

Ijraset Journal For Research in Applied Science and Engineering Technology
NewsIN: A News Summarizer and Analyzer
Authors: Anushree B Salunke, Eisha Saini, Sanskruti Shinde, Pooja Tumma, Suchita Suresh Dange
DOI Link: https://doi.org/10.22214/ijraset.2022.47997
Certificate: View Certificate
Abstract
A summary condenses a lengthy document by highlighting salient features. It helps the reader to understand completely just by reading a summary so that the reader can save time and also can decide whether to go through the entire document. Summaries should be shorter than the original article so make sure to select only pertinent information to include the article. The main goal of a newspaper article summary is, the readers to walk away with knowledge on what the newspaper article is all about without the need to read the entire article. This work proposes a news article summarization system which access information from various local online newspapers automatically and summarizes information using heterogeneous articles. To make ad-hoc keyword-based extraction of news articles, the system uses a tailor-made web crawler which crawls the websites for searching relevant articles. Computational Linguistic techniques mainly Triplet Extraction, Semantic Similarity calculation and OPTICS clustering with DBSCAN is used alongside a sentence selection heuristic to generate coherent and cogent summaries irrespective of the number of articles supplied to the engine. The performance evaluation is one using the ROUGE metric. The rapid progresses in digital data acquisition techniques have led to a huge volume of news data available in the news websites. Most of such digital news collections lack summaries. Due to that, online newspaper readers are overloaded with lengthy text documents. Also, it is a tedious task for human beings to generate an abstract for a news event manually since it requires a rigorous analysis of the news documents. An achievable solution to this problem is condensing the digital news collections and taking out only the essence in the form of an automatically generated summary which allows readers to make effective decisions in less time. The graph based algorithms for text summarization have been proven to be very successful over other methods for producing multi document summaries. The summary generated from knowledge graphs is more in line with human reading habits and possesses the logic of human reasoning. Due to the fast-growing need of retrieving information in abstract form, we are proposing a novel approach for abstractive news summarization using the knowledge graphs to fulfill the need of having more accurate automatic abstractive news summarization and analyzer.
Introduction
I. INTRODUCTION
News is one of the foremost critical channels for obtaining data. In any case, it is more troublesome to extricate comparisons in news articles than in audits. The viewpoints are exceptionally different in the news. They can be the time of the occasions, the individual included, the states of mind of members, etc. These angles can be communicated expressly or verifiably in numerous ways. For illustration, “storm” and “rain” both talk around “weather”, and hence they can shape a potential comparison. All these issues raise awesome challenges to comparative summarization within the news domain. The errand of news summarization is to briefly entirety up the commonalities and contrasts between two comparable news points by utilizing human discernable sentences. The summarization framework is given two collections of news articles, each of which is related to a subject. The framework ought to discover idle comparative perspectives, and produce depictions of those viewpoints in a pairwise way, i.e. counting portrayals of two themes at the same time in each viewpoint. For illustration, when comparing the seismic tremor in Haiti with the one in Chile, the rundown ought to contain the escalation of each temblor, the harms in each fiasco zone, the responses of each government, etc.These days the huge volume of data in electronic frame is expanding quickly. It can be organized information like databases, company bequest information; or unstructured information like content, pictures etc. Around 85 to 90% of information is held in unstructured frames. Subsequently, content mining is essential for extricating and overseeing valuable data from unstructured sets of information, such as news reports, emails and web pages, utilizing different content mining procedures. Hence, text mining has become an imperative and dynamic inquiry about the field.
It is well known that content mining strategies have for the most part been created for the English dialect since most electronic information is in English. Utilizing this to our advantage, it is an self-evident another step to utilize these procedures for filtering through the large number of accessible online information to mine truths and figures from different sources and after that summarize them proficiently to utilize in following different occasions in and around an range beneath Police law.
