

Ijraset Journal For Research in Applied Science and Engineering Technology
Image Based Search Engine Using Deep Learning
Authors: Dr. Y. UshaRani, Teja Abhinav Reddy Kaipu, T. Koushik, U. Sai Kiran, K. Satwik
DOI Link: https://doi.org/10.22214/ijraset.2023.51663
Certificate: View Certificate
Abstract
Machine the learning\'s field of image recognition as well as classification is one that is expanding quickly. The business ramifications of object identification, which is a crucial component of picture categorization, are enormous. A procedure to identify and recognize an item or property in a digital video or picture, image recognition is a subset of artificial intelligence. A larger phrase used to describe techniques for obtaining, processing, and analyzing data from the actual environment is computer vision. The highly dimensional data generates judgements that are expressed as numerical or pictorial information. Artificial intelligence (AI) also encompasses event detection, object identification, learning, picture the rebuilding process, and tracking of video in addition to image classification. This project outlines a methodical strategy to organizing using machine learning. digital photos. Convolutional neural network (CNN) and deep neural networks are two classifiers that may be combined to improve classification performance. Over the past several years, Convolutional Neural Networks (CNNs) have emerged as the leading approach for image classification and object recognition tasks. On several of the picture categorization databases, they now outperform humans. Most of these datasets are built around the idea of tangible classes; photographs are categorized according to the kind of item they include. Using Abstract classes, this project will propose a unique picture classifying dataset that should be simple for humans to solve but difficult for CNNs to fully understand. This dataset and potential variants of the dataset are used to assess the classifications performance of common CNN designs. Interesting topics for future study are found.
Introduction
I. INTRODUCTION
A. Introduction
Along with Bing photo searches, engines for searching like the CBIR engines of the software giant, the CBIR equipment of Google, take note: Not sprinting on every picture (Public the Business), the CBIR engine operated by Gazala (Private company), the Immense Illustration Search The portal (Private business), and others appear to have grown quickly in the past decade. The task of retrieving photos continues to be difficult for Com (Private Organization) [1]. With the aid of the current era, creators can scan for written material statistics very quickly, but this data collection tackle requires people to individually demonstrate each pixel throughout the database, a task which is nearly impossible for massive data sets and for pictures intended to be created physically such as images from security cameras. It has extra drawbacks as a result of Images that employ certain equivalent phrases inside the definition of photos may be skipped. Techniques that focus on classifying images into semantic groups, such as "tiger" as a" livestock "subclass, will eliminate the problem of mis categorization, but it will take more work to select the images that are potentially "tigers" with the help of a usage, even though they are every most useful as a" animal [2]. Contrary to traditional methods, which are entirely cent red around concepts methods, the CBIR methodology [3].
B. Objective
The effectiveness of a Content-Based Image Retrieval (CBIR) system relies heavily on the accuracy of its similarity and characteristic representation algorithms. Convolutional Neural Networks (CNNs) offer a simple and powerful deep learning approach to tackle this challenge by extracting and categorizing features to enable fast image retrieval. Multiple detailed observational studies using diverse image databases have yielded promising results, offering valuable insights for improving CBIR performance. By employing CBIR systems, it is possible to retrieve images that are related to a query image from another picture dataset. The most widely used CBIR technique must be Google's search by image feature.
II. LITERATURE SURVEY
Contrary to various traditional approaches that have been established in recent years, each of which has several drawbacks, such as the histogram, this representation first and foremost results in the loss of geographic data, which is necessary in order to properly convey the content of the photograph. Second, the usage of the histogram brings up the issue of quantifying distinctive spaces. It has been demonstrated that CNN, which was created expressly to cope with the variety of 2D shapes, outperforms all other methods. The many modules that make up recognition systems include feature extraction, classification, and paradigm learning.
In order to improve a performance metric overall, they are enabling such diverse systems to be educated worldwide applying variance-based techniques. The first effective findings on the use of supervised backward propagation systems for digit recognition were reached by [1] in 1998.
Scholars have benefited and created a number of models and methodologies as a result of the development of machine learning for image processing and retrieval as well as the significant decrease in the cost of computer gadgets, such as graphics processors (GPU)., and have researched CNN.
[2] They tested an innovative deep learning approach (Convolutional Neural Networks) for an architecture of deep knowledge with application for CBIR. demonstrated a CNN model parametric workflow that was created using Microsoft Azure's Machine Learning Studio (MAMLS), a cloud-based computing platform, and can acquire information from maps of features and organizing multi-modal pictures with various variabilities through just one process. Contrary to earlier methods, the binarization process algorithms [5, 6] need for paired inputs to acquire binary code.
