

Ijraset Journal For Research in Applied Science and Engineering Technology
Music Recommender System Using ChatBot
Authors: Shivam Sakore, Pratik Jagdale, Mansi Borawake, Ankita Khandalkar
DOI Link: https://doi.org/10.22214/ijraset.2021.39717
Certificate: View Certificate
Abstract
In this era of technological advances, text-based music recommendations are much needed as they will help humans relieve stress with soothing music according to their moods. In this project, we have implemented a chatbot that recommends music based on the user\'s text tone. By analyzing the tone of the text expressed by the user, we can identify the mood. Once the mood is identified, the application will play songs in the form of a web page based on the user\'s choice as well as his current mood. In our proposed system, the main goal is to reliably determine a user\'s mood based on their text tone with an application that can be installed on the user\'s desktop. In today\'s world, human computer interaction (HCI) plays a crucial role, and the most popular concept in HCI is recognition of emotion from text. As part of this process, the frontal view of the user\'s text is used to determine the mood. The extraction of text tone from the user\'s text is another important aspect. We have used IBM Analyser to check the text tone of the user and to predict the mood based on the text of the user, and Last.FM API to recommend songs based on the mood of the user.
Introduction
I. INTRODUCTION
Communication is the thing which we do in our daily life but having communication and getting to know the feeling through the music is a different level.To feel better and relaxing, people find music important in their lives. Why go over the music streaming which is not personalized to search the song that the user is feeling when the user gets a recommendation while based on the communication the user has with chatbot. In a typical conversation, about 93% of communication is determined by emotion being expressed. Humans are capable of detecting emotions, which is exceedingly important for successful communication.
Chatbots help business teams to scale their interactions with users. You could embed it in any major chat app, such as Facebook Messenger, Slack, Telegram, and Text Messages. Chatbots improve the user experience by facilitating interactions between users and services. Are you tired of all the weird chat bots out there that are designed primarily for business purposes? As part of this project, we will build a chatbot service to which you can talk. This wouldn't be a business-driven conversation. We would simply interact casually. Additionally, the chatbot would also recommend songs based on the tone of the user's voice. To implement the song recommendation feature, Last.fm API will be used, a service very similar to Spotify API. Additionally, IBM Tone Analyzer API will be used for the tone/emotion analysis of the conversation. API integration is very important today as the popular chatbots do much more than just have a data-driven conversation; they also offer more user-friendly features. In addition to offering a wide array of open-source libraries for building chatbots, python also provides a wide array of open-source libraries for building chatbots, such as scikit-learn and TensorFlow. For small data sets and simpler analyses, Python's libraries are more practical.
II. PRODUCT ARCHITECTURE
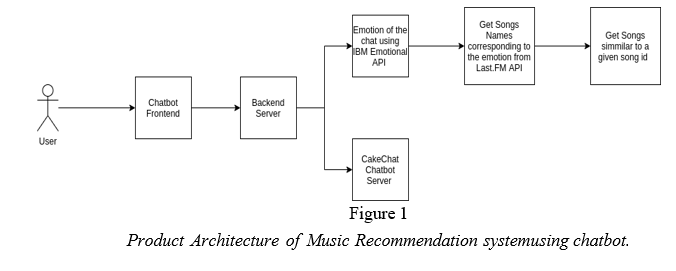
The figure totally showed us how this project would be look like .Basically , frontend is gonna show us how the ui look like but whenever user talk with chatbot it will eventually reflects on the frontend.And the server side there are mainly two api’s would be working to detect the emotion of the text of user by using IBM
Emotional API and after the detection of the emotion it will recommend the song through Last.FM API . Conversation is initiated by the user The IBM Emotional API is used to analyze the conversation's emotional content
The Cakechat Chatbot will reply to your conversation By utilizing the Last.fm songs API, the app retrieves the top songs based on the Emotion it perceives After listening to a song for some time, a similar song will be recommended to the user using the Last.fm API.
