

Ijraset Journal For Research in Applied Science and Engineering Technology
Object Tracking in Crowd Environment Using Deep Learning
Authors: Lingala Hrithika Goud, Ramidi Pooja Reddy, Sai Surya Teja Gedam, Dr. K. Sateesh Kumar
DOI Link: https://doi.org/10.22214/ijraset.2022.44530
Certificate: View Certificate
Abstract
Object tracking is fetching a primary set of object identification, allocating a unique ID to each one of them, and then ensuing each of the objects as they move around frames in a movie while safe keeping the ID assignment. Person tracking is a difficult task in video surveillance. In recent years, many computer vision, deep and machine learning have been developed. Convolutional Neural Networks (CNN) are transforming target tracking. The project\'s purpose is to recognize and track images utilizing object identification techniques such as Region based Convolutional Neural Networks (RCNN), Faster RCNN, Single Shot Detector (SSD), and You Only Look Once (YOLO). Faster-RCNN and SSD have superior accuracy among them, whereas YOLO performs better when speed is prioritized above accuracy. Deep learning combines SSD and Mobile Nets for efficient identification and tracking implementation. This technique detects objects quickly and efficiently without sacrificing performance. Convolutionally default boxex are passed over several feature maps. If a detected object matches one of the object classifiers during prediction, a score is produced..
Introduction
I. INTRODUCTION
Real-time object recognition and tracking for Object Detection has been the focus of much investigation in current years due to its close alliance with video analysis and image elucidation [1]. Fabricated characteristic and superficial formable construction are the foundation of conventional object detection systems [2]. Combining a variety of low-level visual features with high-level context provided by object detectors and location categorization, they can be effortlessly put out of action. With swift advancements in deep learning, more influential tools capable of semantic learning, higher level and in depth features are being advance to solve problems that infestation current systems [3]. As far as of network architecture, training techniques, and enhancement functions, these models act in a unexpected way. In this review, we study deep learning-based object identification architectures. Our investigation begins with a short history of deep learning and its most delegate instrument, the Convolutional Neural Network (CNN).
II. LITERATURE SURVEY
- A deep neural community is used to comprehend things in photographs. SSD discretizes the result area of bounding box containers into a hard and fast of default packing containers in keeping with characteristic map role during numerous thing ratios and scales. The community generates ratings for the presence of every object kind in every default field at prediction time, after which adjusts the field to higher fit the item shape.
- Introducing a class of proficient models called MobileNets for mobile and inserted image handling applications. MobileNets is in light on a simplified design that builds a lightweight deep neural network with depth-separable convolutions. We present two simple global hyperparameters to optimize the balance between latency and accuracy. Based on the limitations of the problem, these hyperparameters help the modeler choose the right model size for the application.
- The YOLO object sensor isolates the input image into SxS grids, and each grid cell predicts only one object. If a cell contains multiple small objects, YOLO will not be able to detect them and will miss the object detection.
- In this project objects are followed in view of variety, development of single and different items (vehicles) are perceived and included in various edges. Further single calculation might be intended for object distinguishing proof by considering shape, variety, surface, object of interest, development of article in multi heading.
- Discovers objects in a video sequence using object detection algorithms such as Gaussian mixed models, Haar algorithms, directed gradient histograms, and local binary patterns.
III. EXISTING METHODOLOGY
A. ResNet (Residual Neural Network)
We utilize a similar strategy concerning DSSD to train the organization model all the more really in this paper (the exhibition of the remainder of the organization is superior to that the presentation of the VGG organization). The aim is to increase precision.
B. RCNN (Region based Convolutional Neural Network)
To get around the difficulty of selecting so many places, Ross Girshick et al. intended a strategy where we can use indiscriminate chase to get only 2000 regions from an image, which is called region suggestion. Consequently, rather than attempting to rank countless positions, you can focus in just on 2,000.
C. Faster R-CNN
To find regional recommendations, the two algorithms above (RCNN and Fast RCNN) use selective search. Selective search is a sluggish and tedious activity that corrupts network execution.
