

Ijraset Journal For Research in Applied Science and Engineering Technology
Pneumonia Detection in X-Ray Chest Images Based on CNN and Data Augmentation
Authors: Pranathi Patel, Hiriyanna GS
DOI Link: https://doi.org/10.22214/ijraset.2022.46031
Certificate: View Certificate
Abstract
Pneumonia is a life-threatening infectious disease affecting one or both lungs in humans commonly caused by bacteria called Streptococcus pneumonia. One in three deaths in India is caused due to pneumonia as reported by World Health Organization (WHO). Chest X- Rays which are used to diagnose pneumonia need expert radiotherapists for evaluation. Thus, developing an automatic system for detecting pneumonia would be beneficial for treating the disease without any delay particularly in remote areas. Due to the success of deep learning algorithms in analyzing medical images, Convolutional Neural Networks (CNNs) have gained much attention for disease classification. In addition, features learned by pre-trained CNN models on large-scale datasets are much useful in image classification tasks. In this work, appraise the functionality of pre-trained CNN models utilized as feature- extractors followed by different classifiers for the classification of abnormal and normal chest X-Rays. We analytically determine the optimal CNN model for the purpose. Statistical results obtained demonstrates that pretrained CNN models employed along with supervised classifier algorithms can be very beneficial in analyzing chest X-ray images, specifically to detect Pneumonia.
Introduction
ACKNOWLEDGEMENT
On the very outset of this report on “Pneumonia detection in X-ray chest images based on CNN and data augmentation”, I would like to extend our sincere & heartfelt obligation towards all the persons who have helped me in this endeavor. I am grateful to my institution J N N College of Engineering and the Department of Computer Science and Engineering for imparting us the knowledge with which I can do my best.
I would like to thank my beloved guide Mr. Hiriyanna G. S, Asst. Professor, Dept. of Computer Science and Engineering. I am highly indebted to them for their guidance and constant supervision as well as for providing necessary information regarding the project & also for their support in completing the project.
I would also like to thank my beloved coordinator Dr. Chetan K. R, Professor, Dept. of Computer Science and Engineering. I am highly indebted to them for their coordination as well as for providing necessary information regarding the project.
I would also like to express my gratitude to Dr. Poornima K. M, Professor and Head of the Department, Computer Science and Engineering and Dr. K Nagendra Prasad, Principal, J N N College of Engineering, Shivamogga for all their support and encouragement. I am thankful to and fortunate enough to get constant encouragement, support and guidance from all Teaching staffs of the Department of Computer Science and Engineering which helped me in successfully completing my project. Also, I would like to extend my sincere regards to all the non-teaching staff of Department of Computer Science and Engineering for their timely support.
Thanking you all,
Pranathi Patel H E 4JN20SCS04
I. INTRODUCTION
Pneumonia causes inflammation of lungs especially air sacs which may filled with fluid or pus causing cough and difficulty in breathing. More than 150 million people especially children below 5 years get infected with pneumonia yearly world-wide. The mortality rate due to pneumonia is specifically higher in children below years in developing nations. This mandates the detection of pneumonia on time so that proper treatment can be provided to the person. The most practiced method world-wide to detect pneumonia is using chest X- ray images. To detect pneumonia, careful examination of chest Xray images is required which in turn necessitate experienced and knowledgeable radiologist/ experts. This makes the process of pneumonia detection a challenging task. Moreover, it is a time consuming task and a little error can have fatal consequences.
A. Pneumonia Detection
Due to the tedious nature of X-ray image analysis task, many computer algorithms and computer aided diagnostic tools have been proposed by researchers in order to analyze X- ray images; however, they were not proved very significant in assisting experts in making decisions. Recently, handcrafted techniques and deep learning techniques are being applied successfully by researchers in the area of medical imaging to analyze and classify medical images for detection of various diseases like skin cancer, breast cancer, tuberculosis, brain tumor etc. This motivated us to propose a deep convolution neural network (CNN) that helps to extract features from chest X-ray image. The extracted features are further used.
- Deep Learning
Deep learning (also known as deep structured learning) is part of a broader family of machine learning methods based on artificial neural networks with representation learning. Learning can be supervised, semi-supervised or unsupervised.
Deep-learning architectures such as deep neural networks, deep belief networks, deep reinforcement learning, recurrent neural networks and convolutional neural networks have been applied to elds including computer vision, speech recognition, natural language processing, machine translation, bioinformatics, drug design, medical image analysis, climate science, material inspection and board game programs, where they have produced results comparable to and in some cases surpassing human expert performance.
Artificial neural networks (ANNs) were inspired by information processing and distributed communication nodes in biological systems. ANNs have various differences from biological brains. Specifically, artificial neural networks tend to be static and symbolic, while the biological brain of most living organisms is dynamic (plastic) and analogue.
The adjective "deep" in deep learning refers to the use of multiple layers in the network. Early work showed that a linear perceptron cannot be a universal classifier, but that a network with a nonpolynomial activation function with one hidden layer of unbounded width can. Deep learning is a modern variation which is concerned with an unbounded number of layers of bounded size, which permits practical application and optimized implementation, while retaining theoretical universality under mild conditions. In deep learning the layers are also permitted to be heterogeneous and to deviate widely from biologically informed connectionist models, for the sake of efficiency, trainability and understandability, whence the "structured" part.
Deep learning neural networks, or artificial neural networks, attempts to mimic the human brain through a combination of data inputs, weights, and bias. These elements work together to accurately recognize, classify, and describe objects within the data.
Deep neural networks consist of multiple layers of interconnected nodes, each building upon the previous layer to re ne and optimize the prediction or categorization. This progression of computations through the network is called forward propagation. The input and output layers of a deep neural network are called visible layers. The input layer is where the deep learning model ingests the data for processing, and the output layer is where the nal prediction or classification is made.
Another process called backpropagation uses algorithms, like gradient descent, to calculate errors in predictions and then adjusts the weights and biases of the function by moving backwards through the layers in an e ort to train the model. Together, forward propagation and backpropagation allow a neural network to make predictions and correct for any errors accordingly. Over time, the algorithm becomes gradually more accurate.
The above describes the simplest type of deep neural network in the simplest terms. However, deep learning algorithms are incredibly complex, and there are di erent types of neural networks to address specific problems or datasets. For example, Convolutional neural networks (CNNs), used primarily in computer vision and image classification applications, can detect features and patterns within an image, enabling tasks, like object detection or recognition. In 2015, a CNN bested a human in an object recognition challenge for the first time. Recurrent neural network (RNNs) are typically used in natural language and speech recognition applications as it leverages sequential or times series data.
