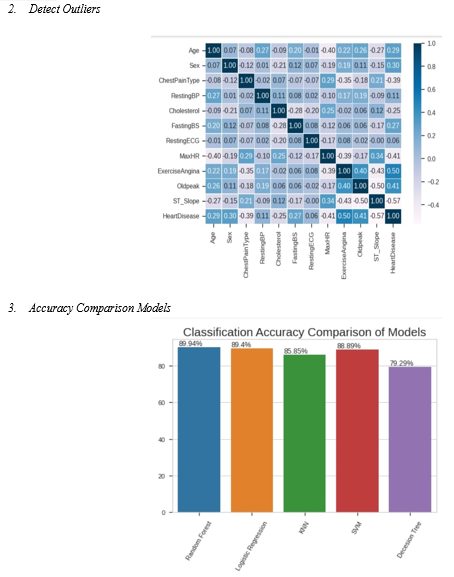
E. Module 5: Performance Evaluation of Models
Different traits of the patient like orientation, chest torment type, fasting pulse, serum cholesterol, and so on are considered for this task. The precision for individual calculations needs to gauge and whichever calculation gives the best exactness is considered for the coronary illness expectation. For assessing the analysis, different assessment measurements like exactness, disarray framework, accuracy, review, and f1-score are thought of.
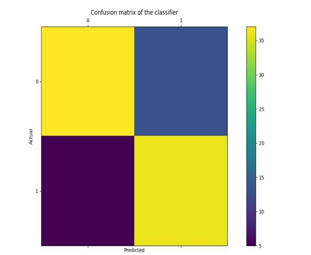
Where
TP: True positive
FP: False Positive
FN: False Negative
TN: True Negative
F. Module 6: Predictions
Forecast of Disease
Different AI calculations are utilized for grouping. Near examination is performed among calculations and the calculation that gives the most noteworthy exactness is utilized for coronary illness expectation.
- Exploratory Data Analysis (EDA)
a. Age vs. Heart Disease
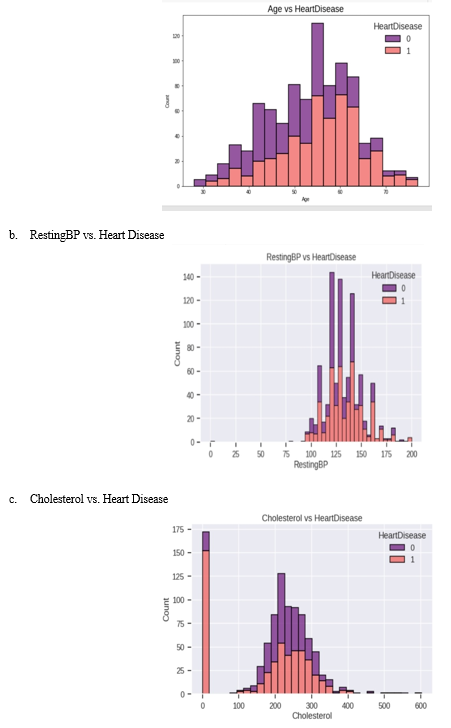
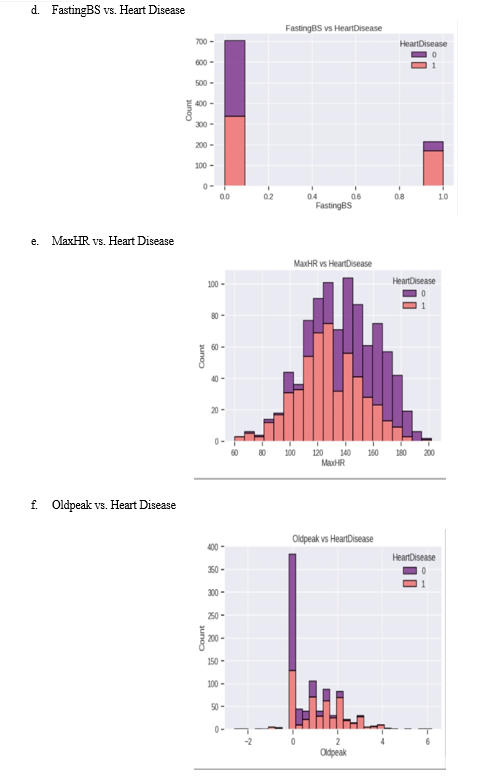
Conclusion
By utilizing SVM and KNN classifiers the precision is estimated and analyzed. The degrees of chance variables assist the specialists with isolating the patients and treating them. A few benefits of these strategies are it assists with expanding the exactness. It can deal with both downright and persistent information. This mechanizes the most common way of filling in missing qualities in information.
References
[1] S Hameetha begum, S N Nisharani (24- 26 AUG 2021) | Added to IEEE Xplore on 17 SEP 2021 [2] Machine Learning Basics: Support Vector Machine | K-Nearest Neighbor | by Gurucharan M K | Towards Data Science [3] M D Amzad Hossein, Taliya Tazin | Hindawi, Mathematical problem of Engineering(10 DEC 2021) | Article ID:1792201 [4] Pooja Gupta, Pritesh Jain, Upendra Singh(June 2018) | International Journal of Scientific Development and Research (IJSDR1806036) | ISSN:24552631 [5] Amayo Mordecai(29 APR 2020) | Towards Data Science.
Copyright
Copyright © 2022 Dr. Hareesh K, Ganesh N, Chetan Kumar V P, Pavan Naik, Gowtham M. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET45923
Publish Date : 2022-07-23
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online