

Ijraset Journal For Research in Applied Science and Engineering Technology
Impact on Performance in Football Game by Players Position using Machine Learning Techniques
Authors: Swathi Gadipudi, Vyshnavi Kesari, Sai Bharath Chitluri, Venkata Naga Satya Swaroop Akkinapalli, Dr. Ram Prasad Reddy Sadi
DOI Link: https://doi.org/10.22214/ijraset.2023.50228
Certificate: View Certificate
Abstract
For many people who have aspired to be successful in their occupations, sports has emerged as a fantastic new field. One of the sports that has gained popularity is football. Better results are obtained when we are aware of and focus on our strengths. The same is true for a player who is conscious of his skills and makes a concerted effort to develop them. A coach must find a player who suits a given position, but doing so might be difficult for a variety of reasons. In the current study, the binary relevance and random forest have been used to find a solution to the problem of determining a football player\'s optimal position. Test results show that the strategy is effective.
Introduction
I. INTRODUCTION
Sports provide a sufficient amount of statistical data on each player, club, game, and season. Earlier, it was thought that experts, coaches, team managers, and analysts owned sports science. Sports companies have recently become aware of the science included in their data and wish to utilize that research by using various data mining approaches. Sports data mining helps coaches and management in a variety of ways, including with result prediction, player performance, talent appraisal, and player identification. Prediction aids clubs and managers in making the best choices to win leagues and tournaments. In all the types of sports, this project deals with the game of football. Football is a sport which involves two teams with eleven players of each team without using their hands or arms, move ball into opposing team's goal. Team with most goals scored wins. The best method to develop intuition is through practice and self-assurance in one's position. But it can be challenging to hone these instincts given the range of places on a soccer field. The team's success, though, is influenced by the players' abilities as well as the roles they are given.In this case, we will train the model using different classification techniques to determine which is the best.The player's ideal position is predicted using the trained model. Additionally, rather than using their score in the model training, their skills are used. Take a former forward player as an illustration. A striker is in the optimal position after a rigorous appraisal of the player's abilities, meaning he can play as a striker more effectively than as a forward. However, other elements, such as experience, may have an impact on older players who have been playing in the position for a while. New players won't be affected in the slightest. Simply put, it fits the new model the best.
A. Project Scope and Direction
It is helpful for the players to improve their skills and also used for coach to put the player in the best position Based on the predictions it can give us a detailed report of the player's positions based on their skills.By this way the winning accuracy can be increased and the player can focus on their best skills.
B. Impact, Significance and Contribution
Choosing suitable position is critical for player in any game, but it's slightly more difficult in football due to large number of positions. Likely, they will simply accept the position that is suggested. If they do this, they may or may not be successful. To prevent this confusion, we will provide idea of their position based on their skills.Identifying a player who is suited for a particular position is crucial for a coach or player, but it can be difficult for a number of different reasons. So if we predict it beforehand it will be easier for practice and performance.
II. RELATED WORK
- Pantzalie Victor Chazan The model was developed using naive bayes, random forests, KNN, and decision trees by the Data Mining and Analytics research team from the School of Science and Technology International Hellenic University. The initial goal of the plan was to separate the clubs into those that would perform better than last season in terms of points earned and those that would perform worse. The results are good but not particularly noteworthy. In order to predict team performance, it was necessary to recreate each game of the season and categorize the outcomes as home wins, draws, or away wins. This technique produced 14 exceptional results. The expected league final standings were then determined by adding up the points earned by each team.
- Javier Fernandez, Daniel Medina, Antonio Gomez Diaz, Marta Arias, and Ricard Gavalda conducted a study on training and player physical performance. It comes to the conclusion that not every attribute depends on the result. Before training the model, they utilize feature selection and PCA (Principal Component Analysis) for dimensional reduction to eliminate the irrelevant and undesired attributes. The findings demonstrate that deleting the irrelevant attributes improves the model's accuracy.
- According to research by Verstraete, Kenneth, Decroos, Tom, Coussement, Bruno, Vannieuwenhoven, Nick, and Davis, Jesse, a player's performance is influenced by a variety of factors, including age and experience in addition to their skill level.
- The Pima-Indians Diabetes dataset was the subject of an experiment by Westin and Lena, and the results show that the missing values had an impact on the outcome. They came to the conclusion that better results were obtained by deleting the missing numbers.
- An study of the advantages of binary relevance over alternative multi-label classification algorithms has been presented by Luaces, Oscar, Dez, Jorge, Barranquero, Jose, del Coz, and Bahamonde, Antonio.
- Algorithms like naive bayes, baysen networks, logit boost, and knn are employed by OsipHucaljuk and Alen Rakipovi of the Faculty of Electrical Engineering and Computing at the University of Zagreb. the challenge of predicting football game outcomes. Due of the popularity and ubiquity of the sport, it presents an interesting problem. But because there are so many variables that must be considered that cannot be quantified or described, predicting the results is likewise a challenging task. Because the teams in the Champions League are evenly matched, selecting one team as the "favourite" of a game won't necessarily provide favourable outcomes. The expert who labelled the second batch may not have been all that knowledgeable.
