

Ijraset Journal For Research in Applied Science and Engineering Technology
Fake News Detection Using Machine Learning
Authors: Hemalatha A, Karpahalakshmi S, Thanga Sri R, Vaishnavi M, Bhavani N
DOI Link: https://doi.org/10.22214/ijraset.2022.44048
Certificate: View Certificate
Abstract
The role of social media in our day to day life has increased rapidly in recent years. Information quality in social media is an increasingly important issue, but web-scale data hinders experts’ ability to assess and correct much of the inaccurate content, or “fake news”, present in these platforms. It is now used not only for social interaction, but also as an important platform for exchanging information and news. Twitter, Facebook a micro-blogging service, connects millions of users around the world and allows for the real-time propagation of information and news. The fake news on social media and various other media is wide spreading and is a matter of serious concern due to its ability to cause a lot of social and national damage with destruction impacts. A lot of research is already focused on detecting it. A human being is unable to detect all these fake news. Detecting fake news is an important step. This process will result in feature extraction and vectorization; we propose using Python scikit-learn library to perform tokenization and feature extraction of text data, because this library contains useful tools like Count Vectorizer and Tiff Vectorizer. Then, we will perform feature selection methods, to experiment and choose the best fit features to obtain the highest precision, according to confusion matrix results. A feature analysis then identifies features that are most predictive for crowdsourced and journalistic accuracy assessments, results of which are consistent with prior work. We aim to provide the user with the ability to classify the news as “fake” or “real”.
Introduction
I. INTRODUCTION
In today’s world social media plays an important role in information passing. It is mandatory to identify the truthfulness of the information which has been circulated in order to avoid fault manipulation, misconception and to create minimum impact on society regarding the fake news.
Machine Learning (ML) is a branch of Artificial Intelligence which includes the study of computer algorithms that improve automatically through experience. It allows applications to become more accurate in predicting outcomes without explicitly programmed based on the training data. Machine Learning models help us in many tasks, such as: Object Recognition, Summarization, Prediction, Classification, Clustering, Recommender systems.
Machine Learning (ML) is one of the most exciting technologies that one would have ever come across. As it is evident from the name, it gives the computer that makes it more similar to humans: The ability to learn. Machine learning is actively being used everywhere.
The process starts with feeding good quality data and then training our machines (computers) by building machine learning models using the data and different algorithms. The choice of algorithms depends on what type of data we have and what kind of task we are trying to automate.
Machine Learning (ML) has proven valuable because it can solve problems at a speed and scale that cannot be duplicated by the human mind alone. With massive amounts of computational ability behind a single task or multiple specific tasks, machines can be trained to identify patterns in and relationships between input data and automate routine processes.
II. ALGORITHM
A. TF-IDF Vectorizer
TF-IDF vectorizer technology is used in the model. It is a common algorithm to transform text into meaningful representation of numbers. It is used to extract features from text strings based on occurrence.
TF-IDF is an acronym that stands for “Term Frequency – Inverse Document” Frequency which are the components of the resulting scores assigned to each word.
TF-IDF is a numerical statistic which measures the importance of the word in a document.
It helps us in dealing with the most frequent words. Using it we can penalize them. Tf-idf Vectorizer weights the word counts by a measure of how often they appear in the documents.
1. TF (Term Frequency)
The number of times a word appears in a document is its Term Frequency. A higher value means a term appears more often than others, and so, the document is a good match when the term is part of the search terms.
Term frequency indicates how important a specific term is in a document. Term frequency represents every text from the data as a matrix whose rows are the number of documents and columns are the number of distinct terms throughout all documents.
2. IDF (Inverse Document Frequency)
Words that occur many times in a document, but also occur many times in many others, may be irrelevant. IDF is a measure of how significant a term is in the entire corpus.
The TF-IDF Vectorizer converts a collection of raw documents into a matrix of TF-IDF features.
Document frequency is the number of documents containing a specific term. Document frequency indicates how common the term is. Inverse document frequency (IDF) is the weight of a term, it aims to reduce the weight of a term if the term’s occurrences are scattered throughout all the documents.
B. Passive Aggresive Classifier
Passive Aggressive algorithms are online learning algorithms. Such an algorithm remains passive for a correct classification outcome, and turns aggressive in the event of a miscalculation, updating and adjusting. Unlike most other algorithms, it does not converge. Its purpose is to make updates that correct the loss, causing very little change in the norm of the weight vector.
