

Ijraset Journal For Research in Applied Science and Engineering Technology
Image Classification Using Convolutional Neural Networks
Authors: Srinija Srimamilla
DOI Link: https://doi.org/10.22214/ijraset.2022.47085
Certificate: View Certificate
Abstract
Convolutional neural networks (CNNs), which are composed of multiple processing layers to learn the representations of data with multiple abstract levels, are the most successful machine learning models in recent years. Within this paper, we present the usage of a trained deep convolutional neural network model to extract the features of the images, and then classify the images. We will study image processing and understand image classification. It has good application prospects.
Introduction
I. INTRODUCTION
The rise of big data and the rapid popularization of high-performance computing devices in recent years have contributed to the unprecedented development of machine learning. Regarding image classification, this study intends to artificially extract features, and convert the features of an original image into useful features characterized by lower dimension and less noise. Machine learning has been gaining momentum over last decades. It is a class of artificial intelligence methods, which allows the computer to operate in a self-learning mode, without being explicitly programmed. Neural network is a machine learning algorithm. It is a system of interconnected arti?cial “neurons” that exchange messages between each other. The network consists of multiple layers of feature-detecting neurons. Each layer has many neurons that respond to different combinations of inputs from the previous layers. Convolutional Neural Network is a special case of the neural network proposed by Yann LeCun in 1988. It consists of one or more convolutional layers, often with a subsampling layer, which are followed by one or more fully connected layers as in a standard neural network. The design of a CNN is motivated by the discovery of a visual mechanism, the visual cortex, in the brain. Each feature of a layer receives inputs from a set of features located in a small neighbourhood in the previous layer called a local receptive ?eld. With local receptive ?elds, features can extract elementary visual features, such as oriented edges, end-points, corners, etc., which are then combined by the higher layers. One of the most important uses of this architecture is Image Classification.
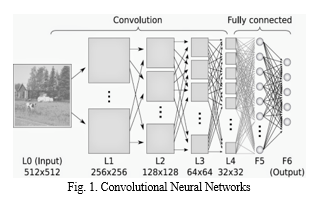
While neural networks and other pattern detection methods have been around, there is signi?cant development in the area of convolutional neural networks. This is because of its ruggedness to shifts and distortions in the image, fewer memory requirements, easier and better training. The image input is passed through a series of convolutional, pooling, flattening and dense fully connected layers, and then the output is generated. In this paper we will be studying about layers of convolutional neural networks and its implementation in real-time.
II. RELATED WORK on IMAGE CLASSIFICATION using CNNs
Convolutional Neural Network has become the most successful deep learning model in the computer vision industry. In recent years, deep learning has been quickly promoted in the machine learning industry, and remarkable theoretical and practical achievements have been continually attained. The development of deep learning can be divided into three stages. From the 1940s to the 1960s, deep learning was called the control theory. While the theoretical development of biological learning and the establishment of the perceptron triggered the first wave of interest in artificial neural networks, as the perceptron could not be used to learn linearly inseparable data, it was resisted by many researchers, which resulted in the low ebb of the first stage. The second wave started with connectionism in 1980 and ended in 1995. In 1974, Paul Werbos proposed the back-propagation algorithm, and solved the problem of linear inseparability in the neural network model. However, as the quantity of training data was small, and the performance of the computers was poor at that time, there was a serious problem in most of the deep learning models - overfitting. At the same time, great progress was made in other machine learning fields. Consequently, deep learning was neglected by most people, which marked the low ebb of the second stage. In 2006, Hinton and Salakhutdinov displayed a neural network model called the autoencoder in the magazine Science. By adopting an unsupervised learning algorithm to initialize networks layer by layer, they efficiently improved the generalization of the deep network. Since then, many researchers have used the same method to revitalize a large number of the deep learning models, which were challenged in the 1980s. This marked the entry into the third wave of deep learning.
Based on the visual system, the convolutional neural network (CNN) is a neural network used exclusively to process data with a lattice structure. In 1959, Hubel and Wiesel discovered the visual cortex cells of mammals and proposed the concept of a partial receptive field. Inspired by this, Fukushima and Kunihiko put forward Neocognitron in 1984, which can be regarded as the prototype of the modern convolutional network. In the 1990s, LeCun published relevant papers to define the modern structure of CNN and improved it afterwards. LeNet-5 is the first convolutional network that could be applied in reality. With little pre-processing, the network can directly learn the number image classifications in the original pixels. However, the training data were inadequate, and the computation ability of the computer was weak; thus, LeNet-5 was not effective in handling complicated problems.
