

Ijraset Journal For Research in Applied Science and Engineering Technology
Review of Machine Learning Techniques for Crop Recommendation System
Authors: Prof. Meena Ugale, Nimeesha Venkatavelu, Pranay Patil, Suraj Rane
DOI Link: https://doi.org/10.22214/ijraset.2022.40559
Certificate: View Certificate
Abstract
The Indian population is highly dependent on agriculture for vegetables, fruits, grains, natural textile fibres like cotton, jute, and many more. Also, the agricultural sector plays a vital role in the economic growth of the country. The agriculture sector is contributing around 19.9 percent since 2020-2021. As a result, agricultural production in India has a significant impact on employment. The soil in India has been in use for thousands of years, resulting in depletion and exhaustion of nutrients and minerals, which leads to a reduction of crop yield. Also, there is a lack of modern applications, which causes a need for precision agriculture. Precision Agriculture, also known as Satellite farming is a series of strategies and tools to manage farms based on observing, measuring, and responding to crop variability both within and between fields. One of the main applications of precision agriculture is the recommendation of accurate crops. It helps in increasing crop yield and gaining profits. This paper aims to review and analyse the implementation and performance of various methodologies on crop recommendation systems.
Introduction
I. INTRODUCTION
About 58% of India's population depends on the agricultural sector for their livelihood. India is the world's second-largest producer of key food staples such as wheat and rice, diverse agriculture-based textile raw materials, coconut, sugarcane, various kinds of dry fruits, and an end number of vegetables and fruits. The agriculture sector plays a crucial role in the development of the country's economy. Precision agriculture i.e., site-specific farming is one of the many techniques brought in to improve the health of the crops and reduce potential environmental risks.
One of the main domains in precision agriculture is the recommendation of crops to increase crop yield. The suggestion of crops helps in increasing the productivity of crops without the consumption of too many resources in the process. The main objective of precision farming is profitability and sustainability. It also helps the farmers acquire knowledge to determine the diseases that the crops could get infected by in advance using different methods of precision farming. The inputs given to the models are characteristics of soil, rainfall, humidity, and temperature of the environment. Based on those parameters provided as the input, the farmer gets suggested the most suitable crop for their field to achieve the maximum crop yield.
The agriculture sector started using Machine Learning algorithms and the Internet of Things to solve problems including low crop yields, irrigation, and loss of nutrients and minerals in the soil. Using Arduino microcontrollers and sensors, such as sunlight intensity sensors, soil moisture sensors, soil pH sensors, and humidity and temperature sensors, IoT is used to collect environmental data. The gathered data is sent to the database by connecting the sensors to the Arduino Wifi Module. A supervised learning algorithm is a form of machine learning method in which machines are trained using the training data and then used to predict the output. The labeled data indicates that some of the input data have already been tagged with the appropriate result. Unsupervised learning algorithms are a subclass of machine learning algorithms that train models on unlabeled data before allowing them to operate on it without supervision. Unsupervised learning aims to uncover a dataset's underlying structure, categorize data based on similarities, and display it in a compact way.
Naive Bayes, Support Vector Machine (SVM), Decision Tree, KNN, Multiplayer-layer Perceptron, ID3, J48, JRIP, BPN, Random Forest, ANN, Linear Regression, Neural Network, Chaid and Kohonen Self Organizing Map are the different kinds of supervised learning algorithms and unsupervised learning algorithms used in the systems. Various methods, such as Natural Language Processing, ensemble methods like majority voting, and others, are used to develop machine learning models. Ensemble technique is a type of machine learning methodology that helps integrate numerous base models to create the single best-fit predictive model. The predictions generated by the classification models are summed or use regression models that are averaged in a voting ensemble.
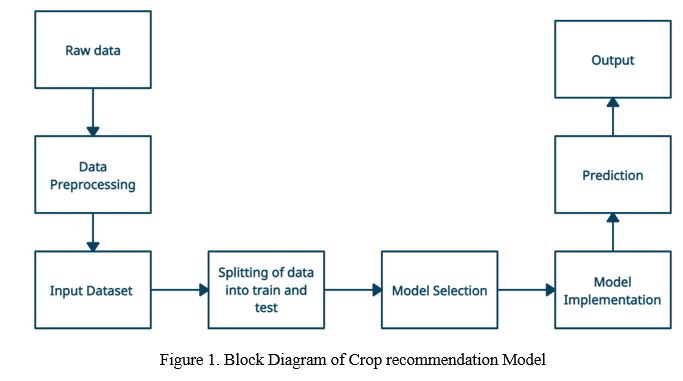
The block diagram depicts the basic stages involved in creating the machine learning model above. The system's first stage involves cleaning and processing raw data. Crop data and fertilizer data are combined in this process to produce a final dataset. This dataset is then separated into training and testing data and utilized as input to the system. Model selection is the process of comparing various classification models in order to find the best appropriate one. The most suited crops are predicted, and the output is used for the following.
