

Ijraset Journal For Research in Applied Science and Engineering Technology
Lightweight URL Phishing Detection System Using SVM and Similarity
Authors: Khan Danish Musa, Shaikh Moaaz Ahmed, Anwar Ismail Khan
DOI Link: https://doi.org/10.22214/ijraset.2022.40119
Certificate: View Certificate
Abstract
As a criminal offense of employing technical method to thieve sensitive information of customers, phishing is presently an important risk facing the net, and losses because of phishing are developing regularly. function engineering is essential in phishing website detection answers; however, the accuracy of detection critically relies upon on earlier knowledge of features. furthermore, even though features extracted for one-of-a-kind dimensions are more comprehensive, a disadvantage is that extracting those functions calls for a massive amount of time. To address those barriers, we propose a multidimensional characteristic phishing detection method based on a quick detection approach by way of the usage of deep mastering (MFPD). within the first step, character sequence functions of the given URL are extracted and used for brief class by means of deep mastering, and this step does not require 1/3-party assistance or any prior know-how approximately phishing. inside the 2d step, we combine URL statistical functions, webpage code features, website text capabilities and the short classification end result of deep studying into multi-dimensional features. The technique can lessen the detection time for putting a threshold.
Introduction
I. INTRODUCTION
Phishing is a web theft that steals consumer's personal statistics and credentials. it is a type of fraud in which the attacker profits full get admission to to others personal statistics. To deal with those troubles, we propose a multidimensional function phishing detection technique primarily based on a quick detection approach through the usage of deep mastering (MFPD). In step one, character collection features of the given URL are extracted and used for brief category with the aid of deep learning. in particular, the CNN (convolutional neural network) is used to extract local correlation functions through a convolutional layer. In a URL, each character may be related to close by characters. Generally, speak me, a phishing internet site is likely to imitate the URL of a valid internet site through converting or including a few characters. this will reason the sequential dependency of the phishing URL to be specific from the phishing URL. The LSTM network can efficaciously learn the sequential dependency from man or woman sequences. Therefore, the LSTM (lengthy short-term reminiscence) community is employed to seize context semantic and dependency features of URL man or woman sequences, and at subsequently tender- max is used to classify the extracted functions. We call the first step CNN-LSTM. From a complete attitude, inside the 2d step, we integrate URL statistical capabilities, webpage code capabilities, webpage textual content capabilities and the class result of deep learning into multidimensional functions, which can be then classified by means of XGBoost. although the multidimensional function detection method has higher accuracy, it requires extracting functions from exceptional aspects, ensuing in longer detection time. In comparison, the method for the URL person sequences handiest wishes to technique the URL, and the detection time is short. To stability the contradiction among detection time and accuracy, we improve the output judgment circumstance of the SoftMax classifier within the deep studying method by using putting a thresh vintage to lessen the detection time. If the end result of deep getting to know isn't always less than the desired threshold, the detection end result is without delay output; otherwise, visit the 2d step of detection.
II. LITERATURE
Review Phishers typically distort the hostname element and the direction component from the URL of the goal webpage to generate the phishing URL, and consequently, features can be extracted primarily based on URL statistical regulations [2], [3] or surely based totally at the URL strings [4]. Researchers have proposed many unique functions of different types of phishing websites from different perspectives. Zouina et al. [1] proposed a lightweight phishing internet site detection technique that used only six URL capabilities, specifically, the URL length, the wide variety of hyphens, the range of dots, the range of numeric characters plus a discrete variable that corresponds to the presence of an IP deal with within the URL, and finally, the similarity index. The features extracted are completely based on URLs, and because of their low features, the detection velocity is speedy. however, the amount of experimental information was exceedingly small. Le et al. [4] proposed a method of extracting lexical features from URL strings and the usage of AROW (Adaptive Regularization of Weights) to discover phishing web sites. This method overcomes the noise of the schooling records even as making sure detection accuracy.
Verma et al. [5] innovatively proposed KS (Kolmogorov- Smironov) distance,(Kullback-Leibler Divergence) distance, Euclidean distance, man or woman frequency and enhancing with the target URL based totally on the deference in characters among the phishing URL and well-known English, combining these capabilities with URL functions. Phishing detection mechanisms based totally at the URL feature simplest need to process the URL, and as a result, the detection pace is speedy. but, the URL data on my own does now not completely constitute the traits of phishing websites. modern-day studies usually extract HTML and textual content features of webpages [6], 1/3-birthday party website capabilities [7], etc., and integrate these features with URL functions to expand multidimensional functions.