In this paper, the data extraction of news articles is based on computational etymological methods to summarize the content. The summarization handle includes sifting, highlighting and organizing data which is concise, coherent and steadfast to the initial record. With the quick development of the broadcast frameworks, the web and online data administrations, increasingly data is accessible and available. Blast of data has caused a well recognized data over-burden issue. There's no time to examine everything and yet we ought to make basic choices based on anything data is accessible. Programmed summarization, done by machine, postures a or maybe challenging issue to computer researchers, due to the abstractness and complexity of human dialects. This issue was recognized and handled early within the 1950s. Since then a few well-known calculations have been created, but the accomplishment was bound by the confinement of the current Normal Dialect Processing technologies, and until nowadays it still remains an dynamic inquiry about the theme. The objective of this venture isn't to move forward on the existing calculations, but to consider and apply these calculations, combining with other valuable methods to deliver common sense. It recovers broadcast tv news from a record, analyzes the substance to recognize news stories by subtopic dialog. Substance of each story is summarized and imperative catchphrases are extricated. This data is to be put away in a central database, and a Data Recovery framework is to be actualized which lets clients hunt for any piece of news within the database. Such a framework has an advantage over other search engines, as we utilize summarization methods to find the story he/she is searching for in a shorter time, when compared to a standard content based look engine.
The key assignments in summarization are as follows:
- Consequently extricate online articles from news websites based on a keyword.
- Partition whole articles as a gathering of sentences, which acts as the dataset for advance processing.
- Speaking to sentences in a machine discernable and justifiable format.
- Identifying semantic likeness between sentences so as to dispense with real excess in summary.
- Clustering comparative sentences to recognize between semantically distinctive sentences.
- Picking sentences among clusters which speak to the data displayed by the comparing cluster.
- Orchestrating the sentences chronologically to show the advancements as they happened.
News is one of the foremost critical channels for obtaining data. Be that as it may, it is more troublesome to extricate comparisons in news articles than in surveys. The viewpoints are exceptionally different in the news. They can be the time of the occasions, the individual included, the states of mind of members, etc. These perspectives can be communicated unequivocally or certainly in numerous ways. For example, “storm” and “rain” both talk about “weather”, and in this way they can frame a potential comparison. All these issues raise extraordinary challenges to comparative summarization within the news domain. The assignment of news summarization is to briefly whole up the commonalities and contrasts between two comparable news themes by utilizing human lucid sentences. The summarization framework is given two collections of news articles, each of which is related to a point. The framework ought to discover idle comparative viewpoints, and create portrayals of those angles in a pairwise way, i.e. counting portrayals of two points at the same time in each perspective. For illustration, when comparing the seismic tremor in Haiti with the one in Chile, the rundown ought to contain the concentration of each temblor, the harms in each calamity zone, the response of each government, etc.
II. LITERATURE SURVEY
[1] An outline condenses a long record by highlighting notable highlights. It makes a difference for the peruser to get it totally fair by perusing rundown so that the peruser can spare time and can choose whether to go through the complete report. Rundowns ought to be shorter than the first article so make beyond any doubt that to choose as it were relevant data to incorporate the article. The most objective of newspaper article summary is, the readers to walk absent with information on what the daily paper article is all approximately without the have to peruse the complete article. This work proposes a news article summarization framework which gets to data from different nearby on-line daily papers consequently and summarizes data utilizing heterogeneous articles. To form ad-hoc watchword based extraction of news articles, the framework employs a tailor-made web crawler which slithers the websites for looking at significant articles.
Computational Phonetic procedures primarily Triplet Extraction, Semantic. Closeness calculation and OPTICS clustering with DBSCAN is utilized nearby a sentence determination heuristic to create coherent and persuasive rundowns independent of the number of articles provided to the motor.
The execution assessment is done utilizing ROUGE metric. Extraction of a single rundown from numerous reports has intrigued since the mid-1990s, most applications being within the space of news articles. A few Web based news clustering frameworks were propelled by inquiry about multi-document summarization, for illustration Columbia NewsBlaster, or News In Substance.
