

Ijraset Journal For Research in Applied Science and Engineering Technology
Music Genre Classification by Machine Learning Techniques
Authors: G. Hasini Varma, J. Vishnu Varun , K. Ganesh Reddy , T. Radhika Reddy , N. Omkar Sainath , CH. Chandu , Mr. D Arivazhagan
DOI Link: https://doi.org/10.22214/ijraset.2023.57496
Certificate: View Certificate
Abstract
Music plays a very important role in people’s lives. Music brings like-minded people together and is the glue that holds communities together. Communities can be recognized by the type of songs that they compose, or even listen to the purpose of our project and research is to find a better machine learning algorithm than the pre-existing models that predicts the genre of songs. Genres can be defined as categorical labels created by humans to identify or characterize the style of music. The concept of automatic music genre classification has become very popular in recent years as a result of the rapid growth of the digital entertainment industry. offering the potential to enhance a wide range of visual-based applications.
Introduction
I. INTRODUCTION
A. Overview Of Project
Music genres are a set of descriptive keywords that convey high-level information about a music clip (jazz, classical, rock...). Music classification is considered as a very challenging task due to selection and extraction of appropriate audio features. While unlabeled data is readily available music tracks with appropriate genre tags is very less. Genre classification is a task that aims to predict music genre using the audio signal. Being able to automatize the task of detecting musical tags allow to create interesting content for the user like music discovery and playlist creations, and for the content provider like music labeling and ordering. Building this system requires extracting acoustic features that are good estimators of the type of genres we are interested, followed by a single or multi label classification or in some cases, regression stage. Conventionally, feature extraction relies on a signal processing front-end in order to compute relevant features from time or frequency domain audio representation. The features are then used as input to the machine learning stage. Machine learning is an application of artificial intelligence (AI) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. It focuses on the development of computer programs that can access data and use it learn for themselves. Machine learning algorithms are used to classify and predict the genre of a music.
II. LITERATURE REVIEW
- Music Genre Classification and Recommendation by Using Machine Learning Techniques Authors: Ahmet Elbir ; Hilmi Bilal Çam ; Mehmet Emre Iyican ; Berkay Öztürk ; Nizamettin Aydin, 2018 Innovations in Intelligent Systems and Applications Conference (ASYU) Music genre prediction is one of the topics that digital music processing is interested in. In this study, acoustic features of music have been extracted by using digital signal processing techniques and then music genre classification and music recommendations have been made by using machine learning methods. In addition, convolutional neural networks, which are deep learning methods, were used for genre classification and music recommendation and performance comparison of the obtained results has been. In the study, GTZAN database has been used and the highest success was obtained with the SVM algorithm
- On Combining Diverse Models for Lyrics-Based Music Genre Classification Authors: Caio Luiggy Riyoichi Sawada Ueno; Diego Furtado Silva, 2019 8th Brazilian Conference on Intelligent Systems (BRACIS) Automatic music organization and retrieval is a highly required task nowadays. Labeling songs with summarized but descriptive information have implications in a wide range of tasks in this scenario. The genre is one of the most common labels used for music recordings. Using this piece of information, music platforms can organize collections by, for instance, associating songs and artists with similar characteristics. Lyrics represent an alternative source of data for genre recognition. While "traditional" bag-of-words-based text mining techniques represent a considerable part of the literature, recent papers shown an advance on this task applying deep learning algorithms. However, there is no research on how these distinct strategies contribute to each other. In this paper, we explore different strategies for music genre classification from lyrics and show that even simple combinations of these strategies allow improving accuracy on the lyrics-based music genre identification.
- Music Genre Recognition Using Residual Neural Networks Authors; Dipjyoti Bisharad ; Rabul Hussain Laskar TENCON 2019 - 2019 IEEE Region 10 Conference (TENCON) Genre is an abstract, yet a characteristic feature of music. Existing works for 4 automatic genre classification compute a set of features from the audio and design a classifier on top of it. Such models, in general, compute these features over a relatively long duration of the audio. In this paper, a residual neural network-based model is proposed for genre classification which is trained on short clips of just 3 seconds duration. Also, traditional genre classification algorithms will assign a single genre to an audio clip. However, it well established that different genres have overlapping characteristics.
III. AIM AND SCOPE OF PRESENT INVESTIGATION
A. Aim Of The Project
Embarking on a deep learning project for the automatic classification of musical genres from audio files holds significant importance in various practical scenarios. The focus of our project is to utilize low-level features related to frequency and time domain in audio data for this classification task. To ensure consistency in our analysis, we are in need of a dataset comprising audio tracks with similar sizes and frequency ranges.
The GTZAN genre classification dataset emerges as the most recommended choice for our endeavor. Widely regarded as a benchmark in the field, this dataset offers a diverse collection of audio tracks spanning various genres. Its comprehensive nature makes it an ideal foundation for training and evaluating deep learning models. By tapping into the GTZAN dataset, our objective is to construct a resilient and efficient deep learning system capable of precisely categorizing music genres based on their distinctive acoustic characteristics.