III. RELATED WORK
We advocate a multidimensional characteristic phishing detection approach based totally on a speedy detection technique by the use of deep gaining knowledge of (MFPD). within the first step, character collection features of the given URL are extracted and used for brief category with the aid of deep getting to know. specially, the CNN (convolutional neural network) is used to extract nearby correlation functions via a convolutional layer. In a URL, each individual may be related to close by characters. usually talking, a phishing internet site is probably to mimic the URL of a legitimate website through changing or adding some characters. this will purpose the sequential dependency of the phishing URL to be different from the phishing URL. The LSTM community can successfully analyse the sequential dependency from individual sequences. consequently, the LSTM (lengthy quick term reminiscence) network is hired to seize context semantic and dependency features of URL individual sequences, and at finally SoftMax is used to classify the extracted capabilities. We call step one CNN-LSTM. From a comprehensive angle, in the 2d step, we combine URL statistical capabilities, web site code functions, webpage textual content capabilities and the class end result of deep gaining knowledge of into multidimensional capabilities, that are then classified by means of XGBoost. although the multidimensional characteristic detection approach has better accuracy, it calls for extracting capabilities from different factors, ensuing in longer detection time. In evaluation, the technique for the URL person sequences simplest needs to procedure the URL, and the detection time is short. To balance the contradiction between detection time and accuracy, we improve the output judgment situation of the SoftMax classifier within the deep learning procedure by setting a threshold to
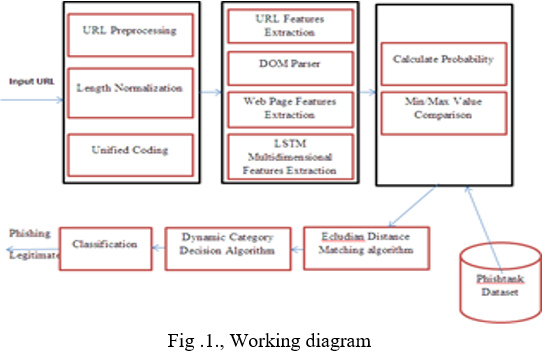
reduce the detection time. If the end result of deep studying is not less than the specified threshold, the detection end result is immediately output; otherwise, go to the second one step of detection. particularly, our key contributions on this paintings are indexed as follows: With the phishing website detection as a -category processing model, we officially define the problem of phishing detection and deliver a particular formal description of the MFPD method. We build a real dataset through crawling a total of one 021 758 phishing URLs as nice samples from phishtank.com, and a total of 989 021 legitimate URLs as terrible samples from dmoztools.net. The process of phishing internet site detection the usage of MFPD is defined, and an intensive experiment on the dataset we built is performed. The consequences show that our proposed approach well-known shows true performance in terms of accuracy, false superb fee, and velocity. A dynamic class decision algorithm (DCDA) is proposed. by revising the output judgment conditions of the SoftMax classifier inside the deep learning seasoned cess and setting a threshold, the detection time can be decreased the proposed method, a most distance matrix is created to measure the distances. as a way to choose the first-rate records, the delivered approach has used weighting of statistics as proven in the example of this section. inside the approach algorithm cycle, whilst we're going to place a report in a cluster, we supply it a weight. by presuming small coefficients, we try to decrease the distances among primary phishing and not phishing ideas.
Conclusion
Our proposed MFPD technique is regular with this concept. Below the control of a dynamic category choice algorithm, the URL individual collection without phishing previous knowledge ensures the detection pace, and the multidimensional characteristic detection guarantees the detection accuracy. We conduct a chain of experiments on a dataset containing tens of millions of phishing and legitimate URLs.
References
[1] T. P. Bohlin, Practical grey-box process identification: theory and applications, Springer Science Business Media, 2016. [2] J. Cao, D. Dong, B. Mao and T. Wang, \\Phishing detection method based on URL features,\" J. Southeast Univ.- Engl. Ed., vol. 29, no. 2, pp. 134-138, Jun. 2013. [3] S. C. Jeeva and E. B. Raj Singh, \\Phishing URL detection-based feature selection to classers,\" Int. J. Electron. Secure. Digit. Forensics, vol. 9, no. 2, pp. 116-131, Jan. 2017. [4] A. Le, A. Markopoulou and M. Faloutsos, \\PhishDef: URL names say it all,\" in Proc. IEEE Int. Conf. Comput. Commun. (INFOCOM), Sep. 2010, pp. 191-195. [5] R. Verma and K. Dyer, \\On the character of phishing URLs: Accurate and robust statistically learning classers,\" in Proc. 5th ACM Conf. Data Appl. Secure. Priv. (ACM CODASPY), Mar. 2015, pp. 111-122. [6] Y. Li, S. Chu and R. Xiao, \\A pharming attack hybrid detection model based on IP addresses and web content,\" Optik, vol. 126, no. 2, pp. 234-239, Nov. 2014. [7] G. Xiang G and J. Hong, \\A hybrid phish detection approach by identity discovery and keywords retrieval,\" in Proc. Int. Conf. World Wide Web (WWW 2009), Oct. 2009, pp. 571- 580
Copyright
Copyright © 2022 Khan Danish Musa, Shaikh Moaaz Ahmed, Anwar Ismail Khan. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET40119
Publish Date : 2022-01-28
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online