

Ijraset Journal For Research in Applied Science and Engineering Technology
Product Fake Reviews Detection with Sentiment Analysis Using Machine Learning
Authors: Prof. Swati Gade, Vaishnavi Harale, Shruti Gaware, Mrunal Badade, Mansi Lohare
DOI Link: 53030
Certificate: View Certificate
Abstract
Recently, Sentiment Analysis (SA) has become one of the most interesting topics in text analysis, due to its promising commercial benefits. One of the main issues facing SA is how to extract emotions inside the opinion, and how to detect fake positive reviews and fake negative reviews from opinion reviews. Moreover, the opinion reviews obtained from users can be classified into positive or negative reviews, which can be used by a consumer to select a product. This paper aims to classify product reviews into groups of positive or negative polarity by using machine learning algorithms. In this study, we analyse online product reviews using SA methods in order to detect fake reviews. SA and text classification methods are applied to a dataset of product reviews. More specifically, we compare five supervised machine learning algorithms: Support Vector Machine (SVM), for sentiment classification of reviews using two different datasets, including product review dataset V2.0 and product reviews dataset V1.0. The measured results of our experiments show that the SVM algorithm outperforms other algorithms, and that it reaches the highest accuracy not only in text classification, but also in detecting fake reviews.
Introduction
I. INTRODUCTION
This project proposes a machine learning approach to identify fake reviews. In addition to the features extraction process of the reviews, this project applies several features engineering to extract various behaviors of the reviewers. Opinion Mining (OM), also known as Sentiment Analysis (SA), is the domain of study that analyzes people’s opinions, evaluations, sentiments, attitudes, appraisals, and emotions towards entities such as services, individuals, issues, topics, and their attributes[1]. “The sentiment is usually formulated as a two-class classification problem, positive and negative”. Sometimes, time is more precious than money, therefore instead of spending time in reading and figuring out the positivity or negativity of a review, we can use automated techniques for Sentiment Analysis.
The basis of SA is determining the polarity of a given text at the document, sentence or aspect level, whether the expressed opinion in a document, a sentence or an entity aspect is positive or negative[2]. More specifically, the goals of SA are to find opinions from reviews and then Classify these opinions based upon polarity. According to, there are three major classifications in SA, namely: document level, sentence level, and aspect level. Hence, it is important to distinguish aspect level of an analysis process that will determine the different tasks of SA [3]. The document level considers that a document is an opinion on its aspect, and it aims to classify an opinion document as a negative or positive opinion. The sentence level using SA aims to setup opinion stated in every sentence.
The documents used in this work are obtained from a dataset of product reviews that have been collected [9]. Then, an SA technique is applied to classify the documents as real positive and real negative reviews or fake positive and fake negative reviews. Fake negative and fake positive reviews by fraudsters who try to play their competitors existing systems can lead to financial gains for them [4].
This, unfortunately, gives strong incentives to write fake reviews that attempt to intentionally mislead readers by providing unfair reviews to several products for the purpose of damaging their reputation. Detecting such fake reviews is a significant challenge. For example, fake consumer reviews in an e-commerce sector are not only affecting individual consumers but also corrupt purchaser’s confidence in online shopping. Our work is mainly directed to SA at the document level, more specifically, on product reviews dataset.
Machine learning techniques and SA methods are expected to have a major positive effect, especially for the detection processes of fake reviews in Product reviews, e-commerce. The conducted experiments have shown the accuracy of results through sentiment classification algorithms. In both cases (product reviews dataset V2.0 and product reviews datasetV1.0), we have found that SVM is more accurate than other methods.
The main contributions of this study are summarized as follows:
- Using the Weka tool [6], we compare different sentiment classification algorithms which are used to classify the product reviews dataset into fake and real reviews.
- We apply the sentiment classification algorithms using two different datasets with stopwords. We realized that using the stopwords method is more efficient than without stopwords not only in text categorization, but also to detection of fake reviews.
