

Ijraset Journal For Research in Applied Science and Engineering Technology
Breast Cancer Detection Using Machine Learning
Authors: Devanshu Rathi, Chanchal Rathad, Avishkar Raskar, Om Randhave, Mukta Rasal
DOI Link: https://doi.org/10.22214/ijraset.2022.47875
Certificate: View Certificate
Abstract
One of the biggest issues facing humanity in the developing countries is cancer-related mortality. Some cancer kinds still lack a cure, despite the fact that there are many strategies to stop it from occurring in the first place. Breast cancer is one of the most prevalent cancer kinds, and early detection is the key to the most crucial aspect of treatment. One of the most crucial steps in the treatment of breast cancer is an accurate diagnosis. There is numerous research about predicting the type of breast cancers in the literature. In this study, predictions on the types of breast cancers were made using information on breast cancer tumors from Dr. William H. Walberg of the University of Wisconsin Hospital. Results obtained with the logistic regression model with all features included showed the highest classification accuracy (98.1%), and the proposed approach revealed the enhancement in accuracy performances. These results indicated the potential to open new opportunities in the detection of breast cancer.
Introduction
I. INTRODUCTION
Breast cancer (BC) is one of the most prominent types of cancer among women each around the world, according to exploration conducted by World Health Organization (WHO). BC is a leading cause of death among women each around the world. Breast cancer also has an exceedingly high rate of cancer losses in India which is around 14% and is the most common cancer among women. BC. affects about 5% of Indian women, but it affects about 12.5 per cent of women in Europe and the United States. It confirms that women in Malaysia who have breast cancer present at a after stage of the complaint than women in other countries. Breast cancer is in utmost cases easy to diagnose if any particular symptom appears. Some women with breast cancer, when considered, face no symptoms. Therefore, periodic breast cancer webbing is pivotal for early discovery.
As portent is so critical for long-term survival, early detection of breast cancer definitely benefits early treatment and diagnosis. Because cancer can be detected, diagnosed, and treated only if detected early, the chance of death is reduced by early detection and early diagnosis. It plays a vital role in a patient's survival. Delay in diagnosing/detecting cancer at a later stage may lead to the spreading of disease and various complications in treatment.
Cancer-related research done in the past on effects of a late cancer diagnosis has found that it is very closely linked to the disease also progressing to various advanced stages, which also lowers the likelihood of saving the patient's life.
An analysis of 92 researchers found that female breast cancer patients who begin treatment within 90 days after the onset of various symptoms had a considerably higher likelihood of surviving than those of them who also wait more than 90 days.
Many earlier studies have found that detecting/diagnosing breast cancer in its early stages and starting the treatment on time increases the chances of survival by preventing malignant (Cancerous) cells from spreading throughout the body. This paper's main contribution is an evaluation and study of the role of various machine learning approaches in breast cancer early detection. Artificial intelligence (AI) and Machine Learning (ML) together can be implemented to improve breast cancer detection/diagnosis, while also avoiding overtreatment. However, merging (AI) with (ML) also approaches helps achieve accurate prediction as well as decision-making. E.g., deciding whether or not the patient needs surgery based on the various biopsy/enucleation results for detecting breast cancer. When surgery is performed to remove malignant/(cancerous) cells, it is sometimes discovered that some of the cells are benign/(non-cancerous) cells. This also implies in a certain way that the patient will be subjected to unnecessary, unpleasant, and costly surgery. M.L. Algorithms have several benefits, including their ability to perform well on healthcare-related datasets such as pictures, x- rays, and blood samples. Some strategies are also suited to small datasets, while some of the others are also best suited to large datasets
II. LITERATURE REVIEW
According to the literature survey, finding the 68 landmarks on any face and one millisecond face alignment with an ensemble of algorithms were the subjects of research by Vahid Kazemi et al., [1] regression trees that might potentially locate the 68 landmarks in a matter of milliseconds. They chose landmarks using two baselines: correlation-based feature selection and random feature selection. The quantity of training photos utilized as input for this method directly affects how hard the training process is.
