

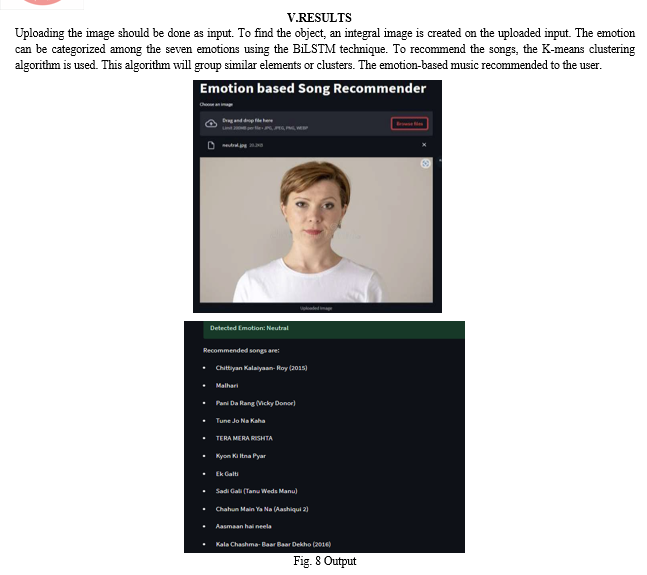
Ijraset Journal For Research in Applied Science and Engineering Technology
Music Recommendation through Facial Emotion Detection using Deep Learning
Authors: Jitendra Gummadi, Dr. Shobana Gorintla
DOI Link: https://doi.org/10.22214/ijraset.2023.54976
Certificate: View Certificate
Abstract
We cannot imagine our lives without music. Only commercially produced music is played for users. The selection of the main features is an enormously important issue for systems like facial expression recognition. The recommended strategy helps individuals in their musical listening by providing recommendations based on emotions, feelings, and sentiments. The seven facial emotion categories that have been considered are angry, disgusted, fear, pleased, sad, surprise, and neutral—are meant to be specifically allocated to each identified face. To classify the emotion, the object should be detected from an inputted image. The object can be recognized in the image using the Haar-Cascades technique. This algorithm can be defined in different stages: Calculating Haar Features, Creating Integral Images, BiLSTM, and Implementing Cascading Classifiers. A deep learning model called BiLSTM (Bidirectional Long Short-Term Memory) is used to categorize human emotion. Based on the predicted emotion the music is mapped and the playlist is recommended to the user. The k-means clustering algorithm is used to map the music to the expected emotion, as compared to the existing models the deep learning model BiLSTM will give the best performance and 86.5% accuracy.
Introduction
I. INTRODUCTION
Generally, facial expressions are the primary means through which people communicate their sentiments. Although one may conceal their words, one cannot conceal their expressions. People have long been aware that music may influence their emotions. 90 out of 100 people like to listen to music. Considering that, this work aims to recommend music based on the user’s emotions. Sensing and recognizing the emotion being detected and displaying appropriate songs can increasingly calm the user's mind and the overall pleasant end up giving a pleasing effect.
At first, the image is given as input and the detection of an object can be done. Later, the emotion of a person is predicted. Based on the predicted emotion the music is mapped. The model is programmed to analyze an image using segmentation method and algorithms for image processing in order to extract information from the target person's face and attempt to determine the emotion the person is attempting to convey. This article seeks to lighten the user's mood by playing music that suits the user's requirements. The greatest method to interpret or infer someone else's feelings is through their facial expressions. Facial expression recognition has been the most effective method of expression analysis known to mankind since the dawn of time. Occasionally, altering one's mood might aid in overcoming challenges like melancholy and despair.The model is trained with the FER-2013 dataset which contains images with all seven emotions. The image is given as input then object detection, and image pre-processing can be done. Then the emotion can be predicted, and now the music is recommended based on the predicted emotion. To do this the Deep Learning models Haar-Cascades, BiLSTM, and k-means clustering are used. The object can be recognizedin an image or video using the Haar-Cascades technique. After detecting the object, by using the BiLSTM model the emotion of an inputted image is predicted. The model is used to recognize facial emotion expressions. Recognizing the expression of a person is very difficult because everyone cannot express their emotions or feelings in the same way, everyone will have their own fashion. So, this work aims to predict emotion accurately. Then based on the predicted emotion, the respective music will be recommended. To do this k-means clustering algorithm the mapping of emotion and music.
