

Ijraset Journal For Research in Applied Science and Engineering Technology
Face Recognition Based Attendance System
Authors: Bhushan Laddha, Devanshu Rathi, Atharva Mugalikar, Bhushan Hatwar, Sakshi Bothe
DOI Link: https://doi.org/10.22214/ijraset.2023.47804
Certificate: View Certificate
Abstract
Out of the most common uses for image processing is face identification, which is important in the technological field. Recognizing faces is a hot issue for verification, especially in student attendance competitions. A face recognition attendance system uses high-definition surveillance and other computer technologies to identify students using face biostatistics. The developing system aims to digitize the outdated method of calling names and maintaining pen-and-paper attendance records. The existing procedures for recording attendance are cumbersome and time-consuming. Manual recording allows for easy manipulation of maintenance records. Traditional attendance systems and current biometric technologies are subject to proxies. As a result, this study is proposed to address all of these issues.
Introduction
I. INTRODUCTION
Administration's extremely important aspect of attendance can sometimes turn into a tedious, duplicated task that pushes for errors. Since it is quite challenging to call names and keep track of them, especially when the student-to-teacher ratio is large, the conventional technique of doing so proves to be a statute of limitations. Each organization has a unique system for determining student attendance. While some firms use a document-centric strategy, others have embraced digital processes like card switching and biometric fingerprinting. These remedies, however, show to be a statute of limitations because they need students standing in a lengthy queue. If the student doesn't show his ID, he won't be allowed to get attendance..In a changing world, growing technology has achieved numerous advancements.
Biometrics are commonly used to develop intelligent attendance systems. One of the biometric approaches to improve this system is to recognize faces. Face recognition has been shown to be a successful means of taking attendance. Scaling, position, illumination, variations, rotation, and occlusions are all issues that traditional face recognition approaches and methodologies fail to address. The suggested framework is intended to address the shortcomings of present systems. Face recognition has come a long way, but the three most important processes are face detection, feature extraction, and face recognition.
II. LITERATURE REVIEW
According to the literature survey, to find the 68 landmarks on some faces and one millisecond face alignment with an ensemble of algorithms were the subjects of research by Vahid Kazemi et al., [1] regression trees that might potentially locate the 68 landmarks in a matter of milliseconds. They chose landmarks using two baselines: correlation-based feature selection and random feature selection. The quantity of training photos utilized as input for this method directly affects how hard the training process is.
III. FLOWCHART
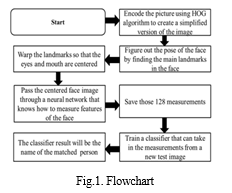
IV. METHODOLOGY
We need to build a pipeline where we solve each step of face recognition separately and pass the result of the current step to the next step. In other words, we will chain together several machine learning algorithms.
HOG is founded on the idea that, even without precise information of the related edge or gradient positions, the distribution of local intensity can frequently provide a fairly accurate description of the appearance and shape of local objects. By segmenting the image window into the necessary number of sections, a local histogram of gradient axes can be built across the pixels in each little spatial region. The representation is created by combining the histogram entries from above.[1]
There are numerous advantages of using the HOG function. It captures gradient structure with very little local geometric and photometric change invariance and a strong local shape-specificity. The result is a pretty simple representation of the original image that highlights the key elements of a face. The measurements that seem so distinct and evident to us humans are not fully understood by a machine that is evaluating individual pixels in an image.[2]
Deep learning techniques can reportedly be applied in these circumstances where the system requires measurements. The complex raw data, such as a picture or a video, can be reduced to a list of computer-generated numbers using a significant amount of machine learning (particularly in language translation). The Deep Convolutional Neural Network is trainable. It takes a lot of data and computing power to train a convolutional neural network to produce face embedding. However, after the network has been trained, it is capable of producing measurements for any face, even ones it has never seen before. To obtain the 128 measurements for each face, all we have to do is feed the images of the faces through trained networks.[3]
The last step is to search for the name in the database which has the closest measurements to our test image.
A. Working of HOG
The first step is to compute the image gradient in x and y direction. As an example, say Q has values surrounding as below

- Step 1: To Find all the Faces
The First Step in the pipeline is face detection.
Face recognition is a fantastic camera feature. When a camera can detect faces automatically, it can ensure that all of them are in focus before taking a photo. However, we'll use it for something else: identifying the areas of the image that ought to be forwarded to the following stage of our pipeline.
When Paul Viola and Michael Jones created a technology to detect faces that were quick enough to operate on cheap cameras in the early 2000s, face detection became ubiquitous. However, there are now far more reliable options available. We'll utilize a technique called Histogram of Oriented Gradients, or HOG for short, that was developed in 2005.
We will start by making our image black and white because we don’t need color data to find faces:

Our objective is to calculate the relative brightness of the current pixel to the pixels around it. The direction the image is darkening will then be indicated by an arrow.
If you repeat this method for each and every pixel in the image, each pixel will be replaced by an arrow. Gradients are the arrows that depict the transition from bright to dark throughout the entire image: Although it could seem like a random decision, utilising gradients rather than pixels has a valid reason. Direct examination of the pixels reveals that images of the same person taken in extreme darkness and light may have entirely different pixel values. However, both extremely dark and extremely bright photographs will have the exact same representation if you only consider the brightness's direction of variation. That makes solving the issue much simpler!
However, keeping the gradient for each and every pixel gives us far too much information. We lose sight of the forest for the trees. It would be preferable if we could simply observe the basic flow of lightness/darkness at a higher level in order to see the core pattern.
To accomplish this, we'll divide the image into 16x16 pixel squares. We'll count how many gradients point in each main direction (how many points up, up-right, right, etc...) in each square. Then we'll replace that square in the image with the strongest arrow directions.
As a consequence, we've transformed the original image into a very simple representation that accurately captures the essential anatomy of a face:

