

Ijraset Journal For Research in Applied Science and Engineering Technology
Prediction for Effective Heart Disease System
Authors: Dr. S. K. Manju Bargavi, Deepak Kumar Tigga
DOI Link: https://doi.org/10.22214/ijraset.2022.41892
Certificate: View Certificate
Abstract
The health care industries gather large quantities of records that include a few hidden information, which is beneficial for making powerful choices. For imparting suitable effects and making powerful choices on records, a few superior records mining strategies are used. In this study, a Heart Disease Prediction System (HDPS) evolved the use of Naive Bayes and Decision Tree algorithms for predicting the danger stage of a coronary heart ailment. The device makes use of 15 scientific parameters along with age, sex, blood pressure, cholesterol, and weight problems for prediction. The HDPS predicts the chance of sufferers getting coronary heart ailment. It permits substantial knowledge. Relationships among scientific elements associated with coronary heart ailment and patterns, to be established. We have hired the multilayer perceptron neural community with backpropagation because of the education algorithm. The acquired effects have illustrated that the designed diagnostic device can efficiently predict the dangerous stage of coronary heart disease.
Introduction
I. INTRODUCTION
A principal mission going through healthcare organizations (hospitals, clinical centers) is the supply of fine offerings at low-cost costs. Quality providers implies diagnosing sufferers effectively and administering remedies that are effective. Poor medical selections can cause disastrous outcomes that are consequently unacceptable. Hospitals have to additionally reduce the value of medical tests. They can gain those effects with the aid of using suitable computer-primarily based totally records and/or selection guide structures. Most hospitals nowadays rent a few types of medical institution records structures to manipulate their healthcare or affected person statistics.
These structures usually generate big quantities of statistics which take the shape of numbers, text, charts, and images. Unfortunately, those statistics are not often used to aid medical decision-making. There is a wealth of hidden statistics in those statistics that are essentially untapped. This raises a crucial question: “How are we able to flip statistics into beneficial statistics which can allow healthcare practitioners to make clever medical decisions?” Although statistics mining has been around for more than decades, its ability is best being found out now. Data mining combines statistical analysis, gadget mastering, and database era to extract hidden styles and relationships from huge databases. The maximum not unusual place modeling goals are type and prediction.
Classification fashions expect express labels (discrete, unordered) while prediction fashions expect continuous-valued functions. Decision Trees and Neural Networks use type algorithms while Regression, Association Rules, and Clustering use prediction algorithms.
II. LITERATURE SURVEY
Different kinds of research were brought to attention regarding the prediction of coronary heart disorder. Various record mining strategies are used for analysis and finished with distinct accuracy stages for distinct methods. The Naive Bayes classifier set of rules makes use of conditional independence; Web-primarily based total fitness care detection was changed.
S. Indhumathi & Mr.G.Vijaybaskar, 2015 has recommended the prediction of high-danger coronary heart disorder through the use of a Naive Bayes set of rules. Records that have been preprocessed have been taken into consideration because the schooling set and the preprocessing consists of cleansing of records, normalization and discounting of records, etc. It has 3 layers in particular, i.e., the enter layer, the hidden layer, and the output layer. The input is supplied to the enter layer and the end result is acquired within the output layer. Then the real outputs and the predicted outputs are compared. The backpropagation has been carried out to locate the mistake and to regulate the burden between the output and the formerly hidden layers. Compared to different device-studying algorithms, KNN is the best set of rules.
The root of the choice tree is the record set, and the leaf is the subset of the record set. A danger stage of coronary heart disorder prediction through a hybrid set of rules has been proposed by Shovon K. Pramanik. A hybrid set of rules is the aggregate of the KNN set of rules and ID3. These algorithms are used for coronary heart disorder prediction. The KNN set of rules is used to preprocess the records.
The preprocessed records are taken into consideration as a schooling set, after which the records have been categorized right into a tree structure. The ID3 set of rules is applied to the classifier in order to predict coronary heart disease. The wrong values are categorized through the KNN Algorithm.
