

Ijraset Journal For Research in Applied Science and Engineering Technology
Object Detection Using Machine Learning and Deep Learning
Authors: Rahul ., Deepika Bansal
DOI Link: https://doi.org/10.22214/ijraset.2023.48958
Certificate: View Certificate
Abstract
An object detection system finds objects of the real-world present either in a digital image or an object detection system locates real-world items that are present in a digital image or a video. These objects can be any type of object, such as people, automobiles, or other objects. A model database, a feature detector, a hypothesis, and a hypothesis verifier are the four components that the system must have in order to successfully detect an item in an image or video. This paper provides an overview of the many methods for object detection, localization, classification, feature extraction, appearance information extraction, and many other tasks in photos and videos. The remarks are derived from the literature that has been analyzed, and important concerns are also noted.
Introduction
I. INTRODUCTION
Object detection If you've ever wondered how face unlock works on your smartphone or how a self-driving car runs on its own, the answer is object detection. Object detection may sound like the pinnacle of artificial intelligence, yet it coexists with us in our daily lives, lurking in plain sight. So, what exactly is object detection? In terms of technology, object detection entails computer vision and image processing that are used to identify objects in pictures or videos. As an illustration, consider how self-driving cars use a moving object detection technique along with computer vision and image processing to generate alerts and direct the moving vehicle. Artificial intelligence is the technology that powers this technology.
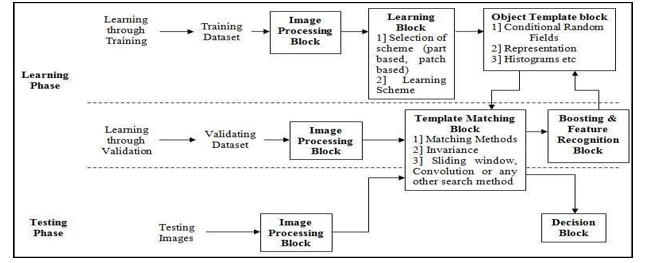
A. Graph based OD
Approach to the image segmentation problem is to represent the image As a graph,, and then segmentation essentially,. is finding cuts in the graph.. so let's take a look at how we represent an image as a graph. There is an image and we can simply say that every pixel in the image is a vertex., and we have an edge between pair of pixels, perhaps not, all pair of pixels, just a pair of pixels that are close to each other. so then the notation is that we have a graph G with vertical V and edge E. and each edge has await associated with it, so each edge is weighted. The affinity or similarity between its two vertices of pixels So this notion of affinity is very important to the way this segmentation works and so, let's take a look at the concept of affinity.
B. Fuzzy Based ODS
Fuzzy colour constancy (LLFCC) algorithm for dynamic colour object recognition. This approach focuses on manipulating a colour locus which depicts the colours of an object. A set of adaptive contrast manipulation operators is introduced and utilised in conjunction with a fuzzy inference system and a new perspective in extracting colour descriptors of an object are presented. Again the question here arises about what colour ranges can be detected feasibly. Munoz-Salinas et al. (2004) make use of the information provided by the camera of a robot in order to assign a belief degree on the existence of a door in it; this is done by analysing the segments of the image. Several fuzzy concepts are defined to lead the search process and find different cases in which doors can be seen. Features of the segments like size.
II. OPEN AND KEYS ISSUES IN OD
Following are the issues in the field of OD:
- Is it necessary to scan the whole image in order to locate the object?, i. e., speed up.
- How to combine the classifiers?, i.e., accuracy.
- Which are good sets of classifiers that are needed to be combined?, i.e., accuracy.
- When and how should the combined classifiers be trained?, i.e., accuracy.
- Should multi-class recognition be performed by detection or by classification?, i.e., speed up and accuracy.
- How to evaluate the performance for an undefined class distribution?, i.e., performance evaluation.
- How can different views of an object be identified as representing a single object?, i.e., accuracy.
- How to handle the occluded objects from detection point of view?
III. FUTURE SCOPES
Herewith are some of the main useful applications of object detection: Vehicle’s Plates recognition, self-driving cars, Tracking objects, face recognition, medical imaging, object counting, object extraction from an image or video, person detection. The future of object detection technology is in the process of proving itself, and much like the original Industrial Revolution, it has the potential to free people from menial jobs that can be done more efficiently and effectively by machines. It will also open up new avenues of research and operations that will reap additional benefits in the future.
