

Ijraset Journal For Research in Applied Science and Engineering Technology
Estimation of Mean Time between Failures of a Two Tandem Mill of a Sugar Plant
Authors: Prof. Sachin N. Patil, Prof. Vaibhav K. Rangari
DOI Link: https://doi.org/10.22214/ijraset.2022.39823
Certificate: View Certificate
Abstract
When minutes of down-time can negatively impact the bottom line of a business, it is crucial that the physical infrastructure supporting be reliable. The equipment reliability can be achieved with a solid understanding of mean time between failures. Mean time between failures (MTBF) has been used for years as a basis for various maintenance decisions supported by various methods and procedures for lifecycle predictions. To quantifying a maintainable system or reliability we can use MTBF. For developing the mean time between failures model we can use make use of Poisson distribution, Weibull model and Bayesian model. In this paper we will be talking about complexities and misconceptions of MTBF and clarify criteria that need to be consider in estimating MTBF in a sequential manner. This paper sheds light on MTBF using examples throughout in an effort to simplify complexity.
Introduction
I. INTRODUCTION
Failure is a great teacher; we can learn a lot by introspecting given situation. To every industries to operates at lower cost, bigger profit and continuously to meet customer satisfaction MTBF plays a big role. MTBF mainly implemented for to planned maintenance regime instead of unplanned maintenance or reactive maintenance regime. Reactive maintenance seen to be one of the factor contributes to high manufacturing cost. MTBF study can be used as a bottom line for further improvement that needs to be done and as a monitoring tool to monitor the success of the improvement implemented. MTBF can synchronization the maintenance time to avoid frequent shutdown especially in a single-stream process. In a single- stream process, every shutdown due to whatever reasons seen as a maintenance opportunity and it is necessary for maintenance personnel to know what are the value can be added to the losses. The definition of MTBF based on failures and assumptions, which need a proper interpretation and well, kept in record. Therefore, this study will clearly interpret all the related components in MTBF. It is the most common means of comparing reliabilities, the factor of meaningless MTBF results are unclear failure definitions, misinterpretation and unrealistic estimations. Field data measurement uses field failure data produces more accurate results than simulations. New design product or low volume productivity of product may not have sufficient field's data, thus field data measurement is more accurate.
II. TERMINOLOGY
It is important to have definitions because, in reality, the true meaning of a term is not always what the typical industry believes. Everyone in an organization must have a common understanding of a definition.
A. Here are the Definitions of Some key terms Related to MTBF
Bad actors are pieces of equipment or assets that typically have long-standing reliability issues. Some companies identify “bad actors” by the amount of maintenance dollars spent on assets in labor and material, not production losses. MTBF is a simple measurement to pinpoint these poorly performing assets. Note that the most systematic, technically based method of determining if an asset is critical is to conduct an assessment based on consequence of failure and risk of failure to the business. Total equipment failure occurs when an asset completely fails or breaks down and is not operating at all. Functional failure is the inability of an asset to fulfil one or more of its functions (for example, it no longer produces a product that meets quality standards). Partial equipment failure occurs when equipment continues to run to a standard but some component of the asset is in failure mode. For example, the equipment may now be operating at a reduced speed. MTBF is the average time an asset will function before it fails. Emergency work order is a formal document written when an asset has failed & maintenance person is called to make a repair. Reliability is the ability of an item to perform a required function under stated conditions for a stated period of time. Error is a deviation from the correct service state for a system or a subsystem. Failure is a transition event that occurs when the delivered service deviates from the correct service state to an unwanted state. Failure rate is the frequency with which an engineered system or component fails.
III. MTBF PROCESS
A. STEPS for Calculating MTBF
- Step I. Ensure all emergency work is covered by a work order no matter how minor the equipment failure and that the asset information is captured in the computerized maintenance management system (CMMS) / Enterprise Asset Management (EAM) by asset number.
- Step II. Begin tracking MTBF, focusing on one production area or asset group. Calculate on a daily basis the mean time between failures:
MTBF=
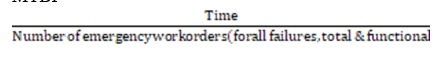
3. Step III. Trend the data you find in this production area or asset group daily on a line graph and post it for everyone to see. (Many people may not like to see this data or even believe it, but it provides knowledge of how the equipment has been performing to date and increases the need to find a solution to improve reliability.)
4. Step IV. Once you start tracking MTBF, another useful metric to track is the percentage change in MTBF.
This allows you to set a target or goal and work toward this goal. This approach often gains support by management for improving reliability.