Numerous research has been performed which has been recognized on analysis of coronary heart disease. They have implemented special records mining strategies for analysis & carried out special possibilities for special methods.
Polaraju, Durga Prasad, & Tech Scholar, 2017 proposed Prediction of Heart Disease the usage of the Multiple Regression Model and it proves that Multiple Linear Regression is suitable for predicting coronary heart disorder chance. The painting is finished with the usage of schooling statistics set includes 3000 severe with thirteen distinctive attributes which have stated earlier. The statistics set is split into elements this is 70% of the statistics are used for schooling and 30% are used for testing.
Deepika & Seema, 2017 make a specialty of strategies that could expect persistent disorder through mining the records contained in historic fitness statistics through the use of Nave Bayes, selection trees, assist vector machines (SVM) and synthetic neural networks (ANN).
Beyene & Kamat, 2018 counselled a coronary heart disorder prediction machine through the use of record mining strategies. The Weka software programmed is used for computerized analysis of disorders and to offer pointers to the great variety of offerings in healthcare centers. SVM is powerful and presents greater accuracy in comparison with different record mining algorithms.
Chala Beyene encouraged the prediction and evaluation of the prevalence of coronary heart disorder through the use of records. The predominant goal is to estimate the prevalence of coronary heart disorder for early computerized analysis of the disorder within a short length of time.
It makes use of one-of-a-kind clinical attributes consisting of blood sugar and coronary heart rate, age, and intercourse as a number of those attributes are blanketed to perceive if the individual has a coronary heart disorder or not.
Soni, Ansari, and Sharma in 2011 proposed the use of a non-linear category set of rules for coronary heart disorder prediction. It is proposed to apply large record gear consisting of Hadoop Distributed File System (HDFS), Map-reduce, and SVM for the prediction of coronary heart disorder with an optimized characteristic set. These paintings turned into research into the use of various record-mining strategies for predicting coronary heart diseases.
Science & Faculty, 2009 counselled predicting coronary heart disorder through the use of record mining and system studying algorithms. Purushottam, Saxena, and Sharma (2016) proposed a green coronary heart disorder prediction machine that uses record mining. Nowadays, record mining performs a crucial function in predicting a couple of diseases. Through the use of record mining strategies, the variety of assessments may be reduced. This is especially true when it comes to predicting coronary heart disease, diabetes, breast cancer, and other diseases.
III. EXISTING SYSTEM
A. Drawbacks of the Prevailing System
User-friendliness could be pretty low. It takes extra time to process activities. The gadget could be very difficult to maintain. It has the possibility of giving inaccurate results.
IV. PROPOSED SYSTEM
Considering the anomalies inside, the prevailing device computerization of the whole hobby is being cautioned after the initial analysis.
It could likely have come approximately so frequently that you or someone of yours need medical doctors' help immediately; however, they may now not be available due to some reasons. The Heart Disease Prediction software is a stop-man or woman assist and online consultation project. Here, we advocate a web software that shall we clients get on-the spot guidance on their coronary heart disease through a sensible tool online. The software program is fed with numerous facts and coronary heart disease is associated with one's facts.
It then tactics purchasers' specific facts to check for numerous infections that might be associated with it. Here we use some smart facts mining techniques to guess the most accurate infection that is probably associated with the patients details. Based on the quit end result, the system automatically shows the quit-end result from specific medical doctors for comparable treatment. The device shall we purchasers to view medical doctors’ details. The device can be utilized in case of emergency.
