

Ijraset Journal For Research in Applied Science and Engineering Technology
Optimization of Deep Neural Networks Using DAPP (DNN Acceleration Using Ping-Pong) Approach
Authors: Mashkoor Ahmad Naik, Er. Jasdeep Singh
DOI Link: https://doi.org/10.22214/ijraset.2023.48771
Certificate: View Certificate
Abstract
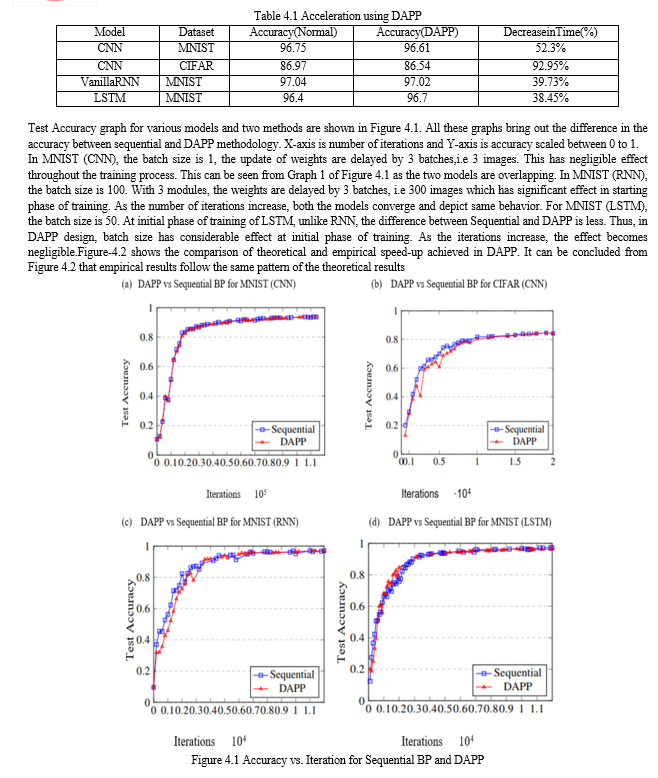
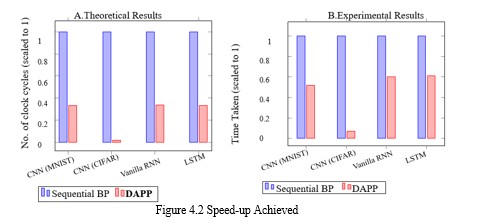
Deep Neural Networks (DNNs) are one of the leading classification algorithms. Deep Learning has achieved remarkable milestones such as Google-Net and Alpha-Go. They have shown promising results in pattern recognition for images and text, language translation, sound recognition, and many more. DNN has been widely accepted and also employed for pattern matching and image recognition. All these applications are possible as these networks emulate functioning of human brain and hence name “Neural” Network.However, to provide competent results, these millions of neurons in neural networks needs to be trained. For which billions of operations are to be carried out. Training of these many neurons and with these many operations is a time-consuming affair. Hence choice of network and its parameter play an important role both in providing accurate trained network and time taken for training. If the network is deep and has plethora of neurons, the time taken is considerably high as training works sequentially on batches of dataset using Sequential Back-propagation Algorithm.To accelerate the training there are many hardware solutions like use of GPU, FPGA and ASICs. However because of popularity of DNN there is increase in demand in mobile and IoT platform devices. These are resource constrained devices, where power and size of these device, restricts usage and implementation of deep NN (Neural Network).Simulation of DAPP is done on MNIST and CIFAR-10 datasets using System-C. Additionally, this technique has been adapted for multi-core architectures. The design shows a reduction in time by 38% for 3 layers of CNN and 92% for 10 layers of CNN, while maintaining the accuracy of networks. This generic methodology has been implemented for Vanilla RNN and LSTM networks. An improvement of 38% for Vanilla RNN and 40% for LSTM has been demonstrated by this methodology.
