

Ijraset Journal For Research in Applied Science and Engineering Technology
Implementation of Machine Learning Technique for Prediction Agriculture Produce
Authors: Miss. Komal K Khandare, Dr. S. R. Gupta
DOI Link: https://doi.org/10.22214/ijraset.2022.41724
Certificate: View Certificate
Abstract
In Indian economy and employment agriculture contributes a major role. Probably most common problem faced by the Indian farmers is they do not optimize crop based on the necessity of soil, as a result they face serious setback in productivity. This problem can be addressed through precision agriculture. This method takes three parameters into consideration, viz: soil characteristics, soil types and crop yield data collection based on these parameters suggesting the farmer suitable crop to be cultivated. Precision agriculture helps in reduction of non suitable crop which indeed increases productivity, apart from the following advantages like efficacy in input as well as output and better decision making for farming.
Introduction
I. INTRODUCTION
In this system we are focusingon figuring out the best crop to grow in order to get optimum yield. We have gathered a dataset built by augmenting datasets of rainfall, climate and fertilizer data available for India. This willgive us a better idea of the trends of crops considering different environmental and geographicalfactors. This will eradicate the problem of nutrients deficiency in fields occurring because ofplanting wrong crops which can scale down the production efficiency in a compound manner.
II. LITERATURE SURVEY
- In this system first the farmers will take some soil of the agricultural field and get it tested by the lab. This process is called soil testing. An accurately calibrated soil test will indicate the degree of nutrient deficiency in a soil and estimate the nutrient rate required to optimize crop productivity. An efficient way to improve accuracy and efficiency in this process is to create a dataset with the data values collected over the years. By the use of technology and data mining concepts, we can create an application which has the ability to suggest the best suitable crop. The main inputs of this system will be the diagnosed nutritional features in soil directly from the lab test reports. They are using the data mining concept and Naive Bayes Algorithm which can give the accurate output. The system based on dataset, will suggest the crops which can suit this soil type and can give profits to the farmer.
- In this they designed a systemmachine learning for betterment of the farmer. Machine learning(ML) is a game changer for agriculture sector. Machine learning is the part of artificial intelligence, has emerged together with bigdata technologies and high-performance computing to create new opportunities for data intensive science in the multi-disciplinary agri- technology domain. In the Agriculture field machine learning for instance is not a mysterious trick or magic, it is a set of well define model that collect specific data and apply specific algorithms to achieve expected results. This designed system will recommend the most suitable crop for particular land. Based on weather parameter and soil content such as Rainfall, Temperature, Humidity and pH. They are collected from V C Farm Mandya, Government website and weather department. This system takes the required input from the farmers or sensors such as Temperature, Humidity and pH. This all inputs data applies to machine learning predictive algorithms like Support Vector Machine (SVM) [5] and Decision tree [6] to identify the pattern among data and then process it as per input conditions. The system recommends the crop for the farmer and also recommends the amount of nutrients to be add for the predicted crop.
- Outline of the proposed system Productivity of a particular crop greatly depends on land resources and the climate of the area along with other factors such as fertilizers. Identification of crop requirements and matching them with the resources available to optimize the productivity in sustainable manner assumes a greater importance. Crop management practices based on soil site suitability criteria and weather conditions will help to overcome this. The proposed system will integrate the data obtained from repository, weather department and user inputs. This machine learning model is developed considering the various, different sets of data to obtain the output. The system takes input from various sources and repositories for weather, soil and crop requirement data and uses NaïveBayes algorithm to predict the best suitable crop for any given area. The developed user interface is flexible and highly interactive which will encourage the farmers to use this mobile application
- In order to discover useful knowledge which is desired by the decision maker, the data miner applies data mining algorithms to the data obtained from data collector. The privacy issues coming with the data mining operations are twofold. If personal information can be directly observed inthe data, privacy of the original data owner will be compromised. On the other hand, equipping with the many powerful data mining techniques, the data miner is able to find out various kinds of information underlying the data. Sometimes the data mining results reveals sensitive information about the data owners. As the data miner gets the already modified data so here the objective was to show the comparative performance between already used classification method and the new method introduced. As previous studies shows that the ensemble techniques provide better results than the decision tree method thus the desired result was inspired thru this concern.
III. SYSTEM DESIGN
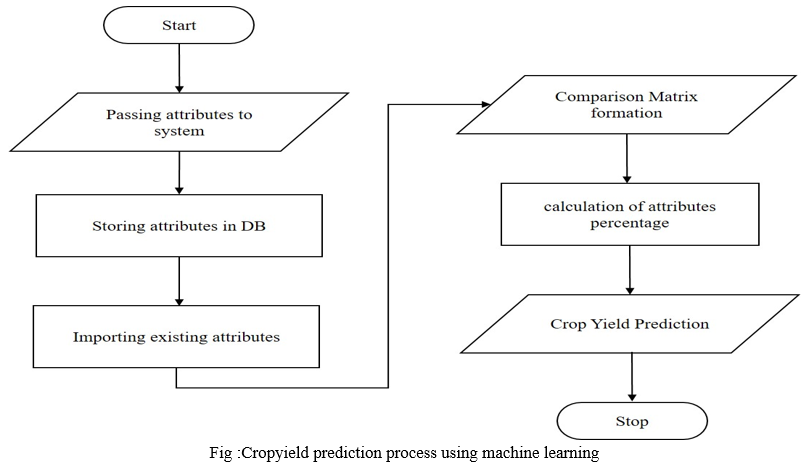
IV. PROPOSED WORK
The objectives of the dissertation:
- To predict crop-yield which can be extremely useful to farmers in planning for harvest and sale of grain harvest.