II. RELATED WORK
A. Crop recommendation using machine learning or deep learning
Crop Recommendation Systems use inputs of soil parameters like the ratio of Nitrogen, the ratio of Phosphorous, the ratio of Potassium and ph value of the soil, environmental factors such as humidity, rainfall, temperature, and many more.
The paper [3] displayed by Kiran Shinde, Jerrin Andrei, and Amey Oke proposes a crop recommendation system by comparing Naive Bayes, ID3, and Random Forest algorithms. The Random Forest algorithm is utilized to create the model, which is more accurate than the Naive Bayes and ID3 algorithms. The paper also proposes two more systems: fertilizer recommendation and crop rotation guidance. The crop rotation recommendation model is developed by using the FP algorithm. The fertilizer recommender calculates all of the fertilizer combinations that will suit the crop's needs at the lowest cost. Farmers can use the web and Android-based mobile devices to access the system.
S.Pudumalar, E.Ramanujam, R.Harine Rajashree?, C.Kavya?, T.Kiruthika?, J.Nisha? in paper [5] build a model using one of the most familiar ensembling techniques called the majority voting technique. Rather than using a single methodology, the ensemble method allows you to create a more accurate model by mixing several techniques. The technique uses different base learners such as Random Forest Tree, Chaid, K-Nearest Neighbor, and Naive Bayes, which makes a prediction model by combining the strengths of all the algorithms to bring out the best accuracy for building the model.
The architecture put forward by the paper [6] employs a majority voting technique which is the most common type of ensembling technique. Multi-layer Perceptron (Artificial Neural Network), Support Vector Machine, Random Forest, and Naive Bayes are the base learners used for creating the model. The base learners are selected in a manner that they are capable of and complimentary to one another, i.e., if one of the algorithms makes an error, the other algorithms will be able to rectify it.
Crop suitability and rainfall predictors make up the crop recommendation system developed by Zeel Doshi, Subhash Nadkarni, Rashi Agrawal, and Prof. Neepa Shah in their study [7]. The Linear Regression algorithm model helps predict the rainfall and displays rainfall of 12 months of a particular state. Supervised learning algorithms such as Random Forest, Decision Tree, Neural Network, and K-NN are compared against one another to get the most suitable algorithm with the highest accuracy score. The Neural Network approach, which has a 91 percent accuracy score, is then used to develop a model for the crop recommendation system. The month-wise rainfall prediction data is provided into the crop recommendation system's training model, which would then be combined to suggest the most suited crops.
Nidhi H Kulkarni, Dr. G N Srinivasan, Dr. B M Sagar, Dr.N K Cauvery in paper [8] provides a model for the crop recommendation system that uses a majority voting technique which is a kind of ensembling technique. The ensemble model has been brought forward using three independent base learners: Random Forest, Naive Bayes, and Linear SVM. Each of the samples from the data is trained and tested on the algorithms. The ensembling technique yielded a 99.91% accuracy score.
Rushika Ghadge, Juilee Kulkarni, Pooja More, Sachee Nene, and Priya R L in paper [9] proposed a system that checks soil quality to predict the crop suitable for cultivation based on soil type and maximize crop production by providing the right fertilizer. Unsupervised learning algorithms like Kohonen Self-Organizing Map are compared to supervised learning algorithms like Back Propagation Network. The algorithm with the highest accuracy is delivered to produce the model for the system.
Pavan Patil, Virendra Panpatil, Prof. Shrikant Kokate have used supervised learning algorithms such as Decision Tree, Naive Bayes, and KNN in paper [13]. The following are compared against each other, and the KNN algorithm seems to have the best precision, and the decision tree has the best accuracy. When a dataset has many variabilities, decision trees perform poorly, yet Naive Bayes performs better than decision trees in such cases. Combination classification algorithms, such as Naive Bayes and decision tree classifiers, outperform single classifier models.