Introduction
I. INTRODUCTION
Deep neural networks are state-of-the-art pattern recognition algorithms. The deep layer architecture of neural network allows it to extract and to learn complex and high-dimensional data features creating a discriminative classifier. Like genetic algorithms and simulated annealing, DNNs are based on an analogy with real-world biological/physical processes. They mimic the behavior of human brain neurons. The degree of influence a neuron has on another neuron is reflected by a numerical weight. In simple terms, training a DNN is the process of selecting values for the weights so that the overall neural network produces the desired output for a given input.NNs are used in analyzing huge volume of data to extract patterns and bring new discoveries. In recent past, neural network has successfully taken a giant leap in many problems related to image recognition, speech recognition, automatic machine translation, natural language processing, automatic music composition and self-driving cars. They have outperformed human beings in games such as Alpha-Go. They are used in many applications such as video surveillance, mobile robot vision, and pedestrian detection. [3][4][5].Along with this, huge amount of data are generated from various other domains, like Internet-of-Things and today’s tremendous amount of devices able to capture pictures and videos, the potential for DNNs have vastly increased. By making our devices able to recognize its surroundings, there could be a huge amount of potential interesting applications. One other field is biology, here it may be a study of genome of any organism or it may to study of any chemical molecular structure. These have a complex and huge datasets, to learn such complex patterns, layers in DNNs are being increased manifold. This has led to a substantial increase in trainable parameters and computation.
To provide more accurate results, the state-of-the-art DNN requires millions of parameters and billions of operations to process a single image, which represents a computational challenge for general purpose processors. As a result, hardware accelerators such as Graphic Processing Units (GPU) [6] [7], Field Programmable Gate Arrays (FPGA)[8][9], and Application Specific Integrated Circuits (ASIC) [10][11] , have been utilized to improve the throughput of the DNN.
Among these accelerators, GPUs are the most widely used to improve both training and classification process of ConvNet, because of their high throughput and memory bandwidth. However, GPUs consume a considerable amount of power which is another important evaluation metric in the modern digital systems. ASIC design, on the other hand, has achieved high throughput with low power consumption by assigning dedicated resources and customizing memory hierarchy. But the development time and cost is significantly high compared to other solutions. As an alternative, FPGA-based accelerators provide high throughput, low power consumption and reconfigurability at a reasonable price.
A Neural Network is a collection of layers which are densely connected to each other. Each connection has some weights. NN is fed with the dataset. It is fed with one or more inputs along with corresponding weights. It takes the weighted summation of inputs and applies a non-linear function called activation function which are discussed as above. The layers perform operations on the output of previous layer. Thus, NN transforms the original input, layer by layer, to desired output and the category with maximum score is predicted. The error in prediction is propagated back in path to tune weights which results in a trained model. Fine-Tuning is done with respect to training algorithms. Some examples of training algorithm are Gradient Descent, Adam and Momentum Optimizer.
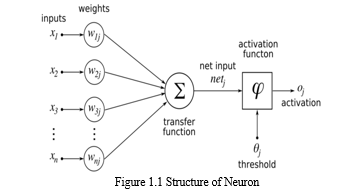
A. Activations
Whenever we see, hear, feel and think something, a synapse (electrical impulse) is fired from one neuron to another in the hierarchy which enables us to learn, remember and memorize things in our daily life. For a particular activity, a specific set of neurons are fired in human brain.