In 2009, Le integrated the convolutional neural network with the deep belief network to form the Convolutional Deep Belief Network (CDBN). In 2012, Krizhevsky adopted AlexNet to bring the error rate of image classification down from 26.3% to 15.2% in ILSVRC-2012. In 2014, a Google team used GoogLeNet to achieve a lower error rate (6.67%) in ILSVRC-2014. In 2015, the convolutional network of Microsoft MSRA brought the error rate of the ImageNet 2012 data concentration down to 4.94%, thus, surpassing humans in terms of recognition.
III. SYSTEM MODEL
We used Python Code for this project. As a framework we implemented Keras, which is a high-level neural network API written in Python. It can’t work by itself, it needs a backend for Flow-level operations. Thus, we installed a dedicated software library called Google’s TensorFlow. As a development environment we used Jupyter Notebook and Matplotlib for visualization. For network training and testing we can download the dataset of images.
IV. PROBLEM STATEMENT
The human visual system does not perceive the world in the same manner as digital detectors imposing additional noise and bandwidth restrictions. Human optical illusions distort and fabricate features due to fundamental properties of human visual perception. Moreover, the memory of humans might me huge but ability to use it might lack. If there are hundreds and thousands of pictures that are to be studied, then it can be digitally possible at ease while it can be a very difficult task manually. The underlying features of the images, distortions, shifts, noise, etc., cannot be easily recognizable by humans. Thus, image classification has been introduced on a digital platform.
V. SOLUTION
Digital image classification utilizes computer-aided enhancement to turn subjective features of an image into data that can be measured, quantified and evaluated. Image processing must be approached in a manner consistent with the scientific method so that others may reproduce, and validate, one’s results. To study image processing and understand image classification we will be using convolutional neural networks. The image input is passed as a dataset through a series of convolutional, pooling, flattening and dense fully connected layers, and then the output is generated.
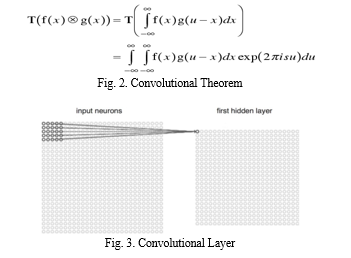
A. Convolution Layer
It is always the first. The image matrix with pixel values is entered into it. Imagine that the reading of the input matrix begins at the top left of image. Next the software selects a smaller matrix there, which is called a filter. Then the filter produces convolution, i.e. moves along the input image. The filter’s task is to multiply its values by the original pixel values. All these multiplications are summed up. One number is obtained in the end. Since the filter has read the image only in the upper left corner, it moves further and further right by one unit performing a similar operation. After passing the filter across all positions, a matrix is obtained, but smaller than the input matrix. When the image passes through one convolution layer, the output of the first layer becomes the input for the second layer. And this happens with every further convolutional layer.
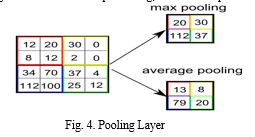
B. Pooling Layer
It follows the convolutional layer. It works with width and height of the image and performs a down sampling operation on them. As a result, the image volume is reduced. This means that if some features have already been identified in the previous convolution operation, then a detailed image is no longer needed for further processing, and it is compressed to less detailed pictures.
C. Flattening Layer
After the convolution and pooling layers, our classification part consists of dense fully connected layers. However, these fully connected layers can only accept One Dimensional data. To convert our 3D data to 1D, we use the flattening layer.
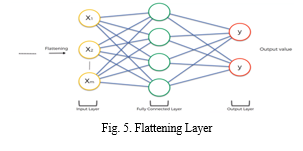
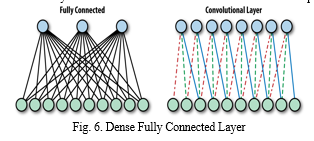
D. Dense Fully Connected Layer
After completion of these series of layers, it is necessary to attach a dense fully connected layer. Attaching a fully connected layer to the end of the network results in an N Dimensional Vector, where N is the number of classes from which the model selects the desired class. Neurons in a fully connected layer have full connections to all the activations in the previous layer.