Typically distinctive from single-document summarization since the issue includes different sources of data that cover and supplement each other, and evacuation of repetitive realities which are displayed in a semantically comparative but syntactically diverse structure. Content Summarization has continuously been a region of dynamic intrigue within the scholarly community. In later times, indeed in spite of the fact that a few strategies have been created for programmed content summarization, proficiency is still a concern. Given the increment in estimate and number of reports accessible online, an productive programmed news summarizer is the require of the hour. In this paper, we propose a strategy of content summarization which centers on the problem of distinguishing the foremost imperative parcels of the content and creating coherent rundowns. In our strategy, we do not require full semantic translation of the content, instead we make a summary employing a show of theme movement within the content determined from lexical chains. We show an optimized and proficient calculation to create content rundown utilizing lexical chains and utilizing the WordNet thesaurus. Within the time of present day Information science and Big Data, it is not a ponder to empower machine learning to get its human dialect and know what individuals are feeling and considering with their surroundings. The term is called Opinion Examination or Supposition Mining which combines the power of normal dialect preparation, content examination and computational etymology to classify subjective information or the passionate state of the writer/subject/topic. Rather than just identifying a positive/negative/neutral estimation, being able to extricate catchphrases that intensifies different feelings such as bliss, fervor, dissatisfaction, fear etc. from the substance. Progresses in individual computing and data innovations have in a general sense changed how maps are created and expanded, as numerous maps nowadays are exceedingly intelligent and conveyed online or through portable gadgets. Appropriately, we ought to consider interaction as an essential complement to representation in cartography and visualization. UI (client interface) / UX (client encounter) portrays a set of concepts, rules, and workflows for fundamentally considering the plan and utilization of an intuitive item, map-based or something else. To see what the world is looking for, there's a Trending Looks page expansion to Google Trends that distributes the foremost frequently searched terms alongside their look volume and related news stories of the past 24-hour across different nations. The URL of every day search trend list is accessible at https://trends.google.com/trends/trendingsearches/daily?geo=US. For this project, the first trending look theme is chosen and analyzed to form a content analytics visualization report. To get the foremost later information about the look subject, different news articles related to the look topic and Twitter information source is used. Advance, we moreover overcome the restrictions of the lexical chain approach to produce a great rundown by executing pronoun determination and by recommending unused scoring strategies to use the structure of news articles. The prior approaches in content summarization centered on deriving content from lexical chains produced amid the topic progression of the article. These approaches were preferred since it did not require full semantic elucidation of the article. The approaches moreover blended a few strong knowledge sources like a part-of-speech tagger, shallow parser for the identification of ostensible bunches, a division algorithm and the WordNet thesaurus. According to Wikipedia, WordNet could be a lexical database for the English dialect. It bunches English words into sets of synonyms called synsets, gives brief definitions and usage examples, and records a number of relations among these synonym sets or their individuals. For illustration two faculties of “bike” are spoken as: cruiser, bicycle and bicycle, bike, wheel, cycle.
[2] Words of the same category are linked through semantic relations like synonymy, which is the study of words with the same or comparative meaning, or the quality of being comparative, and hyponymy, which relates to words of more particular meaning than a common or superordinate term applicable to it. A commonly used example to demonstrate hyponym is: daffodil, which may be a hyponym for blossom.
[4] All these information sources are freely accessible substances. This project speaks to a framework that allots opinion scores and extricates key feelings associated with the conclusion communicated in these news stories and Twitter posts on a certain trending search topic. In spite of the fact that full comprehension of characteristic dialect content remains well past the control of machines, the actualized measurable investigation of tolerably straightforward opinion signs can provide an important quantitative rundown of these expansive sums of subjective information. The venture is essentially executed on Microsoft Control BI, Python and R programming platforms. Power BI may be an information visualization device that underpins a huge run of information sources (for all intents and purposes any data source) to stack, change and clean the information into an information model. An awesome version of Control BI is ready to interface to a web page and convert its information into a dataset. In Control BI, the dataset is usually alluded to as an Inquiry or Table. Morris, Jane and Hirst to begin with presented the concept of lexical chains. In any given article, the linkage among related words can be utilized to create lexical chains. A lexical chain may be a consistent gathering of semantically related words which delineate a thought within the archive. The connection between the words can be in terms of equivalent words, characters and hypernyms/hyponyms. These relations can be utilized to bunch things occurrences in a lexical chain given the condition that each thing is allocated to only one chain.
The challenging errand here is deciding the chain to which a specific thing will be doled out since it may have different faculties or settings. Too, indeed in spite of the fact that there's a single setting for the noun usage, it may well be still ambiguous to decide the lexical chain. This passage presents center concepts from UI/UX plan critical to cartography and visualization, centering on issues related to visual plan. To begin with, a principal qualification is made between the utilization of an interface as an instrument and the broader encounter of an interaction, a refinement that isolates UI plan and UX plan.Norman’s stages of the interaction system at that point is summarized as a direct demonstration for understanding the client encounter with intuitive maps, noticing how diverse UX plan arrangements can be connected to breakdowns at diverse stages of the interaction. At last, three measurements of UI plan are depicted: the basic interaction administrators that frame the essential building pieces of an interface, interface styles that execute these administrator primitives, and suggestions for visual plan of an interface. Summarization has been seen as a two-step process.