II. LITERATURE SURVEY
A smartphone-based mobile system developed by Hyoung-Gook Kim, Gee Yeun Kim, and Jin Young Kim included two essential modules for recognizing human activities and then making music recommendations based on those actions. Their approach uses a deep residual bidirectional gated recurrent neural network to extract high activity detection accuracy from smartphone accelerometer. The results are supported by extensive tests using data from the real world. Extensive trials using real-world data demonstrate the suggested activity-aware music recommendation framework's correctness.
JIANNAN YANG 1, TIANTIAN QIAN 1, FAN ZHANG 2, AND SAMEE U. KHAN, senior IEEE members, presented facial action unit (AU) identification, which detects facial emotions by examining cues relating the movement of atomic muscles in the immediate face area. They might construct AU values based on the observed facial feature points and then use them to classify algorithms for emotion recognition. With the edge devices, they have optimized and customized algorithms to directly interpret the raw picture data from each camera, allowing them to send the identified emotions more readily to their end-user. As a result, they used Raspberry Pi to create a lightweight edge computing-based distributed system.
Deep learning algorithms were used by KORNPROM PIKULKAEW, EKKARAT BOONCHIENG, WARAPORN BOONCHIENG, and VARIN CHOUVATUT4 to study the utilization of 2D facial expressions and motions to evaluate pain. Their method divides pain into three categories: not painful, becoming painfully painful, and becoming excruciatingly painful. To sum up, their research offers a different method of assessing pain before hospitalization that is quick, affordable, and simple for both the general public and medical experts to understand. This analytical method might also be used to other screening methods, such the identification of pain in infectious disorders. An Xception-inspired model used residual blocks and depth-separable convolutions to achieve an accuracy rate of 81% for unforeseen events, but only 51% for neutral emotion recognition.
ZIFAN JIANG, SAHAR HARATI, ANDREA CROWWELL, SHAMIM NEMATI, AND GARI
D. CLIFFORD predicted that an automated facial expression detection system based on convolutional neural networks (CNN), pre-trained on a massive auxiliary public dataset, can improve generalizable approaches to MDD automatic assessment from videos and classify remission or response to treatment. They tested a new deep neural network framework on 365 video interviews (88 hours) from a group of 12 depressed patients before and after DBS therapy. A Regional CNN detector and an ImageNet pre-trained CNN were used to extract seven primary emotions. The Open face toolkit was also used to extract facial action units. The classifier achieved 63.3% accuracy in the Affectnet evaluation set.
PRANAV E, SURAJ KAMAL, SATHEESH CHANDRAN C, and SUPRIYA M.H have
presented an emotion recognition system that can be deployed with high accuracy. The main is to categorize five different human face emotions. Using the manually gathered image dataset, the model is trained, tested, and verified. With an accuracy of 84.33%, the model can forecast various emotions. The method tested attained an accuracy of about 83%. The accuracy of the model, which utilizes an Adam optimizer to reduce the loss function, was tested and found to be 78.04% accurate.
Hui Zhang, Kejun Zhang, and Nick Bryan-Kinns constructed an emotional map between task and song for the two nations based on emotional preferences, cultural differences, and an examination of the emotional preference of music in daily activities through a cross-cultural survey in China and the UK. Then they unveiled EmoMusic, a ground-breaking emotion-based music suggestion service for everyday tasks that lets users see and manage music emotion through an interactive interface. User research is offered to assess the app. This project looked at the emotional preferences of music for different types of activity and employed emotional cues in a recommender service.
III. EXISTING SYSTEM
It is essential to consider how emotions affect a person's thoughts, behaviors, and emotions. An emotion detection system may be developed by utilizing the benefits of deep learning, and numerous applications, such as feedback analysis and face unlocking, may be carried out with high accuracy. The primary goal of this system is to build a Deep Convolutional Neural Network (DCNN) model that can distinguish 5 (five) different forms of emotional expressions that individuals utilize on their faces. The model is developed, tested, and validated using a hand-gathered image dataset. This gives an accuracy of 78.04 percent.