Pradeepa Bandara, Thilini Weerasooriya, Ruchirawya T.H., W.J.M. Nanayakkara, Dimantha M.A.C., and Pabasara M.G.P. propose a system in which Arduino microcontrollers assist in the collection of environmental factors and supervised and unsupervised learning algorithms such as Naive Bayes, Support Vector Machine, and Natural Language Processing are implemented in paper [14]. Sunlight intensity sensor, soil moisture sensor, soil pH sensor, and humidity and temperature sensor are the sensors used in collecting the climate factors.
B. Crop Recommendation Using Natural Language Processing
NLP refers to the automatic processing of natural human language such as speech or text, and while the concept is intriguing, the real value of this technology is found in its applications. In essence, it generates an occurrence matrix for the sentence or text, ignoring syntax and word order. The frequency or occurrences of these words are subsequently employed as features in the training of a classifier.
C. Crop Recommendation Using Ensemble Technique
Ensemble methods are a machine learning method that helps combine multiple base models to produce a single best-predictive model. The majority voting ensemble, also known as voting ensemble, is one of the most often used ensemble algorithms for crop recommendation systems. It's a machine learning model that integrates predictions from a variety of other models. It is a strategy that can be used to increase model performance, to outperform any one model in the ensemble.
III. A COMPARATIVE STUDY OF CLASSIFICATION ALGORITHMS
A. Naive Bayes Algorithm
The Naive Bayes method is a type of supervised learning algorithm that is used for addressing classification issues that is based on the Bayes theorem. The simplest method you may use to analyse your data is Naive Bayes. This approach assumes that the dataset's variables are all "Naive", i.e., uncorrelated. It can be used to estimate the data distribution, but the Gaussian (or Normal) distribution is the simplest to deal with because all you have to do is estimate the mean and the standard deviation from the data being trained.
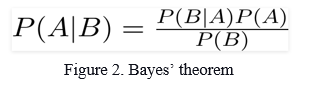
where,
P(A|B) is the Posterior probability: Probability of hypothesis A on the observed event B.
P(B|A) is the Likelihood probability: Probability of the evidence given that the probability of a hypothesis is true.
To understand the above equation in a simpler way, the above equation can be written as
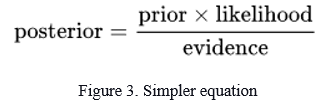
4. Support Vector Machine
The Support Vector Machine (SVM) is a supervised learning approach widely used in text classification, picture classification, bioinformatics, and other fields. The problem space in Linear SVM must be linearly separable.
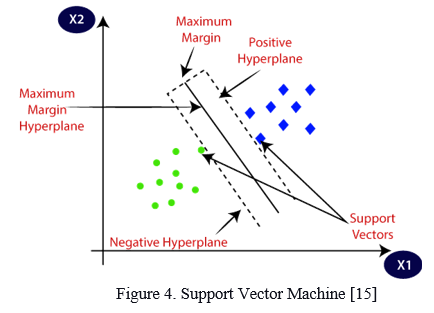
The model generates a hyperplane that maximizes the classification margin. In an n-dimensional Euclidean space, a hyperplane is a flat, n-1-dimensional subset that separates the space into two separate portions. Support vectors are the boundary nodes in the feature space. The greatest margin is calculated based on their relative positions, and an ideal hyperplane is drawn in the midpoint. When the dataset is not linearly separable, non-linear SVM is used. For all of the training data, a kernel function is utilized to generate a new hyperplane. Training data will be linearly separable due to the distribution of labels in the new hyperplane. Later, the labels in the hyperplane will be classified using a linear curve. We get a non-linear solution when we project the classification results back to the feature space.
C. Kohonen’s SOM (Self-Organizing Map)
The fact that the entire learning takes place without supervision, i.e., the nodes self-organize, is a significant feature. They're also known as feature maps because they're essentially retraining the features of the incoming data and just grouping themselves based on their similarity. This is useful for visualizing complex or massive amounts of high-dimensional data and displaying the relationships between them in a low-dimensional, usually two-dimensional, field to determine if the unlabeled data has any structure. The grid is the map that organizes itself at each iteration based on the input data.