A strong Face Recognition system was created by Mohsen Ghorbani et al. [3] using HOG and LBP. The extraction of HOG descriptors from a regular grid is used in this study to correct errors in face feature detection caused by occlusions, pose changes, and lighting variations. Combining HOG descriptors at va
III. METHODOLOGY
A. Boosting
Boosting some of the strategies also has a tendency to work in a similar soul as stowing techniques: we can also assemble a group of various prototypes which are amassed towards in a way that acquires some of the solid students whose conduct is also superior. Despite, dissimilar to stowing that targets also reduces the differences, also supporting to a strategy that is used for linking together various weak learners in an exceptionally adaptative manner: such that each separate weak model in this some of these specific grouping is also fitted/shaped giving more reliability to the datasets which were also previously missing. Naturally, each latest prototype spotlights one's endeavors, especially for troublesome perceptions suitable till the current moment, therefore the user acquires, toward the finish of the interaction, a solid student with lower inclination (regardless of whether we are able to observe the supporting manner that can likewise diminish difference).
Also being primarily engaged at decreasing predisposition, some of the base models that are also frequently considered for supporting are models with low fluctuation but high inclination too. Versatile helping refreshes the loads appended to every one of the preparation dataset perceptions through slope-supporting updates on the worth of these perceptions. This principal contrast comes from the way which also describes the two techniques that also has a tendency to attempt to take care of the enhancement issue of surveying some of the models that can also be composed as a weighted number of powerless students.
B. Support Vector Machine
Support Vector Machine (SVM) is also a supervised machine learning algorithm that is also used for both classification as well as regression. Though we can observe and also say that some of the regression problems as well its best suited for classification. The objective of SVM algorithm is to find a hyperplane in an N-dimensional space that also distinctly classifies some of the data points. The various dimensions of the hyperplane depend upon the number of features. If the specific number of input features are two, then the hyperplane is just a specific line. If the number of input features are three, then the hyperplane also becomes a 2-D plane. It becomes difficult to imagine in a way where the number of features exceeds three and so. The last step is to search for the name in the database which has the closest measurements to our test image.
???????C. Random Forest Classifier
Random forest is an administered learning algorithm. It is an assortment of Decision Trees. A Decision Tree(DT) varies levelled in nature in which various nodes address specific circumstances on a specific arrangement of highlights, as well as the branches split the decision towards the leaf nodes. Leaf decides the class marks. Decision Tree can be developed either by utilizing Recursive Partitioning (RT) or by Conditional Inference Tree (CIT). Recursive Partitioning is the bit-by-bit process by which a Decision Tree (DT) is built by either parting or not parting every node. We can also observe and state that the tree is advanced by parting the source set into some of the subsets given a property estimation test. The recursion ends if the subset at a node has a gross similar value to the objective variable. A contingent Inference Tree is a factual-based approach that involves non-parametric tests as dividing models that are rectified for different testing to avoid overfitting. Random Forest is reasonable for high-layered information displaying as it can deal with missing qualities, and persistent, out and parallel information however for very informational indexes, the size of the trees can also take up to a ton of memory. It can also quite often over-fit, so there is also a need to tune the hyper-boundaries related to it.RF(Random forest) algorithm is utilized at some point of the highest quality in the RF models. RF also constructs multiple DTs which also utilizes random examples with substitutions to increase the efficiency of DTs. Every constructed tree groups their perceptions, and the greater part casts a ballot decision is picked. RF is utilized in some of the solo modes for surveying some of the vicinities among information focuses.
The random forest approach is also related to the bagging method where profound trees, fitted on some of the bootstrap tests, are combined to create a result computed with a lower difference. Be that as it may also, random forests additionally utilize one more stunt to make some of the various fitted trees a piece less related to every other one too: while developing/constructing each and every tree, rather than just inspecting/surveying the perceptions in the dataset to produce a bootstrap test, we likewise test over the highlights and keep just any type of random subset of them to assemble the tree.