Although the uses in automatic music production and videography, the issue of music recommendation from dancing movements has not been studied. To solve this problem, the system recommends and assesses a deep music selection algorithm based on dancing motion analysis. For quantitative assessment, this model uses an LSTM-AE-based music recommendation technique that learns the correspondences between motion and music. Comparative testing of the two methods reveals that the motion analysis-based approaches perform noticeably better. Also, a quantitative evaluation of the most appropriate musical genre is proposed.
IV. PROPOSED SYSTEM
The proposed system employs a music recommendation through facial emotion detection using deep learning. To identify an object in an image or a video, the Haar-Cascades approach is chosen. After detecting the object, by using the BiLSTM model the emotion of an inputted image is predicted. The model is used to recognize facial emotion expressions. Recognizing the expression of a person is delicate because everyone cannot express their feelings or passions in the identical way, everyone will have their own fashion. Hence, this work aims to predict emotion accurately.
Also based on the predicted emotion, the identical music will be recommended. To suit this k- means clustering algorithm is applied. The technique separates the unlabeled dataset into clusters with different attributes, ensuring that each dataset only corresponds to one group. The image is given as input, then the object spotting and image pre- processing can be done. Then the emotion can be predicted, and now the music is recommended based on the predicted emotion. The design is divided into different ways:
A. Haar Feature Selection
Most of the human faces exhibit a few traits or similar characteristics that we can recognize or notice, including:
- A deeper area around the eyes than the upper cheeks.
- A brighter area of the nasal bridge than the eyes.
- Some specific regions of the lips, nose, and eyes.
Computation on adjacent rectangular regions at certain points in a discovery window provide the core of a Haar feature. Below are a few illustrations that demonstrate Haar characteristics.




VI. FUTURE SCOPE
Future applications of this system have enormous prospects. This strategy can be developed for a big crowd. It is easy as people show their emotions, this technology detects them and recommends music to them. This might also be classified into many other emotions and categorized to people. This work can also be extended with the work of Automatic Pain Detection technology making it available and usable for non-communicative people.
Conclusion
The proposed system results in the classification of seven different facial emotions using some of the deep learning techniques to detect the emotion of the user and retrieve the music genre information by recommending perfect music. A model is created that can be coupled with other electronic devices for efficient control and has equivalent training and validation accuracy, which indicate that the model has the best fit and is generalised to the data. The use of the BiLSTM algorithm reduces the errors to give better accuracy and a computer vision system that automatically recognizes facial expressions with subtle differences.
References
[1] “Akriti Jaiswal, A. Krishnama Raju, Suman Deb, “Facial Emotion Detection Using Deep Learning”, It presents the design of an artificial intelligence (AI) system capable of emotion detection through facial expressions, 2020 International Conference for Emerging Technology (INCET), DOI: 10.1109/INCET49848.2020.9154121” [2] “Si Miao, Haoyu Xu, Zhenqi Han, Yongxin Zhu, “Recognizing Facial Expressions Using a Shallow Convolutional Neural Network”, It proposes a shallow CNN (SHCNN) architecture with only three layers to classify static expressions and micro-expressions simultaneously without big training datasets, IEEE Access, 2019,Volume: 