III. TONE ANALYZER
Tone Analyzer by IBM helps to detect communication tones in written text. Emotional, linguistic, and social tones are the three types of communication tones.
There are five different emotional tones: anger, disgust, fear, joy, and sadness. There are three different linguistic tones: analytical, confident, and tentative. There are five major social traits (Big Five personality traits): openness, conscientiousness, extraversion, agreeableness, and emotional range.
What kind of learning has taken place?
Using machine learning, a model was created to predict the tone of new texts based on conversations. Machine learning was performed using the Support Vector Machine (SVM). Around 30% of samples are associated with more than one tone, so they decided not to use multi-class classification, but rather multi-label classification. The model was trained independently for each tone using the One-vs-Rest paradigm. Final tones were determined by identifying those predicted with at least a 0.5 probability.
Please note that shorter sentences cannot be analyzed. A single sentence may contain up to 128KB of text (about 10 sentences). Customer tweets / Facebook posts on company pages would be a good use case
IV. MUSIC CLASSIFICATION BASED ON MOOD
Classifying music can be challenging because listeners' emotional reactions can vary for the same song. Generally, songs are classified by the overall genre of the artist rather than the feeling evoked by the song. Despite the challenges of categorizing music using engineering techniques, it may help to minimize these discrepancies between listeners. The ability to identify the mood of a piece automatically would be extremely useful for sorting large collections of digital music, such as those found on iTunes and Spotify. Online radio services like Pandora could also use mood to determine similar songs, rather than identifying them by similar artists. It is possible to match songs to specific mood categories based on quantifiable musical components like rhythm, harmony, and timbre when the song is broken down into its quantifiable elements.
There are a number of existing methods of dividing moods in music according to Robert Thayer's traditional model Feelings. The model consists of dividing songs based on their levels of energy and stress, from happy to sad and calm to energetic, respectively (Bhat et al 359). Using Thayer's model he created eight categories that included the extremes of the lines as well as the points where the lines may cross each other (e.g. happy-energetic or sad-calm). Figure 1 illustrates the model.
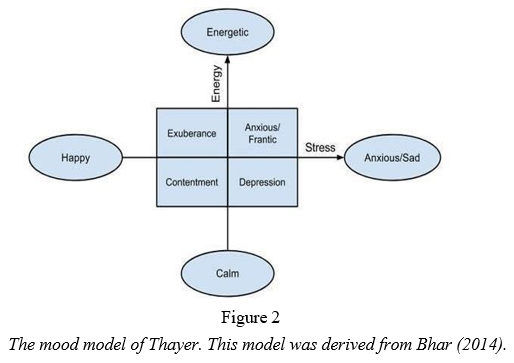
A faster tempo corresponds to a song that has high energy, while a slower tempo corresponds with a song with lower energy. Songs that are loud can be associated with anger, while softer songs suggest tenderness, sadness, or fear (Bhat et al 360). Harmonics create tonal components of a piece that inform the mood of a piece by their timbre. A higher pitch means happiness, carefree mood, and light mood, while a lower pitch means serious, mournful mood. According to researchers at the BNM Institute of Technology in Bangalore, India, timbre stimulates the human energy levels regardless of rhythm or harmonic saturation. Music with simple harmonic profiles tends to have a darker timbre and tends to soothe people. Songs with a lot of intensity represent anger, while soft songs express tenderness, sadness, and fear (Bhat et al 360). emotions” (Bhat et al 360). They also developed a correlation table of intensity, timbre, pitch, and rhythm in order to identify various moods, which can be seen in Table 1.
