

Ijraset Journal For Research in Applied Science and Engineering Technology
Neural Network in Keystroke Dynamics in Biometric Authentication System
Authors: K. Radha , T. Udhayakumar, P. Prabhakaran, G. Pradeepa
DOI Link: https://doi.org/10.22214/ijraset.2022.40826
Certificate: View Certificate
Abstract
In the proposed approach writing speed can be improved by low over head techniques for screening key designs. It is fast and different ways are used to integrate to existing conventions. A more expensive scope of client is allowed to test for equivalent overhead. Proposed method potential predispositions are responsible, so they can be measured and balanced. The comparator has been used a existing standard layout. Mapping both layouts can eliminate differing familiarity and finger memory bias. Delineate it with two cell phone keypad formats: Sam-sung\'s variation of the basic ABC design, and another client particular design (PM). We rehash an examination beforehand attempted by a preparation based technique, which utilized 10 members, and evaluated a 54% speedup for PM (SD=35%). The new strategy utilized 116 members and assessed a 19.5% speedup (SD=7.5%). Wide confidence interval of the training-based methods, differences in test corpuses, and the inherent conservatism of the new method which is used to explain the Differences in speedup estimates. As a result of large test group the effects of user uniqueness tested significantly. There is no obvious effect on any of the measures. ABC and PM performance were significantly related age and keypad experience. Age and Keypad experience does not affect the relative speed. A different experience level of comparison bias has been removed by proposed approach.
Introduction
I. INTRODUCTION
Numerous gadgets utilize keyed contribution for character information. The mapping of the info space (keys) to the yield space (message) the format intensely influences proficiency. Regularly there are various accessible formats: the `de facto standard' QWERTY and the Dvorak designs for English; the North and South Korean designs for Korean. Subsequently we regularly need to contrast two designs one understood with clients, the other new.
Existing strategies for assessing extreme speed, utilizing amplified preparing, require generous exertion and extensive slipped by time with today's short item life cycles, quicker techniques for preparatory assessment are required. One test to testing new designs is the time it can take for members to achieve master execution yet individuals convey involvement with earlier formats to such trials.
We propose a convention utilizing this experience to bolster quick, coordinate correlation, by killing the impacts coming about because of contrasts in nature. We first portray the general thought, and then demonstrate an examination in light of this convention, looking at a customized cell phone keypad design with an outstanding "ABC" format. We think about the hypothetical change in effectiveness, in light of a model of writing velocity, with the exploratory outcomes got from our convention. We finish up with a discourse of the presumptions and confinements of the approach, of the ways it might be adequately joined with different strategies, and some conceivable future augmentations.
Keyed input is used for character data by many devices. Efficiency heavily is affected by mapping of the input space to the output space Keyed input is used for character data by many devices. Efficiency heavily is affected by mapping of the input space to the output space Efficiency heavily is affected by mapping of the input space to the output space. Number of layouts available, “de facto standard” [1]. For English using QWERTY and the Dvorak[2]. The Layouts of north and South Korean keyboards are shown below Fig.1and Fig. 02[3]. Two layouts need to be compared, one popular with users, and other one is unfamiliar. Using extended training, take substantial effort and considerable elapsed time for estimating the ultimate speed by existing methods. Preliminary evaluation is needed, due to today’s short product life cycles and faster methods.

II. EARLIER METHODOLOGIES
In the earlier model, rapid layout comparison was difficult due to more obstacles. The direct comparison of layout is based on familiarity with present biases. Two exact solutions are available for this problem, by using absolute learners, or only if adequate time is given for complete adaptation with the new layout. But these two solutions have grave limitations. Very difficult to find absolute learners among typical children or new language users. On the other hand, long-term users could not use rapid testing environments. Early prototyping is too time consuming for typical one-week training, and the range of test subjects is extremely limited.. The rapid testing protocols have been evaluated by setting several conditions and comparisons; it should satisfy 1. Minimizing the familiarity effect. 2. The level of comparison should be as close to expert as possible. 3. Use as short an elapsed time as possible. 4. From a variety of backgrounds, recruiting a large number of participants is supported by the methodology. 5. On the part of participants, the testing regime should not require a large investment of time.
Generally, familiarity differences are categorized by previous strategies. Such as
- Familiarity issue can be ignored
- Short familiarization session should be provided
- Testing of Novices can be restricted
- Learning process can be observed
A. Familiarity Issue Can be Ignored
Participant groups are created and the results are analyzed independent of familiarity. It is a simple approach and it has been used by researchers who were primarily concerned about achieving initial acceptance of a new design.
