

Ijraset Journal For Research in Applied Science and Engineering Technology
Predict, Identify and Alert on Suspicious Activity by Multiple Zone
Authors: Pratik Yadav, Mayuri Ghodke, Vivek Dhokane, Sanjana Chavan, Prof. Rajshri T. Ingle
DOI Link: https://doi.org/10.22214/ijraset.2023.52523
Certificate: View Certificate
Abstract
Suspicious human activity detection in security capture is a study topic in image processing and vision. The mysterious identification of human activity from video surveillance is an area of study in both fields. Human activity can be monitored visually in conspicuous public spaces like bus depots, airports, railway stations, financial institutions, malls, schools, and universities to avoid terrorist activity, vandalism, accidents, prohibited parking spaces, vandalism, fighting chain theft, criminality, and other unusual behavior. Extremely difficult to continually monitor public spaces, thereby an innovative video surveillance installation system that can track people\'s movements in real-time, classify them as routine or odd, and send out an alert is needed. The field of visual surveillance to identify aberrant actions has seen a significant amount of publications in the last ten years. Furthermore There are a few surveys in the literature for recognising various abnormal activities, but none have reviewed various abnormal activities, but none of them have reviewed various abnormal activities. This study presents the state-of-the-art in the field of recognizing suspicious behavior from surveillance recordings during the past ten years. We provide a brief outline of the risks and challenges associated with detecting suspicious human activity. This article examines six aberrant behaviors, including the identification of abandoned objects, theft, falls, traffic accidents, and unlawful parking, as well as the detection of violence and fire. Generally speaking, we have covered all the processes that have been [1] Foreground object extraction, object identification based on tracking or non-tracking approaches, feature extraction, classification, activity analysis, and recognition are some of the techniques that have been used to identify human activity from surveillance movies in the literature. This paper\'s goal is to give field researchers a literature assessment of six different suspicious activity identification systems together with its broad framework.[1]
Introduction
I. INTRODUCTION
Image processing and vision researchers are now studying the ability to identify abnormal conduct from video surveillance. We are created three zones named as industry, medical, and agriculture.
Recognition of suspicious behavior, fire, and ATM theft in industrial zones. In the last agricultural zone, forecast various types of plant leaf illnesses and tea disease of the leaf. In the wellness zone, recognize brain tumors detection, cancer of the lungs detection, and diabetes detection.
The YOLOv3 algorithm is a state-of-the-art object detection algorithm that can be used to detect and locate human and vehicle objects in images and videos. The algorithm uses a deep neural network to analyses the visual features of an image or video and identify objects of interest [1].
The YOLOv3 algorithm is a popular object detection model that can be used for a wide range of applications, including fire detection in surveillance videos. In order to train the YOLOv3 model to detect fire in surveillance videos, you will need to collect a dataset of images and videos containing fires [2] . In the context of ATM theft detection, it can be used to detect and classify suspicious activity around ATMs, such as people trying to break into the machine, tampering with the card reader or keypad, or installing skimming devices. The suspension activity refers to the ability to detect when the ATM is not in use, such as during non-business hours or maintenance periods. This can help to filter out false alarms and focus on detecting suspicious activity during times when the machine is expected to be in use. To implement this system, a video feed from the ATM is captured and fed into the YOLOv3 algorithm. The algorithm then processes each frame in real-time, identifying any objects of interest and tracking their movements over time. This allows it to detect patterns of behavior that are consistent with ATM theft, such as prolonged periods of activity around the card reader or attempts to physically break into the machines[4].
We are using CNN algorithm to detect rain tumors. An MRI scan is often the initial stage in determining the existence of a tumors in the brain. The major objective is to identify if the brain has brain cancer or is healthy. Brain tumors detection using CNN (Convolutional Neural Networks)
II. LITERATURE SURVEY
Members Ting Yao, Jiajun Deng, Yingwei Pan, Wengang Zhou, and [1] The authors are assessing Abstract— Compared to two-stage detectors, single shot detectors have the potential to be quicker and simpler, making them more useful for object recognition in movies. However, extending these object detectors from images to videos is not simple, especially when appearance degradation, such as motion blur or occlusion, occurs in movies.
How to investigate temporal coherence across frames for improving detection is a legitimate topic. In this study, we suggest that the issue may be solved by aggregating surrounding frames to improve the per-frame characteristics. We provide Single Shot Video Object Detector (SSVD) in particular, a An innovative new architecture for object recognition in movies incorporates feature aggregation into a one-stage detector.[5] To create multi-scale features, SSVD technically uses the Feature Pyramid Network (FPN) as a backbone network.