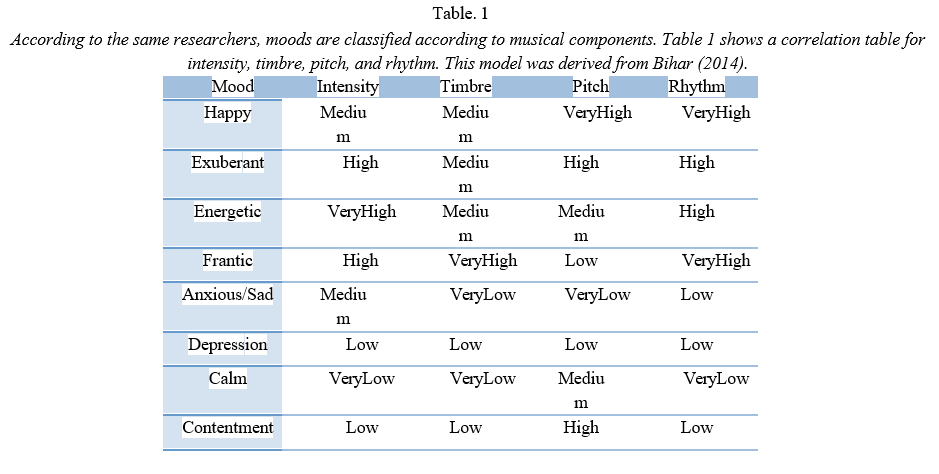
From very low to very high, the music components for all eight of Thayer's mood classifications are shown in table 1. In general, feelings of happiness, exuberance, and energy have higher timbres, pitches, and rhythms than moods of calmness, contentment, and depression. The purpose of this article is to explain how different methods of digital signal processing can be used to identify the rhythm, pitch, intensity, and timbre of musical pieces using DSP.
V. ACOUSTICAL ANALYSIS
Music is an analog signal that is interpreted by our ears - the vibration of air molecules around us. Using sampling, the magnitudes of sound vibrations at many points in time are captured and stored digitally on a computer. A sample is a single magnitude in time. A CD quality recording represents each sample with a 16-bit value, so there are 44,100 samples per second. As these varying magnitudes are applied to the output of the sound card in the computer, they lead to varying voltages that will eventually move the cones of some form of speaker after they are amplified. We will analyze these numerous samples to derive the musical components of a piece. Tempo, or speed, plays a huge role in the rhythm of a piece. An audio beat spectrum can be extracted and the frequency of the beats measured to determine the temp. An accented (stronger or louder) note that is repeated periodically within a piece is called a beat. When matching series of beats are identified, the distance between them can be measured (Bhat et al 360). The strongest kick drum hit in most forms of rock music played in 4/4 time will be on the first beat of the fourth and the strongest snare drum hit will be on the third beat of the fourth. As long as there are drums hitting on beats where the music is louder than on off beats without drums, these hits should be easy to detect. Once one identifies this accented 1 and 3 pattern, one can then determine the length of the 4/4 repetition (one measure) and from that determine the BPM. There is a strong correlation between the tempo of a song and its perceived energy level.
An object's timbre is determined by its harmonic components. The harmonics produce the distinctive sound of an instrument - this is why middle C on a piano can be distinguished from the same note on a violin. Analyzing the frequency responses of two instruments playing the same note allows you to easily identify the timbre difference between them.
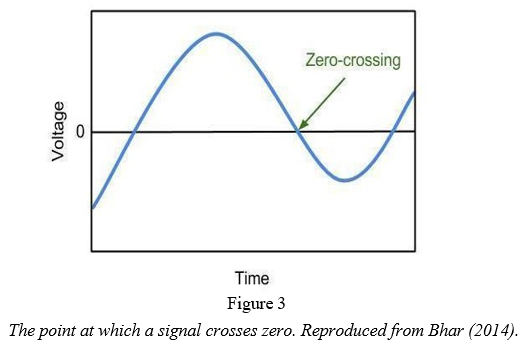
It is much more difficult to determine the difference for an entire piece of music. The zero-crossing rate and spectral irregularity are two of the properties that are analyzed in full songs. Signals crossing the zero line at zero output voltage are said to have a zero-crossing rate. In Figure 2, you can see the zero point. A signal's zero-crossing rate can be an indication of its noise level. The degree of variation between successive peaks in a frequency spectrum is termed spectral irregularity. The amplitude of a peak is calculated by adding the squares of its differences from adjacent peaks. A higher ratio of these two values would indicate more harmonics, and a more saturated overall tone. In Table 1, you can see that higher timbre indicates higher energy in a song. All four higher-energy moods at the top of the table have timbre values of medium or greater, and the four lower-energy moods all have timbre values of low or extremely low.
