

Ijraset Journal For Research in Applied Science and Engineering Technology
Brain Tumor Segmentation Using K-means Clustering Algorithm
Authors: Prof. Amit Thakur, Priya Pudke, Ruchika Das, Lawleen Suman, Priyesha Bansod
DOI Link: https://doi.org/10.22214/ijraset.2022.40112
Certificate: View Certificate
Abstract
With expanding technologies around the world, the medical field is also adapting new mechanization to perform treatment effectively. Identification of brain tumors with old technologies like MRI (magnetic resonance image), CT (Computer Tomography) scan takes time to confirm the possibility of the abnormal cell being cancerous or non-cancerous. Any abnormal cell or mass collection in the brain is a brain tumor. The possibility of a brain tumor depends on the abnormal cell\'s benign (non-cancerous) or malignant (cancerous) nature. In this paper to differentiate between the benign and malignant abnormal cells, one of the extensively used machine learning algorithm K-mean clustering is used for the implementation of the model. K-mean clustering is unsupervised learning, where centroids are defined to make data as clusters having relative relation between them. The agenda of this paper is to examine the abnormal cell whether it is benign (non-cancerous) or malignant (cancerous) using K-mean clustering effectively. In this paper, BRATS 2018 dataset is used for proposed methodology. After implementing proposed methodology, on basis of MR images it is differentiated between tumor being cancerous and non-cancerous.
Introduction
I. INTRODUCTION
Brain tumor is the most menacing disease that causes thousands of deaths every year all around the world. It is one of the most difficult disease to diagnose due to late recognition of abnormal cells being malignant. Earlier histopathology were used to detect the tissue that may have led to a brain tumor, but histopathology had several drawbacks. Histopathology used to take time, which used to slow down the diagnosis process [1]. Addressing drawbacks of histopathology, MRI (magnetic resonance imaging) was introduced which was helpful as it helped recognizing diverse tissue and enhanced the assessment of varied tissues [2]. A CAD system was also introduced that helps to classify brain tumors by visualization [3].The abnormal growth of cells around the brain part is brain tumor. It affects the functioning of the brain in case, if it enlarges with time. Enlargement of the abnormal cell creates pressure in near blood vessels and tissue, which may lead to trouble with memory. Similar to cancer, brain tumors can be benign (non-cancerous) and malignant (cancerous). Malignant tumor grows with time and causes brain tumors [4]. It has been found that most of the abnormal cells are benign and only a few cause brain tumors [5].
Brain tumor may be caused by a mutation in genes or exposure to tremendous radiation from X-rays from last cancer recovery or can be a hereditary condition passed from family members. A patient may have problems hearing, seeing, a headache that goes with vomiting, and may feel trouble concentrating [4]. The most common symptom that has been found is numbness on one side of the whole body or in the face. The beginning of brain tumors is called primary brain tumors that are a result of normal cell development in DNA being alive despite the end period [6]. Different types of primary brain tumors are as follows: Glioma, Meningioma, Pituitary adenoma, and Germ cell tumor. There are more but mostly diagnosis has been performed over mentioned. Gliomas tumors are most suspect to malignancy whereas Meningioma, Pituitary adenoma, and Germ cell tumors are benign [7].Cancer that starts in another part of the body and may spread to the brain part is called a secondary brain tumor. Secondary brain tumors are mostly found in patients with cancer history. Most adults have secondary brain tumors than primary brain tumors [6]. In this paper, the use of K-mean clustering is proposed to segment images of MRI to recognize the abnormal cell being benign or malignant. K-mean clustering is one of the widely used machine learning algorithms [8].
K-mean algorithm is an unsupervised learning technique where unlabeled datasets are grouped into different clusters. Clusters are formed based on features present in the dataset. K-mean clustering is an iterative algorithm as it partitions the dataset into clusters. A data point is assigned to a cluster where the sum of the squared distance between the data points is the cluster centroid being the minimum is the key point to differentiate [9]. Distance-based measurement is used to make the dataset into clusters. Therefore, the k-mean algorithm is followed for image segmentation of brain tumor images. Segmentation is the basic block of the proposed methodology as it is part of image processing [10].
