

Ijraset Journal For Research in Applied Science and Engineering Technology
A Review: Informing Disasters management by Using Twitter Tweets
Authors: Ashish Vijay Naikwade
DOI Link: https://doi.org/10.22214/ijraset.2022.41916
Certificate: View Certificate
Abstract
Recently social media plays a major role and providing information during disasters. This paper mainly focuses on how people used social media, especially Twitter, in response to the country\'s worst flood, Earthquake that had occurred recently. And these tweets collecting analyzed using machine learning algorithms such as Naïve Bayes, Random Forests, Decision Tree, sentiment Analysis during the disaster social media provides a surplus of information which includes information about the natural disaster, affected people\\\'s emotions, and relief efforts. And collect the tweets relating to disasters and build the sentimental classifier to categorize the user’s emotions during disaster based on various distress levels. Various analysis techniques are applied in collecting tweets.
Introduction
I. INTRODUCTION
Microblogging can form a short chat that allows the user to share chat messages by using the internet. There are many microblogging services available such as Twitter, Facebook, what's app, etc. But my focus on this research paper is only on Twitter tweets, which allows only short message means tweets these tweets are generally 140 characters or less. Microblogging is mainly focused on sharing information and tracking general people's opinions during any social, political, Natural Disaster, etc. During any event of a natural disaster, social media has gained a lot of attention and additional crisis communication. And Twitter is most popular in microblogging sites by users sharing the messages, photos, videos for that disaster crises site globally. Twitter is real-time data generated by the user community. The behavior and emotions that users express from natural disaster crises site to be distributed to users across the globe.
II. RELATED WORK
Twitter plays a major role transmit information during natural disasters. The various methods and techniques are used to extract data from Twitter are described below
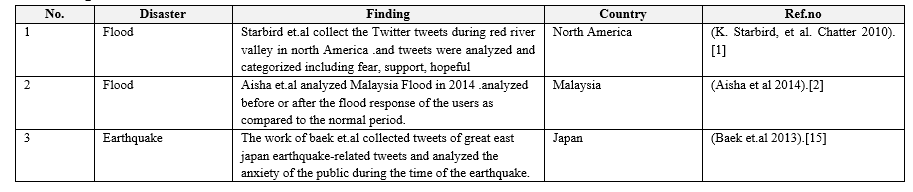
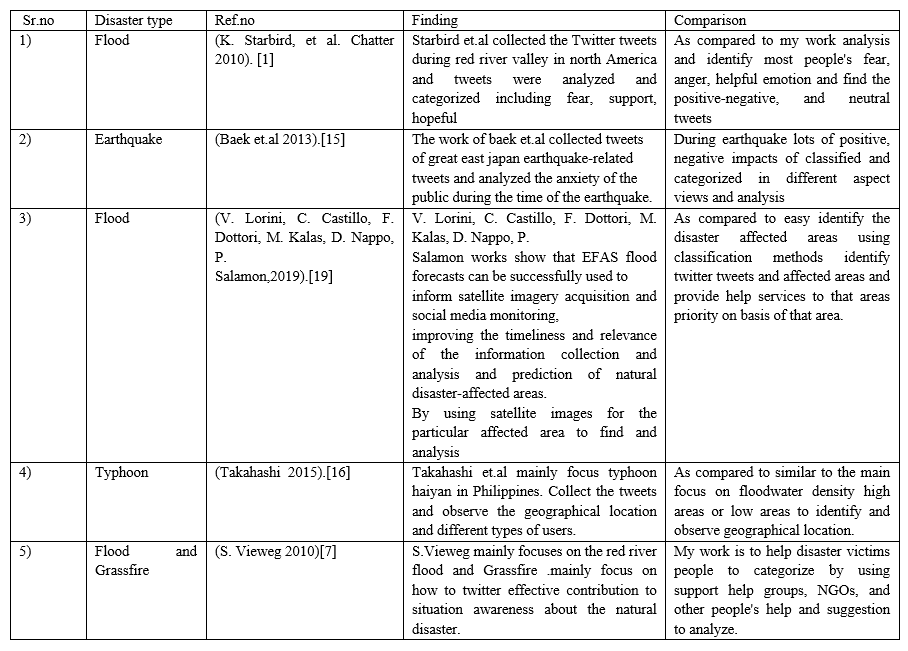
The work of Starbird, chatter used Twitter during the red river flood in central North America [1] They have collected all the tweets regarding the Red River Flood using the keyword #redriver. And each tweet contains such as a tweet, retweet, geographical location approximation distance from the event, and tweets analysis under one of the following categories hopeful, fear, support, and humor.
The work of T.S.Aisha[2] mainly focuses on the 2014 Malaysia Flood that had fully destroyed Malaysia. the number of tweets messages during the flood period was very high as compared to the normal period. This mainly focuses on the satisfaction gained by the Twitter user from sharing information during the flood. most useful data for this work in [8],[9], and[10] analysis of user emotion and distributing the geographical location by using Twitter tweets.