Vibrations or the size of the vibrating object determine the pitch of a sound. In higher pitched vibrations, faster vibrations are producing higher frequencies, and in lower pitched vibrations, slower vibrations are producing the higher pitches. According to Thayer's model, pitch is a very good indicator of a song's placement relative to the level of stress. For instance, higher-pitched songs usually correspond to higher levels of stress. Higher pitched songs tend to fall under the categories of happy, exuberant, or energetic, while lower pitched songs tend to fall under the categories of anxious/sad, calm, or depressive.
The intensity, or loudness, of a song is determined by its average volume over its entirety. The loudness of a song reflects its position in relation to the amount of energy in Thayer's model. The amplitude of a waveform is one of the major components of intensity. Calculate the RMS (root mean square) of the signal. The root of the squared average of a number of amplitudes is the RMS. The higher the RMS, the higher the intensity, and the lower the RMS, the calmer the piece.
It is difficult to develop and improve algorithms for music mood analysis that can analyze these musical components of a signal and make a decision based on their relative amounts. A number of pre-existing DSP algorithms are used in this analysis such as the fast Fourier transform (FFT), which displays the frequencies present in a time-domain signal. Typically, algorithms for analysis run slowly, and their speed can be improved through code optimization. Various song types can also be used to improve their accuracy through further experiments and data collection.
VI. EXPERIMENTS
A number of experiments are presented in this section to analyze the results of the classification of songs based on various features of the audio. An engineering group from the BNM Institute of Technology in Bangalore, India, will present its work. There were differences in intensity, timbre, pitch, and rhythm in a variety of songs across moods according to an algorithm. To make the classification decision, threshold amounts for each audio feature were compared (Bhar et al.). In Table 2, the average amount of each audio feature in specific moods is shown.
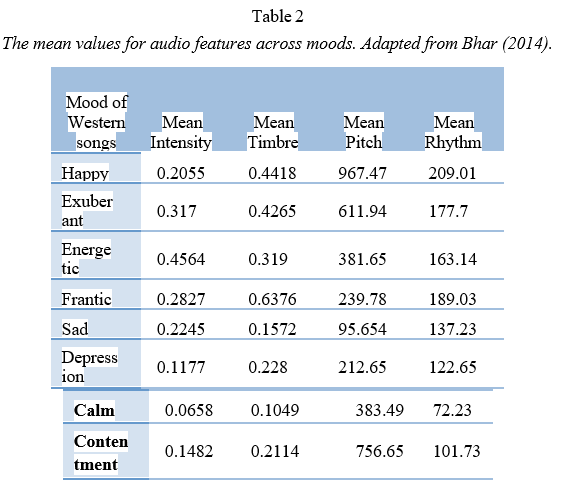
In Table 2, intensity and timbre are presented as normalized values - they should simply be viewed as relative to one another. In Hz, the pitch is expressed as the number of cycles per second, and in BPM, the rhythm is expressed as the number of beats per minute. These results are very consistent with the expectations outlined in the previous section on acoustical analysis. A person in a high-energy mood, such as happy or frantic, has nearly double the rhythm in beats per minute than a person in a low-energy mood like calm or contentment. Contentment or happiness, which are lower stress moods, tend to have a higher average pitch than sad or depressed moods. Table 3 below shows the results of the classification process based on these values.
