

Ijraset Journal For Research in Applied Science and Engineering Technology
Predict the Face-Mask-and-Social-Distance Identification by Using Yolo and CNN
Authors: Savanam Ramakrishnareddy, Perram Subba Rao
DOI Link: https://doi.org/10.22214/ijraset.2022.44618
Certificate: View Certificate
Abstract
COVID-19 virus is still a source of concern and hazard in today\'s world. With such a huge population traveling, manual monitoring of social distance standards is impracticable. Regarding and with a task force and resources that are insufficient to they should be administered There is a requirement for a lightweight, durable, and reliable device. This procedure is automated by a video observation device that operates 24 hours a day, seven days a week. This study offers a detailed and practical solution to the problem. Perform person detection, social distance violation detection, and social distancing violation detection. Using an item, detect faces and classify face masks. Convolution Neural Networks, detection, and grouping (CNN)is a binary classifier that is based on. YOLOv3, Density-fundamentally based spatial bunching of bundles with commotion (DBSCAN), and double are a portion of the instruments that can assist with this. Shot Face Detector (DSFD) and Binary MobileNetV2 Surveillance video assortments were utilized to prepare a classifier. This publication also includes a comparison of various facial types. Face mask detection and classification models. Finally, to make amends for the absence of a dataset within the network, a video dataset labeling technique is presented, couple with a labeled video dataset, which is utilized to evaluate the system. The framework\'s presentation is estimated as far as precision, F1 score, and gauge time, which should be least for practical use. On the labeled video data set, the device has an accuracy of 91.2 percent and an F1 rating of 90. Seventy-nine percent, with an average forecast time of seven.12 seconds for seventy eight frames of video
Introduction
I. INTRODUCTION
Covid are a class of infections that cause sicknesses beginning from colds to presence compromising illnesses comprising of interior Eastern Respiratory disease (MERS) as well as stern sharp Respiratory disease (SARS). Corona virus (covid-19) had been affirmed in ninety, 054,813 examples over the world as of January 2021, with 1,945,610 fatalities expressed to whom. Direct contact (contaminated people) or backhanded contact (filthy climate) can unfurl the COVID-19 infection. Breath drops, which may be drop trash with a measurement of five-10 m, reason this. drop spread commonly happen while an personality is nearby other people (inside 1 m) through superstar who have breath signs and is likewise defenseless against being uncovered to possibly infective respiratory drops through their mouth, nostril, or eyes. With the wide assortment of tainted cases and passing’s rising, it is a higher priority than at any other time to keep up with the infection beneath control. To save you the unfurl of COVID-19, social distance ought to be utilized along with various customary precaution estimates like as wearing veil, deflecting contacting Your face with messy fingers, and intermittently washing your fingers with cleansing cleaner and water for someplace round 20 seconds. The methodology of laying out a solid region among an individual and their environmental elements is alluded to as friendly removing.

Face mask and Social distancing detection
The recommended space to make sure the infection does not increase by make contact with is two meters (six feet).Following social distance standards reduced interaction between individuals over 60 and children under 20 by 95 percent and 85 percent, respectively. This demonstrates the impact of adhering to the appropriate social distancing regulations on "knocking down the curve." COVID-19 is more often than not transmitted from individual to character with the aid of respiration droplets. Coughing, sneezing, talking, screaming, or singing let loose respiratory droplets into the tone.
These droplets can ultimately fall into people's mouths or noses, or they could breathe them in. As a result, wearing masks is critical to preventing the infection from spreading. Masks serve as A primary barrier to hold breathing droplets from spreading to others. When worn throughout the nostril and mouth, research exhibit that mask minimize the spray of droplets. Physically observing social distance principles and reviewing individuals' facial coverings isn't just badly arranged with restricted assets, however it might likewise prompt human errors. A methodology to control the viral transmission by understanding the ideal social removing guidelines to be complied by people in general is critically required. This includes distinguishing social distance infringement and arranging facial coverings to survey resident security by deciding whether adequate distance is kept up with and whether facial coverings are utilized.
This device can be utilized in a selection of public venues with cameras, which include supermarkets, gasoline stations, and site visitor’s indicators. This offers processing strategies that can be used to utilize a surveillance device for a selection of various purposes. This look at offers a proactive and light-weight COVID19 prevention gadget that use video surveillance to perceive and assist the government in ensuring that everyone adheres to social distance and safety standards as a way to save the virus from spreading.
The next is a list of the elements of the paper: section II discusses modern-day art work on this field, segment III describes the dataset used and discusses dataset augmentation The resulting is a posting of the portions of the paper: component II examines modern-day compositions on this field, region III depicts the dataset applied and talks approximately dataset growth and video marking approaches that is probably applied to construct the scale of the dataset and diploma the framework's standard presentation, segment IV talks approximately preprocessing techniques, and level V talks approximately the approach and exceptional designs for character recognition, social eliminating infringement identification, face location, and facial overlaying discovery. The discoveries of the framework's investigation are introduced in Section VI, and the framework's future degree is introduced in Section VII. At long last, area VIII wraps the book up paper.