- To implement a machine learning algorithm that gives better prediction of suitable crop for the corresponding region and crop season in our country.
- A Crop Prediction System using a Machine Learning algorithm (Random Forest Algorithm, Decision Tree Algorithm, Support Vector Regression(SVR) Algorithm.) in which the farmers are helped with a crop recommendation by knowing the type of the soil and location, the intended time of sowing and the crop type.
- The Proposed system will predict the most suitable crop for particular land based on soil contents and weather parameters such as Temperature, Humidity, soil PH and Rainfall define the target for a model.
- After data cleaning the dataset will be split into training and test set by using sklearn library.
- Machine learning predictive algorithms has highly optimized estimation has to be likely outcome based on trained data.
- Predictive analytics is the use of data, statistical algorithms and machine learning techniques to identify the likelihood of future outcomes based on historical data.
- The goal is to go beyond knowing what has happened to providing a best assessment of what will happen in the future.
- In our system we used supervised machine learning algorithm having subcategories as classification and regression. Classification algorithm will be most suitable for our system
V. ALGORITHM USED
Random Forest Algorithm,Decision Tree Algorithm, Support Vector Regression(SVR)Algorithm.
A. Modules
- Login
- Upload
- Preview
- Prediction
- Analysis
- Chart
B. Project Screen Shots
- Home Page
2. User Dashboard Page
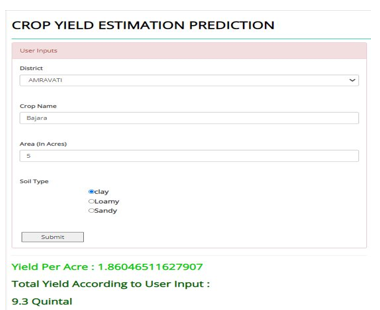
3. Result Page
VI. ACKNOWLEDGEMENT
First and foremost, I would like to express my sincere gratitude to my Dr.S. R. Guptawho has in the literal sense, guided and supervised me. I am indebted with a deep sense of gratitude for the constant inspiration and valuable guidance throughout the work.
Conclusion
We proposed a new approach for the crop yield prediction system. We used a crop yield dataset having the yield production record from year 1997 to 2014. We successfully implement the random forest algorithm to predict the yield of the crop by using attributes like soil type, district, area etc.The approach was flexible, and can be extended to the needs of the users in a better manner
References
[1] SatishBabu (2013),\'A Software Model for Precision Agriculture for small and Marginal Farmers\'. At the International Centre for and Open Source Software(ICFOSS) Trivandrum, India [2] Paper Title: Crop Prediction using Machine Learning Approaches Author Name: Mahendra N, Dhanush Vishwakarma, Nischitha K, Ashwini, Manjuraju M. R [3] Prof.D.S.Zingade, Omkar Buchade, Nilesh Mehta, Shubham Ghodekar, Chandan Mehta Crop Prediction System using Machine Learning [4] Himani Sharma, Sunil Kumar A Survey on Decision Tree Algorithms of Classification in Data Mining. [5] Hem Jyotsana Parashar, Singh Vijendra, and Nisha Vasudeva, “An Efficient Classification Approach for Data Mining”, International Journal of Machine Learning and Computing, Vol. 2, No. 4, pp. 446-448, 2012. [6] T.Sathya Devi, Dr.K.Meenakshi Sundaram, “ A Comparative Analysis Of Meta And Tree Classification Algorithms Using Weka”, International Research Journal of Engineering and Technology (IRJET), Vol.3 No.11, pp. 77-83, 2016. [7] Bendi Venkata Ramana, Prof. M.Surendra Prasad Babu, Prof. N. B. Venkateswarlu, “A Critical Study of Selected Classification Algorithms for Liver Disease Diagnosis”, International Journal of Database Management Systems( IJDMS ), Vol.3, No.2, pp. 101-114, 2011. [8] SweetyManiar, Jagdish S. Shah, “Survey and Comparison of Classification Algorithm for Medical Image”, International Journal of Engineering And Computer Science, Vol.5, No.8, pp.17679-17684, 2016. [9] P.Kalaiselvi, Dr.C.Nalini, “A Comparative Study of Meta Classifier Algorithms on Multiple Datasets”, International Journal of Advanced Research in Computer Science and Software Engineering, Vol.3, No.3, pp. 654-659, 2013. [10] Anita Ganpati, “A Performance Comparison Of End, Bagging and Dagging Meta Classification Algorithms”, Proceedings of Academics World 24th International Conference, 2016.
Copyright
Copyright © 2022 Miss. Komal K Khandare, Dr. S. R. Gupta. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET41724
Publish Date : 2022-04-22
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online