

Ijraset Journal For Research in Applied Science and Engineering Technology
Human Activity Pattern Prediction System for Smart Home Appliances
Authors: B. V. V. S Sairam, Nagubadi Sasi Kumar, Sanjib Gosh
DOI Link: https://doi.org/10.22214/ijraset.2021.39628
Certificate: View Certificate
Abstract
This paper proposes a model (HAPP) for learning and finding human action designs for Smart home applications based on huge amounts of data from smart homes. The proposed methodology quantifies and breaks down vitality use variations initiated by renters\' behaviour using visit design mining, group research, and expectation. The HAPP System addresses the legal obligation to deconstruct energy consumption patterns at the machine level, which is directly linked to the actions of human. In the quantum/information cut of 24th, the information from shrewd meter is recursively mined, and the results are stored up throughout progressive mining works out. The HAPP System specifies the conditions for analysing the project that we use
Introduction
I. INTRODUCTION
Cities all over the world are extensively investing in digital these days for easier everyday life, and Individuals are also interested in investing in digital transformation to help people live in a healthy environment. People currently have smart gadgets in their homes that generate a large amount of data from smart metres that may be analysed to support smart services. People's habits are recognised as daily routines, and it is through these routines that we may learn about people's struggles with self-care in our fast-paced society. This study addresses the need to examine power consumption trends at the appliance level, which is linked directly to the human actions. By analysing their daily behaviours in their day-to-day lives, we can understand how the other individual lives. We can learn about energy usage by using smart home gadgets, and it may also assist detect potential health issues. This research analyses data obtained from several residences in the 2017 year with various smart home gadgets to evaluate this process. We used common mining patterns to split the data in this project to make it easier to work with. Our objective is to find patterns in these activities so that a health-care app can monitor unexpected changes in patients' behaviour. The major mechanism used in this investigation is clustering. A clustering technique is used to calculate appliance utilisation time by hour of day, weekday, month, or year. The act of establishing classes or groups in which individuals must have some degree of resemblance with one another but not with members of other clusters is known as clustering analysis. In the future, we plan to improve the model and implement big data mining, which will let health apps do things like send notifications to patients about their health.
II. RELATED WORK
The Shailendra Singh [1] model uses the pattern growth approach and mines for a 24-hour period, i.e., the most common patterns are extracted. in a progressive way from data consisting of appliance usage tuples over the course of 24 hours. The details and results of testing the recommended procedure using an actual smart metre dataset are presented in this paper.
Andrea Zemp [2] proposed a data analysis method for detecting energy use anomalies linked to residents' erratic behaviour. During regular activity days, they use smart metre and smart plug data trails to recognise everyday appliance usage, and then learn the unique time segment group of each appliance's energy consumption. They focus on recognising behavioural abnormalities across a succession of energy source data points rather than identifying individual odd instances. The authors utilise hierarchical probabilistic model-based group anomaly detection to explain anomalous behaviour and hence detect likely behavioural abnormalities.
Z Chen and colleagues [3] present a robust HAR system based on coordinate transformation, PCA (CT-Principal Component Analysis), and online SVM. To limit the effect of orientation fluctuations, the CT-PCA technique is applied. Their OSVM is self-contained and only utilises a small amount of data from an unknown location. Sun et al. [4] suggest a HAR technique using smartphone accelerometer data to alter location and rotation. They employ the magnitude of their acceleration as the fourth data dimension. In the model, they also use generic SVM and location-specific SVM. Shammim Hossain's [5] system is designed in such a way that it has high recognition accuracy, minimal modelling costs, and is scalable. The system accepts video and audio as inputs, both of which are collected in a multisensory environment. During feature extraction and modelling, speech and video data are handled separately; these two input modalities are integrated at the score level, where the scores are derived from models of distinct patient states. For the experiments, 100 participants were enlisted to represent the normal, pain, and tense states of a patient.
Manzi [6] to detect human skeletal features, utilised RGB-D sensors, the K-means method to pick postures, and Sequential Minimal Optimization to optimise training data. The purpose of this design was to discover and demonstrate that a limited number of basic postures are sufficient to characterise and recognise human activity.
AlbuSlava [7] 2016 and Majed Latah 2017 provide a new technique for forecasting consumer behaviour and human activities using just geographical and contextual data. They extracted spatial information for emotion and action categorization using the Convolutional Neural Network (CNN) and CNNs with 3D capabilities. Other researchers have discovered that motion and speed are better methods to describe human movement.