II. RELATED WORK
- Mohamed Oley et al. [1] created a version that mixes deep switch getting to know (ResNet-50) and conventional device getting to know methods. To growth version performance, the very last layer of ResNet-50 changed into deleted and changed with 3 traditional device getting to know classifiers (Support vector device (SVM), selection tree, and ensemble).One of the four types of datasets they utilized had the most photos, consisting of genuine and artificial face masks, and took the most time during the training process compared to the others. There is also no known accuracy for this sort of dataset in related publications. The choice trees classifier neglected to acquire palatable arrangement precision (68%) on bogus facial coverings when prepared on a dataset utilizing genuine facial coverings.
- Resent on the grounds that the spine, FPN (highlight pyramid organization) as the neck, and classifiers, indicators, assessors, and various added substances are utilized to make an identification network with a spine, neck, and heads [2]. be that as it may, because of the little length of the facial covering dataset, learning calculations struggle with learning further developed highlights. Facial covering identification has definitely stood out as of late, yet further exploration is expected to further develop recognition exactness.
- RinkalKeniya [3] created a self-made model called SocialdistancingNet-19 for recognizing a person's frame and presenting labels to determine if they are safe or harmful if the distance is less than a particular amount. It is vital to have individuals moving continually if a camera is to be utilized, or else the detection will be wrong. This might be related to the network's detection strategy, which involves detecting the full-frame and calculating the distance between persons using cancroids (brute force approach).
- For social separating and covers recognition, Shahs Yadav directed a profound acquiring information on replies with single Shot thing Detection (SSD) utilizing Mobile Net V2 and OpenCV [4].The hassle with this approach is that it labels people as masked in the event that they have their palms over their faces or their features are obscured with the aid of matters. This model is not appropriate for these cases. Although an SSD may identify many objects in a single frame, it is only capable of detecting one human in this system.
- To execute obscure increase, an obscuring elective is picked aimlessly from Gaussian haze with part measures going from 6 to ten, normal haze with portion sizes beginning from 3 to 9, development obscure with piece sizes going from 3 to 10, and no haze. The outcome of blurring a photo with the Gaussian characteristic is Gaussian blur [5]. The pixels closest to the kernel's centre are given more weight than the ones in addition out. The streaking impact is called movement blur. through catching moving things in a shot or a progression of edges settling on an irregular course for the development obscure Then there might be the upward, flat, prevalent inclining, and hostile to askew. Correspondingly convolving the photo with the part normal When a picture is obscured by convolving it with another image, the outcome is obscure. Filter in a box (normalized). The essential part of this technique is the average of all the pixels in the image is used to replace the original .Region of the kernel.
- This paper includes social distancing & face mask detection .wearing face masks and following social detection we can save lots olives and we can reduce the spread of the virus. By using YOLO algorithm we need to track the Objects and as well as Detect the Object. YOLO stands for You Only Look as soon as which goes on a real-time system, construct on deep gaining knowledge of for fixing numerous Object Detection in addition to Object Tracking problems. The monitoring and detecting gadgets the usage of yolov3. Its miles used to calculate the space if any individual cannot observe the space of minimal 6feet than it displays the violation. With the assist of bounding boxes.
- This paper consists of social distancing & face masks detection for the occasions of corona virus. Various healthcare organizations, scientists, health workers are within side the race to amplify powerful drugs and vaccines for this large of the virus. To triumph over this virus we want to hold the 6-ft distance if everyone cannot observe the minimum 6feet through the use of a few algorithms like laptop vision, CNN, item detection, pedestrian detection, and Pedestrian detection makes use of superior sensors to locate human movements. We will music and locate the item and we will given a facts set this is coco version on this version carries all sorts of items like bikes, car, people EST. Finally, we will find persons with bounding boxes
III. DATASET
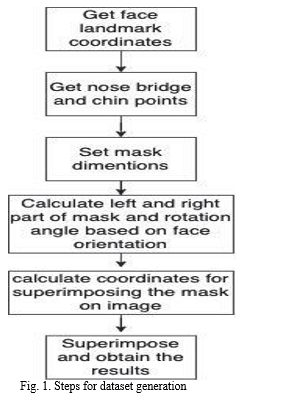
The collection of uncovered and covered faces gathered from current sources was insufficient, thus new and two facts augmentation tactics have been used to feature masks to unmasked faces and blurred snap shots. As illustrated in Fig. 2, records expansion for without masked faces was conducted on records with masks that are three types.