This is very useful in situations where there is a huge amount of data and it is computationally infeasible to train the entire dataset because of the sheer size of the data.
- Working of Passive-Aggressive Algorithms: Passive-Aggressive algorithms are called so because :
- Passive: If the prediction is correct, keep the model and do not make any changes. i.e., the data in the example is not enough to cause any changes in the model.
- Aggressive: If the prediction is incorrect, make changes to the model. i.e., some change to the model may correct it
C. Confusion Matrix
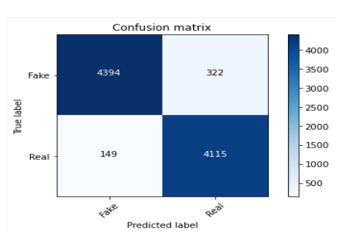
D. Sentimental Analyzer
Sentiment Analysis is a procedure used to determine if a chunk of text is positive, negative or neutral. In text analytics, natural language processing (NLP) and machine learning (ML) techniques are combined to assign sentiment scores to the topics, categories or entities within a phrase.
Sentiment analysis is used to determine whether a given text contains negative, positive, or neutral emotions. It’s a form of text analytics that uses machine learning.
Sentiment analysis looks at the emotion expressed in a text. It is commonly used to analyze customer feedback, survey responses, and product reviews. Social media monitoring, reputation management, and customer experience are just a few areas that can benefit from sentiment analysis. We have used sentimental analysis for detecting the positiveness in the news that are posted in social media.
- Need of Sentimental Analysis
Sentiment Analysis is a Natural Language Processing and Information Extraction task that aims to obtain writer’s feelings expressed in positive or negative comments, questions and requests, by analyzing a large number of documents. It is also a machine learning tool used to study human behavior that analyzes texts for polarity, from positive to negative. By training machine learning tools with examples of emotions in text, machines automatically learn how to detect sentiment without human input.
Sentiment analysis can be used to quickly analyze the text of research papers, news articles, social media posts like tweets and more. Social Sentiment Analysis is an algorithm that is tuned to analyze the sentiment of social media content, like tweets and status updates.
Automatically extracting opinions, emotions and sentiments in text. Language - independent technology that understands the meaning of the text. It identifies the opinion or attitude that a person has towards a topic or an object.
Sentiment analysis is a powerful marketing tool that enables product managers to understand customer emotions in their marketing campaigns. It is an important factor when it comes to product and brand recognition, customer loyalty, customer satisfaction, advertising and promotion's success, and product acceptance.
In our project, once the user gives the news as the input, data undergoes the preprocessing stage, where the words get stemmed and tokenized. Next, the data is given to the Sentimental Analyzer from where the sentiment of the news is detected based on the positivity of the news.
II. SYSTEM DESIGN
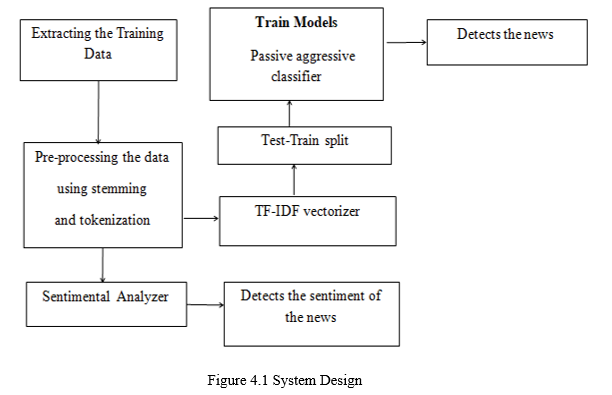
A. ns using Passive Aggressive Classifier to give the desired output.
Our system also analyzes the sentiment of the news, where the news is given as an input. Data preprocessing is done, in order to analyze the positiveness of the news.
B. Data Preprocessing
- Data Preprocessing: Data preprocessing is a technique of preparing (cleaning and organizing) the raw data to make it suitable for building and training Machine Learning models.
2. Need of Data Preprocessing
- A real-world data generally contains missing values, and maybe in an unusable format which cannot be directly used for machine learning models.
- Data preprocessing is a task for preparing the data and making it suitable for a machine learning model which also increases the accuracy and efficiency of a machine learning model.