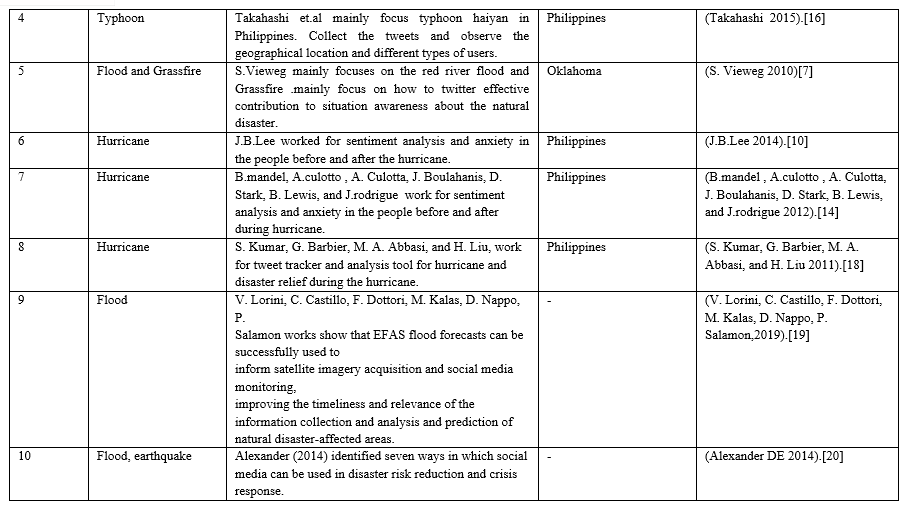
Twitter is the best channel for a communication system for natural disasters [13]. Another people's sentiment analysis for disaster victim emotion and relief measurement [14].
Following Related Work as below
III. METHODS
A. Naive Bayes
Naive Bayes is a classification technique that gives prime importance to conditional independency between predictors. It is based on the assumption that all the attributes are conditionally independent. It is a statistical classifier that performs probabilistic prediction that predicts the class membership probabilities. Classification is based on Bayes Theorem. It is very useful for high-dimensional datasets and they are easy to build. The posterior probability P(c|x) is calculated from the likelihood P(x|c), class prior probability P(c), and predictor prior probability P(x). P(c|x) = (P(x|c) ∗ P(c))/P(x). Features of Naive Bayes are
- Prediction of a class for a test set is simple and easy.
- Multiclass prediction is a key feature of Naive Bayes.
- Class conditional independency is a limitation of Naive Bayes. This is because in real life it is difficult to get completely independent class predictors.
- It works well for categorical data than numerical data
IV. DECISION TREE
The decision tree is a graph .and a decision tree is a branching method to exhibit every possible output for the decision
The tree is constructed in a top-down recursive divide and conquer manner. Initially, all the training samples are placed as the root element. They are partitioned recursively based on the selected attribute. The decision tree mainly consists of 2 nodes namely leaf nodes and decision nodes. A decision node or internal node contains 2 or more subspaces or branches, where each denotes the test on a particular attribute. Leaf node contains the resulting class label, classification, or decision. The decision tree is a classification technique that can handle both numerical and categorical data.
V. RANDOM FORESTS
Random Forests is a machine learning algorithm used for both classification and regression. It is an ensemble learning method that involves the construction of multiple decision trees. Collections of decision tree classifiers are called Forests. Individual decision trees are generated during the training time by the random selection of attributes in each node, which will determine the split.
Each tree will give a classification result that is, all the decision trees will give their vote individually. The forests choose the most popular class. Benefits of Random Forests classification algorithm are:
- Random Forests can handle data that contain outliers.
- It is not mandatory that data need to be pre-processed. They can handle missing values automatically.
- They have a high tolerance to overtraining.
- Random Forests can be built in a faster manner.
- Takes less time to predict the output.
VI. COMPARISON OF PREVIOUS WORK ANALYSIS
VII. ANALYSIS SYSTEM
- Tweeter Data Collection: Data collection with the help of data API. This API collect live or flood, Earthquake disaster-related keywords collect disaster related tweet, retweet, geographical location, likes, followers, etc.
- Sorting: Sorting data in different disaster categories like a flood, Earthquake, Forest fire than to sort data in different attributes needed for help, Relief measure NGO, complaints, suggestion, and most Affected area and worst area and low affected areas to analysis and identify and sort, etc.
- Preprocessing: After that collect the pure data remove a bag of words or unused symbols, numbers, the text then collects the pure data and is ready to preprocess data using
- Classification Data: After that collect data the first step is to segregate data .like floods, earthquakes, Forest fires. After that classify different aspect-wise tweets and sentiment analysis of users.
- Analysis Data: By using Methods analysis for result showing output. And sentiment analysis of people. And frequency determines and analysis of geographical area accuracy and result.