Figure 2 shows the algorithm that was employed. The strategy begins by distinguishing the characterizing points of a face's form. The top piece of the veil can be found by finding the nose span, as well as the base, right and left parts can be found through finding face's jaw focuses. The mask's left and right halves are both made to the correct size. The mask's angle of rotation is computed using the face's orientation. The mask is then put on the face once the coordinates for superimposing it on the face have been determined.
The photographs are recorded from a security camera due to the environment of the scenario because of this the faces are pretty hazy or obscured. The dataset, then again, contained pictures with awesome faces. For the second one statistics augmentation in Fig. 3, blurring filters inclusive of movement blur, Gaussian blur, and average blur is utilized to avoid the model's adaptation to the surveillance first-rate faces.

To execute obscure expansion, an obscuring choice is picked aimlessly from Gaussian haze with bit sizes going from 6 to 10, normal haze with part estimates going from 3 to 9, movement obscure with bit sizes going from 3 to 10, and no haze. The final results of blurring a photograph with the Gaussian characteristic is Gaussian blurs. The pixels closest to the kernel's centre are given more weight than the ones similarly out. The ultimate records contains 011,792 annotated pictures by means of the classifications 0 (without mask) and 01 (with mask), with 10 percentages of the data utilize for test. There were no video datasets available because the problem was new. On the video, there was also no way to assess the system's overall effectiveness. As a result, 30 movies through length of 09-015 second be obtained with label separately. This be utilized to provide an balanced assessment of the system's feat. The names utilized were that complete number of people, the absolute number of individuals who didn't follow social separating, the all out number of appearances distinguished, and the all out number of individuals who wore veils.
IV. PROCEDURE
This section delves into the several models for the system, which are given and employ a variety of object detection and picture categorization algorithms. The movement of that model to construct the structure is depicted imagery as of a observation record are sampled. A variety of one border for each number of 5 frames was used to process the video. Because the videos had an average frame rate of roughly 80 frames per second, some frames may be missed because the association of individuals will not be as well extreme with in a little bit of a moment As a result, that gives a means for increasing calculation speed without sacrificing model performance.
For the YOLOv3 man or woman identity model, all images are scaled to 416x416 and bounding packing containers are fashioned round them. The centurions of those bounding packing containers are calculated, and social distancing norms are confirmed the use of outlier detection strategies with a two-meter distance parameter. The pix are scaled to 128x128 for face identity with CNN and cowl elegance with MobileNetv2. Resent CNN layers are applied to cast off capacities from pix for face discovery, and the images are reduced to 128x128 for face popularity with CNN and covers kind with MobileNetv2. The image outlines are then brought collectively to make the closing video. SOCIAL DISTANCE DETECTION.
For individual location, the YOLOv3 model was used [16]. It involves 106 layers, including 53 degrees of Darknet-53 talented on Image net as a solid trademark extractor and each and every 53 layers for recognition, for an aggregate of 106 layers of completely convolution brain organizations. The YOLOv3 design is found in Figure 5. The anchor box has three scales: 13x13, 26x26, and 52x52. As delineated in the representation, these 3 anchor holders are used to expect the presence of a human. After expectation, this model creates a rundown of jumping pressing compartments on the whole with the certainty level of the found individual class. Non-most concealment is utilized to overcome the difficulty of covering bouncing receptacles bringing about numerous identifications for the indistinguishable article (NMS). The absolute last jumping pressing compartments had been concluded the utilization of a zero. Five self conviction cost and a zero. three NMS edge, separately. This implies that best illustrations with better than half certainty are kept up with, and any bouncing canisters that cross-over another jumping box by over 30% are erased.
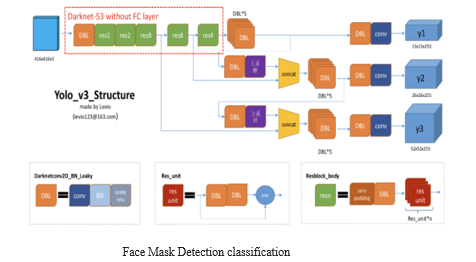
To affirm for the presence of a covers at the countenances found, the Face veil Detection type is done the utilization of CNN parallel picture type architecture. The execution of various designs built the use of CNN for cover class on 128x128 photographs in expressions of exactness, accuracy, remember, and F1 rankings for refinement 0 (no covers) and complexity 1 (concealed). As displayed in Fig , MobileNetV2 become chosen because of its general exhibition as far as expectation time and precision.
V. PROPOSED WORK
Albeit the framework's precision and estimate time are both great, the accompanying regions for development have been recognized: First, the human recognition module consumes the vast majority of individuals of video handling time. the easier character recognition algorithm is probably created that takes less time to forecast and has the identical accuracy as the prevailing model. Second, due to the fact the social distance calculation and mask categorization occur one at a time, parallelism can be employed to carry out them each on the same time. Third, there is a lack of datasets that might be employed in one of these system, and it is not numerous sufficient to feature in all eventualities .Because there aren't enough negative instances with beards in the system, it occasionally confuses beards with masks. A more powerful model may be trained once such datasets become accessible.