As there are fewer experienced radiologists but more slices of MRI images to be examined, it was found that radiologists use to miss nearly 25% of tumors while in the screening process [10]. For medical image processing, the most important process is considered image segmentation as it helps to perform partition of the digital image which helps to focus only on an important part of the image. Image segmentation methods are done because it helps to analyze any image based on the edges, pixel form as well as in specific point-based. Segmentation is done focusing on image properties like similarity and discontinuity in the brain area. There are various segmentation methods but there is no specified way to use them, so it's also another challenge in the image processing process [11].
II. LITERATURE SURVEY
Accurate segmentation processing for brain tumor MRI is still a tedious task. Different researchers already performed various methodologies to achieve accuracy and those methodologies are discussed in this literature survey. It can be considered that may be 100% accuracy is not achieved but through different proposed methodologies, outcomes can be analyzed and with that different factors can be considered for the upcoming researches. Literature survey are as follows:
A. Segmentation using Concept of Deep Neural Network
A CNN architecture different from traditionally based computer vision was proposed which used a fully connected layer. A fully connected layer allowed a speed of 40 fold up. Dataset was trained twice to deal with misbalancing in tumour labels and the dataset used was BRATS 2013 [12]. For pre-processing the dataset, initially, the highest and lowest intensities were removed. And in post-processing flat blobs were removed. Researcher’s explored different two types of architecture were Two-pathway architecture and cascaded architecture. Two-pathway architecture had two streams named local pathway and global pathway, both were a result of consideration of visual details and large patch region on a pixel. They addressed the drawback of the CNN that it performs prediction over-segmentation layer individually. So, they proposed the model where the output probability of the first CNN was considered as additional input for the second layer of CNN. And this was the cascaded architecture that was proposed by them [13].
B. Detection using Statistical and Machine Leaning Method
Some researchers proposed the use of a Weiner filter for the noise reduction that was considered to help out enhance the region of interest. In Weiner filter different wavelet bands with the use of optimal grey-level thresholding. This helped researchers to obtain different texture features and for the separation of MR images, multiple classifiers were used. This methodology was also performed over the BRATS 2013 [12] and BRATS 2015 datasets [14]. Their work comprised of two experimentation, the first was evaluating the enhancement method and the second was the evaluation of the proposed segmentation technique [15].
C. Deep Learning with Transfer Learning
Some researchers used deep learning to detect the region of interest through classification. They restrained the classifier using the transfer learning technique. They discussed the fact that MRI is more preferred than CT scan, as MRI focuses more on soft tissues and CT scan focuses on hard tissues. So their research work focused on MR images only. Through their proposed architecture, they modified the deep learning network which was considered to be effective pre-processing and to classify the input data. Once the input data proceeds towards the input layer the network identifies the presence of a brain tumor. Feature extraction and classification are done through the present through the hidden layer. Transfer learning was used through the classification of input data into one with tumor and another without tumor. Using transfer learning they created another network that successfully classified the input data into two classes. Different DL networks that were used are Alex Net, VGG16, and VGG19, which gave 89.4%, 93.22%, and 95.78% accuracy. And dataset used for testing and training was OASIS and BRATS 2018, which had two classes of the tumor. The proposed network had an input size limitation as 227X227 or 224X224. As most of the data sizes are 512X512, so performing resize over an image causes data loss [16].
D. ANN for Object Detection and Identifying Abnormality of Brain Tumor
Another research work was done to detect and identify the abnormal behaviour of brain tumor, work presented the automated segmentation process and identification approach using ANN from MR images. Improved automated segmentation and identification process was considered to be helpful to catch the case of a brain tumor without human mediation. And it was achieved by following improvements that were done considering previous techniques: k-mean clustering helped by improving MR image region marking in light of greyscale, ANN was utilized in the training phase by opting correct object view and, texture features were used to analyse and differentiate among the benign and malignant case of brain tumor.
While in a training phase, the MR images are considered in terms of the pixels, and then colour is recognized which is then distinguished based on the texture feature. But this is complex since the volume of the MR images comes into consideration for this box method is utilized to get only the object from that. Whenever box size is decreased, the number of a pixel will get less and in case of an increase in box size, this process affected the feature extraction process. And the same will affect the testing phase as well. Researchers also addressed the manual selection of seed points which is nothing but a starting point of a particular sequence. They tried to improve the selection of seed points by uniting the spatial character of a brain tumor from MR images. As the focus of the study was o study abnormality in MR images, the proposed method focused on improving that particularly. The concentrated approach gave 94.07% accuracy over brain tumor classification with 90.09% sensitivity and 96.78% specificity [17].