III. EXISTING SYSTEM
Keystroke elements are generally separated utilizing the planning data of the key down/hold/up occasions. The hold time or dill time of individual keys, and the dormancy between two keys, i.e., the time interim between the arrival of a key and the squeezing of the following key are ordinarily abused. Digraphs, which are the time latencies between two progressive keystrokes, are usually utilized. Trigraphs, which are the time latencies between each three back to back keys, and correspondingly, n-charts, have been examined as Ill.
In their review on keystroke examination utilizing free content and most part n-diagrams with the expectation of complimentary content keystroke biometrics used to researched the viability of digraphs and when they are word-particular, n-charts are discriminative. In that capacity, the digraph and n-diagram highlights do rely on upon the word setting they are figured in. In the 1970's check and distinguishing proof reasons for existing was initially researched by utilization of keystroke progression. Gaines et al. did a preparatory review on keystroke elements based confirmation utilizing the T-test on digraph highlights. Monrose and Rubin later separated keystroke highlights utilizing the mean and fluctuation of digraphs and trigraphs. Utilizing the Euclidean separation metric with Bayesian-like classifiers, they detailed a right distinguishing proof rate of 92% for their dataset containing 63 clients. Bergadano and later Gunetti and Picardi proposed to utilize the relative request of term times for various n-charts to concentrate keystroke includes that was observed to be more vigorous to the intra-class varieties than total planning. They showed that the new relative component, when consolidated with elements utilizing outright scheduling, enhanced the confirmation execution utilizing free content.
Throughout the years, keystroke biometrics explore has used many existing machine learning and grouping systems. Distinctive separation measurements, for example, the Euclidean separation the Mahalanobis remove, and the Manhattan separate, have been investigated. Both established and propelled classifiers have been utilized, including K-Nearest Neighbor (KNN) classifiers, K-implies strategy, Bayesian classifiers, Fuzzy rationale, neural systems, and bolster vector machines (SVMs). However, it is impractical to make a sound examination of different calculations straightforwardly due to the utilization of various datasets and assessment criteria over the evaluations. To address this issue, keystroke elements databases including benchmark aftereffects of famous keystroke biometrics calculations have been distributed to give a standard exploratory stage to advance evaluation.
Each subject, distributed a keystroke flow benchmark dataset containing 51 subjects with 400 keystroke elements gathered by Killourhy and Maxion. Moreover, they assessed fourteen accessible keystroke flow calculations on this dataset, including Neural Networks, K-implies, Fuzzy Logic, KNNs, Outlier Elimination, SVMs, and so forth. Different separation measurements, including Euclidean separation, This keystroke dataset alongside the assessment technique and best in class execution gives a benchmark to impartially gage the advances of new keystroke biometric calculations.
IV. PROPOSED SYSTEM
Crude information gathered from a particular client's sessions are handled and changed over to monograph and digraph groups. Likewise, at this stage, exceptions are expelled from the mono and digraph sets before passing the information to the following stage. Anomaly expulsion happens just on the enrolment information; no exception evacuation occurs for the test information. I utilize Peirce's measure for the end of exceptions. Peirce's rule is a thorough strategy in view of likelihood hypothesis that can be utilized to dispense with anomalies objectively. It comprises of an iterative procedure which begins with ascertaining the mean and standard deviation for the informational index. In the main cycle a supposition is made that the information has just a single far-fetched perception. In view of that supposition and utilizing the Peirce's table, the most extreme admissible deviation is computed and all sections with more prominent deviations are then dispensed with from the dataset. The quantity of dicey perceptions will be increased by one in each of the following emphases. In each of these emphases, the greatest deviation will be recalculated the keeping up a similar mean and standard deviation of the first dataset. The procedure will be rehashed until no more passages are wiped out.
Computed monograph and digraph mapping tables are considered some portion of the client's mark and put away for some time later. I utilize neural systems to display the client conduct in light of the encoded sets of monographs and digraphs. In spite of the fact that the neural system engineering continues as before for all clients, the Lights are client particular. The proposed neural system design and give a visual portrayal of the monograph and digraph marks created keeping in mind the end goal to show the closeness or divergence in conduct for various clients' sessions.
The accompanying are the modules of the proposed framework that are to be depicted quickly in validation framework.