Deep learning may be used in many fields like,
a. Robotics: Many of the recent developments in robotics have been driven by advances in AI and deep learning. For example, AI enables robots to sense and respond to their environment. This capability increases the range of functions they can perform, from navigating their way around warehouse floors to sorting and handling objects that are uneven, fragile, or jumbled together. Something as simple as picking up a strawberry is an easy task for humans, but it has been remarkably difficult for robots to perform. As AI progresses, that progress will enhance the capabilities of robots. Developments in AI mean we can expect the robots of the future to increasingly be used as human assistants. They will not only be used to understand and answer questions, as some are used today. They will also be able to act on voice commands and gestures, even anticipate a worker’s next move. Today, collaborative robots already work alongside humans, with humans and robots each performing separate tasks that are best suited to their strengths.
b. Agriculture: AI has the potential to revolutionize farming. Today, deep learning enables farmers to deploy equipment that can see and differentiate between crop plants and weeds. This capability allows weeding machines to selectively spray herbicides on weeds and leave other plants untouched. Farming machines that use deep learning–enabled computer vision can even optimize individual plants in a field by selectively spraying herbicides, fertilizers, fungicides, insecticides, and biologicals. In addition to reducing herbicide use and improving farm output, deep learning can be further extended to other farming operations such as applying fertilizer, performing irrigation, and harvesting.
c. Medical Imaging and Healthcare: Deep learning has been particularly effective in medical imaging, due to the availability of high-quality data and the ability of convolutional neural networks to classify images. For example, deep learning can be as effective as a dermatologist in classifying skin cancers, if not more so. Several vendors have already received FDA approval for deep learning algorithms for diagnostic purposes, including image analysis for oncology and retina diseases. Deep learning is also making significant inroads into improving healthcare quality by predicting medical events from electronic health record data.
2. CNN
CNN’s were first developed and used around the 1980s. The most that a CNN could do at that time was recognize handwritten digits. It was mostly used in the postal sectors to read zip codes, pin codes, etc. The important thing to remember about any deep learning model is that it requires a large amount of data to train and also requires a lot of computing resources. This was a major drawback for CNNs at that period and hence CNNs were only limited to the postal sectors and it failed to enter the world of machine learning. In deep learning, a convolutional neural network (CNN/ConvNet) is a class of deep neural networks, most commonly applied to analyze visual imagery. Now when we think of a neural network we think about matrix multiplications but that is not the case with ConvNet.
It uses a special technique called Convolution. Now in mathematics convolution is a mathematical operation on two functions that produces a third function that expresses how the shape of one is modified by the other.
A Convolutional Neural Network, also known as CNN or ConvNet, is a class of neural networks that specializes in processing data that has a grid-like topology, such as an image. A digital image is a binary representation of visual data. It contains a series of pixels arranged in a grid-like fashion that contains pixel values to denote how bright and what color each pixel should be.
The human brain processes a huge amount of information the second we see an image. Each neuron works in its own receptive field and is connected to other neurons in a way that they cover the entire visual field. Just as each neuron responds to stimuli only in the restricted region of the visual field called the receptive field in the biological vision system, each neuron in a CNN processes data only in its receptive field as well. The layers are arranged in such a way so that they detect simpler patterns first (lines, curves, etc.) and more complex patterns (faces, objects, etc.) further along. By using a CNN, one can enable sight to computers.
Convolutional neural networks are composed of multiple layers of artificial neurons. Artificial neurons, a rough imitation of their biological counterparts, are mathematical functions that calculate the weighted sum of multiple inputs and outputs an activation value. When you input an image in a ConvNet, each layer generates several activation functions that are passed on to the next layer.
Convolutional Neural Network(CNN) consists of 4 parts, convolutional layer, activation layer, polling layer, and fully connected layer.
Firstly, the convolutional layer is using a filter(convolutional kernel) to scan the original image, compute the product between the original pixel and the weight on the filter. Then, generating the feature map by average the sum of the product.
Secondly, the activation layer plays the role of adding nonlinear factors, which activate the whole feature map through an activation function, such as ReLU, Sigmoid, and Tanh. When Convolutional Neural Network classifies the processed output vector of the original image. These vectors usually have a very high dimension, which could not separate by a line. Thus, the nonlinearity quality is the necessity.
Also, the function of the pooling layer, also called the downsampling layer, is sampling from the feature map and reducing the computation burden, which picks out the representative attribute of the feature map, such as the maximum value or the average value. “Image-based convolutional networks typically use a pooling layer which summarizes the activations of many adjacent filters with a single response. Such pooling layers may summarize the activations of groups of units with a function such as their maximum, mean, or L2 norm. These pooling layers help the network be robust to small translations of the input.”
Finally, a fully connected layer is computing the output by weighting the attribute vectors generated by hidden layers via the vector product and generating the final classification result.
B. Literature Survey
- Pneumonia Detection with Deep Convolutional Architecture
Methodology: Deep residual network which was introduced by Microsoft researchers in ILSVRC 2015 and mask-RCNN by Facebook AI researchers. Those networks are used to develop CAD for pneumonia detection with thorax x-ray images. We also represent, compare and evaluate the performance of two architectures with simple evaluation, yet respectable.
Kaggle RSNA Pneumonia Detection Challenge dataset from the Radiological Society of North America. The dataset consists of 26.684 data, which are in DICOM format, divided into 21.684 training data, 2.000 validation data, 3.000 testing data. The dataset is provided as a set of patient Ids, bounding boxes, and target values. In addition, The dataset is grouped into two groups, pneumonia and non-pneumonia. However, the non-pneumonia groups contain another two groups which are normal and non pneumonia abnormal lungs. The residual mapping can be used when the input and output are in the same dimension. Batch normalization is used right after each convolution and activation. We use Adam optimizer with 32 mini batches. Cosine annealing is used for learning rate to optimize the training process. For the loss function, we combine IoU and binary cross entropy.
Mask Regional CNN (mask-RCNN) is the further development of Faster Regional CNN algorithm. This algorithm usually used in object localization and recognition in an image by combining object detection and semantic segmentation. The objective of object detection is to localize each object on the image using a bounding box. Meanwhile, semantic segmentation goal is to classify each pixel into a xed set of categories using object delineation.
Contributions: Each of trained architecture also shows the contrast difference between sensitivity and specificity. The difference may caused by the unbalanced data between pneumonia and non-pneumonia classes which can cause the architecture tend to missed classify the pneumonia class. The false classification of pneumonia class is not desired for CAD since it can cause the patients tend to have normal lungs or other abnormalities.
Advantages: In the pneumonia detection, residual network shows better performance than mask-RCNN. It may caused by the poor performance of mask-RCNN’s RPN algorithm to find which of the proposed RoIs have an object since the pneumonia features are difficult to find comparing with widely used object detection dataset such as COCO.