[3] The first step is the extraction of vital concepts from the source content by building a halfway representation of some sort. The moment step employs this middle of the road representation to create a rundown. To analyze and get a huge amount of unstructured information like client conclusion, user feedback, item audits, Content Analytics is utilized to determine meaning out of content and written communications. There are a few diverse strategies utilized to analyze content and unstructured data. To rapidly distinguish common themes and issues that arise among clients, recurrence of these themes can be numbered. Some of the time a bunch of words can provide more understanding than a fair one word alone. Interior GIScience interaction most commonly is treated by the exploration push of geographic visualization. Interactivity reinforces visual thinking, engaging clients to externalize their thinking by inquiring a wide run of one of a kind diagram representation, thus overcoming the hindrances of any single diagram arrangement. Geovisualization engages this instinctively considering the reason for examination rather than communication, with the objective of making present day hypotheses and unconstrained encounters around darkened geographic wonders and shapes. As a result, much of the early work on interaction in cartography and visualization is specific to coherent disclosure, considering ace experts as the target client bunch. UI and UX are not the same, isolated in their center on interfacing versus intelligence. An interface may be an apparatus, and for advanced mapping this instrument empowers the client to control maps and their fundamental geographic data. An interaction is broader than the interface, depicting the two-way question-answer or request-result discourse between a human client and a computerized question interceded through a computing gadget. Subsequently, an interaction is both contingent—as the reaction is based on the task, making loops of interactivity—and empowering—giving the client organization within the mapping prepare with changes unexpected on his or her interface and needs. Our overview into the work wiped out the field of summarization examined and made a difference in the issues mentioned and the challenges within the field. We implemented the basic lexical chain demonstrated as examined by Silber and McCoy and after that included our upgrades to resolve the issue of anaphora determination and time complexity of lexical chain era. Since we are summarizing news articles, a few extractions on the basis of legitimate things is essential. We earlier described our scoring procedure for legitimate nouns. Nowadays, UI/UX plan requires thought to utilize cases past exploratory geovisualization and clients past master analysts. Interaction permits clients to see numerous areas and outline scales as well as customize the representation to their interface and needs. Interaction moreover engages clients within the cartographic plan handle, progressing availability to geographic data and dissolving conventional boundaries between mapmaker and outline client.
[4] Progressively, interaction empowers geographic examination, connecting computing to cognition in order to scale the human intellect to the complexity of the mapped wonder or prepare. In like manner, interaction has been recommended as an essential complement to representation in cartography, together organizing modern cartographic grant and hone. For dialog of extra impacts on UI/UX plan in cartography and visualization, see Geocollab. Content analytics offer tremendous openings for companies in any case of industry. Companies and individuals need to settle on superior educated commerce choices based on identifiable and quantifiable knowledge. With movements in Content Examination, companies can presently be able to mine text to get experiences and make strides to their benefit to thrive within competitive advertising. There are countless businesses that can be benefitted by applying content analytics to collate and act on company’s information. Maybe, the application is most suited to showcase information about the media space that a company lives in and how it is gotten by its gathering of people. We were able to auto-summarize news articles and compare outlines created by them to analyze what scoring parameters would lead to way better results. Within the handle, we tweaked strategies we had investigated on to use the fact that we were managing with news articles as it were. We found that journalists take after a settled design to type in a news article. They start with what happened and when it happened within the first paragraph and proceed with an elaboration of what happened and why it happened within the talking after sections. We wanted to use this information while scoring the sentences by giving the things showing up within the to begin with sentence the next score. But after checking on the preparatory comes about our scoring method as depicted in Barzilay and Elhadad we realized that the first sentence always got a high score since it had things that were rehashed a few times within the article.
