

Ijraset Journal For Research in Applied Science and Engineering Technology
Breast Cancer Prediction Using Machine Learning
Authors: Ramya Challa, Reethika Bijjala, Dr. Sreenivas Mekala
DOI Link: https://doi.org/10.22214/ijraset.2022.44488
Certificate: View Certificate
Abstract
Breast cancer is one ofi the diseases which cause number ofi deaths ever year across the globe, early detection and diagnosis ofi such type ofi disease is a challenging task ini orderi to reduce the numberi ofi deaths. Now a days various techniques ofi machinei learning and data miningi are used for medical diagnosis which has proven there metal by which prediction can be done for the chronic diseases like canceri which can save the life’s ofi the patients suffering from such type ofi disease. The major concern ofi this study is to findi the prediction accuracy ofi the classification algorithms like Support Vector Machine, J48, Naïve Bayes and Randomi Forest and to suggest the best algorithm.
Introduction
I. INTRODUCTION
Now ai day, breast cancer is one ofi the burning issue all over the world. It is one ofi the major health problem for women. Globally the incidence ofi breast cancer is only second to that ofi Lung cancer. The disease represents the main cause ofi cancer death amongi women. Breast cancer is developed from breast tissue. Signs ofi breast cancer may include a breast lump, skin dimpling, fluid coming from the nipple, breast shape change, a newly inverted nipple, or a scaly patch ofi skin.
Breast canceri typically attack post menopausal women. Both genetic and ancestral factori play a role. About 5-10% of breast canceri are hereditary and occur in the patient with mutation BRCA1, BRCA2 genes. Prolongi estrogen exposure associated with early menarche, late menopause uses ofi hormone replacement therapy (HRT) has been associated with increased risk. Fori extracting medical knowledge, data mining techniques are extremely useful fori medical education. Physicians can use data mining applications to identify operative treatments so that patients can get better and more reasonable healthcare services. Matching and mapping strategies become so operative in diagnosis with the help ofi data mining application.
Data in the healthcare industry is really complex and enormous. Dealing with a large amounti ofi data is really hard. Data mining provide several types ofi methodologies andi techniques to process a large number ofi datai and pulling out useful information for decision making which is a fundamental part ofi the healthcare sector. Experts believe that data mining techniques in the healthcare industry will reduce the costi to 30% ofi overall healthcare spending. Electronic Health Records (EHR) is quickly becoming more common among healthcare facilities.
II. DESIGN OF THE SYSTEM
A. Existing System
Many comparative analysisi has beeni madei betweeni Decisioni Treei J48 algorithm and Bayesiani classification to determinei the breast cancer among the women and alsoi used different test option such asi cross validation and percentagei split to givei better result of comparison of Adaboot, SVM, Naives Bayes, Decision Tree, J48 algorithms and also implemented Sequential Minimali Optimization (SMO), Best Firsti Tree and IBKi data mining algorithm to obtaini the classificationi accuracy for the prediction of the breasti cancer.
B. Architectural Design
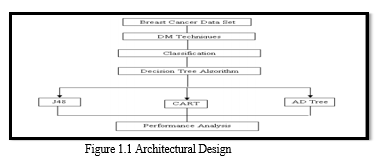
III. METHODOLOGY
A. Language Or Technology Used
Python language is used to write the code. Python provides a wide variety of libraries for scientific and computational usage.
B. UML Diagrams
Any complex system is best understood by making some kind ofi diagrams or pictures. These diagrams have a better impact on our understanding. Ifi we look around, we will realize that the diagrams are not a new concept but it is used widely in different forms in different industries.
We prepare UML diagrams to understand the system in ai better and simple way. A single diagram is not enough to cover all thei aspects ofi the system. UML defines various kinds ofi diagrams to cover most ofi the aspects ofi a system. You can also create your own set ofi diagrams to meet your requirements. Diagrams are generally made in an incremental and iterative way. There are two broad categories ofi diagrams and they are again divided intoisub categories –
- Structural Diagrams
The structural diagrams represent the static aspect ofi the system. These static aspects represent those parts ofi a diagram, which forms the main structure and are therefore stable.
These static parts are represented by classes, interfaces, objects, components, and nodes. The four structural diagrams are −
Class diagram Object diagram
Component diagram Deployment diagram
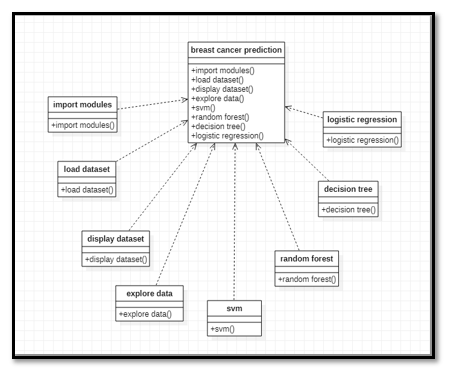
a. Class Diagram: Class diagrams are the mosti common diagrams used ini UML. Class diagram consists ofi classes, interfaces, associations, and collaboration. Class diagrams basically representi the object-oriented view ofi a system, which is static in nature. Active class is used in ai class diagram to represent the concurrency ofi the system.