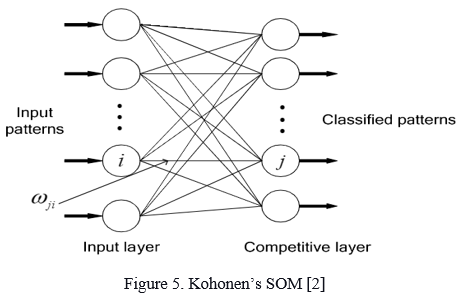
Weight initialization is the first step to take place for the algorithm. Then a for loop from 1 to N number of epochs gets implemented. Selection of a training example takes place. The next few steps are computing and updating the winning vector. Repeat the last three steps for all training examples and cluster the test sample.
D. Neural Network
A neural network is a set of algorithms that attempts to recognise underlying relationships in a batch of data using a method that mimics how the human brain works. Because neural networks can modify input, they can produce the best possible outcome without requiring the output criteria to be redesigned.
A neural network is analogous to the neural network in the human brain. In a neural network, a "neuron" is a mathematical function that collects and categorizes data using a specified design. The two statistical procedures that the network closely resembles are the curve fitting and regression analysis.
E. BPN (Back-Propagation Neural Networks)
The core of neural network training is backpropagation. It's a method for fine-tuning the weights of a neural network based on the error rate of the previous epoch (i.e., iteration). You may reduce error rates and increase the model's generalization by fine-tuning the weights, making it more trustworthy. In data mining and machine learning, it's a crucial mathematical tool for boosting prediction accuracy. Backpropagation is a technique that is used to swiftly calculate derivatives.
The chain rule is used by the back propagation method in neural networks to determine the gradient of the loss function for a single weight. Unlike native direct computation, it efficiently computes one layer at a time. It computes the gradient but doesn't specify how it'll be used. It generalizes the delta rule's computation.
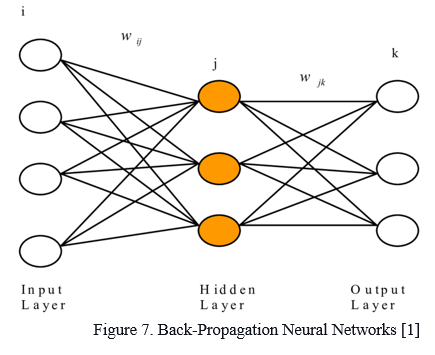
The diagram above is an example to help understand Back propagation neural network:
- X inputs arrive via a pre-connected path.
- The randomly selected real weights W is used to input the model
- We then calculate the output for each neuron, which starts from the input layer to the hidden layers, and the output layer.
- Calculate the error present in the outputs.
ErrorB= Actual Output – Desired Output
5. After calculating the errors present, return from the output layer to the hidden layer to change the weights to reduce the error.
6. Repeat the technique until you get the desired result.
F. Multi-layer Perceptron (Artificial Neural Network)
Artificial neural networks are sometimes simply referred to as neural networks or multi-layer perceptrons, after the most useful type of neural network. A perceptron is a model of a single neuron that serves as a forerunner to larger neural networks. It's a branch of computer science that looks into how simple models of biological brains may be utilized to address difficult computational problems like predictive modeling in machine learning. The goal is to construct strong algorithms and data structures that can be used to represent complex situations, rather than to produce realistic brain models.
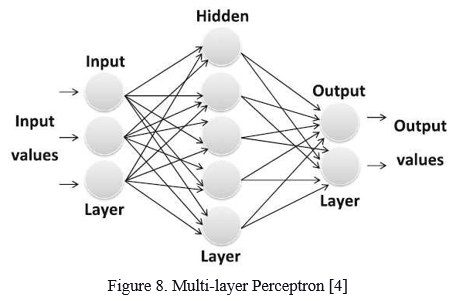
G. Decision Tree
The independent variables are used to create a decision tree, with each node having a condition over a feature. The algorithm begins at the tree's root node to predict the class of the specified dataset. In layman's terms, decision trees are a series of if-else statements. It checks to see if the condition is satisfied, and if it is, it moves on to the next node in the decision chain. Based on the condition, the nodes pick which node to travel to next. Output is expected once the leaf node is reached. The tree is efficient when the conditions are in the appropriate order. The criterion for selecting conditions in nodes is entropy/information gain. The tree structure is derived using a recursive, greedy-based technique.