Limitations: The two networks also show the contrast gap between sensitivity and spesi city which caused by unbalance dataset. Using more complex network structure and augmenting the unbalance dataset may also possible in the future so that we can get the best architecture for pneumonia CAD system.
2. Investigation of the performance of Machine Learning Classifiers for Pneumonia Detection in Chest X-ray Images
Methodology: The system is composed of several steps, including the data collection and pre- processing description, building the classification models and extracting the required features. These steps can be divided into four phases: Data Set, data pre-processing, building and validating classification models, and feature extraction. The chest X-ray image dataset. It was the Chest X-ray Images, including normal chest X-Ray and Pneumonia chest X-Ray. Here, we have taken 5,856 sample images of the dataset to use later on for recognition and classification of Pneumonia. 1,583 of which are normal XRay lung images, and 4,273 of which are X-Ray lung images with Pneumonia. These data set was used for training in Deep Learning method and testing data using Pandas for predicting Pneumonia. The X-ray images were divided into train, test, and validation groups. 80% of data was used for training, 10% used for testing, and 10% used for validations. The data set was randomized in advance to avoid potential bias. Trained the dataset using Keras on the top of Tensor-Flow. There were various Machine Learning models used for classifying Pneumonia X-Ray images from normal ones. The module aims to provide a binary classification of presence absence of Pneumonia within a chest x-ray and to select The Machine Learning algorithms are applied according to the features selected and extracted manually, while the Deep neural network learns to extract the most representative or complex features and patterns on its own according to the input. Moving from Machine Learning to Deep Learning. CNN was one of the best models for image recognition and classification. Therefore, the following sections were focusing on describing the CNN model that was used for this data set. The models that were implemented for comparison were Random Forest, Xgboost, K-nearest neighbor, Decision Tree, Gradient Boost, Adaboost, and Convolutional Neural Network (CNN).
Contributions: The primary aim of this study was to examine and test the performance of Machine Learning techniques and Convolutional Neural Network (CNN) for the classi cation of Pneumonia, which is based on Chest X-ray Images to achieve high accuracy. Another aim is to provide radiologists and medical experts with a tool that is a lower cost. This tool could help them read the X-ray images and to create a basis for a model to analyze more complex data like CT images.
Advantages: In this work, we have oered a model for detecting and classifying Pneumonia from Chest X-ray Images using Machine Learning methods based on Convolutional Neural Network (CNN).
In particular, comparing all seven models based on a test accuracy score, F-score, and ROC curve, it appears that CNN outperforms all other models by a small margin with a test accuracy score of 98.46%. Random forest performs surprisingly well with a test accuracy score of 97.61%. It should note that the CNN model was run with only 100 epochs due to its long-running and waiting time. The result of our model indicates that our model outperforms other methods, which use no extra training data on chest radiography and shows that image training may be sufficient for general medical image recognition tasks. Moreover, the cooperation between a Machine Learning-based medical system and the detection of Pneumonia will improve the outcomes and bring benefits to clinicians and their patients.
Limitations: Furthermore, this study can be applied in the diagnosis of some diseases such as COVID-19. As future work, we hope to build a larger database so we can apply more Deep Learning techniques to train and test the system to predict better results.
3. An Adaptive Data Processing Framework for Cost Effective COVID-19 and Pneumonia Detection
Methodology: The complex nature of COVID-19 and pneumonia radiological features can be described based on the formation of GGO and consolidations, which are inconsistent in sizes and locations within the lung regions. Therefore, the probability of a positive true label CT 2D axial slice with absence of pneumonia findings can be high when 3D CT data are decomposed in a 2D system. This scenario is more commonly happened among the early-course infected lung, in which the pneumonia in ltration is barely manifested and hardly visible. Hence, such a data-space condition is defined as ambiguously labeled samples (AL-CT) in this study. It is hypothesized that the utility of AL-CT slices for model training can complicate the learning process and consequently lead to poor performances as the AL-CT slices share similar spatial representation with the normal lung CT slices.
Contributions: Cost-effective data processing framework for COVID-19 and pneumonia detection to effectively distinguish COVID-19 and other pneumonia infected lungs from healthy lungs. Community-acquired pneumonia (CAP) samples and clinical confirmed COVID19 samples are considered as a single class label in this study due to the invariant radiographic features of GGO that are shared between COVID-19 and CAP CT samples. At the present time, more discriminative multi-class classification task requires further scientific investigation due to the complicated radiography characteristics of COVID-19 and the continuous emergence of new COVID-19 variants.
Advantages: It is worth mentioning that the data processing framework can be extended easily to different medical ML/DL applications, especially in attempts of utilizing 3D data in a 2D-based solution. That is, it can be referenced as data pre-processing procedures for relatable applications to improve data diversity and quality for more efficient neural network development in a cost-effective setting. Limitations: Training a 3DCNN model is much complex and exhausting compared to a 2DCNN model. Moreover, 3D training samples with good feature descriptions are exceptionally scarce.
4. Analysis of COVID-19 and Pneumonia Detection in Chest X-Ray Images using Deep Learning
Methodology: The on-going COVID-19 outbreak made healthcare systems across the globe to be in the edge of the battle. Recent stats indicate that more than 140+ million confirmed cases are diagnosed globally as of April 2021. The cases are increasing day by day. The early and auto diagnosis helps people to be precautious. The proposed work aims to detect COVID-19 patients and Pneumonia patients from X- Rays which is one of the medical imaging modes to analyze the health of patient’s lung inflammation. The suitable Convolutional Neural Network Model is selected for the identified dataset. The model detects COVID-19 patients and Pneumonia patients on the real-world dataset of lung X- Ray images. Images are pre-processed and trained for various classifications like Normal, COVID-19 and Pneumonia. After pre-processing, the detection of the disease is done by selecting the appropriate features from the images in each of the datasets. The result indicates that accuracy of detection of COVID vs Normal and COVID vs Pneumonia. Among those two, COVID vs Normal is with better accuracy than COVID vs Pneumonia. This method detects not only COVID or Pneumonia, but also the subtypes of Pneumonia as bacterial or Viral Pneumonia with 80% and 91.46% respectively. The detection of COVID, Bacterial Pneumonia and Viral Pneumon+ia using the proposed model helps in rapid diagnosis and to distinguish COVID from Pneumonia and its types which facilitates to use appropriate and fast solutions.
Contributions: The work aims to detect COVID-19 and Pneumonia patients using deep learning techniques as Normal, Infected, Pneumonia patients. Transfer learning techniques can be used for COVID-19 detection.
Advantages: CNN is the model used to detect Normal and Infected patients like COVID-19 Infected lungs, Pneumonia Infected lungs. The accuracy of detection of COVID -19 is 95 % which a plus about this model and the current requirement of this pandemic with limited cost and computations. This model is more appropriate for medical practitioners, researchers etc.