VIII. DATASET DESCRIPTION
Twitter social media is the source of the dataset. The dataset of the text mining data set collects tweets, retweets, likes, followers, and comparisons on a count of tweets. disaster-related data for flood, forest fires, Earthquake, and sentiment analysis of people
Conclusion
This paper presents a systematic Literature review on disaster management. And used a total of 20 research papers on this field and reviewed their proposed system and manage the disaster victims and sentiment analysis of disaster victims save people\\\'s lives in the future situation how to manage and precautions that type of situation and Twitter helps to identify the most disaster-affected area and low affected area are easily find and provide help and Twitter Social media plays a major role in Natural Disaster Management help for society and government for quick action in future work.
References
[1] K. Starbird, et al. Chatter on the red: what hazards threat reveals about the social life of microblogged information. In: Proceedings of the 2010 ACM conference on Computer supported cooperative work 2010; 241–250 [2] T.S. Aisha, et al. Exploring the use of social media during the 2014 flood in Malaysia. Procedia-Social and Behavioral Sciences 2015; 211: 931–937. [3] Y. Huang, et al. A scalable system for community discovery in Twitter duriAng hurricane sandy. In: Cluster, Cloud, and Grid Computing (CCGrid), 2014 14th IEEE/ACM International Symposium on 2014; 893–899. [4] K. Kandasamy, P. Koroth. An integrated approach to spam classification on Twitter using URL analysis, natural language processing, and machine learning techniques. In: Electrical, Electronics and Computer Science (SCEECS), 2014 IEEE Students Conference on 2014; 1–5. [5] H. Dong, et al. Social media data analytics applied to hurricane sandy. In: Social computing (SocialCom), 2013 international conference on IEEE. 2013; 963–966. [6] S.R. Kalmegh. Comparative analysis of weka data mining algorithm random forest, random tree, and bad tree for classification of indigenous news data. International Journal of Emerging Technology and Advanced Engineering 2015;5(1): 507–517 [7] S. Vieweg, et al. Microblogging during two natural hazards events: what Twitter may contribute to situational awareness. In: Proceedings of the SIGCHI conference on human factors in computing systems. ACM 2010; 1079–1088. [8] R. E. Cohn and W. A. Wallace, The Role of Emotion in Organizational Response to a Disaster: An Ethnographic Analysis of Videotapes of the Exxon Valdez accident. Natural Hazards Research and Applications Information Center, Institute of Behavioral Science, University of Colorado, 1992 [9] B. Mandel, A. Culotta, J. Boulahanis, D. Stark, B. Lewis, and J. Rodrigue, “A demographic analysis of online sentiment during hurricane irene,” in Proceedings of the Second Workshop on Language in Social Media. Association for Computational Linguistics, 2012, pp. 27–36. [10] J. B. Lee, M. Ybanez, M. M. De Leon, and M. R. E. Estuar, “Under- ˜ standing the behavior of Filipino Twitter users during the disaster,\\\" Journal on Computing (JoC), vol. 3, no. 2, 2014. [11] S. Srivastava. Weka: a tool for data preprocessing, classification, ensemble, clustering, and association rule mining. International Journal of Computer Applications 2014; 88(10). [12] J. B. Lee, M. Ybanez, M. M. De Leon, and M. R. E. Estuar, “Under- ˜ standing the behavior of Filipino Twitter users during the disaster,\\\" Journal on Computing (JoC), vol. 3, no. 2, 2014 [13] J. Sutton, L. Palen, and I. Shklovski, “Backchannels on the front lines: Emergent uses of social media in the 2007 southern California wildfires,” in Proceedings of the 5th International ISCRAM Conference. Washington, DC, 2008, pp. 624–632. [14] B. Mandel, A. Culotta, J. Boulahanis, D. Stark, B. Lewis, and J. Rodrigue, “A demographic analysis of online sentiment during hurricane irene,” in Proceedings of the Second Workshop on Language in Social Media. Association for Computational Linguistics, 2012, pp. 27–36 [15] S.J. Baek, et al. Disaster anxiety measurement and corpus-based content analysis of crisis communication. In: Systems, Man, and Cybernetics (SMC), 2013 IEEE International Conference on 2013; 1789–1794. [16] B. Takahashi, et al. Communicating on Twitter during a disaster: An analysis of tweets during typhoon Haiyan in the Philippines. Computers in Human Behavior 2015; 50 392–398. [17] A. Bruns, Y.E. Liang. Tools and methods for capturing Twitter data during natural disasters. First Monday 2012; 17(4). [18] S. Kumar, G. Barbier, M. A. Abbasi, and H. Liu, “Tweettracker: An analysis tool for humanitarian and disaster relief.” in ICWSM, 2011 [19] V. Lorini, C. Castillo, F. Dottori, M. Kalas, D. Nappo, P. Salamon, Integrating Social Media into a Pan-European Flood Awareness System: A Multilingual Approach, Proceedings of the 16th ISCRAM Conference – València, Spain, (2019). [20] Alexander DE 2014, Social Media in Disaster Risk Reduction and Crisis Management, Science and Engineering Ethics, vol. 20, no. 3, pp. 717–733
Copyright
Copyright © 2022 Ashish Vijay Naikwade. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET41916
Publish Date : 2022-04-27
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online