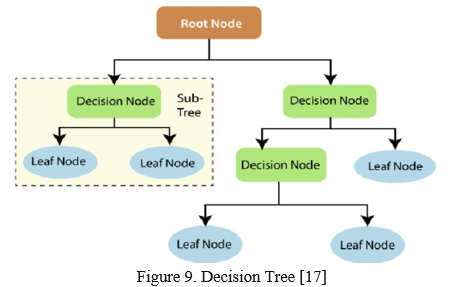
H. Random Forest Tree
To achieve classification and regression outputs, Random Forest uses a number of decision trees ensembled utilizing the "bagging approach". In classification, the result is derived using majority voting, whereas, in regression, the output is calculated using the mean. Random Forest produces a reliable, accurate model that can handle a wide range of input data types including binary, categorical, and continuous characteristics. The following supervised learning model handles overfitting efficiently. It supports implicit feature selection and determines the relevance of importance.
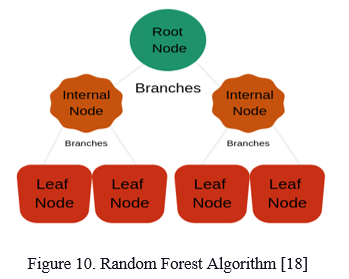
The initial step is the selection of random K data points from the training set. Then create decision trees for the data points chosen, i.e., the subsets. Decide on the number N for the decision trees you wish to generate. Replicate the two initial steps. Find the forecasts of each decision tree for new data points and allocate the up to the minute data points to the category with the most votes.
I. K-Nearest Neighbors
K-nearest neighbors is a non-parametric classification and regression technique. It's one of the most basic machine learning techniques. KNN's basic concept is to look at your neighborhood, suppose the test data point is comparable to them, and derive the result. We look for k neighbors and make a forecast using KNN. KNN classification uses majority voting over the k closest data points, whereas KNN regression uses the mean of the k closest data points as the output. The K value and distance function are the two hyperparameters that makeup KNN. The K parameter indicates how many neighbors should be included in the KNN algorithm. According to the validation error, the value of k should be modified. The most common similarity function used is Euclidean distance. Different possibilities include the Manhattan distance, Hamming distance, and Minkowski distance.
Assume there are two categories, Category A and Category B, and a new data item x1 is received. Which of the following categories does this data point belong in? This type of challenge necessitates the use of a K-NN method. We can determine the category or class of a dataset with the help of K-NN. Consider the diagram below:
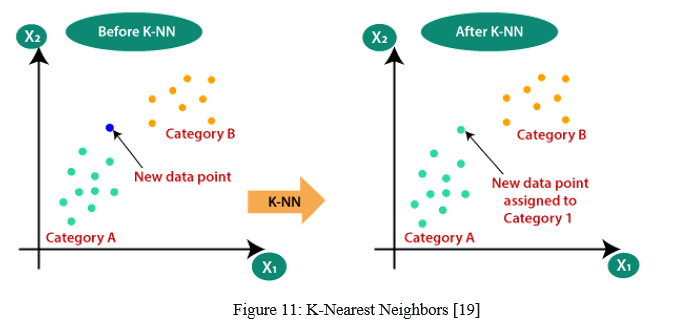
The initial step is to decide the number of neighbors (K). Then determination of the Euclidean distance between K neighbors takes place. Finding the K nearest neighbors using the Euclidean distance is the next step to be followed. Tally the number of data points in each category among these K neighbors. Assigning the new data points with the greatest number of neighbors to the category. We've completed our model.