B. Scope And Objective
- Classification of genre can be very valuable to explain some interesting problems such as creating song references, tracking down related songs, discovering societies that will like that specific song, sometimes it can also be used for survey purposes.
- In addition to this, automatic classification of music into genres can provide a framework for development and evaluation of features for any type of content-based analysis of musical signals.
a. Developing a machine learning model that classifies music into genres shows that there exists a solution which automatically classifies music into its genres based on various different features, instead of manually entering the genre.
b. Another objective is to reach a good accuracy so that the model classifies new music into its genre correctly.
c. This model should be better than at least a few preexisting models.
C. System Requirements
- Hardware Requirements
The most common set of requirements defined by any operating system or software application is the physical computer resources, also known as hardware. The minimal hardware requirements are as follows,
a. Processor : Pentium IV
b. RAM : 8 GB
c. Processor : 2.4 GHz
d. Main Memory : 8GB RAM
e. Hard Disk Drive : 1tb
f. Keyboard : 104 Keys
2. Software Requirements
Software requirements deals with defining resource requirements and prerequisites that needs to be installed on a computer to provide functioning of an application.
The minimal software requirements are as follows,
a. Front end : python
b. Dataset : GTZAN.csv
c. IDE: Command prompt.
d. Operating System : Windows 11
IV. DESIGN METHODOLOGY
A. Existing System
In existing system, we used k-nearest neighbor (k-NN) to classify the genres. This doesn’t give an absolute reasonable correlation between learning strategies for classification of music genre. It uses filter modeling before Piecewise Gaussian Modeling. However, these improvements are not statistically significant. This procedure does not increase classification accuracy and it doesn’t achieve the efficiency prediction.
B. Proposed System
Support Vector Machine (SVMs) have been actively used for various music classification tasks such as music tagging , genre classification and user-item latent feature prediction for recommendation. SVMs and KNNs assume features that are in different levels of hierarchy and can be extracted by convolutional kernels. The hierarchical features are learned to achieve a given task during supervised training.
???????C. Module Description
- Module1: Data Preprocessing is a process of transforming the raw, complex data into systematic understandable knowledge. It involves the process of finding out missing and redundant data in the dataset. Thus, this brings uniformity in the dataset. However, in our dataset, there was no missing values found meaning that every record was constituted its corresponding feature values.
- Module2: Feature extraction is a process of dimensionality reduction by which an initial set of raw data is reduced to more manageable groups for processing. A characteristic of these large data sets is a large number of variables that require a lot of computing resources to process. Feature extraction is the name for methods that select and /or combine variables into features, effectively reducing the amount of data that must be processed, while still accurately and completely describing the original data set.
- Module3: Model Creation: Algorithm’s Used:
- Support Vector Machine (SVM) algorithm
- K-nearest neighbors (KNN) algorithm
- Working of SVM
An SVM model is basically a representation of different classes in a hyperplane in multidimensional space. The hyperplane will be generated in an iterative manner by SVM so that the error can be minimized. The goal of SVM is to divide the datasets into classes to find a maximum marginal hyperplane (MMH).
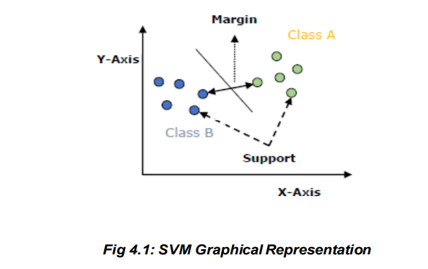
a. Support Vectors: Datapoints that are closest to the hyperplane is called support vectors. Separating line will be defined with the help of these data points.
b. Hyperplane: As we can see in the above diagram, it is a decision plane or space which is divided between a set of objects having different classes.
c. Margin: It may be defined as the gap between two lines on the closet data points of different classes. It can be calculated as the perpendicular distance from the line to the support vectors.
2. Working of KNN Algorithm
K-nearest neighbors (KNN) algorithm uses ‘feature similarity’ to predict the values of new datapoints which further X means that the new data point will be assigned a value based on how closely it matches the points in the training set. We can understand its working with the help of following steps:
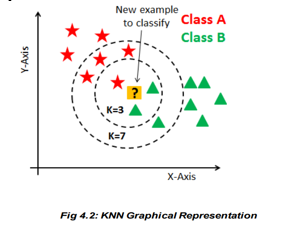
a. Feature Extraction: The process of feature extraction is useful when you need to reduce the number of resources needed for processing without losing important or relevant information. Feature extraction can also reduce the amount of redundant data for a given analysis. Also, the reduction of the data and the machine’s efforts in building variable combinations (features) facilitate the speed of learning and generalization steps in the machine learning process.