- Sports analytics have become significant in recent years. Players can record their position and mobility information while playing thanks to recently developed tracking systems. These data can be used to improve performance of both teams and individual players. For advanced tactical analysis, we provide various machine learning techniques toforecast spatial placements of players.
III. METHODOLOGY
A. Multi-label Classification
Algorithms that can be used for multi-label classification include:
- Random Forest: most accurate method for predicting "win" and "loss" is random forest. By averaging the outcomes from various trees, it generates forecasts. As the number of trees grows, the accuracy of the outcome improves. In a random subset of features, it looks for the best feature. Therefore, the random forest method will be useful in determining the position of players.
- Binary Relevance: Multilabel classification problems can be solved using binary relevance. The most logical approach to learning from examples with many labels is binary relevance. It functions by breaking down multi-label job into several separate binary tasks.
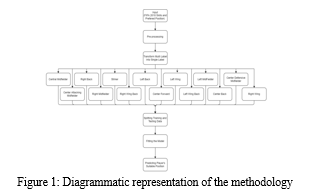
IV. PROPOSED FRAMEWORK
In this system rather than directly predicting the position by eliminating the multi label tuples in the data set here, it is dealt with the binary relevance methodology i.e., the conversion of multi labeled data in 14 multi class classification models. Unlike the Existing system that can predict only 4 positions but here it can predict 14 different positions. Based on the predictions it can give us a detailed report of the player's positions based on their skills.

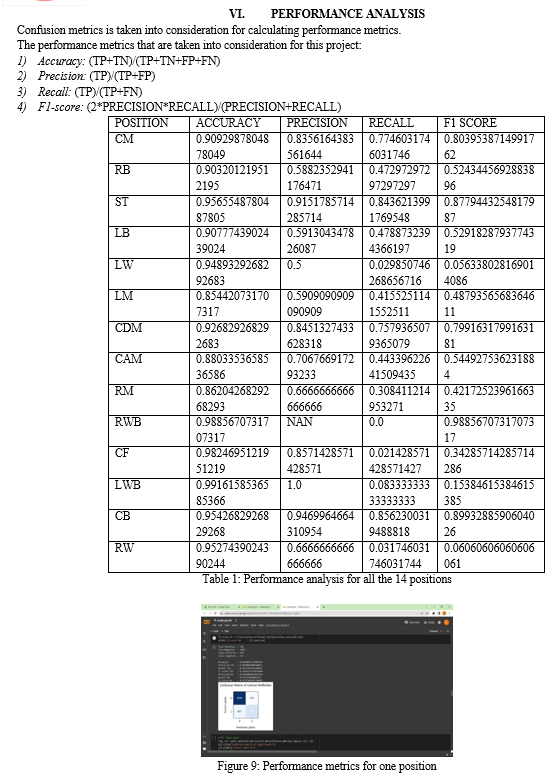
Conclusion
Choosing suitable position is critical for player in any game, but it\'s slightly more difficult in football due to large number of positions. Likely, they will simply accept theposition that is suggested. If they do this, they may or may not be successful. To prevent this confusion, we will provide idea of their position based on their skills.A coach or player must find a player who is qualified for a specific position, but doing so might be difficult for a number of reasons. So, if we predict it beforehand it will be easier for practice and performance. This project will provide the best suitable positions for the players with the highest accuracy. There is room for further improvement. Larger dataset would also help in achieving better results.
References
[1] Chazan-Pantzalis, Victor &Tjortjis, Christos. (2020). Sports Analytics for Football League Table and Player Performance Prediction. [2] Fernández, Javier & Medina, Daniel & Gómez Díaz, Antonio & Arias, Marta &Gavaldà, Ricard. (2016). From Training to Match Performance: A Predictive and Explanatory Study on Novel Tracking Data. 136-143. 10.1109/ICDMW.2016.0027. [3] Verstraete, Kenneth &Decroos, Tom &Coussement, Bruno &Vannieuwenhoven, Nick & Davis, Jesse. (2020). Analyzing Soccer Players’ Skill Ratings Over Time Using Tensor-Based Methods. 225-234. 10.1007/978-3-030-43887-6_17 [4] Westin, Lena. (2008). Missing data and the preprocessing perceptron. [5] Luaces, Oscar &Díez, Jorge &Barranquero, Jose & del Coz, Juan &Bahamonde, Antonio. (2012). Binary relevance efficacy for multilabel classification. Progress in Artificial Intelligence. 1. 10.1007/s13748- 012-0030-x. [6] Ali, Jehad & Khan, Rehanullah& Ahmad, Nasir & Maqsood, Imran. (2012). Random Forests and Decision Trees. International Journal of Computer ScienceIssues(IJCSI)9 [7] Machine Learning for Position Detection in Football by Martin Frey, Elvis Murina, Janick Rohrbach, Manuel Walser, Patrick Haas, Marcel Dettling
Copyright
Copyright © 2023 Swathi Gadipudi, Vyshnavi Kesari, Sai Bharath Chitluri, Venkata Naga Satya Swaroop Akkinapalli, Dr. Ram Prasad Reddy Sadi. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET50228
Publish Date : 2023-04-09
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online