Likewise, Activation functions are important for a Neural Network. They have the role of firing a neuron in neural network. They introduce non-linear properties to the Network. In a neuron, the sum of products of inputs and their corresponding Weights is taken and Activation function f(x) is applied to it to get the output of that layer and feed it as an input to the next layer. A Neural Network without Activation function would simply be a Linear Regression Model, which has limited power and does not performs good most of the times. Also without activation function our Neural network would not be able to learn and model other complicated kinds of data such as images, videos, audio, speech etc.Most popular types of Activation functions are described as follows:
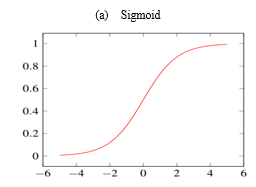
1) Sigmoid: It is a activation function of form f (x) = 1/1 + exp(−x) Its Range is between 0 and 1, which generally represents the probability of class as output. But it has major reasons which have made it fall out of popularity - Vanishing gradient problem. Secondly, its output isn’t zero centered. It makes the gradient updates go too far in different directions. 0 < output < 1, and it makes optimization harder.
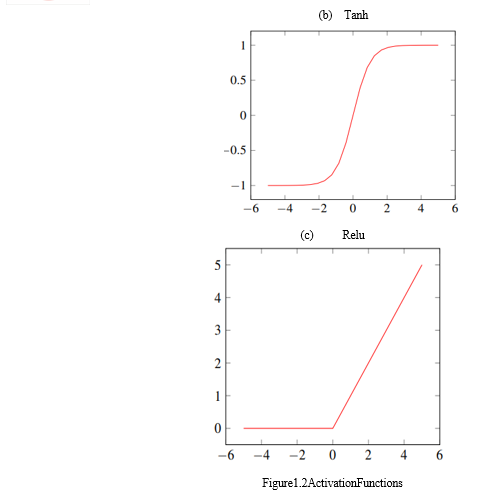

II. RESEARCH OBJECTIVES
The goal of the research is to design, develop, analyze and evaluate software implementation technique of deep neural networks, with the aim of achieving considerably better speed and energy efficiency than those can be realized with standard implementation technique. Thescopeofthisresearchworkisasfollows:
- Proposing a novel design to implement a generic algorithm which can be applied todifferent types of neural network like CNN, Vanilla RNN and LSTM.
- Emulate the implementation both in software and hardware so that fare comparison can be made to observe improvement if any. Validating the concept by using different datasets and standard neural network model
III. RESEARCH METHODOLOGY
This provides a discussion of the methodology used in this work. It begins with explaining the functioning of traditional Sequential Back propagation Algorithm. Here we will see the bottleneck in this approach and how to overcome this bottle neck. We then bring the concept of module through which we can exploit efficient parallelism.
Next we cover the algorithm which implements proposed techniques in SystemC and multi processor platform before we show why this technique works and can be used in a generic way. It elaborates the experimental setup used to implement naive and DAPP architecture. It also covers various model, its structure and parametric configuration considered. It covers details of dataset and libraries used in this work and provide mathematical analysis of expected results.
A. Unrolling of Backward Path
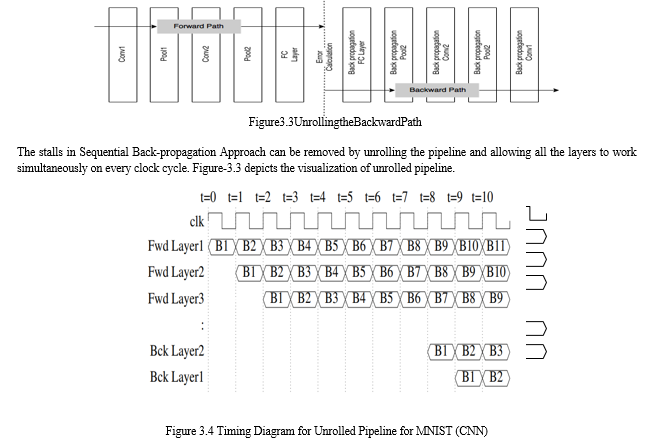
Here by unrolling of pipeline we mean connectcorrect sequence of backward path at end of forward path as depicted in Figure-3.4. Now the length of the pipeline is doubled then what it was earlier. At beginning, the pipeline is empty and random weights are initialized in global memory. These weights are fetched by layers of forward path for processing. Every clock cycle, the batches move forward in pipeline and new batch is fed to pipeline at layer 1. These batches use initialized weights till the pipeline is filled. Once the pipeline is filled, all the gradients corresponding to first batch are computed. The gradients corresponding to batch B1 are used to update the global weights. Updated global weights are used by batch entering the pipeline in the next clock cycle. Post this, global weights are updates on every clock cycle.