???????D. Model Training
A training model is a dataset that is used to train an ML algorithm. It consists of the sample output data and the corresponding sets of input data that have an influence on the output. The training model is used to run the input data through the algorithm to correlate the processed output against the sample output. The result from this correlation is used to modify the model. This iterative process is called “model fitting”. The accuracy of the training dataset or the validation dataset is critical for the precision of the model. Model training in machine language is the process of feeding an ML algorithm with data to help identify and learn good values for all attributes involved. Ther e are several types of machine learning models, of which the most common ones are supervised and unsupervised learning. Supervised learning is possible when the training data contains both the input and output values. Each set of data that has the inputs and the expected output is called a supervisory signal. The training is done based on the deviation of the processed result from the documented result when the inputs are fed into the model.
???????E. Trained Classifier
Classification is the process of predicting the class of given data points. Classes are sometimes called as targets/ labels or categories. Classification predictive modeling is the task of approximating a mapping function (f) from input variables (X) to discrete output variables (y).
???????F. Prediction
The song genre is predicted from the input we provided.
VII. FUTURE ENHANCEMENTS
In our future endeavors, we aim to explore different deep learning methods, particularly those specialized for time series data, such as RNN models like GRU and LSTM, considering their potential for improved performance. Additionally, we're intrigued by the generative aspects of the project, contemplating genre conversion akin to generative adversarial networks transforming photos into artistic styles, but tailored for music. This opens possibilities for creative applications and unique user experiences.
Moreover, we anticipate opportunities for transfer learning, envisioning applications in classifying music by artist or decade. Leveraging pre-trained models and knowledge from one task to enhance performance in another could offer efficiency and accuracy gains in our music genre classification project.
Conclusion
To address the multi-class problem, we propose an ensemble approach, combining SVM and KNN models to create confidence vectors for each input. This ensemble strategy allows for nuanced predictions and could enhance a streaming service, enabling multiple genre inputs. Additionally, experimenting with diverse machine learning models, beyond SVM and KNN, aims to expose different implicit features in the dataset. This exploration contributes to a more comprehensive understanding of music genres and can potentially improve classification accuracy.
References
[1] Git Hub: https://github.com/alikaratana/Music-Genre-Classification [2] Images: https://www.google.co.in/search?sca_esv=589379245&sxsrf=AM9HkKnWFsTHkeOfyhXh5aBoM1gaso1ouQ:1702127489750&q=music+genre+classification&tbm=isch&source=lnms&sa=X&ved=2ahUKEwiM5I2Dt4KDAxWJTGwGHWMjDyYQ0pQJegQIDBAB&biw=1280&bih=643&dpr=1.5 [3] K-means and hierarchical clustering with Python by Joel Grus Released on August 2016. [4] https://www.analyticsvidhya.com/blog/2022/03/music-genre-classification-project-using-machine-learning-techniques/ [5] https://www.geeksforgeeks.org/music-genre-classifier-using-machine-learning/ [6] Music Genre Classification Using Independent Recurrent Neural Network, Wenli Wu ; Fang Han ; Guangxiao Song ; Zhijie Wang, 2018 Chinese Automation Congress(CAC). [7] Music Genre Classification and Recommendation by Using Machine Learning Techniques, Ahmet Elbir ; Hilmi Bilal Çam ; Mehmet Emre Iyican ; Berkay Öztürk ; Nizamettin Aydin, 2018 Innovations in Intelligent Systems and Applications Conference (ASYU). [8] Improve Music Genre Classification with Conv Nets, Rafael L. Aguiar ; Yandre M.G. Costa ; Carlos N. Silla, 2018 International Joint Conference on Neural Networks(IJCNN). [9] Genre Classification using Word Embeddings and Deep Learning, Akshi Kumar ; Arjun Rajpal ; Dushyant Rathore, 2018 International Conference on AdvancesinComputing,Communications andInformatics(ICACCI). [10] Music Genre Classification: A N-Gram Based Musicological Approach, Eve Zheng ; Melody Moh ; Teng-Sheng Moh, 2017 IEEE 7th International Advance Computing Conference (IACC). [11] Long short-term memory recurrent neural network based segment features for music genre classification, Jia Dai ; Shan Liang ; Wei Xue ; Chongjia Ni ; Wenju Liu, 2016 10th International Symposium on Chinese Spoken Language Processing (ISCSLP). [12] Music Genre Recognition Using Residual Neural Networks, Dipjyoti Bisharad ; Rabul Hussain Laskar TENCON 2019 - 2019 IEEE Region 10 Conference (TENCON).
Copyright
Copyright © 2023 G. Hasini Varma, J. Vishnu Varun , K. Ganesh Reddy , T. Radhika Reddy , N. Omkar Sainath , CH. Chandu , Mr. D Arivazhagan . This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET57496
Publish Date : 2023-12-11
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online