D. MANet
Target detection has been a hotbed in computer vision for many years because it is a fundamentally difficult problem. The motive and goal of target identification is to see if an image contains examples of a particular type of object. Target detection returns the spatial coordinates and spatial degree of component cases on the off chance that there is an item to be recognized in a given picture (for example in view of jumping box utilization).
IV. PROPOSED METHODOLOGY
A. YOLO
"You See Only Once" is referred to as YOLO. It’s an algorithm to distinguish and recognize various components of an image. The object recognition in this algorithm is performed as a reverting issue and the class chances of the identified pictures are provided. Convolutional Neural Networks are used in the YOLO technique to detect objects in instantaneous time. For object detection, this method only performs one onward go through the neural network, as the name recommend. Yolo architecture is like FCNN (full accumulation neural network), passing the image (nxn) once over FCNN and generating a prediction (mxm), in contrast to other region recommender classifier networks (Fast) RCNN), do the detection on different suggested regions and thus end up doing the predictions multiple times for different regions of the image. This architecture splits the input image into mxm grids, with two bounding boxes and a class probability generated for each grid generation. It should be noted that the bounding box is more likely to be larger than the grid. This shows that a single run of the algorithm is utilized to foresee the whole image. CNN is utilized to foresee numerous bounding boxes and class probabilities simultaneously. There are few other forms of the YOLO algorithm. Tiny-YOLO and YOLO-v3 are two famous instances.
B. How The Yolo Algorithm Works
YOLO algorithm works of the succeeding 3 ways:
- Residual blocks.
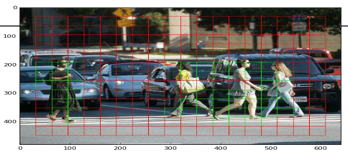
In the image is grilled up into different grids. The dimension of each raster is SxS. The picture shows how the feed in image is split into raster.
There are many grid cells of the same size. The objects displayed in each grid cell are recognized. For example, if the centre of an object appears in a particular grid cell, that cell is accountable for discovering it.
2. Bounding box Regression
A bounding box is a border that emphasizes objects in an picture. Each bounding box in the image includes the succeeding attributes:
Width (bw)
Height (bh)
Class (for example, person, car, traffic light, etc.)- This is represented by the letter c.
Centre of bounding box (bx,by)
The picture shows an instance of bounding box. The bounding box is signified by a yellow colour outline.
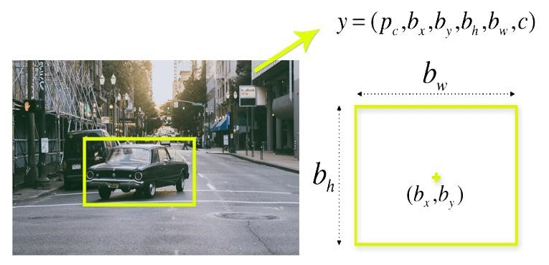
To predict the height, width, centre and class of objects, YOLO uses a single bounding box regression. The probability that an object appears in the bounding box is shown in the graph above.
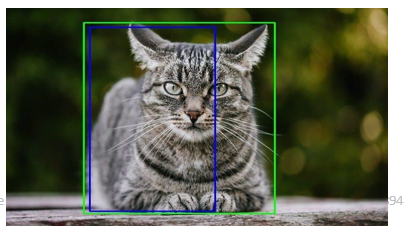
3. Intersection Over Union (IOU)
The proposal of Intersection Over Union(IOU) represents how boxes cross-over in object detection. IOU is used by YOLO algorithm to make a outcome field that pleasantly surrounds the items.
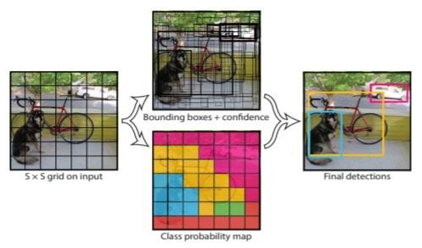
The Bounding boxes and it’s self-assurance rankings are anticipated through every grid cell.
Initially, the image is distributed into matrix cells. Every framework cell predicts a B jumping box and gives their confidence opinion. The cell predicts the class likelihood and decides the class for each object.