SSVD differs from previous feature aggregation techniques in that it directly samples data from consecutive frames in a two-stream structure while simultaneously estimating motion and aggregating neighboring features along the motion route. On the Image Net VID dataset, extensive tests are carried out, and competitive results are provided when compared to cutting-edge methodologies. More astonishingly, SSVD processes a frame on an Nvidia Titan X Pascal GPU in 85 milliseconds with 448 448 input, achieving 79.2mAP on Image Net VID. Object detection algorithms are used in a variety of industries, including defence, security, and healthcare, according to Apoorva Raghunandan, Mohan, Pakala Raghav, and H. V. Ravish Aradhya [2]. A range of object identification techniques, including face detection, skin detection, colour detection, shape detection, and target detection, are modelled and implemented in this study in order to more precisely identify various types of objects for video surveillance applications. Different object detection techniques are explored, as well as their applications and drawbacks. [1] Wenguan Wang, Member, and Jianbing Shen,
Senior Member The purpose of visual attention in understanding object patterns in films is thoroughly investigated in this study. We quantitatively confirmed for the first time the high consistency of visual attention behaviour among human observers by thoroughly annotating three well-known video segmentation datasets (DAVIS16, Youtube-Objects, and SegTrackV2) with dynamic eye-tracking data in the UVOS setting. During dynamic, task-driven viewing, we also found a significant link between human attention and explicit primary object judgments. These ground-breaking discoveries provide a full grasp of the reasoning that underlies the patterns of video objects. The two sub-tasks that we distinguish from UVOS in light of these findings (AGOS) are UVOS-driven dynamic visual attention prediction (DVAP) in the spatiotemporal domain and attention-guided object segmentation. The three main advantages of using our UVOS system are: 1) modular training without the use of costly video segmentation annotations; instead, the initial video attention module is trained using less expensive dynamic fixation data, and the following segmentation module is trained using pre-existing fixation-segmentation paired static or image data. Object detection became one of the main fields in computer vision, according to Jung Uk Kim and Yong Man Ro [4]. The duties of object categorization and object localization are carried out during object detection. With feature maps produced by entirely shared networks, previous deep learning-based object identification networks function well. The feature map's most discriminative object area, however, is where object categorization is concentrated. In contrast, object localization demands a feature map that is focused on the entire region of the item. In this study, we examine how the two goals differ and offer a special object identification network. The proposed deep learning-powered structure has two key parts: 1) a cognitive network that creates task-specific attention maps, and 2) a layer separation that divides the layers for the two tasks. Extensive experimental findings based on the PASCAL VOC dataset and the MS COCO dataset showed that the suggested object recognition networks outperformed state-of-the-art approaches.
Song Wang, Xingyuan Zhang, Qi Zou, Yanting Pei, Yaping Huang, and Image categorization has advanced significantly recently thanks to deep learning neural networks, particularly the Convolutional Neural Networks, just like many other computer vision- related fields (CNNs). As shown by the frequently used image databases Caltech-256, PASCAL VOCs, and Image Net, the majority of the existing works concentrated on classifying extremely clear natural images. However, the acquired images may have some degradations in many actual applications that result in different types of blurring, noise, and distortions. The impact of such degradations to the performance of CNN-based networks is one significant and intriguing issue. the ability of degradation removal to improve CNN-based picture categorization. More specifically, we question whether image classification performance decreases with each type of degradation, whether this decline can be prevented by training on degraded images, and whether the performance of existing computer vision algorithms that try to remove such degradations can be enhanced. In this research, we investigate such issues empirically for nine different types of damaged photos. [3]
III. METHODOLOGY
We used two label of first webpage.
Label 1 ---- 1st Gradient AI
Label2-----2nd enclitic medical
Label3-----3nd agriculture
In each zone separately run YOLOV3 algorithm.
1st Gradient AI
= SUSPICIOUS human activity
= SUSPICIOUS vehicle activity
=ATM theft diction
=Fire diction
choose a zone and Run the software. They start working.
A. YOLOv3 Algorithm
You Only Look Once, Version 3 (YOLOv3) is a real-time object identification system that can recognize certain things in moving images, live feeds, or still photos. [7] Using properties that a deep convolutional neural network has learned, the YOLO machine learning system uses them to find an item. The YOLO machine learning algorithm's third iteration is an improved version of the initial ML strategy. Versions 1–2 of YOLO were made by Ali Farhadi and Joseph Redmond. 3. Version 1 of YOLO was launched in 2016, while version 3, which this article mostly focuses on, was released in 2018. An enhanced version of YOLO, YOLOv2, and YOLOv3 is available. The Keras or Open-CV deep learning frameworks are used to implement YOLO. Installation of YOLOv3 is quite simple. After some dependencies and libraries have been installed, using it to train models is simple. YOLOv3 can be set up either through a notebook or directly on a computer (such as Google Collaborator or Jupyter). The commands are the same for both implementations. The command to install YOLOv3 is pip install YOLOv3, assuming all libraries have been installed. I'll give you a quick tutorial on installing YOLOv3 along with the necessary libraries. Visit Viso.AI/Deep Learning/Yolov3- Overview to learn more.[7]
B. Model Weights
We use YOLOV3 and CNN algorithms are used for the detection of Suspicious activity and process three images to detect the healthy and unhealthy brain, lung, leaf,tea leaf. The algorithm uses a deep neural network to analyze the visual features of an image or video and identify objects of interest. To perform suspension activity detection using the YOLOv3 algorithm, you would need to follow these steps: Collect and preprocess data: Collect a dataset of images or videos that include humans and vehicles in suspension activities. Preprocess the data by resizing, cropping, and normalizing the images to prepare them for input into the YOLOv3 algorithm.