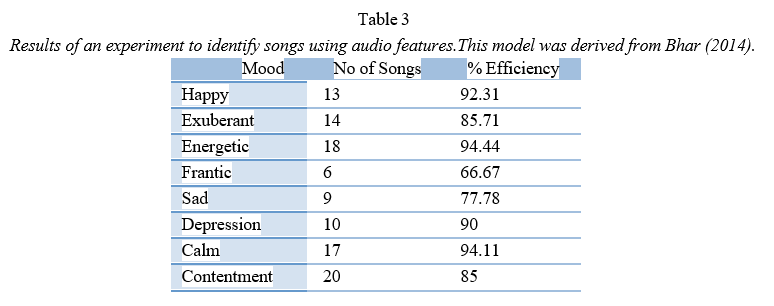
Energy, calmness, and happiness were the most successfully identified moods. All of these are above 90% accuracy, which is very impressive. A mood classification algorithm must be very accurate to be commercially viable. If a significant number of errors were corrected after identification, the value of the algorithm would be diminished, since it is designed to reduce the amount of time the listener will spend listening to individual pieces. Pieces incorrectly identified may have been placed in nearby moods - for example, a calm song may have been wrongly identified as contentment. Experts may find it difficult to distinguish between these areas of the mood scale.
VII. FUTURE/CURRENT USE
The genre of a song is presently determined by the artist when submitting an album or single to a music search engine, such as iTunes or Spotify. Depending on a user's musical preferences, iTunes might suggest albums or artists. The application may display a post below an album that says, "Users who liked this also liked X.". Such a method works well when identifying similar artists or albums on the basis of a store application, but not for songs. Consider an artist who has both upbeat and ballad songs - following purchase of a ballad by the first artist, one should suggest a ballad by another similar artist.
There is technology that can identify the mood of a song, but it hasn't been implemented in commercial music stores. Internet radio applications like Pandora, however, have begun to use more analytical methods when creating playlists. As part of the Music Genome Project, launched by Tim Westergren in 2000, Pandora analyzes song structure to identify similar songs. As of May 2006, its library contains over 400,000 songs by more than 20,000 contemporary artists (Joyce). Up to 450 music characteristics are analyzed by musical experts for every song in the library. Pandora is better able to recognize and respond to an individual's tastes after working with the Music Genome Project, and they state that "the result is a much more personalized radio experience" (Pandora.com).
VIII. IMPORTANCE
It is crucial to filter, prioritize and efficiently deliver relevant information on the Internet, where there is an overwhelming number of choices, to alleviate the issue of information overload, which has created a challenge for many Internet users. Users can benefit from recommender systems by providing them with personalized content and services, searching through a large amount of dynamically generated information. In addition, social networks today are widely used to facilitate social interaction and to share information. The contributions by users provide insight into their behavior, experience, opinions, and interests. Because personality influences many aspects of human behavior, the way we think, and how we feel, it makes sense to enhance the current collaborative filtering recommendation engine by including personality-based qualities. It has been demonstrated that information in a user's social media account reflects the person's actual personality, not their Social networking website Facebook, with its wide user base, provides an ideal platform for users to analyze their own personalities. One of the most popular personality models has been identified as the "Big Five Model" known as the "Five Factor Model" (FFM).
IX. BACKGROUND
In the last decade, researchers have carried out extensive research on the Big Five Model, which is one of the most widely researched and respected measures of personality structure [2]. As a result of analyses of previous personality tests, Tupes and Christal [3] developed a model of five traits of personality: Openness, Conscientiousness, Extroversion, Agreeableness, and Neu-roticism. Across a wide range of age, gender, and cultural lines, McCrae, Costa, and John [4] found generality in five-factor model research. These are the characteristics of the Big Five Model:
In the beginning: Having an open mind means appreciating art, emotion, adventure, unusual ideas, imagination, curiosity, and variety. They are also more likely to hold unconventional beliefs. They tend to be more creative and sensitive. Some of the samples used by people with this tea are energetic. Typically these people are enthusiastic and action-oriented. They are highly visible in groups, like to talk and are assertive. Some sample items used by person with this traits are:
- I like to be the life of the party
- I like to be the life of the party.