7, Journal Article, DOI: 10.1109/ACCESS.2019.2921220” [3] “Hyoung-Gook Kim, Gee Yeun Kim, Jin Young Kim, “Music Recommendation System using Human Activity Recognition From Accelerometer Data”, The song tempo is successfully classified, content-based music browsing may use this feature and search for or recommend songs, IEEE Transactions on Consumer Electronics 2019, Volume: 65, Issue: 3, Journal Article, DOI: 10.1109/TCE.2019.2924177” [4] “Shreya Mishra, Shubham Kumar, Dr. Jaspreet Kour, “Real Time Expression Detection of Multiple Faces Using Deep Learning”, Facial Expression recognition (FER2013) dataset is used to train the model and can recognize five emotions, 2021 International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Publisher: IEEE, DOI: 10.1109/ICACITE51222.2021.9404561” [5] “Pranav E, Suraj Kamal, C. Satheesh Chandran; M.H. Supriya, Facial Emotion Recognition Using Deep Convolutional Neural Network, The main focus of this work is to create a Deep Convolutional Neural Network (DCNN) model that classifies 5 different human facial emotions, 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), DOI: 10.1109/ICACCS48705.2020.9074302” [6] “Heechul Jung, Sihaeng Lee, Sunjeong Park; Byungju Kim; Junmo Kim; Injae Lee; Chunghyun Ahn, “Development of Deep Learning-based Facial Expression RecognitionSystem”, 2015 21st Korea-Japan Joint Workshop on Frontiers of Computer Vision (FCV), DOI: 10.1109/FCV.2015.7103729” [7] “Kornprom Pikulkaew, Waraporn Boonchieng, Ekkarat Boonchieng, Varin Chouvatut , “2D Facial Expression and Movement of Motion for Pain Identification with Deep Learning Methods”, IEEE Access, Volume: 9, PP(s): 109903 – 109914, 30 July 2021, DOI: 10.1109/ACCESS.2021.3101396” [8] “Wenjuan Gong, Qingshuang Yu, “A Deep Music Recommendation Method Based on HumanMotion Analysis”, IEEE Access, Volume: 9, PP(s): 26290 – 26300, 05 February 2021, DOI: 10.1109/ACCESS.2021.3057486” [9] “Yuedong Chen, Jianfeng Wang, Shikai Chen; Zhongchao Shi; Jianfei Cai, “Facial Motion Prior Networks for Facial Expression Recognition”, 2019 IEEE Visual Communications and Image Processing (VCIP), DOI: 10.1109/VCIP47243.2019.8965826” [10] “Shan Li, Weihong Deng, “Deep Facial Expression Recognition: A Survey”, IEEE Transactions on Affective Computing, Volume: 13, Issue: 3, 01 July-Sept. 2022, DOI: 10.1109/TAFFC.2020.2981446” [11] “Deger Ayata, Yusuf Yaslan and Mustafa E. Kamasak, “Emotion Based Music Recommendation System Using Wearable Physiological Sensors”, IEEE Transactions on Consumer Electronics, Volume: 64, Issue: 2, May 2018, DOI: 10.1109/TCE.2018.2844736” [12] “Jiannan Yang, Tiantian Qian, Fan Zhang, Samee U. Khan, “Real-Time Facial Expression Recognition Based on Edge Computing”, IEEE Access, Volume: 9, PP(s): 76178 – 76190, 21May 2021, DOI: 10.1109/ACCESS.2021.3082641” [13] “S L Happy, Aurobinda Routray, “Automatic Facial Expression Recognition Using Features ofSalient Facial Patches”, IEEE Transactions on Affective Computing, Volume: 6, 01 Jan.- March 2015, DOI: 10.1109/TAFFC.2014.2386334” [14] “Hari Prasad Mal;P. Swarnalatha, “Facial expression detection using facial expression model”,017 International Conference on Energy, Communication, Data Analytics and Soft Computing(ICECDS), DOI: 10.1109/ICECDS.2017.8389644” [15] “Marryam Murtaza, Muhammad Sharif, Musarrat AbdullahYasmin; Tanveer Ahmad, “Facial expression detection using Six Facial Expressions Hexagon (SFEH) model”, 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), DOI: 10.1109/CCWC.2019.8666602” [16] “Kyoungro Yoon, Jonghyung Lee, and Min-Uk Kim, “Music Recommendation System UsingEmotion Triggering Low-level Features”, IEEE Transactions on Consumer Electronics, Volume: 58, Issue: 2, May 2012, DOI: 10.1109/TCE.2012.6227467” [17] “Dong-Moon Kim, Kun-su Kim, Kyo-Hyun Park;Jee-Hyong Lee;Keon Myung Lee, “A MusicRecommendation System with a Dynamic K-means Clustering Algorithm”, Sixth International Conference on Machine Learning and