VI. IMPLEMENTATION of the SOLUTION
# Importing the Keras libraries and packages
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Flatten
from keras.layers import Dense
# Initialising the CNN
classifier = Sequential()
# Step 1 - Convolution
classifier.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = 'relu'))
# Step 2 - Pooling
classifier.add(MaxPooling2D(pool_size = (2, 2)))
# Adding a second convolutional layer
classifier.add(Conv2D(32, (3, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
# Step 3 - Flattening
classifier.add(Flatten())
# Step 4 - Full connection
classifier.add(Dense(units = 128, activation = 'relu'))
classifier.add(Dense(units = 1, activation = 'sigmoid'))
# Compiling the CNN
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
# Fitting the CNN to the images
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = ImageDataGenerator(rescale = 1./255)
training_set = train_datagen.flow_from_directory('dataset/training_set',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
test_set = test_datagen.flow_from_directory('dataset/test_set',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
classifier.fit_generator(training_set,
steps_per_epoch = 800,
epochs = 25,
validation_data = test_set,
validation_steps = 200)
# Making predictions
import numpy as np
from keras.preprocessing import image
test_image= image.load_img('dataset/single_prediction/cat_or_dog_1.jpg', target_size = (64, 64))
test_image = image.img_to_array(test_image)
test_image = np.expand_dims(test_image, axis = 0)
result = classifier.predict(test_image)
training_set.class_indices
if result[0][0] == 1:
prediction = 'dog'
else:
prediction = 'cat'
VII. ANALYSIS
The basis of the model is Supervised Machine Learning. It is one of the ways of machine learning where the model is trained by input data and expected output data. It is tested and evaluated. ?o create such model, it is necessary to go through the following phases: model construction, model training, model testing and model evaluation. Model Construction depends on machine learning algorithms. In this project’s case, it is convolutional neural networks. Before model training it is important to scale data for the further use. After model construction it is time for Model Training. In this phase, the model is trained using training data and expected output for this data. Progress is visible on the console when the script runs. At the end it will report the final accuracy of the model. Once the model has been trained it is possible to carry out Model Testing. During this phase a second set of data is loaded. This data set has never been seen by the model and therefore it’s true accuracy will be verified. Finally, the saved model can be used in the real world. The name of this phase is Model Evaluation. This means that the model can be used to evaluate new data.
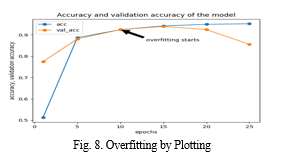
We have taken datasets of cats and dogs. We tried how to classify the images of cats and dogs. The Training Set has 800 pictures of cats and dogs. The Test Set has 200 pictures of cats and dogs. Given any image we must classify whether it is a cat or a dog. As a result of testing the model, we got a very good accuracy: 93.8% of correct classification samples after 32 epochs. The only drawback was that we had to wait about 30 minutes until 32 epochs come to the end. If the training data accuracy (acc) keeps improving while the validation data accuracy (val_acc) gets worse, we are likely in an overfitting situation, i.e. your model starts to basically just memorize the data. Consequently, this model is sufficient to train on 10 epochs. The model can still be optimized to get 100% accuracy by introducing new techniques into the model.

VIII. ACKNOWLEDGMENT
This project work was supported by our Mentor Prof. Dr. G Madhu of Information Technology Department and encouraged by our Institution VNR Vignana Jyothi Institute of Engineering and Technology.
Conclusion
From this project, we figured out what deep learning is. We constructed, assembled, trained, tested and evaluated the Convolutional Neural Networks Model to classify images of cats and dogs. We have tested that this model works well with small number of images and measured how the accuracy depends on the number of epochs in order to detect potential overfitting problem. It is determined that 10 epochs are enough for a successful training of the model. The scope can be extended to try this model on more data sets and apply it to practical tasks in order to see how a higher efficiency can be achieved in various problems.
References
[1] https://www.learnopencv.com/image-classification-using-convolutional-neural-networks-in-keras/ [1] [2] http://www.thejavageek.com/2018/05/13/image-classification-using-cnn/ [2] [3] Papers from https://ieeexplore.ieee.org/document/8379889 [3] [4] Book on Deep Learning with Python by François Chollet [4] [5] Book on Practical Convolutional Neural Networks by Pradeep Pujari, Md. Rezaul Karim, Mohit Sewak [5]
Copyright
Copyright © 2022 Srinija Srimamilla. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET47085
Publish Date : 2022-10-15
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online