- I enjoy being the center of attention.
- The people here make me feel comfortable.
Agreeableness: This trait reflects individual differences in general concern for social harmony. Those who are agreeable value social harmony. Generally, they are considerate, kind, generous, trusting and trustworthy, helpful, and willing to compromise with others. They also have a positive outlook on life. Some sample items used by person with this traits are:
a. I have a heart of gold.
b. People are of interest to me.
c. I put others before myself.
Neuroticism is the tendency to experience negative emotions, such as anger, anxiety, or depression.
- I am easily irritated.
- Stress makes me easily agitated.
- I am easily upset.
X. LITERATURE SURVEY
Conversational interfaces (also known as chat bots) present a new way for individuals to interact with computers. Traditionally, a software program answered a question by using a search engine or by filling out a form. With a chat bot, a user can simply ask questions in the same way they would with a human. Currently, the most well-known chatbots are voice chat bots, such as Alexa and Siri. Nevertheless, chat bots are becoming increasingly popular on computer chat platforms.
Natural language processing is at the core of the rise of chatbots. A recent improvement in machine learning has made natural language processing more accurate and effective, making chatbots an attractive option for many organisations. This improvement in Natural Language Processing is motivating additional research, which should lead to continuous improvements in the Chatbot, which has a very bright future since it will become very common as a website in recent years. Additionally, it is not that expensive, so anyone who has a website can afford it. In recent years, chat bots have become increasingly prevalent in society. There are a lot of studies on chat bots that use different algorithms and how to create advanced chat bots. This study relies heavily on expert knowledge. Any software or applications used by personnel. Chatbots are more effective than humans at reaching out to a large audience via messaging apps. Within the next few years, they may be capable of gathering information. Using natural language processing, the present research seeks to develop a chat bot with various features and to learn about different algorithms.
XI. METHODOLOGY
There is a simple problem statement: recommend music to users from a large collection of songs. A number of live online music recommender systems exist, each using its own methodology to suggest music. For example, Last.fm uses a method in which user activity and similarity scores based on tags, artists, and tracks are considered.
XII. EQUATIONS
The Pandora music service is based on surveys conducted by musicologists. In this case, we use a very basic approach to calculate similarity between artists and songs based on listening events generated by users. Artists and songs are represented as vectors of the play count by each user: Ai = (c1, c2, ...cn) and Sj = (p1, p2, ...pn). where I represents ith artist and i is from 1 to m (i.e., there are 'm' artists); Sj represents j th song and j is from 1 to n (i.e., there are 'n' songs); c1, c2..cn represent the number of times users u1, u2..un listened to an artist, and p1, p2..pn represent the number of times users u1, u2.. The correlation algorithm to be applied is simply a Pearson correlation[6] measure between the vectors of corresponding type.
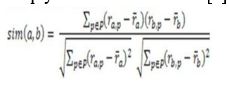
a, b are the two vectors of the same type, p is a user belonging to the group P, ra, p represents the rating of the song/artist represented by vector a; similarly rb, p represents the averaging of all ratings for the songs/artist represented by vector a; similarly rb.
A similarity score for artists/songs is used to generate a list of similar songs/artists in response to the user's request. As no context is considered, i.e., the features of the music are not taken into account. Instead, the list consists of suggestions of similar songs/artists to what the user is currently listening to or has listened to in the past. As a result, the prediction score that represents the likelihood of a song or an artist being recommended to the user is calculated as follows:
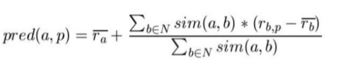
Based on the similarity scores plus the rating for the particular song/artist, this is the weighted average.