2. Step 2: Posing and Projecting Faces
In the photograph, we isolated the faces. But now we have to cope with the fact that faces oriented in different orientations seem to a computer in completely different ways:
To compensate for this, we will attempt to deform each image so that the mouth and eyes are always at the sample location. The future steps will make it much easier to compare faces as a consequence. We'll employ a technique called facial landmark estimation to do this.. The key concept is to detect 68 distinct areas on every face. After that, we'll teach a computer learning system to recognize these 68 specific places on any face:

3. Step 3: Encoding Faces
Researchers have discovered that letting the computer figure out the measures to collect itself is the most accurate method. When it comes to determining which elements of a face are crucial to assess, deep learning outperforms humans.
The answer is to use a Deep CNN to train. We're going to train the network to create 128 measures for each face instead of training it to recognize visual objects like we did last time.
When training, three face images are viewed simultaneously:
a. Load facial image of a known individual as a training face.
b. Load a different image of the same well-known figure.
c. Replace the image with one of a completely different individual.

4. Step 4: To decode the candidates’ names and find their names
Actually, this final step is the easiest of the entire model. The only thing left to do is search through our database of known person to find the individual whose dimensions are closest to those in our test photograph.
This may be accomplished using any core machine learning classification technique. No complex methods are necessary. Although we’ll employ a straightforward linear SVM classifier, any classification method may be effective.
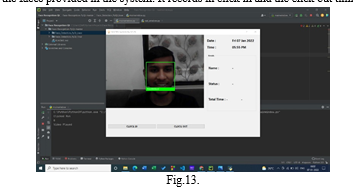
V. RESULTS AND DISCUSSIONS
The model is able to detect the faces provided in the system. It records in click in and the click out timings of the user.
VI. FUTURE SCOPE
Since most college students still utilize manual attendance systems that need paper signatures or instructor commands for daily attendance, the attendance system for colleges can be improved for their usage. Python was used to create a powerful face recognition system that could reliably identify faces in any environment for security and verification needs. Increasing the number of photos used during training will increase facial recognition's accuracy. Using HOG approaches, the findings of person identification show positive signs. Future versions of the same recognition system could include text-to-audio features in addition to a facial expression recognizer; this would be especially helpful for visually impaired people who need to be able to identify people in public settings or within organizations.
Conclusion
Face Recognition smart attendance systems can be used in classrooms, laboratories, and workplaces, as well as for security purposes. This technology eliminates the shortcomings of the traditional attendance marking system, and face recognition outperforms all other biometric methods. This strategy can reduce the chance of the proxy method.
References
[1] Vahid Kazemi and Josephine Sullivan “one millisecond face alignment with an ensemble of regression trees” was presented at computer vision and pattern recognition (cvpr), 2014 IEEE conference. [2] S. Happy, A. Routray, Automatic facial expression recognition using features of salient facial patches, IEEE Transactions on Affective Computing (2015). [3] Mohsen Ghorbani, Alireza Tavakoli and Mohammed Mahdi Dehshibi HOG and LBP: towards a robust face recognition system was presented at Digital Information Management (ICDIM), 2015 Tenth International Conference. [4] Pranav Kumar, S.L.Happy, Aurobindo Routray A Real-time Robust Facial Expression Recognition System using HOG features was presented at the International Conference on Computing, Analytics and Security trends, 2016. [5] Michael Owajyan, Roger Achkar, Moussa Iskandar Face Detection with Expression Recognition using Artificial Neural Networks at the Middle East Conference on Biomedical Engineering and published at the IEEE conference, 2016. [6] Y.Sun, X.Wang, X.Tang, Deep Convolutional network Cascade for facial point detection in Computer Vision and Pattern Recognition, 2013 IEEE conference. [7] A. Albiol, D. Monzo, A. Martin, J. Sastre, A. Albiol, Face recognition using HOG-EBGM, Publisher, City, 2008. [8] Aniwat Juhong, C.Pintavirooj “Face Recognition based on Facial Landmark Detection”,BMEiCON – 2017. [9] Rajesh K M, Naveenkumar M, “An Adaptive-Profile Modified Active Shape Model for Automatic Landmark Annotation Using Open CV”, International Journal of Engineering Research in Electronic and Communication Engineering (IJERECE), Vol.3, Issue.5, pp:18-21, May 2016. [10] Jan Erik Solem, “Programming Computer Vision with Python”, First Edition , ISBN 13:978-93-5023-766-3, July 2012 [11] https://medium.com/@ageitgey/machine-learning-is-fun-part-4-modern-face-recognition-with-deep-learning-c3cffc121d78 J. Clerk Maxwell, A Treatise on Electricity and Magnetism, 3rd ed., vol. 2. Oxford: Clarendon, 1892, pp.68–73.
Copyright
Copyright © 2023 Bhushan Laddha, Devanshu Rathi, Atharva Mugalikar, Bhushan Hatwar, Sakshi Bothe. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET47804
Publish Date : 2022-11-30
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online