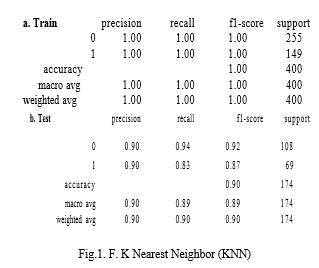
K-Nearest Neighbor is one of the easiest and most reliable Machine Learning Algorithms. It can also be used for various Classifications and Regressions, but it is specifically used for Classification only. KNN do addresses both characterization as well as relapse assignments. In the Classification technique, it arranges the articles considering the k closest, getting-ready models in the component space. The working mechanism behind KNN model is that it also accepts that the various considerable comparative data centers lie in the same environmental components. It gets the chance of proximity considering a mathematical condition which is also called Euclidean distance, the calculation of distance between two spots in a plane. If we consider two points in a plane which are A (x0, y0) and B (x1, y1) then, the Euclidean distance between them is determined as follows:
To figure out which of the K cases in the preparation dataset are like other information, a distance measure is utilized. For genuine esteemed input factors, the most well-known distance measure is the Euclidean distance.
The steps to be done during the K-NN calculation are as per the following:
- Divide the information into preparing and test information.
- Select a worth K.
- Also determine which distance work should be utilized.
- Choose a situation from the test information that should be specifically ordered and register the distance to its n preparing tests.
- Classify the distances got and take the k-closest information tests.
- Assign the test class to the class given the larger part vote of its k neighbors.
Important Tuning Parameters for KNN
• n_neighbours: The number of nearest neighbours K in the K-NN algorithm
• Weights: Weight function used in predictions.
IV. dicision tree
Decision Trees (DT’s) are Machine Learning (ML) calculations that are consistently partitioned into reliable informational collections into more modest information bunches considering an unmistakable element until they arrive at sets that are mostly sufficiently less to be portrayed by some mark. This is the sort of calculation that independent vehicles use to perceive walkers and items, or associations exploit to gauge clients’ lifetime esteem and their beat rates. They expect that you have information that is marked (labelled with at least one name, like the plant name in pictures of plants), so they attempt to name new information considering that information. Decision Trees calculations are amazing to tackle arrangement (where machines sort information into classes, regardless of whether an email is a spam) and relapse (where machines anticipate values, like a property cost) issues. The significance of DT’s depends on the way that they have various groups of utilizations. Being one of the most involved calculations in ML, they are also applied to various functionalities in a few enterprises.
 ???????
???????
Conclusion
Our work on Detecting breast cancer using ML is also principally centred around the various advancements of predictive models to accomplish great precision in foreseeing a number of legitimate diseases which results utilizing supervised machine learning (ML) techniques. Further research in this field ought to be done for the better execution of the grouping procedures so it can foresee a number of factors. . The dataset also contains 32 characteristic features that contribute to bringing down the multi-dimensional large dataset to only a few necessary dimensions. The relative multitude of the three applied algorithms the K-Nearest-Neighbour, the Support Vector Machine (SVM), and Logistic Regression, Support Vector provides the most noteworthy exactness of 93.8% when calculated with different calculations.
References
[1] P. Boix-Montesinos, M.J. Vicent,, A. Armiñán, M. Orzáez, P.M. Soriano-Teruel. Breast Cancer models for nano-medicine development Adv. Drug Deliv. Rev. [2] Aamodt, Agnar, and Enric Plaza. “AI communications: Foundational issues, methodological variations, and system approaches.” [3] M.A. T.-S. Kim Al-Antari. Computation of deep learning detection. [4] M.M. Freire, F. Soares. Surveying of breast masses on contrast-enhanced magnetic resonance images.
Copyright
Copyright © 2022 Devanshu Rathi, Chanchal Rathad, Avishkar Raskar, Om Randhave, Mukta Rasal. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET47875
Publish Date : 2022-12-04
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online