Limitations: With ensemble of different models to improve the accuracy of detection of different classes but with the cost of time and computation.
5. Pneumonia detection in X-ray chest images based on convolutional neural networks and data augmentation methods
Methodology: The dataset of 5863 analyzed X-ray images comes from Kaggle.com web service [Attribution 4.0 International (CC BY 4.0)], which unites the community of artificial intelligence enthusiasts as well as holds machine learning competitions. These images are of pediatric patients between one and years old from Guangzhou Women and Children’s Medical Centre, Guangzhou. Images of different resolutions, with the majority of approximately 1500 x 1000 pixels, are given in JPEG format. All of the images are in grayscale at 8 bpp. According to Kaggle’s information all of the radiographs have been initially screened for quality by removing unusable scans and classified to one of the categories (pneumonia/normal) by two experienced radiologists and only then cleared for training neural networks. The downloaded images were sorted into two categories as the contest announced on Kaggle.com required differentiation of healthy and infected cases.
Contributions: The purpose of this study is to apply CNN into medical imaging environment to ascertain how accurate and sensitive these methods prove to be in recognizing different types of pneumonia (viral or bacterial). Advantages: Standard CNN is able to provide quite accurate classification (85%) of X-ray pneumonia images solving true three-class problem (distinguishing between viral, bacterial and control cases).
Limitations: Implemented in healthcare system to supplement the diagnosis of X-ray pneumonia images of pediatric patients.
6. Convolutional Neural Network for Automatic Pneumonia Detection in Chest Radiography
Methodology: The training dataset was augmented to develop the dataset to avoid over fitting. The augmentation strategy consists of resizing (cropping), ip, and rotation. The training dataset is divided into training datasets and validation randomly. The validation dataset is used to provide a model evaluation that does not favor the training dataset. The resulting model will be used for the testing process (prediction). Before the prediction process is carried out, the data testing is pre processed. Pre- processing of the testing dataset consists of the centered crop, ip, and rotation. The dataset used in this paper uses 5,856 X-ray radiographic images of Kaggle in JPEG format with dimensions of 10241024 pixels and grouped into two classes: NORMAL and PNEUMONIA, which is stored into a different folder. The dataset is divided into training and testing data with a composition of 90% and 10% randomly. Composition of training and testing dataset, 10% of training dataset are randomly selected as validation data to provide the skills of the model sought by comparing and selecting suitable models. The convolutional layer is the core building of CNN. Image input passes through a convolutional layer which consists of a set of filters with certain parameters. The filter consists of a height and weight that is smaller than the input size. Filters are built in 3x3 size to ensure a detailed feature reading. Each filter will calculate the ReLu activation value and be pooled to summarize the convolution result information. The output from the convolution process is used as input in the classification process by first flattening.
Contributions: Different deep convolution neural network architectures with an augmentation strategy to classify the pneumonia detection from the chest X-ray images. We use three convolution layers and three classification layers (fully connected)
Advantages: CNN’s architecture with an augmentation strategy to detect the pneumonia disease using a chest X-ray image. The experiment result shows that the augmentation strategy on the proposed CNN’s architecture achieves better results than without augmentation.
Limitations: Prediction results with the augmentation strategy and without the augmentation strategy shows that the proposed CNN’s architecture can train small datasets.
7. A Pneumonia Detection Method Based on Improved Convolutional Neural Network
Methodology: For traditional machine learning and image processing, it is di cult to extract features, the quality of feature extraction will directly affect the classification accuracy, another problem is that the large difference between the original datasets and the target datasets in the transfer learning, lead to unsatisfactory results. In addition, the original convolution model network is too shallow, recognition rate is not high; Therefore, this paper presents an improved convolutional neural network method for pneumonia detection based on deep learning model. First, the image size in the original datasets are xed and the appropriate batch size are used as the input of the network, Then the convolution layers and pooling layers are added on the basis of lenet-5 model, Secondly, a feature integration layer is added to construct an optimal model for accurate classification. The proposed method not only avoids the complex feature extraction process but also has fewer parameters than other classical convolutional neural networks. By using two public datasets, the second which provided by the RSNA joint Kaggle medical image pneumonia recognition competition, after a series of experiments of single dataset and fusion of two datasets, the final accuracy rate reached 98.83% and 98.44% respectively, the test accuracy also reached 97.26% and 91.41% respectively. Compared with existing transfer learning, GoogleNet Inception V3+Data Augmentation(GIV+DA), GIV3+RF models.
Contributions: It is able to assist doctors taking appropriate medicine to shorten the cure time of pneumonia and improve the cure rate of pneumonia.
Advantages: This paper first introduces the models and results proposed by some previous researchers, and brie y introduces some basic knowledge of convolutional neural networks Then, on the basis of relevant research, a convolutional neural network based on improved Lenet was proposed to realize the detection of pneumonia images, the model in this paper is based on the original classical lenet-5 model by adding convolutional layer and pooling layer as well as feature integration layer, the obtained features were further highly abstracted, and finally excellent results were obtained on two public datasets, not only on the training set but also on the test set, which shows the proposed model has good robustness. In the following research work, further studies will be conducted on the detection of pneumonia types in our team, which will be detected according to types. at the same time, using convolutional neural network segment the lung area and locate the lesion area. Using CapsNet reconstruct the blurred images of lesion area (CapsNet has been proven that reconstructed images have very useful functions such as smoothing the noise) then, using appropriate neural networks for detection.