TABLE I
Application of Machine Learning Algorithms in Crop Recommendation System
|
Year |
Study |
Application |
Techniques/Algorithms |
Performance Results |
|
2015 |
Kiran Shinde, Jerrin Andrei, Amey Oke [3] |
Web Based Recommendation System for Farmers |
|
The study recommends that Random Forest Tree be used to make recommendations to farmers for crops, crop rotation, and fertilizer selection. |
|
2016 |
S.Pudumalar, E.Ramanujam, R.Harine Rajashree?, C.Kavya?, T.Kiruthika?, J.Nisha? [5] |
Crop Recommendation System for Precision Agriculture |
|
The model has an accuracy of 88% in terms of prediction. |
|
2017 |
Rohit Kumar Rajak, Ankit Pawar, Mitalee Pendke, Pooja Shinde, Suresh Rathod,Avinash Devare [6] |
Crop Recommendation System to Maximize Crop Yield using Machine Learning Technique |
|
The following system helps recommend crops on the basis of Ensembling Technique which uses base learners such as SVM, Naive Bayes, Random Forest Tree and Multi-layer Perceptron algorithms. |
|
2018 |
Zeel Doshi, Subhash Nadkarni, Rashi Agrawal, Prof. Neepa Shah [7] |
AgroConsultant: Intelligent Crop Recommendation System Using Machine Learning Algorithms |
|
The system in the following paper provides a model made by the Neural Network which gives the best accuracy of 91% compared to the other algorithms. |
|
2018 |
Nidhi H Kulkarni, Dr. G N Srinivasan, Dr. B M Sagar, Dr.N K Cauvery [8] |
Improving Crop Productivity Through A Crop Recommendation System Using Ensembling Technique |
|
The system in the following paper uses Ensembling Technique to recommend crops to the users, which uses base learners such as Linear SVM, Naive Bayes and Random Forest Tree algorithms. |
|
2018 |
Rushika Ghadge, Juilee Kulkarni, Pooja More, Sachee Nene, Priya R L [9] |
Prediction of Crop Yield using Machine Learning |
|
Kohonen’s Self- Organizing Map and Back-Propagation Neural Networks are compared against each other, the algorithm with the best accuracy is used to recommend crops to increase crop yield. |
|
2020 |
Annapoorna.S, Apoorva Herle, C M Sushma, Neha.Y.Jain, Mr.Vijay Kumar.S [11] |
CRAPCSS-Crop Recommendation and Pest Control Suggestion System |
|
After performing feature selection based on different attributes, integration of the SVM model takes place. SVM in comparison to Logistic Regression provides a better accuracy of 97%. |
|
2020 |
Dr.A.K.Mariappan, Ms C. Madhumitha, Ms P. Nishitha and Ms S. Nivedhitha [12] |
Crop Recommendation System through Soil Analysis Using Classification in Machine Learning |
|
The accuracy provided by the KNN algorithm is 89% which is better than SVM as it provides an accuracy of 80%. |
|
2020 |
Pavan Patil, Virendra Panpatil, Prof. Shrikant Kokate [13] |
Crop Prediction System using Machine Learning Algorithms |
|
The K- Nearest Neighbor model gives the best accuracy compared to Decision Tree Algorithm is 89.4% |
|
2020 |
Pradeepa Bandara, Thilini Weerasooriya, Ruchirawya T.H., W.J.M. Nanayakkara, Dimantha M.A.C and Pabasara M.G.P [14] |
Crop Recommendation System |
|
It is clear from the data collected by sensors that the suggested system has a high level of accuracy and is suited for both rural and urban locations. |
|
2021 |
Palaniraj A, Balamurugan A S, Durga Prasad R,Pradeep P [20] |
Crop and Fertilizer Recommendation System using Machine Learning |
|
The model made using Support Vector Machine gives an accuracy of 90.01%, which helps in predicting the crops based on different N, P, K values, rainfall, temperature and location. |
TABLE III
Comparison between advantages and disadvantages of classifiers
|
Classifiers |
Advantages |
Disadvantages |
|
Naive Bayes |
|
|
|
Support Vector Machine |
|
|
|
Decision Tree |
|
|
|
K-Nearest Neighbors |
|
|
|
Random Forest |
|
|
|
Neural Network |
|
|
Conclusion
The review of research papers on the use of machine learning and deep learning algorithms showed that these techniques can be useful to assist farmers. Crop Recommendation, Crop rotation recommendation, Fertilizer Recommendation, and Rainfall Prediction were the most common systems created using the mentioned algorithms. Study [5] gives the prediction accuracy of 88% for the model. Neural Network provides the best accuracy of 91% compared to the other algorithms in study [7]. Study [11] shows the Support Vector Machine algorithm to be having a better accuracy than Logistic Regression of 97%. The K-Nearest Neighbors algorithm in Study [12] provides an accuracy of 89%, which is better in comparison to the Support Vector Machine algorithm which has an accuracy of 80%. Study [13] after comparison between different algorithms, shows that K-Nearest Neighbors has the best accuracy of 89.4%. This paper mainly reviews the advantages of each classifier and compares their compatibility for a crop recommendation system, from gathering the parameters required for the system to making the model that helps predict the most suitable crops. The inquiry demonstrates the abilities of various computations in predicting a few climate wonders, such as temperature, rainstorms, and precipitation, and concludes that real systems are capable of doing so. Based on the findings of this work, we believe that more research is needed in the agricultural industry to improve precision. Using group approaches is a good way to ensure that the framework is more precise.
