

Ijraset Journal For Research in Applied Science and Engineering Technology
Indian Food Image Classification Using Convolutional Neural Network
Authors: R. Shailaja, P. Rohith, R. Prem Kumar, K. Kannaki
DOI Link: https://doi.org/10.22214/ijraset.2023.55680
Certificate: View Certificate
Abstract
Food classification using Convolutional Neural Networks (CNNs) has gained significant attention due to its potential applications in dietary analysis, food recommendation systems, and nutrition monitoring. In this study, we present a CNN-based approach for food classification, leveraging image data augmentation to enhance the model\'s ability to generalize to new and unseen food images. We utilize a dataset containing diverse food categories and preprocess the images by resizing and normalization. The proposed CNN architecture consists of multiple convolutional and pooling layers, along with dropout and batch normalization for regularization. To prevent overfitting, we employ early stopping as a custom callback during model training. The experimental results demonstrate promising training accuracy of 90.13% and relatively low training loss of 0.3066, indicating effective learning from the training data. the validation accuracy of 69.00% and validation loss of 1.270.
Introduction
I. INTRODUCTION
Indian Food Classification using Convolutional Neural Networks (CNNs) has gained significant attention for its potential impact on dietary analysis, personalized nutrition, and food recommendation systems. With the exponential growth of food-related images shared on social media, blogs, and restaurant review platforms, automated food recognition has become crucial for understanding eating habits and promoting healthier choices.
However, food classification poses challenges due to the wide variation in appearance caused by different cooking styles, ingredient combinations, and food presentations. CNNs have shown great promise in image classification tasks, including food recognition, but they require large and diverse datasets for effective learning. Obtaining such datasets can be challenging, leading to potential overfitting on limited data.
To address these issues, image data augmentation techniques are employed to increase the diversity of the training dataset artificially. By applying random transformations like rotations, zooming, and flips, the CNN is exposed to various variations of the same food images, reducing the risk of overfitting and improving generalization to unseen data.
In this work, we propose a CNN-based food classification approach that leverages image data augmentation to enhance the model's accuracy on diverse food categories. We use a carefully preprocessed dataset of food images and design a CNN architecture with specialized layers for effective feature extraction and regularization. To prevent overfitting, we introduce an early stopping mechanism during training. In this work, we have set the callback value for the training loss at 0.3066.
The structure of this paper is as follows: Section 2 provides an overview of related work in the field of food classification using CNNs and image data augmentation techniques. Section 3 details the methodology, including the dataset, preprocessing steps, CNN architecture, and data augmentation strategy. Section 4 presents the experimental setup and analyzes the results obtained from model training and evaluation. Section 5 concludes the paper, outlining future research directions to advance the field of a food classification using Convolutional Neural Network.
II. LITERATURE SURVEY
Convolutional Neural Networks (CNNs) have become widely popular in food recognition applications, surpassing traditional machine learning methods in terms of performance. Numerous studies have successfully utilized CNNs for food recognition.
In [1], the authors altered the AlexNet model's architecture, which was first described in [2], and created a deep CNN using images from the Food-101 dataset. This novel strategy attained a top-1 accuracy of 56.4%, which is astounding. The use of CNNs for food recognition and identification across ten food groups in [3] is another noteworthy contribution. The outcomes demonstrated CNNs' exceptional performance, with a detection accuracy of 73.7% when compared to traditional techniques.
On the UEC-FOOD-100 dataset [5], which contains 100 Japanese food classifications, CNNs were the only feature extractors employed in [4]. This method's accuracy of 72.3% was outstanding. The outputs from a pre-trained AlexNet model and manually created features were combined to create the feature maps.
A new food dataset was unveiled in [4], which included photos that were gathered from open social media sites like Instagram. This dataset produced a CNN classification performance that was comparable to previous datasets, with a remarkable accuracy of 99.1%.
III. METHODOLOGY
A. Dataset
The Food classfication is trained by a dataset named as Indian food classification. It contains 6269 images belong to 20 food categories from the Indian food classification dataset has been considered for the classification. These 20 food categories from the Indian food classification dataset are burger, butter_naan, chai, chapati, chole_bhature, dal_makhani, dhokla, fried_rice, idli, jalebi, kaathi_rolls, kadai_paneer, kulfi, masala_dosa, momos, paani_puri, pakode, pav_bhaji, pizza, samosa. In this dataset, 80% of data is used for training and 20% of data is used for validation.
B. Data Preprocessing
Before feeding the images into the CNN model, several preprocessing steps are applied to standardize and facilitate model learning. The images are resized to a fixed size of 64x64 pixels to ensure uniformity in the input data. Additionally, pixel values are normalized to the range [0, 1] by dividing each pixel value by 255. This normalization process helps in stabilizing the training process and improving convergence.
C. Convolutional Neural Network Architecture
The proposed CNN architecture is designed to effectively extract features from food images for accurate classification. The architecture consists of multiple layers, including convolutional layers, pooling layers, dropout layers, and batch normalization layers.
The CNN model starts with a convolutional layer with 32 filters of size (3, 3) and a ReLU activation function. The stride is set to 1, and padding is applied to maintain the spatial dimensions.