The extracted includes' ability to generalize, the relationship between decreased dimensions and loss of accuracy in CBIRs, the most efficient distance measuring technique to CBIRs, and the benefit of coding procedures for increasing the effectiveness of CBIRs all contribute to the description of features having the greatest accuracy offered by CNN.
[5] suggested presenting a feature binarization strategy for improved CBIR efficiency. More precisely, the binarization decreased the original data's 31/32 space use. A deep learning system to produce binary data was suggested in [6]. hash codes to get images quickly. The theory states that binary codes may be learnt when the data labels are accessible by utilizing a hidden layer to reflect the latent notions that predominate the class labels. The use of CNN also facilitates the 'learning' of picture descriptions. The method they use is ideal for huge datasets since it transfers hash codes and picture renderings in a point-wise way.
[Support the Vector Machine Advanced Learning Algorithms] has been used by them to perform efficient feedback on relevancy for picture retrieval. The suggested method selects the most interesting photos to fulfil the user's query notion promptly learns an area that isolates those images from the remaining parts of the database. The authors integrated CNN with SVM to benefit from SVM methods for classification [8–10]. [8] implements an amalgamated CNN and support victor engine (SVM) model in the CBIR and employs (SVM) to create a hyperplane that can effectively distinguish between similar and different picture pairings. The query picture and every test image in the photograph collection are the pair features that make up the data source of the SVM.
III. SYSTEM OVERVIEW
A. Existing System
Similarity evaluation is a focus of some other contemporary techniques. As an illustration, ELALMI [19] presented a CBIR model in which he introduced a matching The suggested model collects color and texture information from photos and reduces this set by choosing pertinent and not redundant. elements. This technique measures the resemblance between images. The obtained photos are then classified using an ANN network such that they belong to the same class as the query's photo. The simulation employs a matching method for the recovery stage by computing the overlap across every single database image characteristic vector and the corresponding image query attributes vectors.
1. Existing System Disadvantages
a. In existing methods image processing techniques are used which are less accurate and results are not promising.
b. Machine learning algorithms are used in which accuracy of the model is less than 70 percent.
B. Proposed System
Every one of the neurons throughout a convolutional neural network (CNN) are tiled in a feed-forward artificial neural network such that it reacts when there are overlaps in the visual field. They are VGG 19 model invariants with biological inspiration that need the least amount of preparation. These models are frequently applied to video and recognize images. Convolutional artificial neural networks employ comparatively less pre-processing in comparison to other classification and extraction of features techniques. This implies that, unlike other more established methods, the network is in charge of creating its own filters (unsupervised learning). One of CNN's key advantages is the absence of initial calibration and human interaction. This project's primary goal is to make money from the performance.
- Advantages of Proposed System
a. Proposed system is accurate in content-based image retrieval.
b. Accuracy of the proposed model is more accurate than other approaches currently in use.
C. Design of Proposed System
For this project, I employed five distinct modules, each with its own set of functions, including:
- Dataset
Collect data set of images which we want to train and create folders with names. Name of the folder is considered as label and data inside image is considered as label.
2. Image Processing
The system's input picture is collected from datasets and data must be pre-processed. Pre-processing in this case comprises image scaling as well as contrast and brightness adjustments. This is done to adjust for the picture's non-uniform lighting and is accomplished using image processing techniques such as image data generator to process data.
3. Test Train Split
The dataset is split into both test and training data. We aim to assess our model's performance on novel data and the extent to which it has adapted to the training data by conducting this split. The next phase in a model's construction process is the model's appropriate, which comes after this process.
4. Model Evaluation
This last stage involves evaluating our model's performance using data from the test. I employed the "accuracy score" assessment measure to examine my model. A model example is first created, then the initial data set is fitted to the model using the fit approach, and finally predictions are made using the predict algorithm using the x_test or testing information. After generating the forecasts, the results are stored in a variable called y_test_hat. To evaluate the effectiveness of our method, we will use the accuracy_score function to compare y_test and y_test_hat and store the outcome in a parameter called test_accuracy, which reflects the model's testing accuracy. We applied these steps across various machine learning models and obtained varying results.
5. Classification
In this stage user registers with web application and uploads images to website and image is preprocessed and passed to loaded model and perdition is performed and related images are displayed to user.