References
[1] Mahesh Pal, “Factors influencing the accuracy of remote sensing classifications: a comparative study” Jan 2002 [2] Jicheng Ding, Jian Zhang, Weiquan Huang and Shuai Chen, “Laser Gyro Temperature Compensation Using Modified RBFNN”, Oct 2014. [3] Kiran Shinde, Jerrin Andrei, Amey Oke, “Web Based Recommendation System for Farmers”, IJRITCC, Volume 3, March 2015. [4] Ghazi Al-Naymat, Mouhammd Alkasassbeh, Nosaiba Abu-Samhadanh, Sherif Sakr, “Classification of VoIP and non-VoIP traffic using machine learning approaches”, JATIT, Volume 92, Oct 2016. [5] S.Pudumalar, E.Ramanujam, R.Harine Rajashree?, C.Kavya?, T.Kiruthika?, J.Nisha?, “Crop Recommendation System for Precision Agriculture”, ICoAC, 2016. [6] Rohit Kumar Rajak, Ankit Pawar, Mitalee Pendke, Pooja Shinde, Suresh Rathod,Avinash Devare, “Crop Recommendation System to Maximize Crop Yield using Machine Learning Technique”, IRJET, Volume 4, December 2017. [7] Zeel Doshi, Subhash Nadkarni, Rashi Agrawal, Prof. Neepa Shah, “AgroConsultant: Intelligent Crop Recommendation System Using Machine Learning Algorithms”, IEEE, 2018. [8] Nidhi H Kulkarni, Dr. G N Srinivasan, Dr. B M Sagar, Dr.N K Cauvery, “Improving Crop Productivity Through A Crop Recommendation System Using Ensembling Technique”, IEEE, 2018. [9] Rushika Ghadge, Juilee Kulkarni, Pooja More, Sachee Nene, Priya R L, “Prediction of Crop Yield using Machine Learning”, IRJET, Volume 5, February 2018. [10] M.V.R. Vivek, D.V.V.S.S. Sri Harsha, P. Sardar Maran, “A Survey on Crop Recommendation Using Machine Learning”, IJRTE, Volume 7, February 2019. [11] Annapoorna.S, Apoorva Herle, C M Sushma, Neha.Y.Jain, Mr.Vijay Kumar.S, “CRAPCSS - Crop Recommendation and Pest Control Suggestion System”, IRJET, Volume 7, August 2020. [12] Dr.A.K.Mariappan, Ms C. Madhumitha, Ms P. Nishitha and Ms S. Nivedhitha, “Crop Recommendation System through Soil Analysis Using Classification in Machine Learning”, IJAST, Volume 29, 2020. [13] Pavan Patil, Virendra Panpatil, Prof. Shrikant Kokate, “Crop Prediction System using Machine Learning Algorithms”, IRJET, Volume 7, February 2020. [14] Pradeepa Bandara, Thilini Weerasooriya, Ruchirawya T.H., W.J.M. Nanayakkara, Dimantha M.A.C and Pabasara M.G.P, “Crop Recommendation System”, IJCA, Volume 175, October 2020. [15] Tapan P. Bagchi, “Support Vector Machines--An Overview”, Advanced Business Analytics for Management Students, Jan 2020. [16] Neural Network Definition. (2021, December 8). Investopedia. https://www.investopedia.com/terms/n/neuralnetwork.as [17] Bahzad Taha Jijo, Adnan Mohsin Abdulazeez, “Classification Based on Decision Tree Algorithm for Machine Learning”, JASTT, Volume 2, March 2021 [18] Schott, M. (2021, December 9). Random Forest Algorithm for Machine Learning - Capital OneTech.Medium.https://medium.com/capital-one-tech/random-forest-algorithm-for-machine-learning-c4b2c8cc9feb [19] Goyal, C. (2021, June 2). KNN Interview Questions | KNN Algorithm Questions to Test Your Skills. Analytics Vidhya. https://www.analyticsvidhya.com/blog/2021/05/20-questions-to-test-your-skills-on-k-nearest-neighbour/ [20] Palaniraj A, Balamurugan A S, Durga Prasad R,Pradeep P, “Crop and Fertilizer Recommendation System using Machine Learning”, IRJET, Volume 8, April 2021.
Copyright
Copyright © 2022 Prof. Meena Ugale, Nimeesha Venkatavelu, Pranay Patil, Suraj Rane. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET40559
Publish Date : 2022-02-28
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online