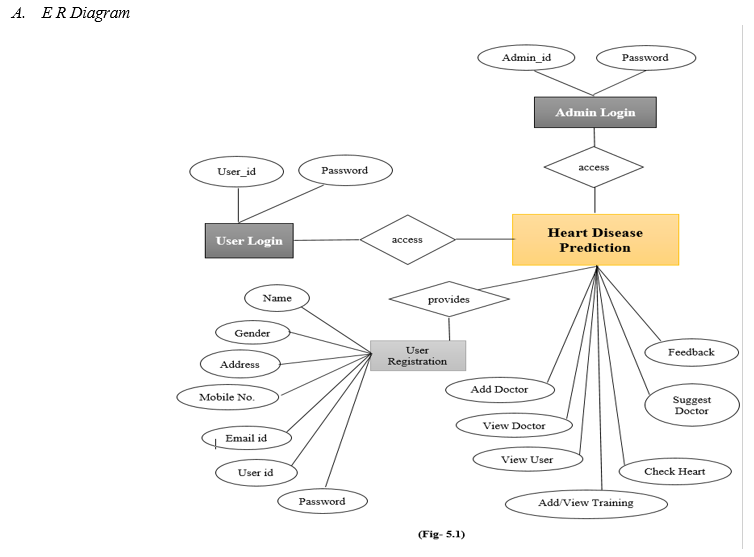
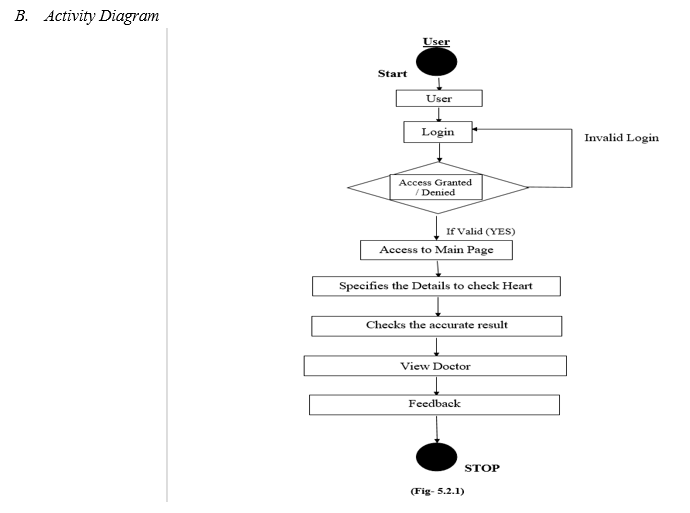
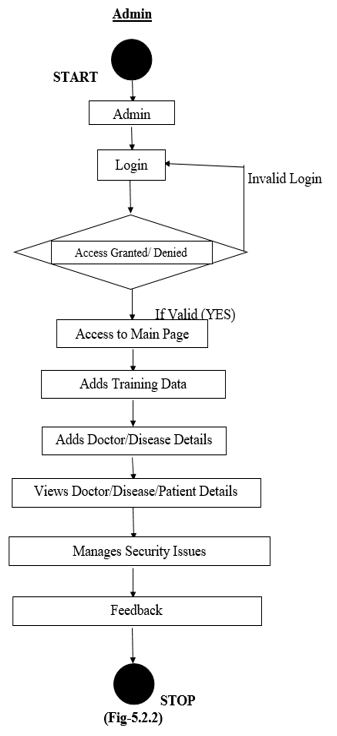
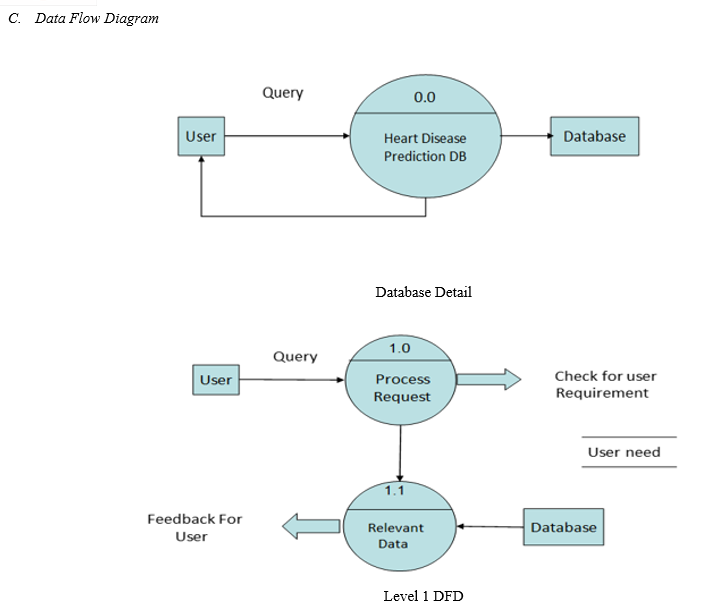
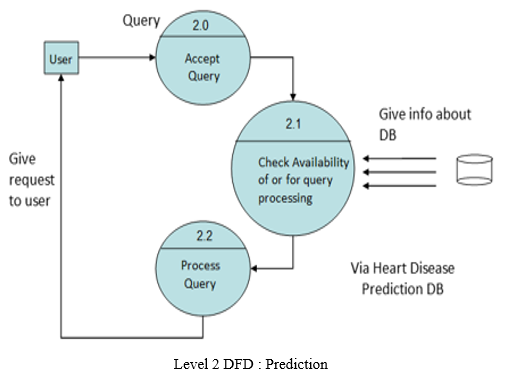
V. DATA FLOW
A Data Flow has the handiest path of flow among symbols. It may also flow in each guideline among a manner and information save to reveal a study earlier than an update. The latter is normally indicated, but through separate arrows seeing that those manifest at extraordinary types. A data flow cannot cross at once and return to the identical manner it leads. There ought to be at least a further manner that handles the data flow produces a few different records glide returns the unique data into the start manner. Data flow to information keep way update (delete or change). Statistics Flow from a statistics save approach retrieve or use.
VI. CONSTRUCTING DFD
Processes have to be named and numbered for easy reference. Each name must be a representative of the system. The direction of the float is from top to bottom and from left to right. Data traditionally go along with the go with the flow from delivery to the holiday spot regardless of the truth that they'll go along with the go with the flow decrease lower back to the deliver. One way to indicate this is to draw prolonged float strains to decrease lower back to delivery. A possible way is to replicate the provided image as a holiday spot. Since its miles are used extra, then as quickly as in the DFD, its miles are marked with a quick diagonal. When a system explodes into reduced degree details, they may be numbered. The names of shops and places are written in capital letters. Process and dataflow names have the number one letter of each portray capitalized. A DFD typically indicates the minimum contents of information saved. Each document store needs to contain all the information elements that float in and out.
Questionnaires want to contain all the information elements that float in and out. Missing interface redundancies and choices are then accounted for regularly via interviews.
VII. TECHNIQUES USED FOR PREDICTION
This study proposes a prediction technique based on KNN and the ID3 set of rules. It includes modules. The initial module encompasses a classifier module, and the second module encompasses a prediction module. In the classifier module, statistics are categorized via the KNN set of rules. All the entered parameters have been determined and are primarily based on the characteristic age; the statistics have been categorized by the use of the KNN set of rules. These categorized statistics are supplied to check statistics. The KNN set of rules gives K-particular cost to each organization; if the age falls close to that organization, it belongs to that respective organization. Otherwise, it is constantly undergoing exams until it reaches its respective organization.
In the prediction, module statistics are examined and expected via the ID3 set of rules. All the instructions have been determined, and every magnificence has been established to locate the changing stage of coronary heart disease. If the check statistics exceed that magnificence cost, the change stage of the affected person is intimated to the affected person and the doctor. In the tree, every sub-node represents the schooling statistics of every magnificence. Using this sub-node structure, the check statistics instructions are established, and the chance price of the affected person is changed in the calculation.