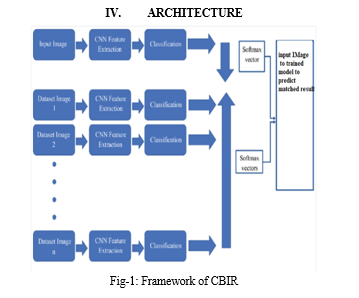
VI. FUTURE ENHANCEMENT
Future CBIR products will be built on Squeeze Net and ResNet18 models, which were created and evaluated on multiple-class digital picture datasets (Core-1K and GHIM-10K). The results of the evaluation of these models were contrasted to those of classic CBIR, which is based on characteristics of both texture and color.
Conclusion
The CBIR job based on CNN may be fully updated by incorporating the pooling intermediary layers of the algorithm such as a representation of features and VGG 19 model. It can save a significant amount of money and even speed up preparation. Once again, the CNN model shows how they perform. Pre-learning yields excellent outcomes: it is quick for using them as highlight image and classification extractors, and it is even better for retraining them specifically (Fine Tuning). The mining of attributes is a great first step that strikes a great balance between performance and intricacy. The results are encouraging and provide fresh views. Pre-processing the photographs by cropping or restoring the hue histograms might occasionally be useful. Additionally, models may be enhanced via standard methods for adding features.
References
[1] Lin, X., J.-H. Li, S.-L. Wang, F. Cheng and X.-S. Huang, Recent advances in passive digital image security forensics: A brief review. Engineering, 2018. 4(1): p. 29-39. [2] Fonseca, L.M.G., L.M. Namikawa, and E.F. Castejon., Digital image processing in remote sensing. in 2009 Tutorials of the XXII Brazilian Symposium on Computer Graphics and Image Processing. 2009. IEEE. [3] Liu, Y., D. Zhang, G. Lu and W.-Y. Ma ., A survey of content-based image retrieval with high-level semantics. Pattern recognition, 2007. 40(1): p. 262-282. [4] Zare, M.R., R.N. Ainon, and W.C. Seng., Content-based image retrieval for blood cells. in 2009 Third Asia International Conference on Modelling & Simulation. 2009. IEEE. [5] Sreedevi, S. and S. Sebastian., Content based image retrieval based on Database revision. in 2012 International Conference on Machine Vision and Image Processing (MVIP). 2012. IEEE. [6] Latif, A., A. Rasheed, U. Sajid, J. Ahmed, N. Ali, N. I. Ratyal, B. Zafar, S. H. Dar, M. Sajid and T. Khalil ., Content-based image retrieval and feature extraction: a comprehensive review. Mathematical Problems in Engineering, 2019. 2019. [7] Wang, S., K. Han, and J. Jin., Review of image low-level feature extraction methods for content-based image retrieval. Sensor Review, 2019. [8] Thilagam, M. and K. Arunish., Content-Based Image Retrieval Techniques: A Review. in 2018 International Conference on Intelligent Computing and Communication for Smart World (I2C2SW). 2018. IEEE. [9] A. Iliukovich-Strakovskaia, A. Dral, and E.Dral, “Using pre-trained models for fine-grained image classification in fashion field,” 2016 [10] Y. Liu, D. Zhang, G. Lu, and W.-Y. Ma, “A survey of content-based image retrieval with high-level semantics,” Pattern recognition, vol. 40, no. 1, pp. 262–282, 2007. [11] N. Khosla and V. Venkataraman, “Building image-based shoe search using convolutional neural networks,” CS231n Course Project Reports, 2015. [12] Z. Ji, W. Yao, W. Wei, H. Song, and H. Pi, ‘‘Deep multi-level semantic hashing for cross-modal retrieval,’’ IEEE Access, vol. 7, pp. 23667–23674, 2019. [13] K. Sankar, G. N. K. Suresh Babu, “Implementation of Web Image Search Portal with automated concealed annotation,” Communication and Electronics Systems (ICCES), IEEE, 2016. [14] Yuan Cao, Heng Qi, Jien Kato, Keqiu Li, “Hash Ranking with Weighted Asymmetric Distance for Image Search,” IEEE Transactions on Computational Imaging, IEEE, vol. 3, no. 4, Dec. 2017, pp. 1008-1019.
Copyright
Copyright © 2023 Dr. Y. UshaRani, Teja Abhinav Reddy Kaipu, T. Koushik, U. Sai Kiran, K. Satwik. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET51663
Publish Date : 2023-05-06
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online