For example, you can perceive objects of not less than three categories: Car, Canine, and Bicycle. All expectations are made at the same time utilizing a solitary convolutional brain organization.
Intersections on the merger ensure that the forecasted bounding box is even to the actual box of the object. This action eliminates extraneous bounding boxes that don't correspond to the object's attributes (like level and width). The last recognition consists of a unique bounding box that exactly matches the object.
For instance, a pink bouncing box encompasses a vehicle and a yellow jumping box encompasses a bike. The blue bouncing box was utilized to underline the canine.
V. RESULTS
In this chapter we will discuss about the results
- Commands to Execute
In the Fig 6.1, these are the commands which are being executed. Python YOLO.py script is being run .
After executing this command, —image Specifying the path of an input image is sent into the script
Coco data is being passed following – yolo

In the Fig 6.2, that the model successfully identified the objects in a video displaying news, thereby it is evident that this model can be integrated with CCTV software and can be used in complex applications to improve the security of people's lives. Irrespective of the video quality available, the model is able to identify the objects and returns the list at the top left corner and also highlights the objects with a rectangular box with the confidence intervals being displayed


In the Fig 6.4, the objects are clumsy, moreover the suitcases were kept together indistinguishably. yet, the model was able to identify each suitcase separately and also the trucks at the corner of the image
The end detection consists of distinctive set of bounding boxes which are displayed around the detected objects with confidence value for the given inputs.
Conclusion
In this project, we suggested about YOLO algorithm for the motive of objects identification using a single neural network. This algorithm is stereotype, it exceeds different strategies once stereotype from natural pictures to different domains. The algorithm is simple to construct and can be instructed directly on a complete image. Region proposal strategies limit the classifier to a particular region. YOLO accesses to the entire image in forecasting boundaries. And it forecasts fewer false positives in background areas. Comparing to other classifier algorithms this algorithm is much more well organized and fastest algorithm to use in real time. In the proposed system, we have identified several objects in a frame of a video with some accuracy. This work can be extended in a possible way to get the description of objects along with the caption. For example, car number plate detection, model description, owner name, model name for a detected car. Similarly, Bio-graphic details about a person. Example: Height, Skin tone, Texture details (Colours of outfit, age, gender)
References
[1] J. Kang, S. Tariq, H. Oh and S. S. Woo, \"A Survey of Deep Learning-Based Object Detection Methods and Datasets for Overhead Imagery,\" in IEEE Access, vol. 10, pp. 20118-20134, 2022, doi: 10.1109/ACCESS.2022.3149052. [2] Asra Aslam, Edward Curry,A Survey on Object Detection for the Internet of Multimedia Things (IoMT) using Deep Learning and Event-based Middleware: Approaches, Challenges, and Future Directions,Image and Vision Computing, Volume 106, 2021, 104095, ISSN 0262-8856, https://doi.org/10.1016/j.imavis.2020.104095 [3] N. Kumaran and U. S. Reddy, \"Object detection and tracking in crowd environment — A review,\" 2017 International Conference on Inventive Computing and Informatics (ICICI), 2017, pp. 777-782, doi: 10.1109/ICICI.2017.8365242. [4] C. P. Papageorgiou, M. Oren and T. Poggio, \"A general framework for object detection,\" Sixth International Conference on Computer Vision (IEEE Cat. No.98CH36271), 1998, pp. 555-562, doi 10.1109/ICCV.1998.710772. [5] C. Tang, Y. Feng, X. Yang, C. Zheng and Y. Zhou, \"The Object Detection Based on Deep Learning,\" 2017 4th International Conference on Information Science and Control Engineering (ICISCE), 2017, pp. 723-728, doi: 10.1109/ICISCE.2017.156. [6] X. Zhou, W. Gong, W. Fu and F. Du, \"Application of deep learning in object detection,\" 2017 IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS), 2017, pp. 631-634, doi: 10.1109/ICIS.2017.7960069.
Copyright
Copyright © 2022 Lingala Hrithika Goud, Ramidi Pooja Reddy, Sai Surya Teja Gedam, Dr. K. Sateesh Kumar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET44530
Publish Date : 2022-06-19
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online