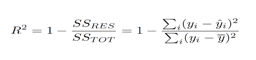
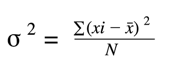
Conclusion
This paper presents the review of the various methods for detecting objects in images as well as in videos. The process of OD is classified into five major categories namely Sliding window-based, contour-based, graph based, fuzzy-based and context-based. Apart from this, other approaches that are used for detecting objects like the shape-based detection and Steiner tree-based are also summarised. A review on the topic of OD has been carried out by Prasad (2012), Madaan and Sharma (2012) and Karasulu (2010). Prasad (2012) has discussed the problem of OD in real images and addressed the various aspects like the feature types, learning model, object templates, matching schemes and boosting methods. A. Performance Matrices In machine learning, a performance evaluation metric plays a very important role in determining the performance of our machine learning model on a dataset that it has never seen before. Chances are, the model you have trained will always perform better on the dataset you have trained it. But we train machine learning models to perform well while solving real-world problems where data flows continuously. If we are using a model that is not capable enough to perform well, there is no point in using machine learning to solve your problems. This is where performance evaluation metrics come in. A performance evaluation metric calculates whether your trained approaches that are used for detecting objects like the shape-based detection and Steiner tree-based are also summarised. B. R2 Score The R2 score is a very important metric that is used to evaluate the performance of a regression based machine learning model. It is pronounced as R squared and is also known as the coefficient of determination. It works by measuring the amount of variance in the predictions explained by thedataset. Simply put, it is the difference between the samples in the dataset and the predictions made by the model. C. Explained Variance The explained variance is used to measure the proportion of the variability of the predictions of a machine learning model. Simply put, it is the difference between the expected value and the predicted value. The concept of explained variance is very important in understanding how much information we can lose by reconciling the dataset. D. Confusion Matrix The confusion matrix is a method of evaluating the performance of a classification model. The idea behind this is to count the number of times instances of class 1 are classified as class For example, to find out how many times the classification model has confused the images of Dog with Cat, you use the confusion matrix. E. Classification Report A classification report is one of the performance evaluation metrics of a classification-based machine learning model. It displays your model’s precision, recall, F1 score and support. It provides a better understanding of the overall performance of our trained model. To understand the classification report of a machine learning model, you need to know all of the metrics displayed in the report. So we For a clear understanding, I have explained all of the metrics below so that you can easily understand the classification report of your machine learning model: 1) Precision: Precision is defined as the ratio of true positives to the sum of true and false positives. We have tried several models with both balanced and imbalanced data. We have noticed most of the models have performed more or less well in terms of ROC score, Precision and Recall. But while picking the best model we should consider few things such as whether we have required infrastructure, resources or computational power to run the model or not. For the models such as Random Forest, SVM, XGBoost we require heavy computational resources and eventually to build that infrastructure the cost of deploying the model increases. On the other hand, the simpler model such as Logistic regression requires less computational resources, so the cost of building the model is less. We also have to consider that for little change of the ROC score how much monetary loss of gain the bank incur. If the amount is huge then we have to consider building the complex model even though the cost of building the model is high. The code returns the quantity of false positives it identified after comparing the real numbers with that number. This is used to assess the algorithms\' accuracy and precision. The subset of data we used for speedier testing made up 20% of the entire dataset. At the conclusion, which also takes use of the whole dataset, both results are presented. The result is as follows, with class 0 designating a real transaction and class 1 indicating a transaction that was determined to be fraudulent. Along with the classification report for each method, these outcomes are also given. This result was compared to the class values in order to rule out any potential false positives. 2) Train set • Accuracy = 0.95 • Sensitivity = 0.92 • Specificity = 0.98 • ROC = 0.99 • 3) Test set • Accuracy = 0.97 • Sensitivity = 0.90 • Specificity = 0.99 • ROC = 0.97
References
[1] Amine, K. and Farida, M.H. (2012) ‘An active contour for range image segmentation’, Signal &Image Processing: An International Journal (SIPIJ), Vol. 3, No. 3, pp.17–29, doi: 10.5121/sipij.2012.3302. [2] Arbeláez, P. (2006) ‘Boundary extraction in natural images using ultra metric contour maps’, Proceedings of the Conference on Computer Vision and Pattern Recognition Workshop, p.182. [3] Bar, M. (2004) ‘Visual objects in contexts’, Nature Reviews Neuroscience, Vol. 5, No. 8, pp.617– 629,doi: 10.1038/nrn1476. [4] Belongie, S., Malik, J. and Puzicha, J. (2002) ‘Shape context: a new descriptor for shape matching and object recognition’, IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol.24, No. 4, pp.509–522. Bergboer, N., Postma, E. and Herik, J. (2007) ‘Accuracy versus speed in context based object detection’, Pattern Recognition Letters Vol. 28, No. 6, pp.686–694, doi: 10.1016/j.patrec.2006.08.004. [5] Bhanu, B. and Lin, Y. (2004) ‘Object detection in multi-modal images using genetic programming’, Journal of Applied Soft Computing, Vol. 4, No. 2, pp.175–201. [6] Camp, K. and Stiefelhagen, R. (2007) ‘Automatic person detection and tracking using fuzzy controlled active cameras’, IEEE Conference on Computer Vision and Pattern Recognition. [7] Chen, C. and Tian, Y. (2010) ‘Door detection via signage context-based hierarchical compositional model’, Computer Vision and Pattern Recognition Workshop, pp.1–6
Copyright
Copyright © 2023 Rahul ., Deepika Bansal. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET48958
Publish Date : 2023-02-01
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online