MTBF% change =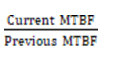
5. Step V. Trend the percentage change.
6. Step VI. Once you feel comfortable tracking and trending MTBF for this one production area or asset group, begin stepping down to the next level in your asset group. This group is typically called the child in your equipment hierarchy. What you have been measuring thus far is what I call the father or parent in the equipment hierarchy. You may define the hierarchy differently but in general the message is understood.
Continue the process throughout your organization’s production areas and assets.
B. Estimation of MTBF and Prediction
MTBF and service life is two different things. Service life can expressed as expected number of operating hours before system fails. While MTBF describe as:
MTBF = MTTD + MTTR + MTTF
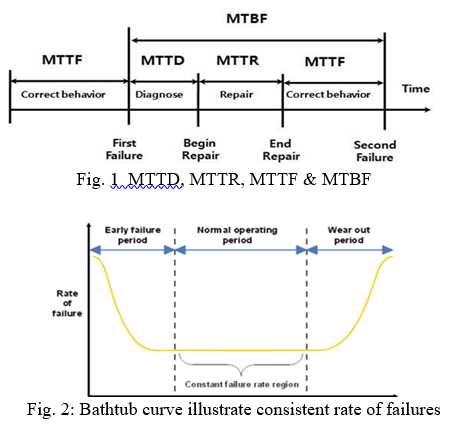
MTBF consist of mean time to diagnose (MTTD) mean time to repair (MTTR) and mean time to failure (MTTF); See figure 1. While product still in their "useful life" or "normal life" will gives high MTBF as a result. As at this period it's experiencing the lowest and almost a constant failure rate. There should be no correlation between MTBF and service life. A product can be extremely high MTBF (reliability) but a low service life. See Figure 2.
Machine components is in use in useful life period the field with a product quality and results to a constant failure rate with respect of time. Source of failures at this stage could include:
- Undetectable defects.
- Low design safety factor.
- Higher random stress than expected
- Human factors.
There are two ways to determine MTBF.
a. Reliability Prediction Method (Predict MTBF): It is usually performed early in the product lifecycle and based on the system design values are calculated. For example; new product designs. If field data does exist, this method should not be use.
b. Reliability Estimation Method (Estimate MTBF): The method is to calculate value based on observe sample of similar system. It could be done with large population of sample deployed in the field. It is most widely used as the product tested under a real working environment.
Determining MTBF by using estimate method is commonly use. MTBF is often confused with mean time to failure (MTTF), which applies to replaceable rather than repairable unit. The biggest challenge in implementation of Estimate MTFF is time. High reliability product will takes longer time. MTBF can be estimated in shorter time. Run the test with the population of units until long enough to have reasonably large number of failures. Replace the failed unit in the test population with a new unit. MTBF approximation can be obtained by multiplying number of units in the population by the total time, and dividing by the total failures. For the better approximation of actual MTBF larger number of failure are require.
For a repairable system, run a small number (as small as one) of units until they have experienced a number of failures (repair each failed unit and put it back into the test). Then take the total running time and divide by the number of failures. Formula for calculating the MTBF is (Scott Speaks, Vicor Reliability Engineering):
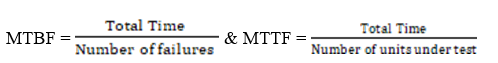
IV. RESEARCH METHODOLOGY
Plant's MTBF Base Line
MTBF situations will use for improvements.
Type of Improvement
There are few types of improvement:
- Improvement on components MTBF by
a. Improvement on component design
b. Replace too high-reliable product
c. System adjustment
2. Sufficient Number of Spares Instrumentation
For complex engineering design improvement Finite Element Analysis (FEA) will be use.
a. Data Collection: Historical data for parts replacement or maintenance will be drill out from Maintenance register.
b. Limitation of Study: This study is limited to two tandem mill of sugar mill.
V. FAILURE & ASSUMPTIONS
The definition of failure is actually infinite it is not limited to below two. Realistic assumptions have to be considered. To simplify the process of estimating MTBF assumption are required. It is almost impossible to collect the correct data and calculate the exact number. Assumptions may come from past experience, journals, hand book or proved previous similar project.
- To perform its required function whole failure system is require.
- Failure of any individual system (subsystem) to perform its required function but not to the system as a whole.
A. Methodology
- Identify problematic scenario: To record data logbook of operations department was referred.
- Collect relevant info: Downtime, time spent on attending issues for the said asset was noted down.
- Perform calculations
B. Example
Asset: Two tandem mill of a sugar plant.