Limitations: still seems to be a little inadequate, the recognition rate is not high, prone to over- fitting series of problems;
8. Feature Extraction and Classification of Chest X-Ray Images Using CNN to Detect Pneumonia
Methodology: Here, we present two CNN architectures- one with a dropout layer and another without a dropout layer. Both CNN consist of convolution layer, max pooling and a classification layer. A series of convolution and max-pooling layers act as a feature extractor that is divided into two parts. The first part consists of two Convolution layers with 32 - 32 units each along with a max-pooling layer of size 3 3 and a Relu activator. While the other also has two Convolution layers but with 64 and 128 units respectively along with a max-pooling layer of size 2 2 and a Relu activator. Relu is a popular activation function which is generally used in neural networks especially in CNNs. Relu layer introduces nonlinearity to the model. Features extracted from the feature extractor part of the CNN are given as input to the dense layer which classifies the image. Before feeding the extracted features to the dense layer, a flatten layer a used. As the dense layer takes 1-Dimensional input, hence, flatten layer flattens the feature data and gives a 1- Dimensional output which is fed to the dense layer. While training a CNN it might be possible that output through a certain layer is more dependent on a few selected neural units. To reduce this dependency and prevent over fitting, the concept of dropout is introduced. During training, in each epoch, a neuron is momentarily dropped with a dropout probability p. Due to this, all the inputs and outputs to this neuron become disabled in the current epoch which results in some loss of data enhancing regularization in the model so that at times it would predict with much higher accuracy. The dropped-out neurons are resampled with probability p at every training step, so a dropped-out neuron at one step may become active in the next step. A dropout probability of 0.5, corresponds to 50% of the neurons being dropped out. In the proposed CNN architecture with dropout layer, we apply dropout at two places. First, it is applied at the feature extractor part i.e. after convolution and max-pool layers. As, the convolutional layers have not too many parameters, hence over fitting is not an issue in this case. Hence, here we take a low drop probability of 0.2. Second, it is used at dense layer. Dropout in the lower layers helps because it provides noisy inputs for the higher fully connected layers which prevents them from over fitting. At dense layers a drop probability of usually 0.5 is used as it has been observed that dense probability of 0.5 gives best regularization in most of the cases. We also use a drop probability of 0.5 here. The model summary of CNN with and without dropout. The architecture of CNN with dropout. The dataset employed in this work is picked from Kaggle. It consists of 5863 images of chest X-ray. The dataset is split into three portions namely training dataset, validation dataset and testing dataset. Initially, the images in the dataset are of varying sizes. However, all the input images given to CNN should be of same size. To solve this problem, all the images in the dataset are resized to 64 64. To avoid over fitting and to enhance the generalization capabilities of the proposed CNN architectures, various in-place data augmentation techniques such as rescaling, flipping etc. are used in this paper. Use of this type of data augmentation ensures that our CNN see new variations of data at each and every epoch during training.
Contributions: CNN architecture from scratch instead of using transfer learning. In this paper, we propose various CNN architectures and these are trained on chest X-ray image dataset
Advantages: we propose two CNN architectures that are designed from scratch to detect pneumonia from images of chest X-ray. To avoid over fitting, data augmentation techniques are used. The result of experiments performed to assess the performance of the proposed architectures and the effect of data augmentation on the performance of the proposed CNN’s show that CNN with dropout trained on augmented data outperforms the other models.
Limitations: we plan to use different optimizers and other data augmentation techniques in an attempt to further improve the classification accuracy of the proposed CNN architecture with data augmentation. We also plan to use early stopping and batch normalization instead of dropout layer to see their effect in avoiding over fitting.
9. Pneumonia Detection Using CNN based Feature Extraction
Methodology: Pneumonia is a life-threatening infectious disease affecting one or both lungs in humans commonly caused by bacteria called Streptococcus pneumoniae. One in three deaths in India is caused due to pneumonia as reported by World Health Organization (WHO). Chest X-Rays which are used to diagnose pneumonia need expert radiotherapists for evaluation. Thus, developing an automatic system for detecting pneumonia would be beneficial for treating the disease without any delay particularly in remote areas. Due to the success of deep learning algorithms in analyzing medical images, Convolutional Neural Networks (CNNs) have gained much attention for disease classification. In addition, features learned by pre-trained CNN models on large-scale datasets are much useful in image classi cation tasks. In this work, we appraise the functionality of pre-trained CNN models utilized as feature- extractors followed by different classifiers for the classification of abnormal and normal chest X-Rays. We analytically determine the optimal CNN model for the purpose. Statistical results obtained demonstrates that pretrained CNN models employed along with supervised classifier algorithms can be very beneficial in analyzing chest X-ray images, specifically to detect Pneumonia.
Contributions: The classification used with high-rich extracted features exhibit improved performance in classifying images .
Advantages: Presence of expert radiologists is the topmost necessity to properly diagnose any kind of thoracic disease. This paper primarily aims to improve the medical adeptness in areas where the availability of radiotherapists is still limited. Our study facilitate the early diagnosis of Pneumonia to prevent adverse consequences (including death) in such remote areas. So far, not much work has been contributed to specifically to detect Pneumonia from the mentioned dataset. The development of algorithms in this domain can be highly beneficial for providing better health-care services. In this regard, we have proposed a model architecture for detecting Pneumonia from frontal chest X-ray images with the utilization of Densenet as feature-extractors and SVM as classifier. We observed the performance of various pretrained CNN models along with distinct classifiers and then on the basis of statistical results selected DenseNet-169.
Limitations: Although the results were overwhelming, there were still some limitations in our model which we believe are vital to keep in consideration. The first biggest limitation is that there is no history of the associated patient considered in our evaluation model. Secondly, only frontal chest X-rays were used but it has been shown that lateral view chest X-rays are also helpful in diagnosis. Thirdly, since the model exercises a lot of convolutional layers, the model need very high computational power otherwise it’ll eat up a lot of time in computations.
10. Comparative Experiment of Convolutional Neural Network (CNN) Models Based on Pneumonia X-ray Images Detection
Methodology: This paper aims to reveal the relationship between the Convolutional Neural Network (CNN) model’s behavior and the depth of the model. Due to the worldwide coronavirus pandemic, the training dataset is the chest x-ray images of the lungs, which are infected by pneumonia. The contrastive study incorporates three models: a classic model, which is the imitation of LeNet5, VGG16, and Residual Network 50. This research is based on pneumonia detection, and it can give people a deeper understanding of CNN’s mechanism rather than only focusing on the result of di erent models. The explainable analysis visualizes the loss value and accuracy curves, CAM & Grad-CAM images, and activation maps. It leads to three conclusions: rst, as the depth of the model increases, the average loss values of a given epoch will decrease; secondly, the accuracy will increase with the increasing depth; third, the extracted attributes become more abstract in the deeper hidden layers.
Contributions: CNN is the most effective means, nowadays, to deal with various pictorial tasks. This work shows the basic idea and functions of different models. We hope other people can gain enlightenment and do the improvement based on this work.
Advantages: Unlike showing the application and performance of one model, this work not only generates the results but also visualizes the activation map of the original picture to compare the differences in which the models capture the features. This work demonstrates the mechanism of Convolutional Neural Network via a concrete way.
Limitations: In this experiment, it also has some Deficiency, first is over fitting problems. Accuracy of VGG16, the accuracy is dropping down rapidly because of over fitting; it is better to add regularization in the loss function to prevent over fitting problems. Second, there are also some disruptive factors in the datasets. The model cannot completely capture the location of the infected area. Sometimes the model captures the shoulder or outside the body, and the shoulder has no relationship with pneumonia. It is better to preprocess the datasets to reduce the disruptive factors.
C. Problems Statement
The idea is to identify Pneumonia Infected patients using chest X-Ray images with the help of CNN. The identification can be classified as Identification of Pneumonia affected lungs. Identification of Normal and not affected lungs.
D. Objectives
Motivation is to build a CNN architecture from scratch instead of using transfer learning. Various CNN architectures and these are trained on chest X-ray image dataset. Later the CNN model is trained and will be able to detect whether pneumonia is present or pneumonia is not present by the input Chest X-ray.
