

Ijraset Journal For Research in Applied Science and Engineering Technology
Musical Tones Classification using Machine Learning
Authors: K. Sreekar, A. Devansh Reddy
DOI Link: https://doi.org/10.22214/ijraset.2022.48084
Certificate: View Certificate
Abstract
In today\'s scenario, most things are digitized. Music is one of the most famous forms of art, learned by different people and taught by several musicians. Therefore, music information retrieval (MIR) and its applications are gaining popularity following advances in machine learning technology. Various applications such as genre recognition, song recognition, automatic score generation, music transcription, tempo, beat type, etc. have been developed to achieve this goal. However, little research has been done to identify musical instruments. The new method proposed here develops a machine learning model in combination with the Mel-frequency-cepstral-coefficient by extracting audio features directly from the raw audio dataset. A total of 600 audio files containing sound samples from 6 different instruments are used for system training and instrument prediction.
Introduction
I. INTRODUCT?ON
Music is the main part of any song with out that songs won’t get popular, Most of the popular songs has a great match between the theme of song and music beats in background Music directors are responsible form syncing the music beats and vocal song. Here arises the need of identifying the instrument to justify presence of instruments and audibility in any song, This model is very helpful is such cases by computing and identifying the instruments in a audio file. Here we are developing a machine algorithm which can identify the instruments directly from a raw audio file. This algorithm is beneficial to beginner’s who practices professional level music tuning and song composing.
[1] The authors of this article used convolutional neural networks to analyze and classify lung sounds using three distinct types of inputs: MFCC, Spectrograms, and LBP. CNNs have proved indispensable in solving common categorization problems. Their performance, however, is dependent on learning parameters, batch size, and iterations.. [2] The purpose of this study is to provide very basic research and ideas on how to identify musical instruments in a preliminary phase using certain appropriate methodologies. This study used a small quantity of data and aims to expand with a fully labelled dataset for increased efficiency.[3] The presented conclusion is a collaborative data challenge on new monitoring datasets, a summary of machine learning algorithms suggested by challenge teams, a comprehensive performance evaluation, and a discussion of how such detection approaches might be implemented into remote management initiatives.[4] Drones are being utilized more and more in all fields, including hauling loads of products, explosives, and army activities, so testing and development before deployment is critical, and they employed MFCC and LPCC to identify malfunctioning drones with increased precision using propeller sound waves.[5] Because weak sounds are frequently lost or distorted, source separation and noise reduction are unsuccessful.
More training data might be one option, but we believe that, regardless of the fact that our datasets are shorter than the one used in industrially supported application areas, this will not be enough to close the gap. Rather, we believe that improvements in automated pattern identification will be crucial.[6] Reinforcement learning as a technique for detecting and removing reflected artefacts is a possible replacement for geometrical wideband models. We used simulated pictures of raw single photon channel data with numerous sources and artefacts to train a CNN.
In the absence and presence of channel noise, our results indicate that the network can discriminate between a replicated source and an artefact..[7] The purpose of this work was to assess the utility of CNN and TDSN architectures to categorize sound sources using audio spectral spectrum analyzer. Convolutional Layers are commonly used to solve picture categorization issues. This research demonstrates how deep neural networks may be used to classify sounds. [8]
II. PROPOSED ARCH?TECTURE
A. Block diagram Flow
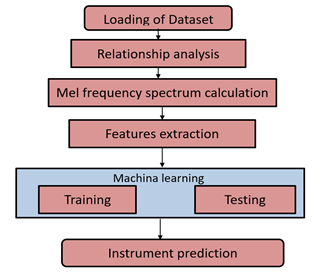
The methodology of our suggested model is described in the following block diagram - based on machine learning model (Fig.1). The contributions to the paper are listed below.
- Features extraction from raw mp3 audio files with Librosa package
- Feature Scaling and Missing Values are used to preprocess the data collection.
- The characteristics are correlated and the relationships between them are displayed.
- Regressors is fitted to the feature set, with and without feature scaling.
.
III. RESULTS AND D?SCUSS?ON
A. Qualitative Anylysis with Dataset
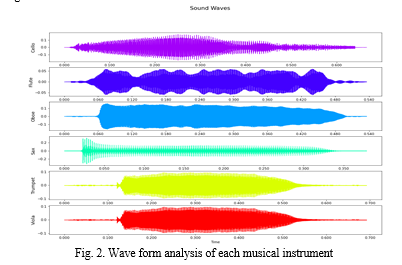
The implementation is based on the raw mp3 music files dataset from the philharmonia world class orchestra website . The dataset consists of six different instuments as follows: (Flue, Sax, Oboe, Cello, Trumpet, Viola). The code was written in Python using Anaconda Navigator and Jupiter notebook. Training and testing datasets are divided 75:25. The music files dataset's exploratory data analysis is displayed in Fig. 2.