This can be intuitively consistent since the primary sentence of the article continuously has nouns that the article talks about almost. A number of disciplines, callings, and information ranges contribute to UI/UX plan, counting ergonomics, realistic plan, human-computer interaction, data visualization, brain research, convenience building, and web plan. Extra systems for understanding UX plans have been advertised as UX gets to be formalized conceptually and professionally. For occurrence, Fitts’ law giving an early understanding of indicating intuitive was based on brain research thinks about almost human substantial development, Encourage, Foley et al.’s three plan levels were determined from inquire about on human-computer interaction whereas Garrett’s five planes of plan are advertised from web plan involvement. At last, most proposals depict UI/UX experience. At long last, most proposals portray UI/UX as a plan prepare that incorporates numerous, user-centered assessments, making use of strategies and measures built up in Ease of use Designing (see Convenience Building). In later years, the blast of social media has made accessible an exceptional sum of real-time information to a degree of open conclusion. Agreeing to the Unused York Times, more than one billion election-related tweets were posted on Twitter amid the final presidential decision, from the to begin with presidential talk about until decision day. As a social media stage, Twitter has emerged as a well-known communication channel between pioneers of challenging parties and voters. Amid decision campaigns, the challenging parties and voters express their conclusions on Twitter generating a tremendous sum of unstructured information. Interested parties can utilize this information to monitor election campaigns, gauge political polarization and negative campaigning, and indeed forecast election comes about combined with conventional off-line race surveying at any point in time. The Text Analytics module of this framework can offer assistance to reply to a few basic questions like which issues are getting more consideration from the open, what candidates are gathering more positive / negative sentiment, people’s response to occasions amid the decision campaign in genuine time etc. As with representation plans and the visual factors, an interaction can be deconstructed into its essential building pieces. Interaction primitives portray the basic components of interaction that can be combined to make an interaction technique. Researchers in cartography and related areas identify advancement of a scientific categorization of interaction primitives as the foremost squeezing required for the understanding of interaction, as such a scientific categorization verbalizes the total solution space for UI/UX plan. In like manner, there are presently a run of scientific categorizations advertised within the UI/UX writing, counting scientific categorizations particular to cartography and visualization.
III. PROBLEM STATEMENT
In today's society, news may be found on a variety of platforms, but it can be difficult for individuals to grasp them. This is owing to the news's unstructured style. People do not have the time to read the entire news. As a result, people are unaware of what is going on in the globe.
In the current world situation when there is a rapid increase in technology, the data on the World Wide Web is increasing at a tremendous rate. Because the web is always developing, the news that may appear there may not give a comprehensive picture of the story.
IV. OBJECTIVE AND SCOPE
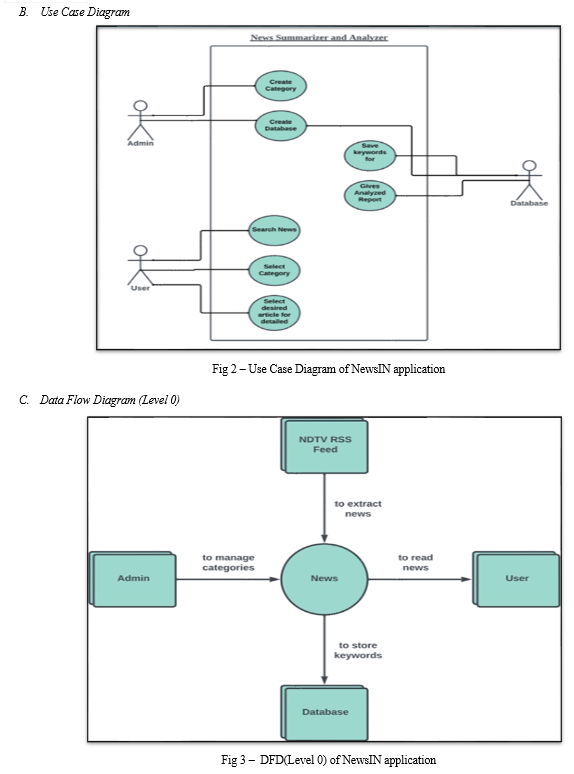
- To extract data from a News Website.
- To categorize the news as per the domains.
- To provide summarize content of the news
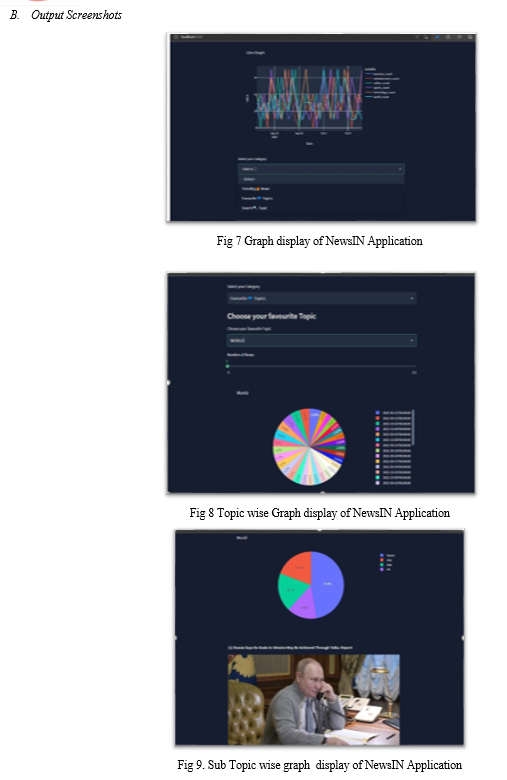
- To provide the analyzed news in the form of graphs, charts along with categories.