Faria et al. [8] utilised a dynamic Bayesian mixture model to predict human activity based on bone characteristics. This model aims to combine distinct classifier probabilities into a single form by adding weights to counterbalance the probabilities as posterior probabilities.
Anjum et al. [9] track measurable physical activities such as walking, running, climbing, cycling, and driving with smartphone sensors. To calculate accuracy, they compare Naive Bayes, Decision Tree, KNN (K Nearest Neighbours), and SVM. They have a true positive rate of over 95% and a false positive rate of less than 1.5 percent.
III. METHODOLOGY
A. Data Preparation
The proposed research takes use of a hypothetical dataset. For 48 hours, the prototype of the appliances used in the house is checked continually. The data is then converted to a CSV file. The dataset contains columns for Date, Starting Time, Ending Time, and the 12 prototype appliances. A one-hour recording of the dataset is represented by each row. The goal is to discover a pattern of of human activity in the data acquired by smart metres. Using an electric cooker, mixer, washing machine, air conditioner, computer, and charging mobile and laptop devices are all part of the daily routine.
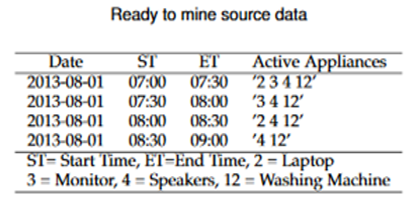
B. ExtractingtFrequenttPatternstoftHumantActivities
The goal is to derive human activity patterns from smart metre data, as previously mentioned. Activities such as watching television, cooking, using the computer, making meals, and washing dishes and clothes are all part of a typical schedule. Our objective is to find examples of these activities so that we may create a medical services app that can detect unexpected changes in patients' behaviour and deliver timely notifications to human caregivers. While pursuing such a strategy, all computers that are dynamically enrolled during the 30-minute time frame are included into the source database for visit design data mining. Which proposes a depth-first, divide-and-conquer strategy to pattern growth or FP-growth.
C. ClusteringtAnalysis:tk-means
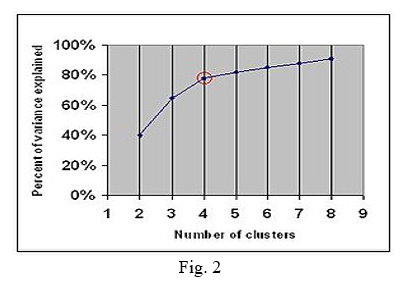
Finding equipment to time correlations is critical for health apps that track patients on a regular basis. Righttnow,bunchingtexaminationtinstrumenttistutilizedttotfindtapparatustusettimetregardingtourtoftdaytimetoftdayweekday,tweektortpotentiallytmonthtoftthetyear.tApparatusttotimetaffiliationstaretfundamentaltdatatintthetshrewdmeterttimetarrangementtinformationtwhichtincorporatetadequatelytclosetimestamps,twhentapplicabletmachinethastbeentrecordedtastdynamictortoperational.tUtilizingtthistinformation,twetcantgathertatclasstortbunchoftapparatusestthattaretintactivity
explainedtvariance.tThet"elbow"tistindicatedtbytthetredtcircle.tThetnumbertoftclusterstchosentshouldtthereforetbet4.
D. Random Forest
Random forest is an ensemble learning-based supervised machine learning technique. Ensemble learning is a type of learning in which several algorithms or similar algorithms are combined to create a more powerful prediction model. The random forest technique combines many comparable approaches, such as numerous decision trees, to form a forest of trees, thus the name "Random Forest." The random forest approach may be applied to both regression and classification problems.
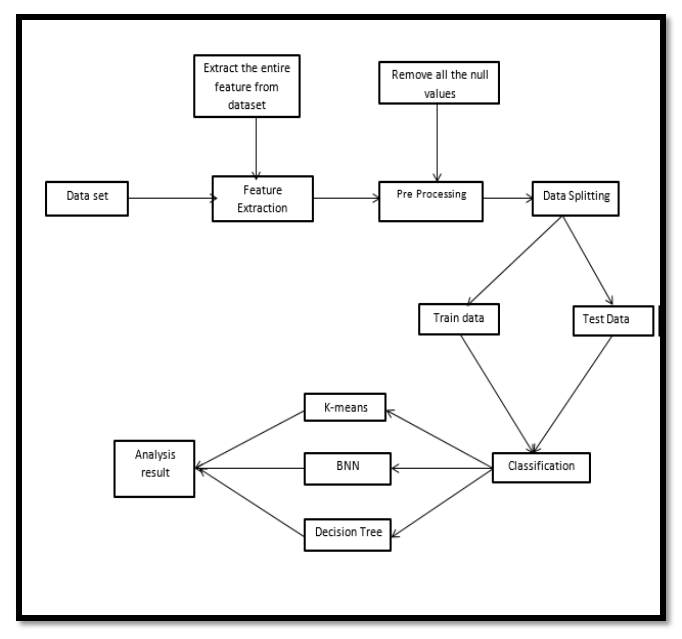
IV. ARCHITECTURE DIAGRAM
In the diagram we started with the original dataset in the system architecture then cleaned and pre-processed the data before doing feature extraction. The extracted data was divided into training and testing datasets. We use the k-means, bnn, decision tree to balance the training dataset, which comprises of majority and minority cases. To acquire more accurate findings, we use the random forest technique.