E. Detection and Classification using 3D CNN and Feature Selection Architecture
3D Convolutional neural network takes a sequence of 2D images and turns out to be an efficient model by learning from volumetric data. Research work was presented in which 3D CNN was designed for extraction of brain tumor and then those extracted tumor were passed towards pre-trained CNN model for feature extraction process. And then features were sent to the correlation-based selection method as output, where the best feature was selected. For selected features validation is also done through the feed-forward neural network for final classification.
Compared with exiting techniques during their implementation period researchers accomplished accuracy of 98.32 over BRATS 2015, 96.97 over BRATS 2017, and 92.67% over BRATS 2018 dataset [18]. Also after a few more implementations of 3D CNN, high precision and less error rate were achieved, and with that the proposed model correctly segmented tumor from low contrast MRI image. Well, this research work can be appreciated as a part of high contrast MRI scans, they also focused on the low contrast images [19].
F. Image Classification using K-means Clustering, NSCT and SVM
Another automated classification of MR images was presented by using K-means clustering, NSCT, and SVM. For pre-processing of images, a median filter was used which removed all noise as well as enhanced resolution of images. As k-means clustering is considered for image segmentation the segmentation was done faster with it. As NSCT provides properties such as multi-scale, multidirectional as well as shift variance, it was applied over segmented images. After that nearly seven features were extracted and were used for classification using SVM. They evaluated model efficiency using sensitivity, specificity, and accuracy. From the families of SVM, the kernel was picked considering the advantages it provided, such as tunable parameters and Gaussian radial basis (GRB) function was used.
Evaluation of presented model was evaluated using 88 normal and abnormal images from the BRATS dataset, specifically, flair images were collected for the evaluation process. MATLAB was used for the evaluation process. For training purposes, features from 35 images that had 10 normal and 25 abnormal images were used. After that nearly 50 image was applied for testing purpose. After the experiment proposed technique showed 98.86% accuracy over the GRB kernel. But researchers found the need for validation of the presented hybrid scheme with more testing and training [20].
G. Unified patch Based Method using Features Fusion
Texture analysis is one of most important part to be considered while recognizing objects from computer systems. And there is method called as geometric feature learning which detects features from edges, ridges and blobs. Considering the discussed two concept researcher used that for tumor classification over MR images. Proposed techniques were evaluated over the MRI that included T2 and flair case, the most popular Otsu method was used for tumor segmentation. The region of interest was enhanced using FNLM (fast non-local mean) with a 4X4 patch size. Acquired features such as a histogram of oriented gradients, area, filled area, circularity were merged into a single-dimensional vector. This single-dimensional vector was used for predictions.
While pre-processing they found that after segmentation, the segmented image consisted of extra pixels which were successfully removed using morphological erosion. For experimentation BRATS 2013 and 2015 with Harvard datasets were used. For validation of the proposed method, two testing’s were done- pixel-based and feature-based. In pixel-based testing, the presented method showed results 94.1% for complete tumor, 94.0% for core tumor, and 95.2% for enhancing tumor. Whereas for second testing accuracy was 1.00 on GEO on LBP and 0.90 on HOG for BRATS 2015 dataset and 0.99 accuracies on GEO with 0.97 on LBP with SVM. For the Harvard dataset, the feature independently achieved 0.95 accuracies on GEO and LBP with SVM. More features were used that can be found on the paper. Researchers have shown interest in the enhancement of fusion of statistical and GEO features with deep learning features for classification [21].
After reviewing several research papers we came to know that k-means clustering is effective for segmentation but the methods used for feature extraction and feature selection make the difference in efficiency achieved. In this paper, we have proposed a unique methodology to achieve more efficiency than previously proposed methodologies. The dataset that is used to implement proposed methodology is BRATS 2018 [18].