A. Planning
- Task 1: Installing the Cake Chat Chatbot server locally Since the Chatbot is the primary component of the project, we will install it first. Understanding this by itself should shed some light on the project.
- Task 2: We will set up the IBM Tone Analyzer API in this milestone in order to analyze the tone of conversation (emotions). Due to the lack of time, data, computational power, or computational power, we are using an API here. This milestone makes it apparent why it is better to use open-source APIs than to create your own model every time.
- Task 3: Setting up the Last.fm Songs API In this milestone, we will test the Last.fm Songs API so we can recommend some songs to the user based on how the user is feeling. Based on the specific tones we have previously collected, we are using an API here because we lack the data, computational power, and time to scrape the web for songs.
- Task 4: We will have a very good understanding of the overall process once we complete this milestone project architecture. In addition, you can take this project in a This milestone will lead to a new direction. Understanding the product architecture is essential to completing this milestone as there are many components that need to be integrated together to create the chatbot.
- Task 5: Once you understand the entire process, you can build the chatbot however you want. A command-line interface can be used to accomplish all of these tasks. A Web Page or API that performs the above steps is also possible.
XIII. TOOLS AND TECHNOLOGIES
A. Python
Python is a widely used high-level programming language for general-purpose programming
Python has an automatic memory management system and a dynamic type system
Multiple programming paradigms are supported, including object-oriented, imperative, and functional
Styles of programming and procedural programming. The standard library is extensive and comprehensive.
B. TensorFlow:
TensorFlow is an infrastructure layer that enables differentiable programming. It's a framework for manipulating N-dimensional arrays (tensors), similar to NumPy.
However, there are three key differences between NumPy and TensorFlow:
- TensorFlow leverages hardware accelerators such as GPUs and TPUs.
- TensorFlow can compute gradients of arbitrary differentiable tensor expressions.
- It is possible to distribute TensorFlow computation to large numbers of devices on a single machine and to large numbers of machines (possibly with multiple devices per machine).
C. Keras layers
Keras is a user interface for deep learning, handling layers, models, optimizers, loss functions, metrics, and more.
TensorFlow handles tensors, variables, and gradients, which are part of differentiable programming.
TensorFlow's Keras API is what makes it simple and productive: Keras is what makes TensorFlow easy and simple.
In Keras, the Layer class represents the fundamental abstraction. Layers encapsulate a state (weights) and some computation (defined in the call method).
- IBM Analyser Conduct Social Listening: Analyze emotions and tones in what people write online, such as tweets and reviews. Find out whether they are happy, sad, confident, etc.
- Enhance Customer Service: You can respond to your customers effectively and at scale by monitoring customer service and support conversations. Verify whether customers are satisfied or frustrated, and whether agents are polite and sympathetic.
Chatbots should be able to distinguish customer tones so they can build dialog strategies that adjust the conversation accordingly.
Conclusion
When a song is broken down into quantifiable elements like rhythm, harmony, and timbre, it can be matched to specific mood categories according to expected data. Even though this classification system is not perfect, it can be used for a variety of technical purposes, such as identifying similar songs for online radio or automating large catalogs of music, as in iTunes. Both the accuracy of the results and the speed with which classification algorithms can be applied will determine the utility of the application. From the above survey we have made it can be concluded that there will be a tremendous growth in the design of chat-bots which will lead to a huge impact on human lives. In addition to this a comparison has been made between several chatbots so far developed which were represented in the form of different algorithms. For developing a good purpose, chatbots require knowledge bases which are extensive. In this project we have made chatbots but also, we can make different types of chatbots like we can also make face recognition bot or speech recognition bot. The major applications in which we can implement this project can be WhatsApp, Facebook, Slack, Telegram, Instagram. We can use this idea as a feature in WhatsApp, Example: - Recently, WhatsApp has added the new feature of payment likewise we can also add this feature to WhatsApp, Facebook, Slack, Telegram, Instagram. The future improvement for the application could be automatic detection of the user\'s mood which could be preceded when the user opens the application. Under these conditions, the emotion detection module could be executed regularly to check for changes in the user\'s communication tone. If there is a change in tone, the user is asked to choose a song. This project will be very helpful for the society to keep them calm and comfortable.