A. CNN classification of images
Because of its greater geographic attribute withdrawal capacity and minor computation price CNN acting a vital position in processor idea-associated model detection applications [1]. A binary classification of images is one of its various applications. To extract senior-rank facial appearance CNN use complication kernel to convolve with the unique pictures or aspect map.
B. CNN for Object Detection
The process of transmission a group marker to a figure is known as image classification. Drawing a bound pack approximately a thing in a image is known as object localization. Objective finding is extra challenging, since it combines the two tasks by drawing a bound box approximately each item of notice in the icon and assigning a group tag to it. Let look at how easy binary or multi-class algorithms may be tweaked to create bounding bins round an object.
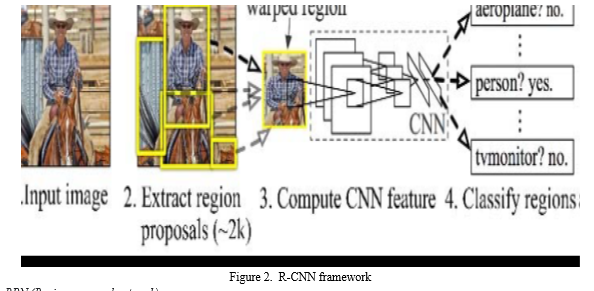
C. Faster R-CNN algorithm
The maximum drastically applied cutting-edge shape of the R-CNN own circle of relatives is quicker R-CNN. These networks usually consist of the subsequent components: a) A location inspiration approach for producing "bounding boxes," or places of in all likelihood gadgets with inside the image. b) A level for producing functions for those gadgets, usually the usage of a CNN. c) A class layer to forecast which magnificence this item belongs to, and d) A regression layer to refine the bounding container coordinates of the item.
D. RPN (Region proposal network)
The enter photo is furnished into the spine convolution neural community of the location idea community (RPN). The furnished photo is to start with downsized to six hundred pixels at the shortest aspect and one thousand pixels at the longest aspect. Depending at the stride of the spine community, the output functions of the spine community are regularly appreciably smaller than the enter photo. The community ought to examine whether or not an item is gift with inside the enter photo at its related role and estimate its length for every factor with inside the output characteristic map.
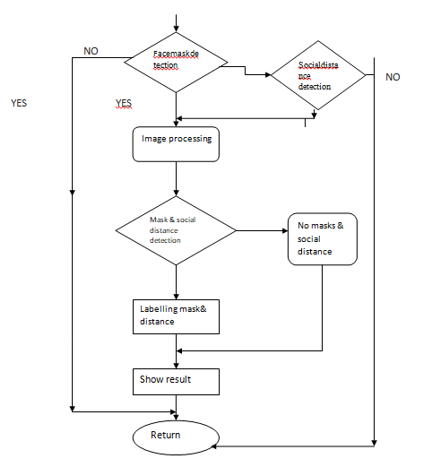
VI. WRAPPING UP
The Purpose of this take a look at turned into to recognize the social distancing &face masks detection for the occasions of covid-19. The social distancing item detection turned into primarily based totally on persons, at the same time as the face masks detection turned into primarily based totally on face, created the usage of Yolo. This embedded vision-primarily based totally generation may be utilized in any operating surroundings in which accuracy and precision are required, including a public place, a station, a company setting, streets, purchasing malls, and exam centers. It may be hired in clever metropolis innovation and might assist many underdeveloped nations boost up their growth. Our method gives the possibility to be higher organized for the following disaster or to evaluate the results of large-scale social extrade on sanitary safety standards.
References
[1] MingjiJiang? ,Xinqai Fen, Hoing Yaan, RETINA FACEMASK: A FACE WITH MASK DETECTOR (2020) [2] Shaashi Yadaav, Goeel ITechnology and organization, Dr. A.P.J. Abdul Kalam technological University, Deep Learning base Safe Social isolation and Face With Mask Detection in community Areas (2021) [3] COVID-19 security tips devotion (2020). [4] Rinakal Keeniya, Ninadh Mehendhale, real-time societal isolation detector the use of Social distancing-Net19 deep learning set-up (2020). [5] Indhu Jain, Mr.Sudhir Goswami; A relative take a look at of numerous photograph healing strategies with extraordinary kinds of shape, global paper Of research In pc programs And Roobotics (2019).
Copyright
Copyright © 2022 Savanam Ramakrishnareddy, Perram Subba Rao. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET44618
Publish Date : 2022-06-20
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online