B. Quantitative Analysis with different Classifer Algoritham
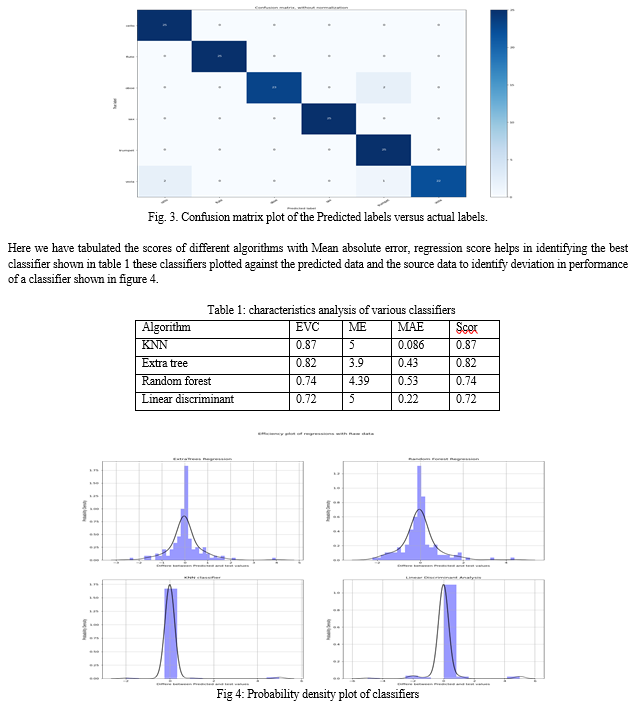
The raw data set is 10 percent trimmed to avoid the null spaces in start and end of audio file, and fitted to KNN classifier and the training dataset is tested and the performance metrics are plotted to find the accuracy of the model with help of confusion matrix shown in fig3.
C. Quantitative Analysis with sugessted model
The dataset is fitted with KNN classifier with knn constant as 5 , Extra tree regressor ,Random forest regressor, Linear discriminant analysis Both the predicted and test data are used data are plotted on the probability plot analysis metrics, allowing us to see the probability of difference between the test and predicted data these analysis shows that KNN classifier is predicting the instruments with 1.75 as its probability score with less deviations towards data is the best classifier classifying the instruments.
Conclusion
This paper performs the exploratory data analysis of the extracting features from raw audio files and also explores the correlation between the features. Dataset is fitted with all regressors to analyze the performance in terms of MAE, MSE, EVS and R-score. Experimental results shows that the KNN classifier performed with an accuracy of 97 percent after feature scaling and from. The undertaking has a huge degree in future. The task can be executed on intranet in future. Undertaking can be refreshed in not so distant future as and when necessity for the equivalent emerges, we are aiming to develop a full automated system that continuously analyze music samples all the day and predicts the instrument name helpful to beginner’s who are starting their journey singers in analyzing songs and instruments accurately.
References
[1] Bardou, D., Zhang, K., & Ahmad, S. M. (2018). Lung sounds classification using convolutional neural networks. Artificial intelligence in medicine, 88, 58-69. [2] Haidar-Ahmad, Lara. \"Music and instrument classification using deep learning technics.\" Recall 67.37.00 (2019): 80-00. [3] Eichner, M., Wolff, M., Hoffmann, R. (2006). Instrument classification using hidden Markov models. system, 1(2), 3. [4] Khamparia, Aditya, Deepak Gupta, Nhu Gia Nguyen, Ashish Khanna, Babita Pandey, and Prayag Tiwari. \"Sound classification using convolutional neural network and tensor deep stacking network.\" IEEE Access 7 (2019): 7717-7727. [5] Stowell, D., Wood, M. D., Pamu?a, H., Stylianou, Y., & Glotin, H. (2019). Automatic acoustic detection of birds through deep learning: the first Bird Audio Detection challenge. Methods in Ecology and Evolution, 10(3), 368-380. [6] Anwar, Muhammad Zohaib, Zeeshan Kaleem, and Abbas Jamalipour. \"Machine learning inspired sound-based amateur drone detection for public safety applications.\" IEEE Transactions on Vehicular Technology 68, no. 3 (2019): 2526-2534. [7] Allman, Derek, Austin Reiter, and Muyinatu A. Lediju Bell. \"Photoacoustic source detection and reflection artifact removal enabled by deep learning.\" IEEE transactions on medical imaging 37, no. 6 (2018): 1464-1477
Copyright
Copyright © 2022 K. Sreekar, A. Devansh Reddy. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET48084
Publish Date : 2022-12-12
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online