- We perform several analysis and tests to find the learning algorithm in terms of accuracy.
The rest of this paper is organized as follows. Section II presents the related works. Section III shows the methodology and finally, Section IV presents the conclusion and future works.
II. RELATED WORKS
Our study employs statistical methods to evaluate the performance of detection mechanism for fake reviews and evaluate the accuracy of this detection. Hence, we present our literature review on studies that applied statistical methods.
A. Sentiment Analysis
Sentiment analysis also referred to as opinion mining, is an approach to natural language processing (NLP) that identifies the emotional tone behind a body of text. This is a popular way for organizations to determine and categorize opinions about a product, service, or idea [10].
B. Textual reviews
Most of the available reputation models depend on numeric data available in different fields; an example is ratings in e- commerce. Also, most of the reputation models focus only on the overall ratings of products without considering the reviews which are provided by customers. On the other hand, most websites allow consumers to add textual reviews to provide a detailed opinion about the product [11].
These reviews are available for customers to read. Also, customers are increasingly depending on reviews rather than on ratings. Reputation models can use SA methods to extract users’ opinions and use this data in the Reputation system. This information may include consumers’ opinions about different features
C. Detecting Fake Reviews Using Machine Learning
Filter and identification of fake reviews have substantial significance. Moraes et al. proposed a technique for categorizing a single topic textual review.
A sentiment classified document level is applied for stating a negative or positive sentiment. Supervised learning methods are composed of two phases, namely selection and extraction of reviews utilizing learning models such as SVM.
Extracting the best and most accurate approach and simultaneously categorizing the customers written reviews text into negative or positive opinions has attracted attention as a major research field. Although it is still in an introductory phase, there has been a lot of work related to several languages. Our work used several supervised learning algorithms such as SVM for Sentiment Classification of text to detect fake reviews.
D. Classification Algorithms
Comparative studies on classification algorithms to verify the best method for detecting fake reviews using different datasets such as News Group dataset, text documents, and product reviews dataset. It also proves that NB and distributed keyword vectors (DKV) are accurate without detecting fake reviews.
While finds that NB is accurate and a better choice, but it is not oriented for detecting fake reviews. Using the same datasets, finds that SVM is accurate with stop Words method, but it does not focus on detecting fake reviews, while finds that SVM is only accurate without using stop words method, and also without detecting fake reviews.
III. METHODOLOGY
To accomplish our goal, we analyze a dataset of product reviews using the Weka tool for text classification. In the proposed methodology, as shown in Figure 1, we follow some steps that are involved in SA using the approaches described below.
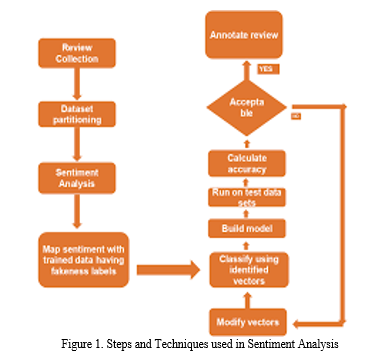
IV. IMPLEMENTATION
A. Step 1: Reviews collection
To provide an exhaustive study of machine learning algorithms, the experiment is based on analyzing the sentiment value of the standard dataset. We have used the original dataset of the product reviews to test our methods of reviews classification. The dataset is available and has been used in, which is frequently conceded as the standard gold dataset for the researchers working in the field of the Sentiment Analysis. The first dataset is known as product reviews dataset V2.0 which consists of 2000 product reviews out of which 1000 reviews are positive, and 1000 reviews are negative. The second dataset is known as product reviews dataset V1.0, which consists of total 1400 product reviews, 700 of which are positive and 700 of which are negative. A summary of the two datasets collected is described in Table II.