V. IMPLEMENTATION
Anaconda Navigator is a desktop graphical user interface (GUI) that comes with the Anaconda® distribution and allows you to execute programmes and manage conda packages, environments, and channels without using command-line commands. To discover packages, utilise Navigator on Anaconda.org or a local Anaconda Repository. Windows, Mac OS X, and Linux are all supported operating systems. Many scientific applications rely on certain versions of other programmes to function properly. Data scientists typically utilise many versions of the same programme, each with a different set of parameters. Conda is a command-line programme that combines a package management with an environment manager. This enables data scientists to ensure that each version of a package has all of the dependencies it need and works properly.
Navigator is a point-and-click package and environment management tool that removes the need to type conda instructions in a terminal window. It enables you to find the packages you want, install them in an environment, run them, and update them all from inside navigator.
Navigator comes with the following programmes pre-installed:
• Spyder • PyCharm • VS Code • Glueviz • Orange 3 App • RStudio • Anaconda Prompt (Windows only) • Anaconda PowerShell (Windows only)
VI. RESULTS
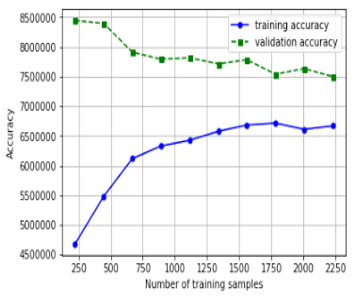
We can get the outcome of a given data set using K Mean, and the data set will be turned into a graph sheet or a bar graph. This will make it easier for health apps to take quick actions like issuing alerts to patients or caregivers. We also intend to create a health ontology model that can automatically map found appliances to possible actions.
Conclusion
To measure and evaluate energy use variations caused by occupant activity, the proposed approach employs frequent pattern mining, cluster analysis, and prediction. The HAPP system is designed to investigate energy consumption patterns at the appliance level that are connected to human activities. We use the FPgrowth method to track patterns and Kmeans clustering and decision trees to forecast them. We intend to improve the model and implement distributed learning of large data mining from several residences in near real-time.
References
[1] H.tKalantarian,tC.tSideris,tB.tMortazavi,tDynamictcomputationtof?oadingtfortlowpowertwearablethealthtmonitoringtsystems,tIEEEtTransactionstontBiomedicaltEngineering,t64(3):t621–628,t2017.t [2] tS.H.tAhmetd,tD.tKim,tNamedtdatatnetworking basedtsmartthome,tIcttExpress,t2(3):t130–134,t2016. [3] tS.S.tRautaray,tA.tAgrawal,tVisiontbasedthandtgesturetrecognitiontforthumantcomputertinteraction:tasurvey,tArti?cialtIntelligencetReview,t43(1):t1–54,t2015. [4] tF.J.tOrd´to˜nez,tD.tRoggen,tDeeptconvolutionaltandtlstmtrecurrenttneuraltnetworkstfortmultimodaltwearabletactivitytrecognition,tSensors,t16(1):t115,t2016. [5] D.tCook,tKD.tFeuz,tNC.tKrishnan,tTransfertlearningtfortactivitytrecognition:tAsurveyt,tKnowledgetandtInformationt [6] L.tWang,tRecognitiontofthumantactivitiestusingtcontinuoustautoencoderstwithtwearabletsensors,tSensors,t16(2):t189,t2016. [7] Y.tBengio,tDeeptlearningtoftrepresentations:tLookingtforward,tintInternationaltConferencetontStatisticaltLanguagetandtSpeechtProcessing,t1–37,t2013.t
Copyright
Copyright © 2022 B. V. V. S Sairam, Nagubadi Sasi Kumar, Sanjib Gosh. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET39628
Publish Date : 2021-12-24
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online