References
[1] K. S. Naveen Kumar, R. Vinay Kumar and K. P. Soman, \"Amrita-CEN-SentiDB 1: Improved Twitter Dataset for Sentimental Analysis and Application of Deep learning\", 2019 10th International Conference on Computing Communication and Networking Technologies (ICCCNT), pp. 1-5, 2019. [2] H.Immanuel James, J.James Anto Arnold, J.Maria Masilla Ruban, M. Tamilarasan and R. Saranya, \"Emotion based Music Recommendation System\", International Research Journal of Engineering and Technology(IRJET), vol. 06, no. 03, Mar 2019. [3] K. Jwala is pursuing M. Tech.(CST) in the department of CSE in S.R.K.R Engineering College, India. She did her B. Tech.(I.T) in the same college.This is the first paper that is going to be published by her. [4] Dr. G. V. Padma Raju is a professor and Head of the department of CSE in S.R.K.R. Engineering College, India. He did his B. Sc.(Physics) from Andhra University and stood second in M. Sc.(Physics) from IIT, Bombay. He stood first in university level in M. Phil. (Computer Methods). He received Ph.D. from Andhra University. He has 30 years working experience as a lecturer. [5] Peter Bae Brandtzæg and Asbjørn Følstad. 2018. Chatbots: Changing User Needs and Motivations. Interactions 25, 5 (2018), 38–43. [6] N. Dahlback, A. J ¨ onsson, and L. Ahrenberg. 1993. Wizard of Oz studies — why and how. ¨ Knowledge-Based Systems 6, 4 (1993), 258 – 266. [7] Steven Dow, Blair MacIntyre, Jaemin Lee, Christopher Oezbek, Jay David Bolter, and Maribeth Gandy. 2005. Wizard of Oz Support Throughout an Iterative Design Process. IEEE Pervasive Computing 4, 4 (Oct. 2005), 18–26. [8] Alan M Turing. Computing machinery and intelligence. In Parsing the Turing Test, pages 23–65. Springer, 2009. [9] Rosalind W. Picard. Effective Computing. MIT press, (321):1–16, 1995 . [10] Qiao Qian, Minlie Huang, Haizhou Zhao, Jingfang Xu, and Xiaoyan Zhu. Assigning personality/identity to a chatting machine for coherent conversation generation. arXiv preprint arXiv:1706.02861, 2017. [11] Huyen Nguyen, David Morales, and Tessera Chin. A neural chatbot with personality. Technical report, Stanford University working paper, 2017. [12] Shivani Shivanand1 , K S Pavan Kamini2 , Monika Bai M N3 , Ranjana Ramesh4 , Sumathi H R. [13] Munira Ansari Computer Engineering, M. H. Saboo Siddik Polytechnic Mumbai, India. Saalim Shaikh Computer Engineering, M. H. Saboo Siddik Polytechnic Mumbai, India. Mohammed Saad Parbulkar Computer Engineering, M. H. Saboo Siddik Polytechnic Mumbai, India Talha Khan M. H. Saboo Siddik Polytechnic Mumbai India. Anupam Singh Computer Engineering, M. H. Saboo Siddik Polytechnic Mumbai, India. [14] Abhishek Das1 , Satwik Kottur2 , Khushi Gupta2*, Avi Singh3*, Deshraj Yadav4 , José M.F. Moura2 , Devi Parikh1 , Dhruv Batra1 1Georgia Institute of Technology, Carnegie Mellon University, 3UC Berkeley, Virginia Tech.
Copyright
Copyright © 2022 Shivam Sakore, Pratik Jagdale, Mansi Borawake, Ankita Khandalkar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET39717
Publish Date : 2021-12-30
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online