- Client Enrolment
- Design Analysis
- Neural Network
- Format Creation
- Database Updation
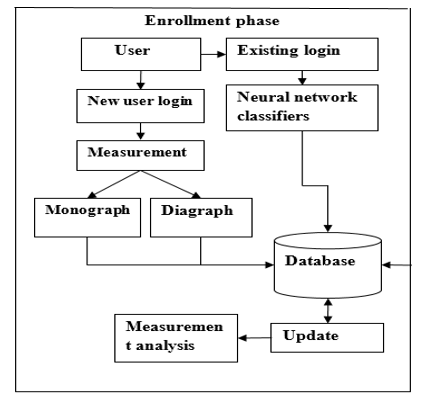
A. Client Enrolment
Keystroke progression is the way toward investigating the way a client sorts at a terminal by checking the console inputs a great many times each second, and endeavors to recognize them in light of periodic cadence designs in the way they write. In this module, client enters their enrollment points of interest and enters client name and watchword. This venture client retypes the secret word four circumstances for future confirmation. The squeezing of a key. The proficiency of programming projects is now and again measured by the quantity of keystrokes it requires to play out a particular capacity.
The keystrokes, assert some product makers, the quicker and more proficient the program. The quantity of keystrokes is for the most part less vital than different qualities of the product. A keystroke is a solitary press of a key on a console. Each key press is a keystroke. Keystrokes can be utilized for programming purposes to react to the client squeezing a specific key. They can likewise be utilized for things, for example, keystroke logging, where a client's keystrokes are followed either with or without the earlier information or assent of the client.
B. Design Analysis
The proposed approach consolidates monograph/digraph estimation with neural system investigation with the expectation of complimentary content acknowledgment. A monograph speaks to the activity of pushing on a key on the console. The activity can be depicted by the key code as the time.
A digraph speaks to a writing activity performed by the client from a particular key to another key on the console. The digraph activity is depicted by the two key codes of the from to keys and the fly time these keys. Monograph investigation approach considers just the keys introduce in the enrolment test, the key mapping procedure is utilized to set up the information for the neural system. Dissimilar to digraph investigation, every single missing monograph will be overlooked amid the examination as Ill as any digraph that contains such keys. In this module, utilize a portrayal for monographs which reflects the approach utilized for digraphs. A digraph speaks to a writing activity performed by the client from a particular key to another key on the console. The digraph activity is depicted by the two key codes of from/to keys and the fly time these keys.

C. Neural Network
Neural systems (NNs) are computational models enlivened by a creature's focal sensory systems (specifically the cerebrum), and are utilized to evaluate or inexact capacities that can rely on upon an extensive number of sources of info and are by and large obscure. Simulated neural systems are for the most part exhibited as frameworks of interconnected "neurons" which can register values from information sources, and are equipped for machine learning as example acknowledgment on account of their versatile nature. Missing digraphs containing keys happening in the enrolment test will be approximated utilizing a key mapping strategy joined with a neural system to decide the normal planning data for the digraphs. The key mapping procedure is utilized to set up the information for the neural system. The neural systems estimated the missing digraphs and model the client conduct in light of the encoded set of digraphs and monographs.
D. Format Creation
In view of neural system can make mark of client named as monograph mark and digraph marks. These marks put away as layout for confirm the client at the season of check. What's more, this layout might be shielded from aggressors. In this module, make designs for key strokes with productive outcomes. The examples incorporate both examples, for example, monograph examples and digraph designs.
Can store the examples with session time. It can be put away as table. The table contains key code and eras and afterward likewise contains fly time.
E. Database Updation
The client signature coming about because of the enrolment mode comprises of the mapping tables and the Lights of the prepared neural systems.
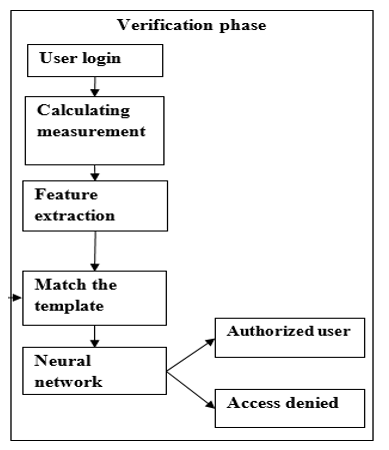
This mark is put away and utilized for the in this mode, the two neural systems will be stacked with the Lights put away in the true blue client's mark. Every monograph and digraph in the checked session will go through the relating mapping module, which uses the mapping table gave by the client's mark. The yield of every module will be passed as contributions to the comparing Mono/Di prepared neural system, which will yield the fly time required for the authentic client to play out the gave Mono/Digraph activity. The distinctions those circumstances and the first dIll/fly circumstances of the observed mono/digraphs speak to the deviations from the true blue client's conduct. The ascertained deviations will be passed to the choice unit that is in charge of settling on a definitive choice about a client's character.