Unlike sequential back-propagation, this technique does not use updated weights of immediate previous batch but delayed by few cycles which is proportional to the length of pipeline. Thus, introducing delay in update of weights, allows the layers to work in parallel on consecutive set of batches.
The timing diagram for unrolled architecture is shown in Figure-3.4. From clock cycles 0 to 9, the layers work with initialized weights. After 9th clock cycle, the weights are updated and the next batch enters the pipeline, i.e Batch 11 (B11) is processed using the updated weights of B1. In next clock cycle, B12 works using weights updated till B2.
This can begeneralized as ithbatch works with weights updated till (i − 10)th batch. If each worker, thread or computational unit, works on independent layer, then the whole process will become in-efficient. This is because, layers like pooling and dense have much less number of computations to perform as compared to Convolutional Layer. Acc to Alex[24]Convolutions take 80% of computations in ConvNets.


V. FUTURE WORK
- DAPP can further be inspected closely to improvise its implementation so as to patch its outcome of experimental performance with theoretical expectation.
- Currently, DAPP has been implemented on Multi-core Xeon Processor and simulated using System-C. Implementation of DAPP on FPGA to make it energy and power efficiency can be exploited.
- The multi- core implementation of DAPP can be incorporated with Tensorflow library.
- To further accelerate the training process, the proposed approach can be incorporated with techniques like approximate computing, and quantization.
Conclusion
1) To conclude, we introduce a practical design flow for deep learning where have proposed a synchronous technique called DAPP, which accelerate the learning of Neural Network. When introducing the design flow we show how this speed up DNN training limitations of parallel Synchronous SGD has been removed by eliminating the need for global memory. 2) DAPP design can be implemented in for both BP and BPTT algorithm making this generic implementation. Although we have referred proof that this works for both, we demonstrate this, by implementing DAPP on different CNN model which has different depth along with Vanilla RNN and LSTM networks. 3) This approach carries the data in such a way that parallel workers keep gradients in local memory which requires less bandwidth and minimizes the delay caused by contention and communication. To address a few pitfalls of using synchronous technique some optimization steps are suggested along with algorithm which needs to be followed for a better result. 4) When evaluating the performance of DAPP technique, it is compared with the naive implementation of respective algorithms. Experimental results show a reduction in time by 40% for LeNet which is smaller network and 92% on Network-in-Network architecture of CNNs wherein it has 10 layers. For vanilla RNN, and LSTM class of algorithm on multi-core platform. 38% decrease in time for training basic one layer of Vanilla RNN and 40% for one layer of LSTM. Although we have not implemented this for a more deeper network like GooleNet [35], ResNet [36] we believe that this can further work on a more deeper network. In closing, we believe that we have answered our objective question by showing that DAPP can be used as practical acceleration platform for deep learning. We believe that this work is valuable in acting as a guide to future researchers who wish to continue efforts in this field and encourage the future development.