3. Stopwords
- The words which are generally filtered out before processing a natural language are called stop words.
- These are actually the most common words in any language (like articles, prepositions, pronouns, conjunctions, etc) and does not add much information to the text.
- For tasks like text classification, where the text is to be classified into different categories, stopwords are removed or excluded from the given text so that more focus can be given to those words which define the meaning of the text.
4. Stemming: Stemming tries to cut off details like exact form of a word and produce word bases as features for classification. Stemming is important in natural language understanding (NLU) and natural language processing (NLP).
5. Need of Stemming: When a text is pre-processed for classification purposes, stemming is applied in order to bring words from their current variation to their original root in order to better the process in natural language with subsequent steps..
6. Tokenization: Tokenization is a way of separating a piece of text into smaller units called tokens. Here, tokens can be either words, characters, or subwords. Hence, tokenization can be broadly classified into 3 types – word, character, and subword tokenization .As tokens are the building blocks of Natural Language, the most common way of processing the raw text happens at the token level.
7. Need of Tokenization: Tokenization helps in understanding the context or developing the model for Natural Language Processing. The tokenization helps in interpreting the meaning of the text by analyzing the sequence of the words.

Figure 4.2 Tokenization of Fake news dataset

Figure 4.3 Tokenization of Real news dataset
IV. IMPLEMENTATION
The entire project is implemented using Python, the library and packages includes:
- Flask: Flask is a small and lightweight Python web framework that provides useful tools and features that make creating web applications in Python easier. It gives developers flexibility and is a more accessible framework for new developers.
- Importlib-metadata: importlib. metadata is a library that provides for access to installed package metadata. Built in part on Python's import system, this library intends to replace similar functionality in the entry point API and metadata API of pkg_resources.
- Joblib: Joblib is a set of tools to provide lightweight pipelining in Python. It works with both file objects and string filenames.
- Nltk: The Natural Language Toolkit (NLTK) is a platform used for building Python programs that work with human language data for applying in statistical natural language processing (NLP).It contains text processing libraries for tokenization, parsing, classification, stemming, tagging and semantic reasoning.
- Numpy: NumPy is a library for Python that adds support for large, multi-dimensional arrays and matrices, along with a large collection of high-level mathematical functions to operate on these arrays.
- Pandas: Pandas is an open source Python package that is most widely used for data science/data analysis and machine learning tasks. It is built on top of another package named Numpy.
- Python-dateutil: The dateutil module provides powerful extensions to the standard datetime module. This module supports the parsing of dates in any string format. This module provides internal up-to-date world time zone details.
- Scikit-learn: The sklearn library is probably the most useful library for Machine Learning. It contains a lot of efficient tools for machine learning and statistical modeling including classification, regression, clustering and dimensionality reduction.
- Scipy: SciPy stands for Scientific Python. It provides more utility functions for optimization, stats and signal processing. SciPy is a scientific computation library that uses NumPy underneath.
- Typing-extensions: The typing-extensions module serves two related purposes: Enable use of new type system features on older Python versions.
- Requests: The requests module allows you to send HTTP requests using Python. The HTTP request returns a Response Object with all the response data. It works as a request-response protocol between a client and a server.
The implementation is segregated into several modules according to the process:
- Importing the dataset
- Data pre processing
- Training the model
- Sentimental Analyzer
A. Importing The Dataset
The first step involves importing the dataset. The two datasets namely Real and Fake having the real news data and fake news data respectively are to be imported as separate csv files. Datasets namely,
- True.csv
- Fake.csv
B. Data Preprocessing
Data cleaning
- Stemming: Stemming is the process of reducing a word to its word stem that affixes to suffixes and prefixes or to the roots of words known as a lemma. Stemming is important in natural language understanding (NLU) and natural language processing (NLP). When a text is pre-processed for classification purposes, stemming is applied in order to bring words from their current variation to their original root in order to better the process in natural language with subsequent steps.
- Stop Words: The words which are generally filtered out before processing a natural language are called stop words. These are actually the most common words in any language (like articles, prepositions, pronouns, conjunctions, etc) and does not add much information to the text. For tasks like text classification, where the text is to be classified into different categories, stopwords are removed or excluded from the given text so that more focus can be given to those words which define the meaning of the text.