- To extract data through news Website
- Segregating that news as per the Domain
- Summarizing the news and displaying them
- As per category displaying that data in graphical representations
V. EXPERIMENTAL SETUP
A. Software Requirement
- Operating System – Windows
- Python 3.10 and above
- Visual Studio Code
- Natural Language Processing (NLP)
- Plotly – 4.0 and above
- HTML 5, CSS 3
- MySQL – 8.0.23 and above
- Application connected via – News website
- NLTK
B. Hardware Requirements
- Intel Core i3 10th generation processor or higher
- RAM – 4 GB or above
- ROM – 128 MB or above
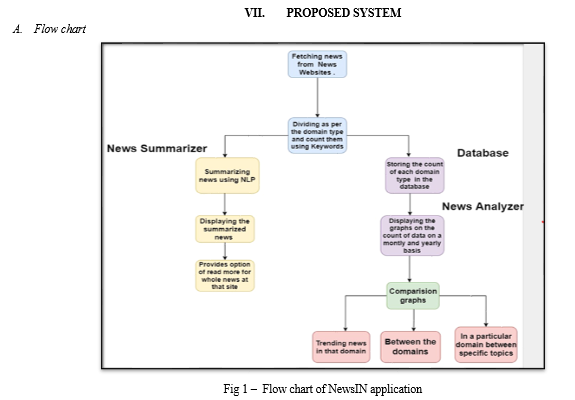
VI. METHODOLOGY
- Import the modules which include PIL from Image library which is used for importing Images from the website, newspaper from Article library used to import news, punkt from nltk library for summarizing the news, plotly. express library for analyzing the news
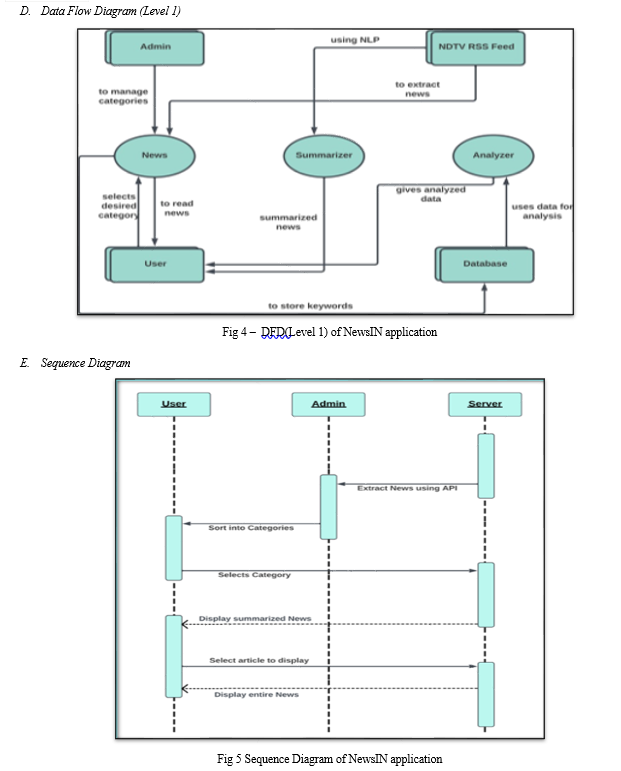
- Extracting the news from RSS feed which is an XML file
- As per the different domains like World, Entertainment, Sports, Technology, etc., the news will be segregated based on keywords stored
- For getting the ratio of those domains will further store the domain data count
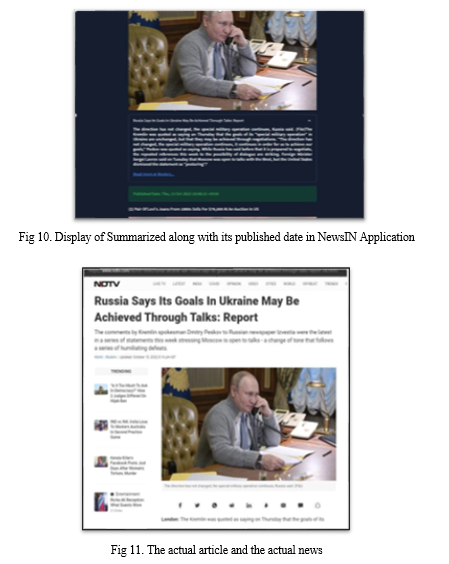
- Using the punkt algorithm from the nltk library, the summarized news will be displayed
- Using the stored keywords we will perform analysis using plotly library
- Plotly library provides online graphing, analytics, and statistics tools
- The pie charts for particular domains were represented using the daily domain data count.