III. PROPOSED METHODOLOGY
For identification of brain tumor using MR images, initially image acquisition is done. As we are using already available dataset so we are not having image acquisition image step in proposed methodology. Our methodology consist of data collection, image preprocessing, data augmentation, feature extraction, feature selection and class identification. The diagrammatic representation isshown in below fig 1.
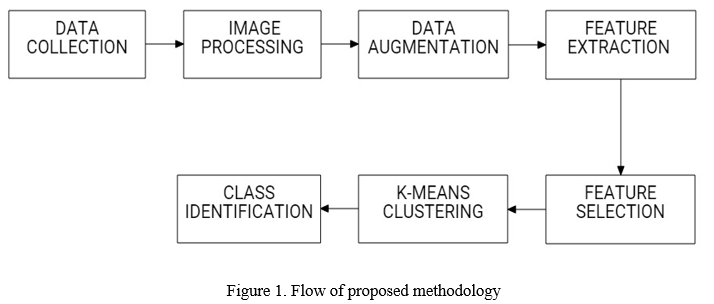
A. Data Collection
For the implemented methodology we have used BRATS 2018 dataset. BRATS 2018 dataset has a 3-dimensional magnetic resonance image of the brain where 4 different modalities are present for every T1, T1c, T2, and flair case. This dataset is prepared by physicians, they observed very carefully and it included three tumor sub-regions. The enhancing tumor, the peritumoral edema, and non-enhancing tumor, these observations were combined into three sub-regions enhancing tumor, whole tumor, and tumor core.
B. Image Preprocessing
Before any image is used for the classification the extra noise from the image is removed to make it effective for accurate result generation. And image pre-processing is achieved using pre-processing techniques which are - mean normalization, standardization, noise removal, resizing images, image filtering, and geometric transformations. Image processing is used for the advancement of the features present in particular images. Image processing is mostly used in computer vision as all the result is dependent on the features. There are some speculations that image pre-processing can affect the true features of images. Therefore a journal paper dedicated to the image pre-processing only which can be referred from here [22].
C. Data Augmentation
Data augmentation when analysing data is a technique used to increase the amount of data by adding slightly modified copies of existing data or new aggregated data created from existing data. This acts as a regularization and helps to reduce over fitting when training machine learning models. This is closely related to oversampling in data analysis. Data augmentation is a popular technique that improves the generality of deep neural networks and can be thought of as implicit regularization. It plays an important role in situations where reliable, high-quality data is limited and new examples are expensive and time-consuming. This is a very common problem in the analysis of medical images, especially when identifying representative tumours. This article reviews recent advances in data augmentation techniques applied to brain tumor magnetic resonance imaging. Oversampling and down sampling in data analysis are techniques used to adjust the distribution of classes in a data set (especially the ratio between different classes/categories represented by the data set area). The term is used both in statistical sampling and survey design methods, and in machine learning. Oversampling and down sampling are approximation and opposite techniques. There are also simpler oversampling techniques, which involve the creation of artificial data points using algorithms such as composite prime sampling.
D. Feature Extraction
The work of classifying a pattern is made easier by feature extraction, which extracts the key shape information inherent in the pattern. Feature extraction is a type of dimensionality reduction used in pattern recognition and image processing. The primary purpose of feature extraction is to extract the most important information from the original data and express it in a lower-dimensional space. When an algorithm's input data is too huge to analyze and is suspected of being redundant (i.e., there is a lot of data but not a lot of information), the data is transformed into a reduced representation set of features (also known as a features vector). Feature extraction is the process of transforming raw data into a set of features.
If the features extracted are carefully chosen, it is expected that the features set will extract the relevant information from the input data in order to perform the desired task using this reduced representation rather than the full-size input pattern recognition is a new field of image processing research. When we have a large data set and need to reduce the number of resources without losing any vital or relevant information, we can utilize the feature extraction technique. Feature extraction aids in the reduction of unnecessary data in a data set. Finally, reducing the data makes it easier for the machine to develop the model with less effort, as well as speeding up the learning and generalization processes in the machine learning process. Feature extraction is used in machine learning, pattern recognition, and image processing to create derived values (features) that are meant to be useful and non-redundant, easing future learning and generalization phases and, in certain situations, leading to improved human interpretations.