- Tokenizing Text: Tokenization is a way of separating a piece of text into smaller units called tokens. Here, tokens can be either words, characters, or subwords. Hence, tokenization can be broadly classified into 3 types – word, character, and subword tokenization .As tokens are the building blocks of Natural Language, the most common way of processing the raw text happens at the token level. Tokenization helps in understanding the context or developing the model for Natural Language Processing. The tokenization helps in interpreting the meaning of the text by analyzing the sequence of the words.
C. Training The Model
Training a model simply means learning (determining) good values for all the weights and the bias from labeled examples. Usually, machine learning models require a lot of data in order for them to perform well. Usually, when training a machine learning model, one needs to collect a large, representative sample of data from a training set. Data from the training set can be as varied as a corpus of text.
- Tf-idf Vectorizer: TF-IDF is a statistical measure that evaluates how relevant a word is to a document in a collection of documents. This is done by multiplying two metrics: how many times a word appears in a document, and the inverse document frequency of the word across a set of documents.
- Passive Aggressive Classifier: Passive Aggressive algorithm remains passive for a correct classification outcome, and turns aggressive in the event of a miscalculation. Its purpose is to make updates that correct the loss, causing very little in the norm of weight vector.
D. Sentiment Analyzer
Once the user gives the input, data gets preprocessed by stemming and tokenization. Preprocessed data is given to the sentiment analyzer to analyze the sentiment of the news.
V. FUTURE ENHANCEMENT
Fake news Detector detects only the linguistic-based information as Real or Fake.In our application ,news articles are given as the input and the output is delivered as real or fake. Also our application detects the sentiment of the required news.Our future enhancement of our project is to give more details on the fake news detection by including the publisher of the article,subject of the article and also to detect the visual-based information as real or fake.
Conclusion
media, more and more people consume news from social media instead of traditional news media. However, social media has also been used to spread fake news, which has strong negative impacts on individual users and to the society.Classification news manually requires in-depth knowledge of the domain and expertise to identify anomalies in the text. In Fake News Detection, we discussed the problem of classifying fake news articles and their sentiments using TF-IDF vectorizer,Passive aggressive classifier and VaderSentiment.
References
[1] DETECTING FAKE NEWS WITH MACHINE LEARNING METHOD, Supanya Aphiwongsophon, Prabhas Chongstitvatana, Department of Computer Engineering, Faculty of Engineering Chulalongkorn, University Bangkok, Thailand, July, 2018 [2] A SMART SYSTEM FOR FAKE NEWS DETECTION USING MACHINE LEARNING, Anjali Jain, Harsh Khatter and AvinashShakya, Dr. APJ Abdul Kalam University, Lucknow, India, September, 2019. [3] FAKE NEWS DETECTION USING MACHINE LEARNING ENSEMBLE METHODS, Iftikhar Ahmad, Muhammad Yousaf and Suhail Yousaf - Department of Computer Science and Information Technology, University of Engineering and Technology, Peshawar, Pakistan. Muhammad Ovais Ahmad - Department of Mathematics and Computer Science, Karlstad University, Karlstad, Sweden, October, 2020. [4] FAKE NEWS DETECTION USING PASSIVE AGGRESSIVE AND TF-IDF VECTORIZER, Jayashree M Kudari - Jain University. Varsha V, Monica BG and Archana R - UG Scholar, Jain University, September, 2020. [5] FAKE NEWS DETECTION USING MACHINE LEARNING, Vijaya Balpande, Kasturi Baswe, Kajol Somaiya, Achal Dhande, Prajwal Mire - Department of Computer Science and Engineering, Priyadarshini J. L. College of Engineering, Nagpur, Maharashtra, India, June, 2021. [6] AN AUTONOMOUS MODEL FOR FAKE NEWS DETECTION, Noman Islam - Department of Computer Science, Iqra University, Karachi, Pakistan. Asadullah Shaikh, Yousef Asiri , Sultan Almakdi and Adel Sulaiman - College of Computer Science and Information Systems, Najran University, Najran 61441, Saudi Arabia. Asma Qaiser, Verdah Moazzam and Syeda Aiman Babar - Department of Computer Science, NED University of Engineering and Technology, Karachi, Pakistan, October, 2021.
Copyright
Copyright © 2022 Hemalatha A, Karpahalakshmi S, Thanga Sri R, Vaishnavi M, Bhavani N. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET44048
Publish Date : 2022-06-10
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online