- No. of emergency work orders in the past 24 hours = 8:
- Total equipment failure = 3,
- Functional equipment failure = 5.
(No need to bother about the exact definition of each type of failure. An emergency work order needs to be written any time an asset has a problem and a maintenance person is called to the asset to investigate or make a repair.)
- Time: 24 hours
Calculation:

Trending this information is valuable when identifying whether an asset’s health is improving or getting worse. An example of this trending is seen in figure
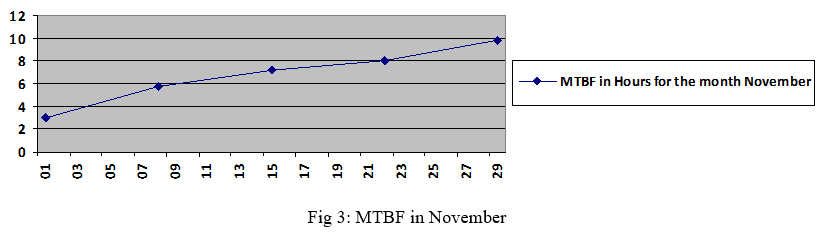
VI. MTBF PERCENTAGE CHANGE
Over a seven day period the MTBF improved from having failures every 3 hours to having a failure every 5.8 hours.
- Time: 7 days
- Previous MTBF: Day 1 = 3 hours
- Current MTBF: Day 7 = 5.8 hours
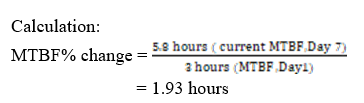
Total Plant MTBF
MTBF calculated for all assets in a plant is an indicator of the total plant reliability.
VII. LIMITATION & IMPROVEMENT OF MTBF AND MTFF
The main issue that deviate MTBF results is aging. Each component has its special age-related degradation mode. During repair Wear and tear effects on components are commonly detectable. Various effects, such as corrosion, slowly take their roll. As these phenomena goes on, unit will begin to fail at increasing rate where they have passed the useful lives. See Fig.2.
For the success of the MTBF estimation realistic assumptions are always there. Annual failure rate (AFR), has two scenarios that need to be considered (American Power Conversion, White Paper #112, 2004). Scenario 1 makes the following 2 assumptions: (1) the products operate 24 hours a day, 365 days a year; (2) all the products in the populations begin at the same time. It is relevant for products that are continuously running. Scenario 2, for products is known to run intermittently.
Maintenance free operating period (MFOP) was conceptualized by UK’s ministry of defense. Jacob and Sreejith (2008) introduced minimum mean time between failures (MMTBF) that is another approach to improve MTBF. The improvement does not mean the improvement of MTBF results. It is the way of determining value of improvement that sufficiently needed. This mean MTBF will be further improve by two key components; a specified MMTBF and a maximum acceptable probability of premature failure, Pj. Pf is the probability that the time to failure smaller than MMTBF. This approach is to determine the value of reliability that need to be improve. The value can be decided based on the control chart. The control chart also can be used to monitor improvement in reliability for necessary action to be taken if the improved system is not reflecting the desired result.
Conclusion
Failures are best avoided but they are unavoidable. Reactive maintenance is one of the main pulling factors that limit the organization from being best-cost-producer. It affects the organizations in many ways. Annual manufacturing cost, customer satisfaction and company’s image are put into jeopardize if the organization’s maintenance mode is not been shifted from reactive regime to predictive maintenance.
References
[1] Reliability Engineering & System Safety Volume 64, Issue 1, April 1999, Pages 127-131 Maintenance free operating period – an alternative measure to MTBF and failure rate for specifying reliability. U. Dinesh Kumar, J.Knezevic, J.Crocker [2] IEEE Transactions on Reliability 1970, Failure Rate/MTBF, Duncan Badenius [3] National Conference on Postgraduate Research (NCON- PGR) 2009 1st October 2009, UMP Conference Hall, Malaysia © Centre for Graduate Studies, University Malaysia Pahang Editors: M.M. Noor; M.M. Rahman and K. Kadir [4] International Journal for Scientific Research & Development, Vol. 1, Issue 3, 2013, Guidelines to Understanding to estimate MTBF, Narendra D. Chauhan, Prof. Nilesh H. Pancholi [5] Scott Speaks, Reliability and MTBF overview. Vicor reliability engineering, 1-10. Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specification, IEEE Std. 802.11, 1997.
Copyright
Copyright © 2022 Prof. Sachin N. Patil, Prof. Vaibhav K. Rangari. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET39823
Publish Date : 2022-01-06
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online