TABLE II. DESCRIPTION OF DATASET
|
Dataset |
Content of the Dataset |
|
Product Reviews Dataset V2.0 |
2000 Reviews (1000+ & 1000-) |
|
Product Reviews Dataset V1.0 |
1400 Reviews (700+ & 700-) |
B. Step 2: Data preprocessing
The preprocessing phase includes two preliminary operations, shown in Figure 1, that help in transforming the data before the actual SA task. Data preprocessing plays a significant role in many supervised learning algorithms. We divided data preprocessing as follows:
- Attribute Selection: Removing the poorly describing attributes can significantly increase the classification accuracy, in order to maintain better classification accuracy, because not all attributes are relevant to the classification work, and the irrelevant attributes can decrease the performance of the used analysis algorithms, an attribute selection scheme was used for training the classifier.
C. Step 3: Feature Selection
Feature selection is an approach which is used to identify a subset of features which are mostly related to the target model, and the goal of feature selection is to increase the level of accuracy. In this study, we implemented five feature selection methods widely used for the classification task of SA with Stop words methods. The results differ from one method to the other. For example, in our analysis of Review datasets, we found that the use of SVM algorithm is proved to be more accurate in the classification task.
D. Step 4: Sentiment Classification algorithms
In this step, we will use sentiment classification algorithms, and they have been applied in many domains such as commerce, medicine, media, biology, etc. There are many different techniques in classification method like SVM, Naïve Bayes Neural Networks, and Genetic Algorithm. In this study, we will use five popular supervised classifiers: SVM, Naïve Bayes algorithms.
- Naïve Bayes (NB): The NB classifier is a basic probabilistic classifier based on applying Bayes' theorem. The NB calculates a set of probabilities by combinations of values in a given dataset. Also, the NB classifier has fast decision-making process.
- Support Vector Machine (SVM): SVM in machine learning is a supervised learning model with the related learning algorithm, which examines data and identifies patterns, which is used for regression and classification analysis. Recently, many classification algorithms have been proposed, but SVM is still one of the most widely and most popular used classifiers.
E. Step 5: Detection Processes
After training, the next step is to predict the output of the model on the testing dataset, and then a confusion matrix is generated which classifies the reviews as positive or negative. The results involve the following attributes:
- True Positive: Real Positive Reviews in the testing data, which are correctly classified by the model as Positive (P).
- False Positive: Fake Positive Reviews in the testing data, which are incorrectly classified by the model as Positive (P).
- True Negative: Real Negative Reviews in the testing data, which are correctly classified by the model as Negative (N).
- False Negative: Fake Negative Reviews in the testing data, which are incorrectly classified by the model as Negative (N).
True negative (TN) are events which are real and are effectively labeled as real, True Positive (TP) are events which are fake and are effectively labeled as fake. Respectively, False Positives (FP) refers to Real events being classified as fakes; False Negatives (FN) is fake events incorrectly classified as Real events. The confusion matrix, (1)-(6) shows numerical parameters that could be applied following measures to evaluate the Detection Process (DP) performance. In Table III, the confusion matrix shows the counts of real and fake predictions obtained with known data and for each algorithm used in this study there is a different performance evaluation and confusion matrix.
The confusion matrix is a very important part of our study because we can classify the reviews from datasets whether they are fake or real reviews. The confusion matrix is applied to each of the five algorithms discussed in Step 4.
F. Step 6: Comparison of results
In this step, we compared the different accuracy provided by the dataset of product reviews with various classification algorithms and identified the most significant classification algorithm for detecting Fake positive and negative Reviews[8].