- Organization of The Report: The organization of the paper is as follows, Chapter 1 contains introduction to pneumonia detection and CNN with deep learning, Objectives and Problem Statement. Chapter 1 also contains a literature survey of relevant research papers of the topic pneumonia detection using CNN. Chapter 2 provides the Methodolgy and fetaures of dataset considered. Chapter 3 provides the followed System Architecture. Chapter 4 provides the Result snapshots and analysis of the results. Lastly, Chapter 5 gives the Conclusion and future scope of the proposed report.
II. METHODOLOGY
A. CNN Architecture
The model of convolutional neural network consists of convolution layers, pooling layers and full connection layers. The convolution layer and pooling layer are superimposed alternately. After passing through the full connection layers, another softmax layer is connected to map the probability of each category to the output of the network
CNN models are feed-forward networks with convolutional layers, pooling layers, flattening layers and fully connected layers employing suitable activation functions.
- Convolutional Layer: It is the building block of the CNNs. Convolution operation is done in mathematics to merge two functions. In the CNN models, the input image is first converted into matrix form. Convolution filter is applied to the input matrix which slides over it, performing element-wise multiplication and storing the sum. This creates a feature map. 3 × 3 filter is generally employed to create 2D feature maps when images are black and white. Convolutions are performed in 3D when the input image is represented as a 3D matrix where the RGB color represents the third dimension. Several feature detectors are operated with the input matrix to generate a layer of feature maps which thus forms the convolutional layer.
- Activation Functions: All four models presented in this paper use two different activation functions, namely ReLU activation function and softmax activation function. The ReLU activation function stands for rectified linear function . It is a nonlinear function that outputs zero when the input is negative and outputs one when the input is positive. The ReLU function is given by the following formula: This type of activation function is broadly used in CNNs as it deals with the problem of vanishing gradients and is useful for increasing the nonlinearity of layers. ReLU activation function has many variants such as Noisy ReLUs, Leaky ReLUs and Parametric ReLUs. Advantages of ReLU over other activation functions are computational simplicity and representational sparsity. Softmax activation function is used in all four models presented in this paper. This broadly used activation function is employed in the last dense layer of all the four models . This activation function normalizes inputs into a probability distribution. Categorical cross-entropy cost function is mostly used with this type of activation function .
- Pooling Layer: Convolutional layers are followed by pooling layers. The type of pooling layer used in all four models is max-pooling layers. The max-pooling layer having a dimension of 2 × 2 selects the maximum pixel intensity values from the window of the image currently covered by the kernel. Max-pooling is used to down sample images, hence reducing the dimensionality and complexity of the image . Two other types of pooling layers can also be used which are general pooling and overlapping pooling. The models presented in this paper use max-pooling technique as it helps recognize salient features in the image.
- Flattening Layer and Fully Connected Layers: After the input image passes through the convolutional layer and the pooling layer, it is fed into the flattening layer. This layer flattens out the input image into a column, further reducing its computational complexity. This is then fed into the fully connected layer/dense layer. The fully connected layer has multiple layers, and every node in the first layer is connected to every node in the second layer. Each layer in the fully connected layer extracts features, and on this basis, the network makes a prediction. This process is known as forward propagation. After forward propagation, a cost function is calculated. It is a measure of performance of a neural network model. The cost function used in all four models is categorical cross-entropy. After the cost function is calculated, back propagation takes place. This process is repeated until the network achieves optimum performance. Adam optimization algorithm has been used in all four models.
- Reducing Over Fitting: The first model exhibits substantial overfitting; Hence, dropout technique was employed in the later models. Dropout technique helps to reduce overfitting and tackles the problem of vanishing gradients. Dropout technique encourages each neuron to form its own individual representation of the input data. This technique on a random basis cuts connections between neurons in successive layers during the training process. Learning rate of models was also modified, to reduce overfitting. Data augmentation technique can also be employed to reduce overfitting.
- Algorithm of CNN Classifiers: The algorithms used in the convolutional neural network classifiers have been explained . The number of epochs for all the classifier models presented in this paper was fixed at 20 after training and testing several CNN models over the course of research. Classifier models trained for more number of epochs have showed overfitting. Several optimizer functions were also trained and studied. Adam optimizer function was finalized to be used for all classifiers after it gave the best results. Initially, a simple classifier model with convolutional layer of image size set to 64 * 64, 32 feature maps and employing ReLU activation function was trained. Fully connected dense layer with 128 perceptrons was utilized. To improve the result, the second classifier model was trained with one more convolutional layer of 64 feature maps for better feature extraction. The number of perceptrons in dense layer was also doubled to 256, so that better learning could be achieved. The third model was trained for three convolutional layers with 128 feature maps in third convolutional layer for more detailed feature extraction. Dense layer was kept unchanged. Dropout layer was introduced at 0.3, and learning rate of optimizer was lowered to 0.0001 to reduce the overfitting. The final fourth classifier model was trained for four convolutional layers with 256 feature maps in fourth convolutional layer. Dense layer, dropout layer and learning rate were kept same as classifier model.
???????B. Dataset
The dataset is organized into 3 folders (train, test, val) and contains subfolders for each image category (Pneumonia/Normal). There are 5,863 X-Ray images (JPEG) and 2 categories (Pneumonia/Normal). Chest X-ray images (anterior-posterior) were selected from retrospective cohorts of pediatric patients of one to five years old from Guangzhou Women and Children’s Medical Center, Guangzhou. All chest X-ray imaging was performed as part of patients’ routine clinical care. For the analysis of chest x-ray images, all chest radiographs were initially screened for quality control by removing all low quality or unreadable scans. The diagnoses for the images were then graded by two expert physicians before being cleared for training the AI system. In order to account for any grading errors, the evaluation set was also checked by a third expert.
The dataset employed in this work is picked from Kaggle.
The details of number of images under each part is shown in Table I. Some sample chest X-ray images are given in Fig. 2.1.
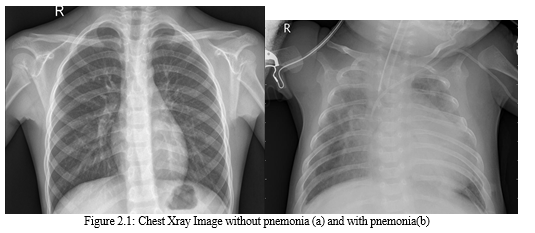
|
Dataset |
Number of Normal Images |
Number of Pnemonia Images |
|
Training Dataset |
1341 |
3875 |
|
Validation Dataset |
8 |
8 |
|
Testing Dataset |
234 |
390 |
Table 2.1: Dataset Information
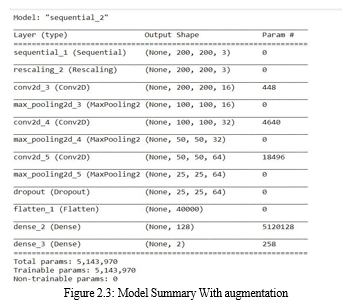
C. Model Summary
The size of each image is (200, 200, 3),
Keras then appends an extra dimension for processing multiple batches, i.e., to train multiple images in every step of a single epoch. Since batch size can vary, its size is represented by None. Hence, the input shape becomes (None, 200, 200, 3).