E. Feature Selection
Whenever features are extracted there may be an abundant number of features or maybe less, but we cannot use all those features to classify. Therefore some extremely important features are selected and on basis of that, the result is evaluated. Apart from this after reducing the number of features it also helps to reduce the computing cost to implemented model and directly it affects the performance of the model also. As our model is based upon K-means clustering which is unsupervised learning, then it's also helpful to have a few selected features. For supervised learning, there are different methods available for feature selection such as filter methods, wrapper methods, and embedded methods.
The filter method is considered faster and takes less computational cost by selecting intrinsic properties of features that are measured using univariate statistics. In the wrapper method, the selection process depends upon the specified machine learning algorithm that is meant for the dataset. Basically wrapper method follows the greedy approach by calculating all possible features combinations. An embedded method is iterative in nature as it takes iteration of the model training process each time and then sharply extracts the features. Another feature extraction method which is hybrid is used over a small sample taken out of the dataset. Therefore the filtering process is dependent on instance learning as the dataset is small for it.
F. K-means Clustering
K-means clustering is the most used algorithm for the unlabeled dataset. It is one of the unsupervised learning algorithms to solve clustering problems. K-means works by making different clusters on basis of certain features where no. of clusters (k) is pre-defined. It is also said as an iterative algorithm as it takes an iterative approach to make k different clusters on basis of similar properties. And with that kind of approach, every cluster is associated with a particular centroid so it is also considered as a centroid-based algorithm. This algorithm helps to minimize the sum of distances between each data point and cluster.
A simple example can be considered which is explained with the help of the diagram below. If there are different kinds of data points are present which can be seen in fig 2 but among it, a certain feature only belongs to that particular data type then it can be selected as its feature for collecting all similar types as in fig 3 the data points are differentiated on basis of their different color.
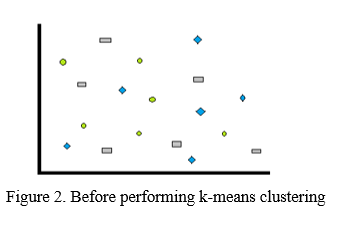
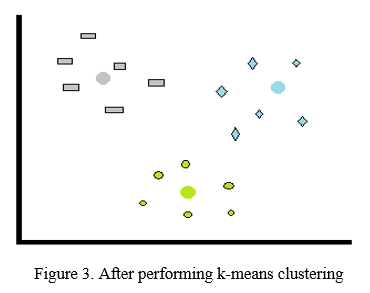
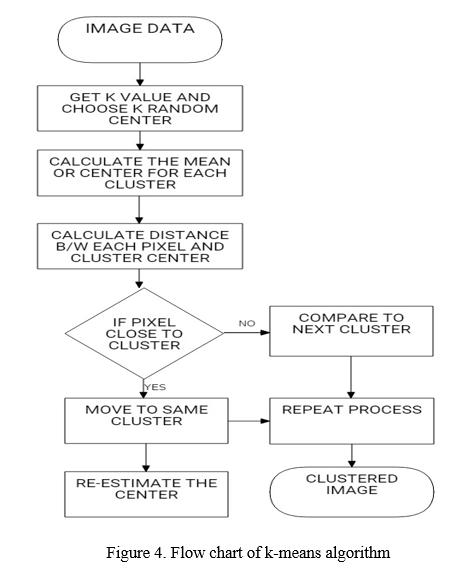
Clustering is one of the most extensively utilized data analysis methods in a variety of emerging-area applications. Clustering is the process of identifying groupings of things in which the objects in each group are similar to one another but distinct from those in other groups. The steps followed in K-means clustering can be seen in below fig 4. This is an excellent clustering approach because it produces high-quality clusters with high intra-cluster resemblance and low inter-cluster resemblance. We must first define the number of clusters k in the k-means algorithm. Then, at random, cluster centers are picked. Each pixel's distance from the cluster centers are determined. The distance might be calculated using a simple Euclidean function. The distance formula is used to compare a single pixel to all cluster centers.
Algorithm of implementing K-means clustering-
- Ask for the number of cluster values.
- Pick the k cluster center at random.
- Determine the cluster's mean or center.
- Find the distance between each pixel and each cluster center.