Conclusion
The ability of keystroke dynamics authentication systems for their application to collaborative systems collaborative systems need to authenticate there users. The quality of a keystroke dynamics system is improved by proposed techniques without modification of algorithms. This is a real problem, because with static password based authentication methods, the genuine user can correct himself his typing errors and being correctly authenticated. On the contrary, with our keystroke dynamic implementation, the system will force the user to type again the password in order to have a correct sized vector. The system and algorithms have to be modified to allow the use of backspace key to correct the password because errors can be characteristic of the user. In this project analyse the ability of keystroke dynamics authentication systems for their application to collaborative systems collaborative systems need to authenticate there users. Can see through this study that, even with quite simple methods from the state of the art, the obtained results are almost correct method 2, with less than error but need yet to be improved. One-class neural network with only five vectors per users for the training seems to give better results. it is up to the users of the system to add breaks in their way of typing. Composing keystroke dynamic based passwords by proposed system could be better accepted than the good practice of classical passwords.. In the tested systems, only Ill typed passwords are taken into account.
References
[1] M. Brown and S. J. Rogers, “User identification via keystroke characteristics of typed names using neural networks,” Int. J. Man-Mach. Stud., vol. 39, no. 6, pp. 999–1014, Dec. 1993. [2] F. Monrose and A. Rubin, “Authentication via keystroke dynamics,” in Proc. Fourth ACM Conf. Comput. Commun. Security, pp. 48–56, Apr. 1997. [3] M. S. Obaidat and B. Sadoun, “Verification of computer users using keystroke dynamics,” IEEE Trans. Syst., Man Cybernet., Part B, vol. 27, no. 2, pp. 261–269, 1997. [4] J. Wayman, “Technical testing and evaluation of biometric devices,” in Biometrics: Personal Identification in Networked Society, A. K. Jain, R. Bolle, and S. Pankanti, Eds., KluIr Academic Publishers, 1999. [5] F. Bergadano, D. Gunetti, and C. Picardi, “User authentication through keystroke dynamics,” ACM Trans. Inform. Syst. Security, vol. 5, no. 4, pp. 367–397, Nov. 2002. [6] P. Dowland, S. Furnell, and M. Papadaki, “Keystroke analysis as a method of advanced user authentication and response,” in Proc. IFIP TC11 17th Int. Conf. Inform. Security: Visions Persp, May 7–9, 2002, pp. 215–226. [7] S. Ross, “Peirce’s criterion for the elimination of suspect experimental data,” J. Eng. Technol., vol. 20, no. 2, pp. 38–41, Oct. 2003. [8] S. Bengio and J. Mariethoz, “A statistical significance test for person authentication,” in Proc Odyssey 2004: The Speaker and Language Recognition Workshop, 2004. [9] D. Gunetti and C. Picardi, “Keystroke analysis of free text,” ACM Trans. Inform. Syst. Security, vol. 8, no. 3, pp. 312–347, Aug. 2005. [10] M. Villani, C. Tappert, N. Giang, J. Simone, St. H. Fort, and S.-H. Cha, “Keystroke biometric recognition studies on long-text input under ideal and application-oriented conditions,” in Proc. 2006 Conf. Comput. Vis. Pattern Recognit. Workshop (CVPRW’06), June 2006, p. 39. [11] L. Ballard, D. Lopresti, and F. Monrose, “Forgery quality and its implication for behavioral biometrics security,” IEEE Trans. Syst. Man Cybernet., Part B, vol. 37, no. 5, pp. 1107–1118, Oct. 2007. [12] M. E. Schuckers, Computational Methods in Biometric Authentication, Springer, 2010. [13] R. Giot, M. El-Abed, B. Hemery, and C. Rosenberger, “Unconstrained keystroke dynamics authentication with shared secret,” Comput. Security, vol. 30, no. 6–7, pp. 427–445, June 2011. [14] D. Polemi. “Biometric techniques: Review and evaluation of biometric techniques for identification and authentication, including an appraisal of the areas where they are most applicable
Copyright
Copyright © 2022 K. Radha , T. Udhayakumar, P. Prabhakaran, G. Pradeepa. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET40826
Publish Date : 2022-03-17
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online