Applications (ICMLA 2007), DOI: 10.1109/ICMLA.2007.97” [18] “Xuan Zhu, Yuan-Yu an Shi; Hyoung-Gook Kim; Ki-Wan Eom, “An Integrated Music Recommendation System”, IEEE Transactions on Consumer Electronics ( Volume: 52, Issue:3, August 2006), DOI: 10.1109/TCE.2006.1706489” [19] “Ke Chen; Beici Liang; Xiaoshuan Ma; Minwei Gu, \"Learning Audio Embeddings with User Listening Data for Content-Based Music Recommendation”, ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Issue: 13 May 2021, DOI: 10.1109/ICASSP39728.2021.9414458” [20] “Thanapong Khajontantichaikun; Saichon Jaiyen; Siam Yamsaengsung; Pornchai Mongkolnam; Unhawa Ninrutsirikun, \"Emotion Detection of Thai Elderly Facial Expressions using Hybrid Object Detection\", International Computer Science and Engineering Conference (ICSEC), Volume: 14, Issues: 27 October 2020, DOI: 10.1109/TAFFC.2020.3034215” [21] V. K. Chaithanya Manam, V. Mahendran, and C. Siva Ram Murthy. \" Performance Modeling of DTN Routing with Heterogeneous and Selfish Nodes.\" Wireless Networks, vol. 20, no. 1, pp. 25-40, January 2014. [22] V. K. Chaithanya Manam, Gaurav Gurav, and C. Siva Ram Murthy.\" Performance Modeling of Message-Driven Based Energy-Efficient Routing in Delay-Tolerant Networks with Individual Node Selfishness.\" In COMSNETS’13: Proceedings of the 5th International Conference on Communication Systems and Networks, pp. 1-6, January 2013. [23] V. K. Chaithanya Manam, V. Mahendran, and C. Siva Ram Murthy. \"Message-Driven Based Energy-Efficient Routing in Heterogeneous Delay-Tolerant Networks.\" In MSWiM HP- MOSys’12: Proceedings of ACM MSWIM Workshop on High-Performance Mobile Opportunistic Systems, pp. 39-46, October 2012. [24] V. K. Chaithanya Manam, V. Mahendran, and C. Siva Ram Murthy. \"Performance Modeling of Routing in Delay-Tolerant Networks with Node Heterogeneity\" In COMSNETS’12: Proceedings of the 4th International Conference on Communication Systems and Networks, pp. 1-10, January 2012. [25] V. K. Chaithanya Manam, Dwarakanath Jampani, Mariam Zaim, Meng-Han Wu, and Alexander J. Quinn. \"TaskMate: A Mechanism to Improve the Quality of Instructions in Crowdsourcing.\" In Companion Proceedings of The 2019 World Wide Web Conference (WWW \'19). Association for Computing Machinery, New York, NY, USA, pp. 1121–1130, May 2019. [26] V. K. Chaithanya Manam, and A. Quinn. \" WingIt: Efficient Refinement of Unclear Task Instructions.\" In HCOMP\'18: Proceedings of the 6th AAAI Conference on Human Computation and Crowdsourcing, pp.108-116, June 2018. [27] S. Nyamathulla , Dr. P. Ratnababu , Dr. G. Shobana , Dr. Y. Rokesh Kumar4 , K.B.V. Rama Narasimham A Fast, Dynamic method to identify attributes sets using Corelation-Guided Cluster analysis and Genetic algorithm Techniques” in Design Engineering ISSN: 0011-9342 | Year 2021 Issue: 7 | Pages: 5497-5510. [28] Mrs.Shobana gorintla ,2 Mr.B.Anil Kumar ,3Mrs.B.Sai Chanadana ,4 Dr.N.Raghavendra Sai,5 Dr.G.Sai Chaitanya Kumar “Deep-Learning-Based Intelligent PotholeEye+ Detection Pavement Distress Detection System” in Proceedings of the International Conference on Applied Artificial Intelligence and Computing (ICAAIC 2022) IEEE Xplore Part Number: CFP22BC3-ART; ISBN: 978-1-6654-9710-7 [29] G. Shobana, Dr Bhanu Prakash Battula” A Novel Imbalance Learning with Fusion Sampling using Diversified Distribution” in International Journal Of Research In Electronics And Computer Engineering -IJRECE VOL. 6 ISSUE 3 ( JULY - SEPTEMBER 2018) ISSN: 2393- 9028 (PRINT) | ISSN: 2348-2281 (ONLINE). [30] G. Shobana, Dr Bhanu Prakash Battula “ A comparitive study of skewed data sources using fusion sampling Diversified Distributon” International Journal of Research in Advent Technology, Special Issue, March 2019 E-ISSN: 2321- 9637
Copyright
Copyright © 2023 Jitendra Gummadi, Dr. Shobana Gorintla. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET54976
Publish Date : 2023-07-24
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online