- If the distance is close to the center, go there cluster.
- If not then move on to the next cluster.
- Reassess the core.
- Continue until the center remains stationary.
Representation in mathematics-
Calculate the cluster means m for a given image.
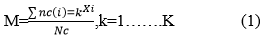

G. Class Identification
Primary and secondary brain tumours can be distinguished. Primary brain tumours start in the brain and grow from there. A large number of initial brain tumours are harmless. Secondary brain tumours, also known as metastatic brain tumours, occur when cancer cells in other organs, such as the lungs or chest, expand to the brain.
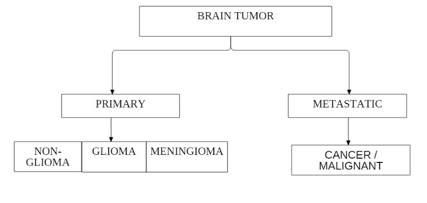
- Primary Brain Tumor: Primary brain tumor can affect both children and adults, although they are uncommon in both. Radiation exposure or genetic mutations may have a role in the formation of brain tumor in some circumstances, according to experts. It's critical to recognize that there are several forms of brain tumor and that symptoms vary based on the tumor location and size. Primary brain tumor can also be malignant, benign, or malignant-like (benign).
- Metastatic Brain Tumor: Metastatic brain cancers begin elsewhere in the body and spread to the brain, unlike primary brain tumor. Primary brain tumor are less prevalent than metastatic brain tumor. Through the circulation or lymphatic vessels, cancers from other regions of the body spread or metastasis to the brain.
In this paper we are classifying the MR images on basis of it being cancerous and non-cancerous only. If any abnormal spot in the MR images is detected then the model defines that as cancerous and if not then non-cancerous. The reason behind use of MR images over CT scan is that MRI focus on soft tissues whereas CT scan focuses mainly on structure.
IV. RESULT
After applying K-means clustering algorithm the proposed methodology is successfully identifying the region of interest. Once the segmentation process is completed the model can identify using MR image that it’s cancerous or non-cancerous. Number of clusters are important in K-means clustering as in case of taking less number of cluster the most frequently found feature is considered but in case of taking high number of cluster the features are selected by considering deep features from images.
Conclusion
After the implementation of k-means clustering, it can be concluded that the efficiency of the model is dependent on the number of clusters (k) taken. Cluster size depends upon the dataset being used and possibly different types. As the dataset we used had around 255 images we used clusters number as 6. The efficiency of a model can be increased more. In the proposed methodology we will be including more features in future research works using different feature extraction techniques like random forest and SVM.
References
[1] K. Lennert, N. Mohri, H. Stein, and E. Kaiserling, “The Histopathology of Malignant Lymphoma,” Br. J. Haematol., vol. 31, no. s1, pp. 193–203, 1975, doi: https://doi.org/10.1111/j.1365-2141.1975.tb00911.x. [2] N. Jeremy Hill et al., “Recording human electrocorticographic (ECoG) signals for neuroscientific research and real-time functional cortical mapping,” J. Vis. Exp., no. 64, Jun. 2012, doi: 10.3791/3993. [3] R. A. Castellino, “Computer aided detection (CAD): An overview,” Cancer Imaging, vol. 5, no. 1, pp. 17–19, 2005, doi: 10.1102/1470-7330.2005.0018. [4] S. Koriyama et al., “A surgical strategy for lower grade gliomas using intraoperative molecular diagnosis,” Brain Tumor Pathol., vol. 35, no. 3, pp. 159–167, 2018, doi: 10.1007/s10014-018-0324-1. [5] N. A. Charles, E. C. Holland, R. Gilbertson, R. Glass, and H. Kettenmann, “The brain tumor microenvironment,” Glia, vol. 