IV. SYSTEM ARCHITECTURE
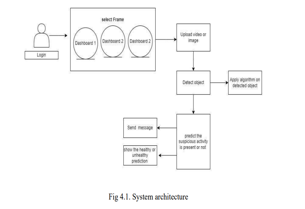
V. DISADVANTAGES
- One disadvantage crash or damage camera then system is not working because system is also depend on camera. APPLICATION
- Forest
- Banking
- Society
Conclusion
Nearly everyone in the modern world is aware of the value of CCTV video, but in most circumstances, it is only used for investigative purposes after a crime or incident has occurred. The benefit of the suggested paradigm is that it prevents crime from occurring. Real-time CCTV footage is being monitored and examined. The analysis\'s outcome is a directive to the appropriate authority to take action if it appears that an unfortunate situation is about to occur. So, it is possible to stop this. work with various datasets. And establish the zone. Our approach can offer crucial suggestions for the real-time recognition of distorted objects after motion in the films. Utilising a Raspberry Pi for live human contact in the wild.
References
[1] MUHAMMAD SUALEH AND GON-WOO KIM, “Visual-LiDAR Based 3D Object Detection and Tracking for Embedded Systems”, IEEE Access (August 24, 2020,) 10.1109/ACCESS.2020.3019187 [2] Jiajun Deng, Yingwei Pan, Ting Yao, Member, IEEE, Wengang Zhou, Member, IEEE, Houqiang Li, Senior Member, IEEE, and Tao Mei, Fellow, IEEE , “Single Shot Video Object Detector”, information :DOI 10.1109/TMM.2020.2990070, IEEE Transactions on Multimedia. [3] Deng-Ping Fan, Ge-Peng Ji, Ming-Ming Cheng, and Ling Shao , “Concealed Object Detection”, information: DOI 10.1109/TPAMI.2021.3085766, IEEE, Transactions on Pattern Analysis and Machine Intelligence [4] Wenguan Wang, Member, IEEE, Jianbing Shen, Senior Member, IEEE, Xiankai Lu, Member, IEEE, Steven C. H. Hoi, Fellow IEEE, Haibin Ling , “Paying Attention to Video Object Pattern Understanding”,information:DOI 10.1109/TPAMI.2020.2966453, IEEE Transactions on Pattern Analysis and Machine Intelligence [5] Runsheng Zhang, Yaping Huang, Mengyang Pu, Jian Zhang, Qingji Guan, Qi Zou, Haibin Ling Member, IEEE, “Object Discovery From a Single Unlabeled Image by Mining Frequent Itemset With Multi-scale Features”, DOI 10.1109/TIP.2020.3015543, IEEE Transactions on Image Processing. [6] Yanting Pei, Yaping Huang, Qi Zou, Xingyuan Zhang, Song Wang , “Effects of Image Degradation and Degradation Removal to CNN- based Image Classification”, information: DOI 10.1109/TPAMI.2019.2950923, IEEE Transactions on Pattern Analysis and Machine Intelligence. [7] Jung Uk Kim and Yong Man Ro, “ATTENTIVE LAYER SEPARATION FOR OBJECT CLASSIFICATION AND OBJECT LOCALIZATION IN OBJECT DETECTION”, 978-1-5386-6249- 6/19/$31.00 ©2019 IEEE [8] Apoorva Raghunandan, Mohana, Pakala Raghav and H. V. Ravish Aradhya , “Object Detection Algorithms for Video Surveillance Applications”, 978-1-5386-3521-6/18/$31.00©2018 IEEE [9] H.-K. Chu, W.-H. Hsu, N. J. Mitra, D. Cohen- Or, T.-T. Wong, and T.-Y. Lee, “Camouflage images.” ACM Trans. Graph., vol. 29, no. 4, pp.51–1, 2010. [10] Z.-Q. Zhao, P. Zheng, S.-t. Xu, and X. Wu, “Object detection with deep learning: A review,” IEEE T. Neural Netw. Learn. Syst., vol. 30, no. 11,pp. 3212–3232, 2019. [11] D.-P. Fan, J. Zhang, G. Xu, M.-M. Cheng, and L. Shao, “Salient objects in clutter,” arXiv preprint arXiv:, 2021. [12] J.-X. Zhao, J.-J. Liu, D.-P. Fan, Y. Cao, J. Yang, and M.-M. Cheng, “Egnet:edge guidance network for salient object detection,” in Int. Conf.Comput. Vis., 2019. [13] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisser-man, “The pascal visual object classes (voc) challenge,” Int. J. Comput. Vis., vol. 88, no. 2, pp. 303–338, 2010. [14] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet:A large-scale hierarchical image database,” in IEEE Conf. Comput. Vis.Pattern Recog., 2009, pp. 248–255
Copyright
Copyright © 2023 Pratik Yadav, Mayuri Ghodke, Vivek Dhokane, Sanjana Chavan, Prof. Rajshri T. Ingle. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET52523
Publish Date : 2023-05-19
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online