- We represented the Line graph of all the domains using the weekly domain data count
VIII. PROJECT IMPLEMENTATION
A. Algorithm
- Import all the Modules.
- Initialize a variable with 'Analyzer.xlsx'.
- Initialize function search topic.
- Open site
- Read
- Initialize news_list=sp_page.findall('item') #finding news
- return news_list
- Repeat from steps 3 for various functions of various categories.
- Initialize function news_poster.
- Open poster link
- Read data
- Open Image
- Close function
- Initialize run() function
- Select category=[' --select-- ', 'Trending News', 'Favorite Topics', 'Search Topic']
If category[0] warning("Please select type !")
elif category[1] show trending news
elif category[2] select favorite topic
show favorite topic
eilf category[3] enter your topic
show entered topic
16. End
Conclusion
In this project, we were able to accurately summarize the news and show the data on the User Interface. News was shown on the application according to the particular domain that was chosen, and many additional features were also available to assist the user acquire accurate information. Various visuals have been used to illustrate the facts in diagrammatic way. [1] With the help of these graphs, the user will be able to assess the state of the world. We have gathered the most recent news items from various news websites, sorted them, and then displayed them all in one place using the News API. The news summary gives the user a broad understanding of the story\'s subject matter and its current worldwide ramifications. After analysis, we found that the introductory sentence regularly obtained high marks because it contained nouns that were used often in the text[2]. The initiative gave us insight into daily news patterns, such as which stories are more widely read than others. What search terms were utilised to spread that news? What makes the popularity of the news different? It is a platform that aids in making the page more dynamically displayed[4]. R programming languages have been used for the majority of text analytics projects[3]. However, we attempted to improve the effectiveness and accuracy of the information we are delivering and did this using the Python programming language.
References
[1] Rananavare, Laxmi & Reddy, P.. (2018). Automatic News Article Summarization. International Journal of Computer Sciences and Engineering. 6. 230-237. doi: 10.26438/ijcse/v6i2.230237.HTTPS://WWW.RESEARCH GATE.NET/PUBLICATI ON/ 325775102_AUTOMATIC_NEWS_ARTICLE_S UMMARIZATION [2] P. Sethi, S. Sonawane, S. Khanwalker and R. B. Keskar, \"Automatic text summarization of news articles,\" 2017 International Conference on Big Data, IoT and Data Science (BID), 2017, pp. 23-29,doi: 10.1109/BID.2017.8336568.HTTPS://IE EEXPLORE.IEEE.ORG/DOCUMENT/8336568 [3] Nahar, J., Kline, D, Layman, L., Modares Nezhad, M. (2019) Daily Text Analytics of News and Social Media with Power BI. Annals of the Master of Science and Information Systems at UNC Wilmington, 13(2) paper 2. http://cs bapp.unc w.edu/data/mscsis/full.aspx HTTPS://UNCW.EDU/CSB/MSCSIS/COMPLETE/PDF/NAHAR_FALL2019.PDF [4] Roth, Robert. (2017). User Interface and User Experience Design. Geographic Information Science and Technology Body of Knowledge. 2017, doi: 10.22224/gistbox/ 2017.2.5.HTTPS://WWW .RESEARCHGATE.NET /PUBLICATION/31 7660257_USER_I NTERFACE_AND _USER_EXPERIEN CE_UIUX_DESIG NNES_SUMMARIZATION_AND_ANALYZER.PPTX [5] Developer Documentation for Web Development HTTPS://DEVDOCS.IO
Copyright
Copyright © 2022 Anushree B Salunke, Eisha Saini, Sanskruti Shinde, Pooja Tumma, Suchita Suresh Dange. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET47997
Publish Date : 2022-12-08
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online