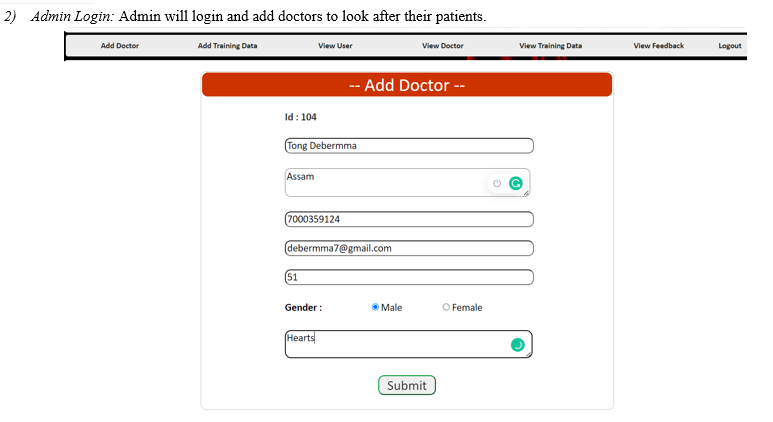
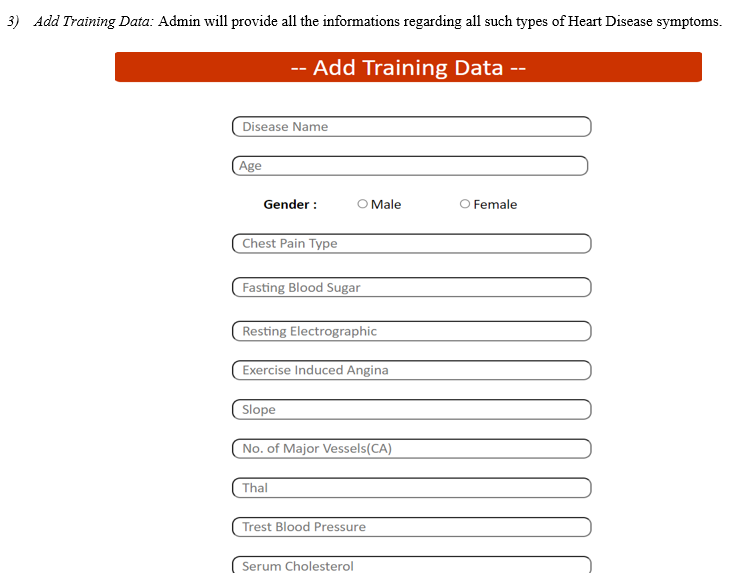
A. Screenshots
- Login Interface
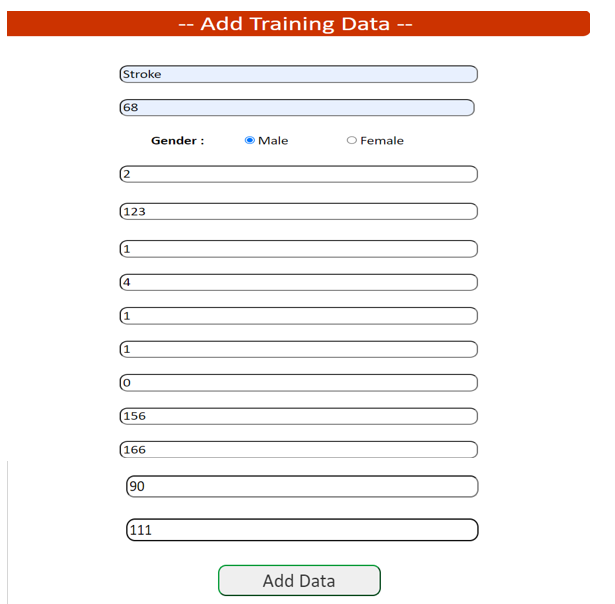
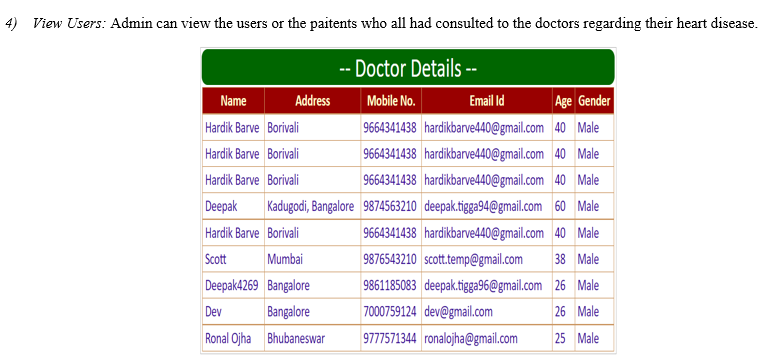
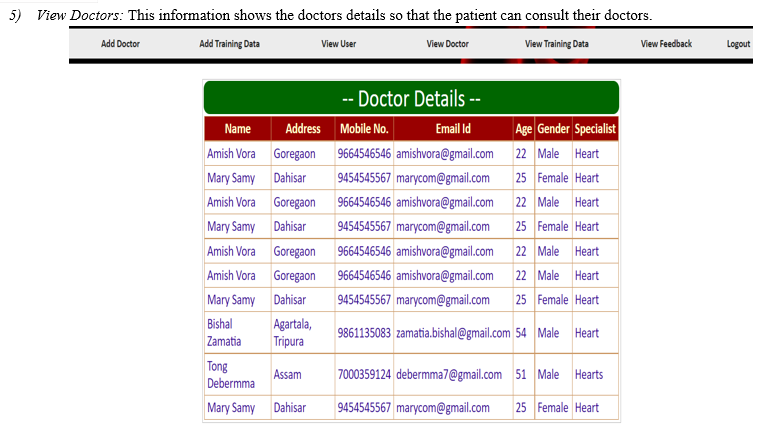

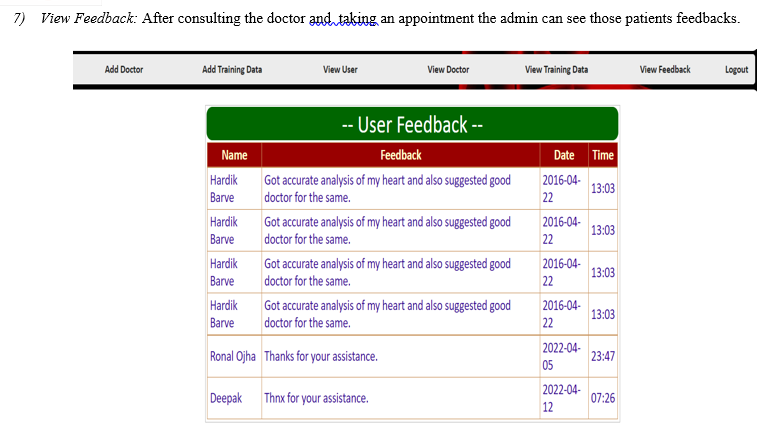
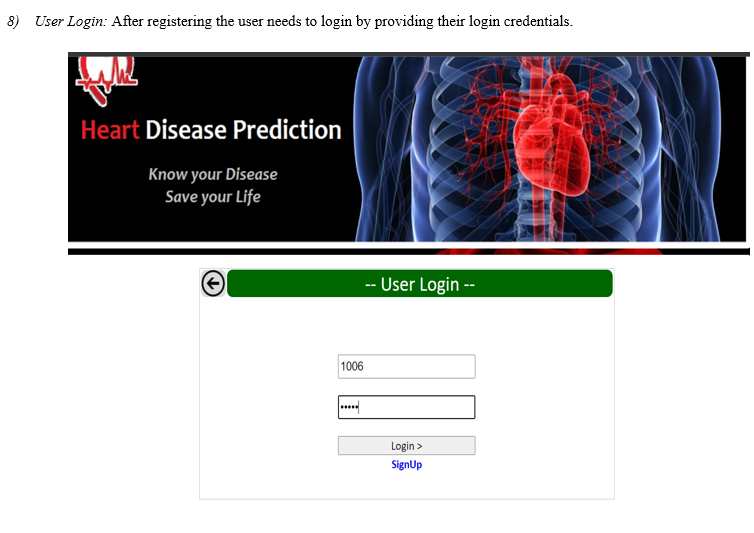
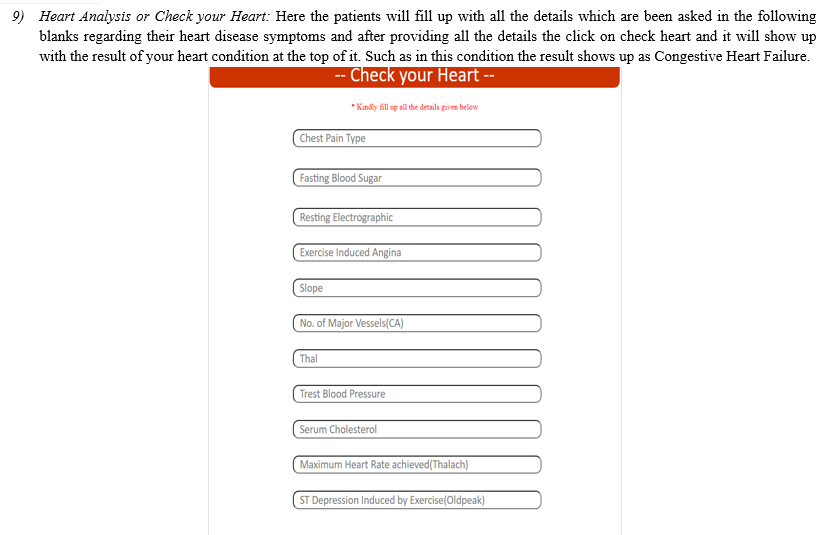

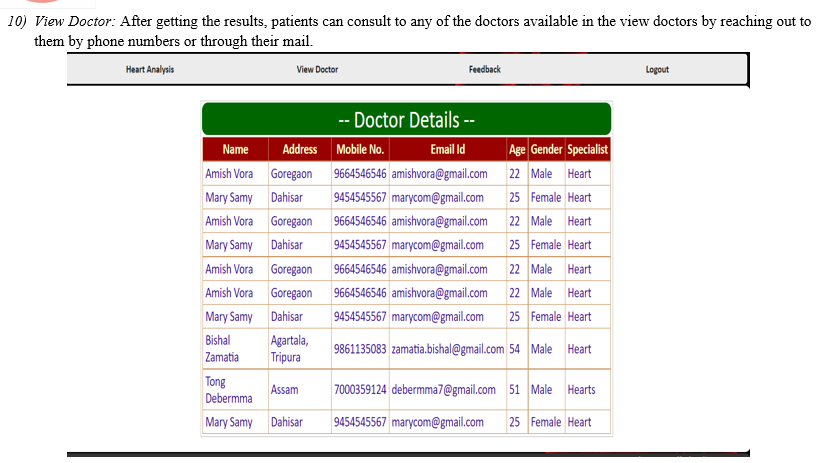
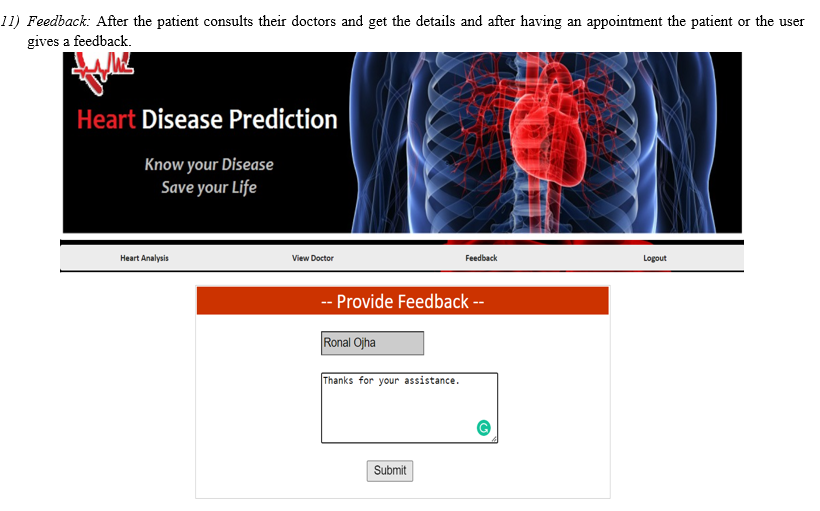
Conclusion
The critical motivation of this paper is to provide an insight into detecting coronary heart disorder risk costs via using statistical mining techniques. Various statistics mining techniques and classifiers are noted in plenty of studies that are probably used for inexperienced and efficacious coronary heart disorder diagnosis. As in step inside the assessment mode, it’s clear that many authors use various generations