References
[1] Yann LeCun and Corinna Cortes. MNIST handwritten digit database. 2010. [2] Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. Cifar-10 (canadian institute for advanced research) [3] SamanBashbaghi, Eric Granger, Robert Sabourin, and Mostafa Parchami.Deeplearning architectures for face recognition in video surveillance. CoRR, abs/1802.09990,2018. [4] JahanzaibShabbir and TariqueAnwer. A survey of deep learning techniques for mobile robot applications. CoRR,abs/1803.07608,2018. [5] Denis Tomè, Federico Monti, Luca Baroffio, Luca Bondi, Marco Tagliasacchi, andStefano Tubaro. Deep convolutional neural networks for pedestrian detection. CoRR,abs/1510.03608,2015. [6] Thomas Paine, HaiinJin, Jianchao Yang, Zhe Lin, and Thomas S. Huang.GPUasynchronous stochastic gradient descent to speed up neural network training. CoRR,abs/1312.6186,2013. [7] Alexander Guzhva, Sergey Dolenko, and Igor Persiantsev. Multifold acceleration ofneural network computations using GPU. In Artificial Neural Networks – ICANN 2009,pages373–380.SpringerBerlinHeidelberg,2009. [8] KaiyuanGuo, Shulin Zeng, Jincheng Yu, Yu Wang, and Huazhong Yang.A survey off pga based neural network accelerator,2017. [9] JiantaoQiu, Jie Wang, Song Yao, KaiyuanGuo, Boxun Li, Erjin Zhou, Jincheng Yu,Tianqi Tang, Ningyi Xu, Sen Song, Yu Wang, and Huazhong Yang. Going deeper with embedded fpga platformfor convolutional neural network.InProceedingsofthe2016ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, FPGA’16,pages26–35,NewYork,NY,USA,2016.ACM. [10] Eriko Nurvitadhi, David Sheffield, Jaewoong Sim, Asit Mishra, Ganesh Venkatesh, andDebbie Marr.Accelerating binarized neural networks: Comparison of FPGA, CPU,GPU, and ASIC. In 2016 International Conference on Field-Programmable Technology(FPT).IEEE,dec2016. [11] Eriko Nurvitadhi, Jaewoong Sim, David Sheffield, Asit Mishra, Srivatsan Krishnan, and Debbie Marr. Accelerating recurrent neuralnetworksinanalyticsservers:Comparisonof FPGA, CPU, GPU, and ASIC.In 2016 26th International Conference on FieldProgrammableLogicandApplications(FPL).IEEE,aug2016. [12] Patryk Chrabaszcz, Ilya Loshchilov, and Frank Hutter.A downsampled variant of image netasanalternativet othecifar datasets,2017. [13] YoungwooYoo and Se-Young Oh.Fast training of convolutional neural networkclassifiers through extreme learning machines.In2016InternationalJointConferenceonNeuralNetworks(IJCNN).IEEE,jul2016. [14] Yijin Guan, Zhihang Yuan, Guangyu Sun, and Jason Cong. FPGA-based acceleratorfor long short-term memory recurrent neural networks. In 2017 22nd Asia and SouthPacificDesignAutomationConference(ASP-DAC).IEEE,jan2017. [15] SrimatChakradhar, MuruganSankaradas, VenkataJakkula, and Srihari Cadambi. Adynamically configurable coprocessor for convolutional neural networks. In Proceed-ings of the 37th Annual International Symposium on Computer Architecture, ISCA ’10,pages247–257,NewYork,NY,USA,2010.ACM. [16] OmryYadan, Keith Adams, YanivTaigman, and Marc’AurelioRanzato. Multi-gputrainingofconvnets,2013. [17] Wojciech Marian Czarnecki, GrzegorzS´wirszcz, Max Jaderberg, Simon Osindero,OriolVinyals, and Koray Kavuk cuoglu. Understanding synthetic gradients and decoupledneuralinterfaces,2017. [18] Lei Jimmy Ba and Rich Caurana.Do deep nets really need to be deep?CoRR,abs/1312.6184,2013. [19] A.Nøkland.DirectFeedbackAlignmentProvidesLearninginDeepNeuralNetworks.ArXive-prints,September2016. [20] Tim Salimans and Diederik P. Kingma.Weight normalization: A simple reparameteri-zationto accelerate training of deep neural networks. CoRR,abs/1602.07868.
Copyright
Copyright © 2023 Mashkoor Ahmad Naik, Er. Jasdeep Singh. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET48771
Publish Date : 2023-01-21
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online