Convolving a (200, 200) image with a (4, 4) filter, with strides and dilation rate of 1, and ’valid’ padding, results in an output . Since you have 200 such filters, the output shape becomes (200, 200, 16).
The default MaxPooling kernel has a shape of (16, 16) and strides of (16, 16). Applying that to a (100, 100) image results in an image .
This pattern can be extended to all Conv2D and MaxPooling layers.
The Flatten layer takes all pixels along all channels and creates a 1D vector (not considering batch size)= 40000 values maxpooling layer that takes the output of the convolution as input. The output of the pooling has shape (None, 50, 50, 32), so it divided the size of your image by two, leaving the rest as it was first layer is a convolution, which takes an unknown input shape (it’s known by you, you defined it somewhere with input_shape.
The first convolution has an output with shape (None, 100, 100, 16) Flatten layer, which takes the images and transform them into a single vector, output shape is (None, 40000), where None is still the batch size untouched, the 40000 are all elements you had in the input tensor, now in a single vector, one vector per sample in the batch.
Then Dense layers, the first with 128 units, the second with 2 units.
The final output shape of your model is (None, 82). It outputs 82 values per sample in the batch.
Each layer has a number of parameters (which are generally the weights). The parameters that are trainable will be updated with backpropagation. The parameters that are not trainable will remain static or will be updated with a different method (only a few layers such as BatchNormalization has parameters that are updated with different methods) Your model has a total of 5143970 weights, all trainable.

III. DESIGN AND IMPLEMENTATION
A. System Architecture
The convolution layer carries the main portion of the network’s computational load.This layer performs a dot product between two matrices, where one matrix is the set of learnable parameters otherwise known as a kernel, and the other matrix is the restricted portion of the receptive field. The kernel is spatially smaller than an image but is more in-depth. This means that, if the image is composed of three (RGB) channels, the kernel height and width will be spatially small, but the depth extends up to all three channels.
During the forward pass, the kernel slides across the height and width of the image-producing the image representation of that receptive region. This produces a two-dimensional representation of the image known as an activation map that gives the response of the kernel at each spatial position of the image. The sliding size of the kernel is called a stride. Trivial neural network layers use matrix multiplication by a matrix of parameters describing the interaction between the input and output unit. This means that every output unit interacts with every input unit. However, convolution neural networks have sparse interaction. This is achieved by making kernel smaller than the input e.g., an image can have millions or thousands of pixels, but while processing it using kernel we can detect meaningful information that is of tens or hundreds of pixels. This means that we need to store fewer parameters that not only reduces the memory requirement of the model but also improves the statistical efficiency of the model.
The pooling layer replaces the output of the network at certain locations by deriving a summary statistic of the nearby outputs. This helps in reducing the spatial size of the representation, which decreases the required amount of computation and weights.
The pooling operation is processed on every slice of the representation individually. There are several pooling functions such as the average of the rectangular neighborhood, L2 norm of the rectangular neighborhood, and a weighted average based on the distance from the central pixel. However, the most popular process is max pooling, which reports the maximum output from the neighborhood.
Neurons in Full Connected layer have full connectivity with all neurons in the preceding and succeeding layer as seen in regular FCNN. This is why it can be computed as usual by a matrix multiplication followed by a bias effect.
The FC layer helps to map the representation between the input and the output.

???????B. Implementation
Here, we present two CNN architectures- one with a dropout layer and another without a dropout layer. Both CNN consist of convolution layer, max pooling and a classification layer. A series of convolution and max-pooling layers act as a feature extractor that is divided into two parts. The first part consists of two Convolution layers with 32 - 32 units each along with a max-pooling layer of size 3 × 3 and a Relu activator. While the other also has two Convolution layers but with 64 and 128 units respectively along with a max- pooling layer of size 2 × 2 and a Relu activator. Relu is a popular activation function which is generally used in neural networks especially in CNNs. Relu layer introduces nonlinearity to the model. Features extracted from the feature extractor part of the CNN are given as input to the dense layer which classifies the image. Before feeding the extracted features to the dense layer, a flatten layer a used. As the dense layer takes 1-Dimensional input, hence, flatten layer flattens the feature data and gives a 1- Dimensional output which is fed to the dense layer. While training a CNN it might be possible that output through a certain layer is more dependent on a few selected neural units. To reduce this dependency and prevent overfitting, the concept of dropout is introduced. During training, in each epoch, a neuron is momentarily dropped with a dropout probability p. Due to this, all the inputs and outputs to this neuron become disabled in the current epoch which results in some loss of data enhancing regularization in the model so that at times it would predict with much higher accuracy. The dropped-out neurons are resampled with probability p at every training step, so a dropped-out neuron at one step may become active in the next step. A dropout probability of 0.5, corresponds to 50% of the neurons being dropped out. In the proposed CNN architecture with dropout layer, we apply dropout at two places. First, it is applied at the feature extractor part i.e. after convolution and max-pool layers. As, the convolutional layers have not too many parameters, hence overfitting is not an issue in this case. Hence, here we take a low drop probability of 0.2. Second, it is used at dense layer. Dropout in the lower layers helps because it provides noisy inputs for the higher fully connected layers which prevents them from overfitting. At dense layers a drop probability of usually 0.5 is used as it has been observed that dense probability of 0.5 gives best regularization in most of the cases .
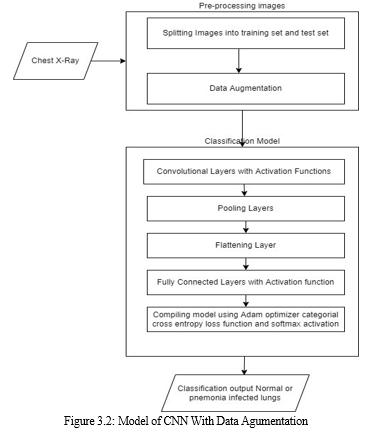
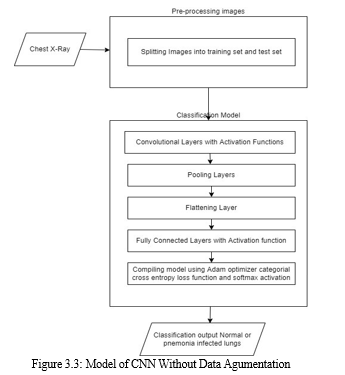
IV. RESULTS AND ANALYSIS
To assess the consequences of data augmentation methods on the performance of proposed CNN architectures, we trained the two CNN’s with the original dataset as well as the augmented dataset. The detail of CNN’s with the type of dataset used for training them are given .TYPES OF MODEL Model Dataset and CNN architecture Model 1 Without Augmentation, for 50 epochs Model 2 With Augmentation, for 50 epochs Model 3 Without Augmentation, for 20 epochs Model 4 With Augmentation, for 20 epochs The 2 models are trained for 50 epochs and other 2 models are trained for 20 epochs.