A max-pooling layer with a pool size of (2, 2) and stride of 2 follows the first convolutional layer to downsample the feature maps and reduce computational complexity. Subsequently, another convolutional layer with 64 filters and a ReLU activation function is applied. Dropout with a rate of 0.2 is introduced after the second convolutional layer to prevent overfitting during training. A max-pooling layer is then employed with the same specifications as before. The third convolutional layer consists of 128 filters and a ReLU activation function, followed by another max-pooling layer to downsample the feature maps further. Following the convolutional and pooling layers, the feature maps are flattened into a one-dimensional vector. This flattened vector is then passed through a fully connected dense layer with 512 units and a ReLU activation function to capture higher-level features and representations of the input images. To further prevent overfitting, a dropout layer with a rate of 0.3 is introduced after the dense layer. Finally, the output layer contains a number of units equal to the number of food classes, with a softmax activation function to produce the probability distribution over the classes.
D. Image Data Augmentation
Image data augmentation is a crucial technique employed to enhance the model's generalization and prevent overfitting. During model training, the ImageDataGenerator class from Keras is used to apply various transformations to the input images. The transformations include random rotations, zooming, horizontal and vertical shifts, and horizontal flips. These augmented images, along with the original images, create a more diverse training dataset, which helps the model learn more robust and representative features for accurate classification.

E. Model Compilation and Training
The model is compiled using the Adam optimizer, a popular choice for optimizing deep learning models. The categorical cross-entropy loss function is used as the training objective, as it is well-suited for multi-class classification problems.
During training, the model is fed batches of images generated by the ImageDataGenerator. The training process runs for a specified number of epochs (in this case, 100) with a batch size of 64. Early stopping is applied as a custom callback with a target loss value of 0.3129. This early stopping mechanism allows the training to halt if the specified target loss is achieved, helping to prevent unnecessary computations and potential overfitting.
IV. EVALUATION
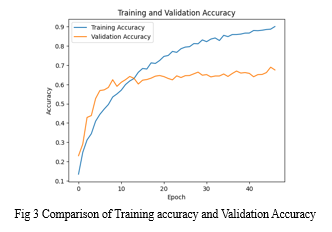
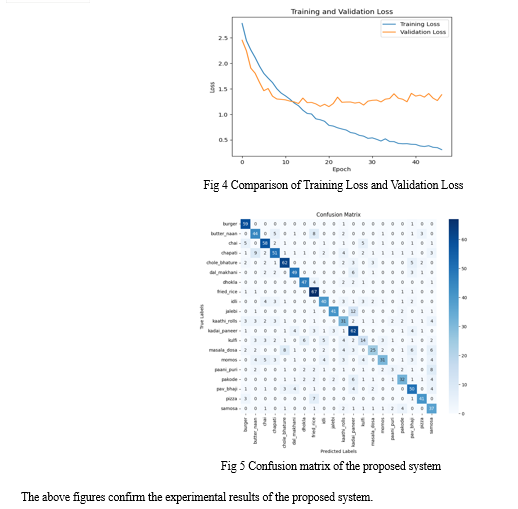
The model's performance is evaluated using various metrics, including training accuracy, training loss, validation accuracy, and validation loss. The training accuracy and training loss measure the model's performance on the training dataset, while the validation accuracy and validation loss assess its generalization on unseen data from the validation dataset. Additionally, the confusion matrix is computed to analyse the model's performance on individual food classes. This matrix provides insights into the number of true positive, true negative, false positive, and false negative predictions for each class, enabling a detailed analysis of classification accuracy for different food categories.
Conclusion
In this research study, the Convolution Neural Network, a Deep learning technique is used to classify the Indian food image classification with their classes. The dataset considered here is Indian Food Classification. The experiment results promising training accuracy 90.13% and relatively low training loss 0.3066, indicating effective learning from the training data. the validation accuracy 69.00% and validation loss 1.270.
References
[1] L. Bossard, M. Guillaumin, and L. Van Gool, “Food-101–mining discriminative components with random forests,” in European Conference on Computer Vision, 2014, pp. 446–461. [2] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in neural information processing systems, 2012, pp. 1097–1105. [3] H. Kagaya, K. Aizawa, and M. Ogawa, “Food detection and recognition using convolutional neural network,” in Proceedings of the 22nd ACM international conference on Multimedia, 2014, pp. 1085–1088. [4] Y. Kawano and K. Yanai, “Food image recognition with deep convolutional features,” in Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication, 2014, pp. 589–593. [5] Y. Matsuda, H. Hoashi, and K. Yanai, “Recognition of multiple-food images by detecting candidate regions,” in Multimedia and Expo (ICME), 2012 IEEE International Conference on, 2012, pp. 25–30 [6] H. Kagaya and K. Aizawa, “Highly accurate food/non-food image classification based on a deep convolutional neural network,” in International Conference on Image Analysis and Processing, 2015, pp. 350–357 AUTHOR’S DETAILS 1. Independent researcher, Tamil Nadu, India, shailajar1404@gmail.com. 2. Independent researcher, Tamil Nadu, India, itsmerohu31@gmail.com. 3. Independent researcher, Tamil Nadu, India, prekumar30@gmail.com. 4. Independent researcher, Tamil Nadu, India, kannaki.abi01@gmail.com.
Copyright
Copyright © 2023 R. Shailaja, P. Rohith, R. Prem Kumar, K. Kannaki. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET55680
Publish Date : 2023-09-09
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online