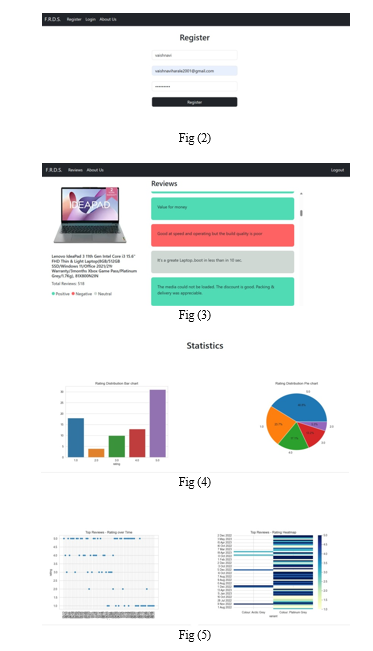
VI. ACKNOWLEDGMENT
We take this opportunity to thank the teachers and senior authorities whose constant encouragement made it possible for us to take up a challenge of doing this project. We express our deepest sense of gratitude towards our Hon’ble Head of department DR. R. V. PATIL for giving permission to use the college resources and his constant encouragement for this work.
We are grateful to Prof. S. P. Gade for her technical support, valuable guidance, encouragement and consistent help without which it would have been difficult for us to complete this project work. She is a constant source of information to us. We consider ourselves fortunate to work under the guidance of such an eminent personality.
Last but not the least; we are thankful to our entire staff of COMPUTER ENGINEERING DEPARTMENT for their timely help and the guidance at various stages of the progress of the project work.
Conclusion
In this paper, we proposed several methods to analyze a dataset of reviews. We also presented sentiment classification algorithms to apply a supervised learning of the reviews located in two different datasets. Our experimental approaches studied the accuracy of all sentiment classification algorithms, and how to determine which algorithm is more accurate. Furthermore, we were able to detect fake positive reviews and fake negative reviews through detection processes. Five supervised learning algorithms to classifying Sentiment of our datasets have been compared in this paper: SVM. Using the accuracy analysis for these five techniques, we found that SVM algorithm is the most accurate for correctly classifying the views datasets, i.e., V2.0 and V1.0. Also, detection processes for fake positive reviews and fake negative reviews depend on the best method that is used in this study.
References
[1] B. Liu, “Sentiment analysis and opinion mining,” Synthesis lectures on human language technologies, vol. 5, no. 1, 2012, and pp.1–167. [2] W. Medhat, A. Hassan, and H. Korashy, “Sentiment analysis algorithms and applications: A survey,” Ain Shams Engineering Journal, vol. 5, no. 4, 2014, pp. 1093– 1113. [3] B. Pang, L. Lee, and S. Vaithyanathan, “Thumbs up? Sentiment classification using machine learning techniques,” in Proceedings of EMNLP, 2002, pp. 79–86. [4] J. Malbon, “Taking fake online consumer reviews seriously,” Journal of Consumer Policy, vol. 36, no. 2, 2013, pp. 139–157. [5] R. Xia, C. Zong, and S. Li, “Ensemble of feature sets and classification algorithms for sentiment classification,” Information Sciences, vol. 181, no. 6, 2011, pp. 1138– 1152. [6] T. Barbu, “SVM-based human cell detection technique using histograms of oriented gradients,” cell, vol. 4, 2012, p. 11. [7] G. Esposito, LP-type methods for Optimal Transductive Support Vector Machines. Gennaro Esposito, PhD, 2014, vol [8] P. Kalaivani and K. L. Shunmuganathan, \"Sentiment classification of product reviews by supervised machine learning approaches,\" Indian Journal of Computer Science and Engineering, vol. 4, no. 4, pp. 285- 292, 2013. [9] B. Pang and L. Lee, “A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts,” in Proceedings of the 42nd annual meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2004. [10] Python Machine Learning and Deep Learning with Python, Scikit-learn, and TensorFlow 2 By Sebastian Raschka, Vahid Mirjalili · 2019. [11] Deep Learning books I am Good fellow, Yoshua Bengio, Aaron Courville 2016
Copyright
Copyright © 2023 Prof. Swati Gade, Vaishnavi Harale, Shruti Gaware, Mrunal Badade, Mansi Lohare. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET53030
Publish Date : 2023-05-25
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online