59, no. 8, pp. 1169–1180, 2011, doi: https://doi.org/10.1002/glia.21136. [6] G. Perkins,A. Liu, “Primary Brain Tumors in Adults: Diagnosis and Treatment - American Family Physician,” Am. Fam. Physician, vol. 93, no. 3, pp. 211–218, 2016, [Online]. Available: www.aafp.org/afp. [7] M. Wrensch, Y. Minn, T. Chew, M. Bondy, and M. S. Berger, “Epidemiology of primary brain tumors: Current concepts and review of the literature,” Neuro. Oncol., vol. 4, no. 4, pp. 278–299, 2002, doi: 10.1093/neuonc/4.4.278. [8] A. Likas, N. Vlassis, and J. J. Verbeek, “The global k-means clustering algorithm,” Pattern Recognit., vol. 36, no. 2, pp. 451–461, 2003, doi: https://doi.org/10.1016/S0031-3203(02)00060-2. [9] S. S. Khan and A. Ahmad, “Cluster center initialization algorithm for K-means clustering,” Pattern Recognit. Lett., vol. 25, no. 11, pp. 1293–1302, 2004, doi: https://doi.org/10.1016/j.patrec.2004.04.007. [10] M. Ahmed and D. Mohamad, “Segmentation of Brain MR Images for Tumor Extraction by Combining Kmeans Clustering and Perona-Malik Anisotropic Diffusion Model,” Int. J. Image Process., vol. 2, 2008. [11] W. Khan, “Image Segmentation Techniques: A Survey,” J. Image Graph., vol. 1, no. 4, pp. 166–170, 2014, doi: 10.12720/joig.1.4.166-170. [12] “The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS),” doi: 10.1109/TMI.2014.2377694. [13] M. Havaei et al., “Brain tumor segmentation with Deep Neural Networks,” Med. Image Anal., vol. 35, pp. 18–31, 2017, doi: 10.1016/j.media.2016.05.004. [14] Y. Pan et al., “Brain tumor grading based on Neural Networks and Convolutional Neural Networks,” Proc. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. EMBS, vol. 2015-Novem, pp. 699–702, 2015, doi: 10.1109/EMBC.2015.7318458. [15] J. Amin, M. Sharif, M. Raza, T. Saba, and M. A. Anjum, “Brain tumor detection using statistical and machine learning method,” Comput. Methods Programs Biomed., vol. 177, pp. 69–79, 2019, doi: 10.1016/j.cmpb.2019.05.015. [16] A. Anil, A. Raj, H. Aravind Sarma, N. C. R, and D. P L, “Brain Tumor detection from brain MRI using Deep Learning,” Int. J. Innov. Res. Appl. Sci. Eng., vol. 3, no. 2, p. 458, 2019, doi: 10.29027/ijirase.v3.i2.2019.458-465 [17] N. Arunkumar et al., “K-Means clustering and neural network for object detecting and identifying abnormality of brain tumor,” Soft Comput., vol. 23, no. 19, pp. 9083–9096, 2019, doi: 10.1007/s00500-018-3618-7. [18] S. Bakas et al., “Identifying the Best Machine Learning Algorithms for Brain Tumor Segmentation, Progression Assessment, and Overall Survival Prediction in the BRATS Challenge,” 2018, [Online]. Available: http://arxiv.org/abs/1811.02629. [19] A. Rehman, M. A. Khan, T. Saba, Z. Mehmood, U. Tariq, and N. Ayesha, “Microscopic brain tumor detection and classification using 3D CNN and feature selection architecture,” Microsc. Res. Tech., vol. 84, no. 1, pp. 133–149, 2021, doi: 10.1002/jemt.23597. [20] C. Saha and M. F. Hossain, “MRI brain tumor images classification using K-means clustering, NSCT and SVM,” 2017 4th IEEE Uttar Pradesh Sect. Int. Conf. Electr. Comput. Electron. UPCON 2017, vol. 2018-Janua, pp. 329–333, 2017, doi: 10.1109/UPCON.2017.8251069. [21] M. Sharif, J. Amin, M. W. Nisar, M. A. Anjum, N. Muhammad, and S. Ali Shad, “A unified patch based method for brain tumor detection using features fusion,” Cogn. Syst. Res., vol. 59, pp. 273–286, 2020, doi: 10.1016/j.cogsys.2019.10.001. [22] I. Processing, “a71E05Cfc49Ab0777B82Ca94D181F779149F,” pp. 39–84.
Copyright
Copyright © 2022 Prof. Amit Thakur, Priya Pudke, Ruchika Das, Lawleen Suman, Priyesha Bansod. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET40112
Publish Date : 2022-01-28
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online