The batch size is 82.
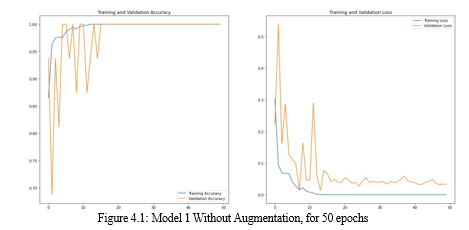
Above figure contains the training accuracy and validation accuracy and loss values against 50 epoch values are being seen through the graph for the model without augumentation.
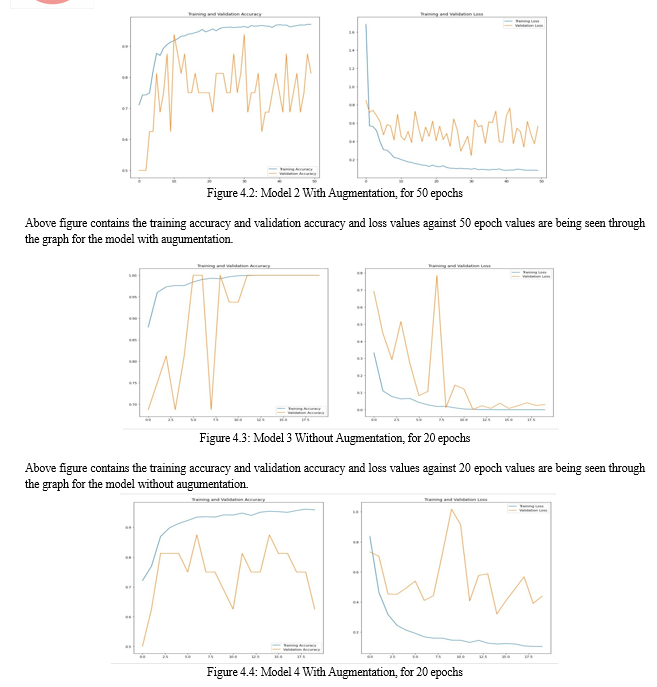
Above figure contains the training accuracy and validation accuracy and loss values against 20 epoch values are being seen through the graph for the model with augumentation. In the Table 4.1, the values of accuracy and loss observed in each of the 4 models is being mentioned based on testing accuracy, which clearly shows the accuracy of the models with augumentation is slightly higher than the models without augumentation. Loss of models built without augumentation brings high loss when they are being compared with loss of models built with introducing augumentation to them.
|
Model |
Accuracy |
Loss |
|
Model 1 |
0.7468 |
4.9 |
|
Model 2 |
0.7885 |
0.7292 |
|
Model 3 |
0.7372 |
4.06 |
|
Model 4 |
0.8189 |
0.4755 |
Table 4.1: Testing Accuracy and Loss of different model
Conclusion
Two CNN architectures that are designed from scratch to detect pneumonia from images of chest X-ray. To avoid overfitting, data augmentation techniques are used. The result of experiments performed to assess the performance of the proposed architectures and the effect of data augmentation on the performance of the proposed CNN’s show that CNN with dropout trained on augmented data outperforms the other models. In future, the plan is to use different optimizers and other data augmentation techniques in an attempt to further improve the classification accuracy of the proposed CNN architecture with data augmentation. The plan is also to use early stopping and batch normalization instead of dropout layer to see their effect in avoiding overfitting.
References
[1] Al Mamlook, R.E., Chen, S. and Bzizi, H.F., 2020, July. Investigation of the performance of machine learning classifiers for pneumonia detection in chest x-ray images. In 2020 IEEE International Conference on Electro Information Technology (EIT) (pp. 098-104). IEEE. [2] Al Mubarok, A.F., Dominique, J.A. and Thias, A.H., 2019, March. Pneumonia detection with deep convolutional architecture. In 2019 International conference of artificial intelligence and information technology (ICAIIT) (pp. 486-489). IEEE. [3] Garstka, J. and Strzelecki, M., 2020, September. Pneumonia detection in x-ray chest images based on convolutional neural networks and data augmentation methods. In 2020 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA) (pp. 18-23). IEEE. [4] Lee, K.W. and Chin, R.K.Y., 2021, September. An Adaptive Data Processing Framework for Cost-Effective COVID-19 and Pneumonia Detection. In 2021 IEEE International Conference on Signal and Image Processing Applications (ICSIPA) (pp. 150-155). IEEE. [5] Sharma, H., Jain, J.S., Bansal, P. and Gupta, S., 2020, January. Feature extraction and classi cation of chest x-ray images using cnn to detect pneumonia. In 2020 10th International Conference on Cloud Computing, Data Science & Engineering (Con uence) (pp. 227-231). IEEE. [6] Li, X., Chen, F., Hao, H. and Li, M., 2020, June. A pneumonia detection method based on improved convolutional neural network. In 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC) (Vol. 1, pp. 488-493). IEEE. [7] Khoiriyah, S.A., Baso , A. and Fariza, A., 2020, September. Convolutional Neural Network for Automatic Pneumonia Detection in Chest Radiography. In 2020 International Electronics Symposium (IES) (pp. 476-480). IEEE. [8] Varshni, D., Thakral, K., Agarwal, L., Nijhawan, R. and Mittal, A., 2019, February. Pneumonia detection using CNN based feature extraction. In 2019 IEEE international conference on electrical, computer and communication technologies (ICECCT) (pp. 1-7). IEEE. [9] Wei, X., Chen, Y. and Zhang, Z., 2020, October. Comparative experiment of convolutional neural network (CNN) models based on pneumonia X-ray images detection. In 2020 2nd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI) (pp. 449-454). IEEE. [10] Radha, D., 2021, June. Analysis of COVID-19 and Pneumonia Detection in Chest X-Ray Images using Deep Learning. In 2021 International Conference on Communication, Control and Information Sciences (ICCISc) (Vol. 1, pp. 1-6). IEEE.
Copyright
Copyright © 2022 Pranathi Patel, Hiriyanna GS. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET46031
Publish Date : 2022-07-27
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online