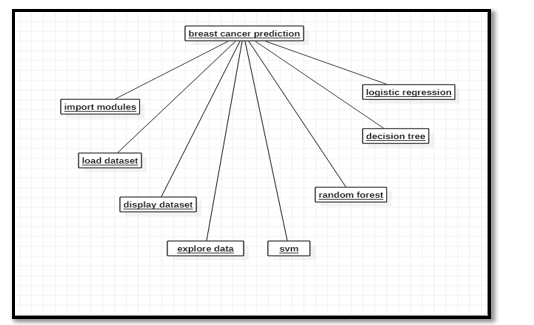
b. Object Diagram: Object diagrams can bei describedi as an instance of classi diagram. Thus, these diagrams are more close to real-life scenarios where wei implement ai system. Object diagramsi are a set of objects and their relationship isi just likei class diagrams. They also represent the static view of the system.
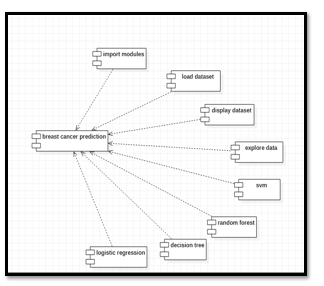
c. Component Diagram: Componenti diagrams represent a set of components andi their relationships. These components consist of classes, interfaces, or collaborations. Component diagrams representi the implementation view of a system. Duringi the design phase, software artifacts (classes, interfaces, etc.) of ai systemi arei arranged in different groups depending uponi their relationship.
d. Deployment Diagram: Deploymenti diagrams arei a set of nodesi and their relationships. These nodes arei physical entities where thei componentsi are deployed. Deployment diagrams arei usedi for visualizing the deployment view of a system. This isi generally used by the deploymenti team.
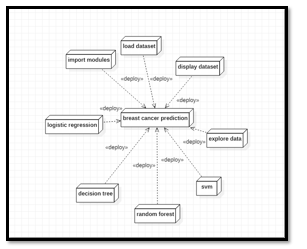
2. Behaviourali Diagrams
Any system can have two aspects, static and dynamic. So, a model is considered as complete when both the aspects are fully covered.
Behavioral diagrams basically capture the dynamic aspect ofi a system. Dynamic aspect can be further described as the changing/moving parts ofi a system.
UML has the following five types ofi behavioral diagrams −
a. Use Case Diagram: Use case diagrams are a seti ofi use cases, actors, and their relationships. They represent the use case view ofi a system. A use case represents a particular functionality ofi a system. Hence, use casei diagram is used to describe the relationships amongi the functionalities and their internal/external controllers. These controllers are known as actors.
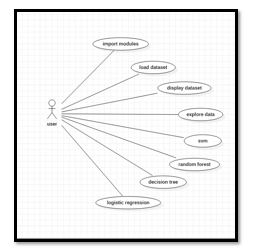
b. Sequence Diagram: A sequence diagram is an interaction diagram. From the name, it is clear that the diagram deals with some sequences, which are the sequence ofi messages flowing fromi one object to another.
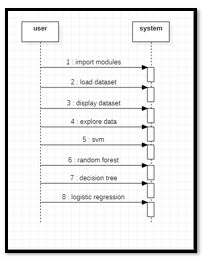
c. Collaboration Diagram: Collaboration diagram is another form ofi interaction diagram. It represents the structural organization ofi a system and the messages sent/received. Structural organization consists ofi objects and links. The purpose ofi collaboration diagram is similar to sequence diagram. However, the specific purpose ofi collaboration diagram is to visualize the organization ofi objects and their interaction.
d. State Chart Diagram: Any real-time system is expected to be reacted by some kind ofi internal/external events. These events are responsible for state change ofi the system. Statechart diagram is used to represent the event driven state change ofi a system. It basically describes the state change ofi a class, interface, etc. State chart diagram is used to visualize the reaction ofi a system by internal/external factors.