and distinct numbers of attributes for their studies. Hence, a wonderful generation offers wonderful precision, counting on the huge types of attributes considered. Using KNN and ID3 units of rules, the risk rate of coronary heart disorder was detected and the accuracy level was also supplied for a wonderful wide range of attributes. The use of some distinctive algorithms inside destiny may want to reduce the wide variety of attributes and growth accuracy. Heart Disease Prediction is specified in an easy way. As a result, protection is simple. This software can be used by all patients or their personal families and buddies who need help in an emergency.
References
[1] S.Indhumathi, Mr.G.Vijaybaskar, “Web based health care detection using naive Bayes algorithm”, International Journal of Advanced Research in Computer Engineering & Technology (IJARCET), Volume 4 Issue 9, pp.3532-36, September 2015. [2] Sharma Purushottam, Dr Kanak Saxena, Richa Sharma” Heart Disease Prediction System Evaluation Using C4.5 Rules and Partial Tree” in Springer, Computational Intelligence in Data Mining, 2015, pp-285-294, DOI 10.1007/978-81-322-2731-1_26. [3] Chhikara, S & Sharma,P Data Mining Techniques on Medical Data for Finding Locally Frequent Diseases, I JRASET 2014, PP 396-402 [4] Jyoti Soni, Ujma Ansari, Dipesh Sharma, Sunita Soni “Predictive Data Mining for Medical Diagnosis: An Overview of Heart Disease Prediction” IJCSE Vol. 3 No. 6 June 2011. [5] Dr.S.Seema Shedole, Kumari Deepika, “Predictive analytics to prevent and Control chronic disease”, http://www.researchgate.net/publication/ 316530782, January 2016. [6] Mr. Clala Beyene, Prof. Pooja Kamat, “Survey on Prediction and Analysis the Occurrence of Heart Disease Using Data Mining Technique”, International Journal of Pune and Applied Mathematics, 2018. [7] K. Polaraju, D. Durga Prasad, “Prediction of Heart Disease using Multiple Linear Regression Model”, International Journal of Engineering Development and research Development, ISSN:2321-9939, 2017. [8] Marji Sultana, Afrin Haider, “Heart Disease Prediction using WEKA tool and 10-Fold cross-validation”, The Institute of Electrical and Electronics Engineers, March 2017. [9] Mr.P.Sai Chandrasekhar Reddy, Mr.Puneet Palagi, S.Jaya, “Heart Disease Prediction using ANN Algorithm in Data Mining”, International Journal of Computer Science and Mobile Computing, April 2017, pp.168-172.
Copyright
Copyright © 2022 Dr. S. K. Manju Bargavi, Deepak Kumar Tigga. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET41892
Publish Date : 2022-04-26
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online