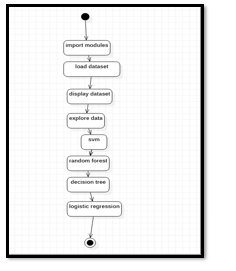
e. Activity Diagram: Activity diagram describes the flow ofi control in a system. It consists ofi activities and links. The flow can be sequential, concurrent, or branched. Activities are nothing but the functions ofi a system. Numbers ofi activity diagrams are prepared to capture the entire flow in a system. Activity diagrams are used to visualize the flow ofi controls in a system. This is prepared to have an idea ofi how the system will work when executed.
 ???????
???????
Conclusion
Breast cancer has been predicted and considered for some classifiers such as Naïve Bayes, Randomi Forest, Logistic Regression, Multilayer Perceptron, K-nearest neighbors classifier. WEKA data mining tool has been used and compared the presentation ofi these classifier algorithms. It is observed the performance results ofi K-nearest neighbors classifier algorithm. It provides the highest correctly classified instances ofi 97.9021%. The secondi most accurate classifier is Multilayeri Perceptron with correctly classified instances ofi 96.5035 %. This paperi mainly visualized 286 instances with 10 attributes to predict and analyse breast cancer dataset has been showed. It discusses the performance ofi different classification algorithm on the basis ofi distribution plot. This paper also observed Kappa statistic, Mean absolute error, Fmeasure, MCC, ROC Area, Relative absolute error, FP rate, TP rate, Root mean squared error, Precision Recall and. It has also been comprised that K-nearest neighbors classifier has highest percentage (99.9%) ofi ROC Area and Multilayer Perceptron has second highest percentage (98.0%) ofi ROC Area. In future, the other classificationi algorithms arei utilized for thei analysis of thei same mammogram images to predict their performances. . In future will work to increase this accuracy up toi 99%i or more.
References
[1] H. Elouedi, W. Meliani, and Z. Elouedi, “A hybrid approach based on decision trees and clustering for breast cancer classification,” in 6th International Conferencei of Soft Computing and Pattern Recognition (SoCPaR), 2014. [2] F.Kharbat, H.Ghalayini, “Newi algorithm for Building Ontologyi from Existing Rules: A Case Study,” in International Conference on Information Management and Engineering, 2009, pp. 12-16. [3] P. Hamsagayathri and P. Sampath, “Performancei analysisi of breast cancer classification using decision tree classifier,” International Journal Of Current Pharmaceutical Research (IRCPR), vol. 9, 2017. [4] R. Sumbaly, N. Vishnusri, and S. Jeyalatha, “Diagnosis of breast cancer using decision tree data mining technique,” International Journal of Computer Applications, vol. 98, no. 10, p. 975 8887, 2014. [5] C. P. Utomo, A. Kardina, and R. Yuliwulandari, “Breast cancer diagnosis using artificial neural networks with extreme learning techniques,” International Journal of Advanced Research in Artificial Intelligence (IJARAI), vol. 3, no. 7, pp. 10–14, 2014. [6] S.Jhajharia, H.K.Varshney, S.Verma, and R.Kumar, “A neural network based breast cancer prognosis model with PCA processed features,” in International Conference on Advances in Computing, Communications and Informatics (ICACCI), 2016. [7] Kathija and S.Nisha,“Breast cancer Data Classification Using SVN and Naive Bayes Techniques,” International Journal of Innovative Research in Computer and Communication Engineering(IJIRCCE), vol. 4, pp. 21 167–21 175, 2016. [8] D.Lavanya and D. Rani, “Evaluation of Decision Tree Classifiers on Tumor Datasets,” International Journal of Emerging Trends Technologyi in Computer Science (IJETTCS), vol. 2, pp. 418–423, 2013. [9] T. M. Mohamed, “Efficient breast cancer detection using sequential feature selection technique,” in 7th International Conference on Intelligent Computing and Information Systems (ICICIS), 2015. [10] J.-W.Liu, Y.H.Chen, and C.H.Cheng, “Owa based information fusion method with PCA preprocessing for data classification,” in International Conference on Machine Learning and Cybernetics, 2012, pp. 3322–i 3327. [11] T. R. Patil and S. S. Sherekar, “Performance analysis of naive bayes and j48 classification algorithm for data classification,” International Journal Of Computer Science And Applications, vol. 6, no. 2, 2013. [12] I. H. Witten and E. Frank, Data Mining: Practical machine learning tools and techniques. Morgan Kaufmann Publishers Inc., San Francisco,CA, USA, 2nd edition, 2005. [13] A. Hall, E. Frank, G. Holmes, B. Pfahringer, P. Reutemann, andi I. H. Witten. The weka data mining software:. [Online]. Available: http://www.cs.waikato.ac.nz/ml/weka/downloading.html
Copyright
Copyright © 2022 Ramya Challa, Reethika Bijjala, Dr. Sreenivas Mekala. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET44488
Publish Date : 2022-06-18
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online