

Ijraset Journal For Research in Applied Science and Engineering Technology
Product Ingredient Analysis
Authors: Harshit Gautam, Vishal Singh, Deepak Kumar, Sukhpreet Kaur
DOI Link: https://doi.org/10.22214/ijraset.2022.43745
Certificate: View Certificate
Abstract
Whenever I want to try something new, it is very difficult to choose. Sometimes it\'s scary because new things I\'ve never tried end up giving me a skin problem. We know that the information we need is behind each product, but it is really difficult to define that ingredient list unless you are a pharmacist. You may relate to this situation. So instead of buying and trusting the best, why not use data science to help us predict what might be right? We will create a content-based recommendation system where the content will be the chemical components of cosmetics. Specifically, we will process a list of 1472 cosmetic ingredients in sephora using WORD EMBEDDING, and visualize the similarity of the ingredient using a machine learning method called t-SNE and a collaborative library called Bokeh. In a world focused on the need to sell a large growing number of goods, quality, visual appearance, texture, taste, taste etc. it becomes an important factor in supporting the development of the global economy. As a result, different types of food additives have been developed and are still being developed and used to achieve those purposes. Next, the purpose of this paper is to introduce the design and implementation of a new software package for embedded systems that can support the customer in the food purchasing system. The advanced software package works on the platform and uses the cloud optical character (NLP) MACHINE learning algorithm. The details related to the product you are interested in and provided on request to customers are: name and product ingredients code, risks associated with each food supplement, source of each food component, soap, limit of daily use. and side effects, dietary restrictions etc.
Introduction
I. INTRODUCTION
Whenever something new is a cosmetic item, it becomes very difficult to choose. It is actually more than a challenge. Sometimes it's scary because new things I've never tried end up in a skin problem. We know that the information we need is behind each product, but it is really difficult to define those lists of ingredients unless you are a pharmacist. So instead of buying and trusting the best, why not use data science to help us predict which products might fit well? In this notebook, we will create a product-based recommendation system where the ‘product’ will be the chemical components of cosmetics.

II. PROCESS/METHOD
A. Focus on One Category of Product and One Type of Skin
Product categories in our data (moisturizers, detergents, face mask, eye cream and sun protection) and there are five different skin types (combination, dry, normal, oily and sensitive) .Because people have different product needs and different skin types. , let's improve our workflow so that the output (T-SNE model and display of that model) is customized. An example in the book, let’s focus on moisturizer for those with dry skin by filtering data appropriately.
B. COMMENTARY Ingredients
In order to achieve our ultimate goal of comparing ingredients in each product, we first need to do some pre-processing tasks and keep the exact names in the ingredients list for each product. The first step will be to make tokens from the list of ingredients in the INGREDIENTS column. After splitting them into tokens, we will create a binary word wallet. After that we will create a dictionary token, ingredients_idx
C. Launching Document-Term Matrix (DTM)
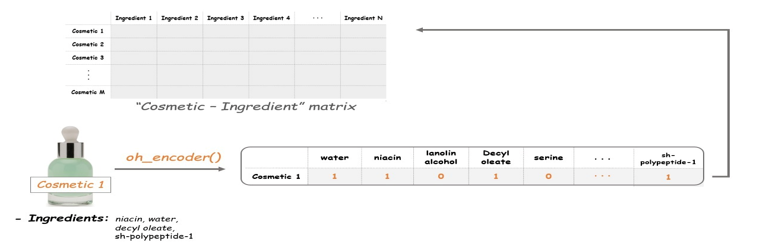
The next step is to create a document-term matrix (DTM) .here each cosematics product will match the document, and each chemical composition will match the name, which means we can think of it as a "cosmetic-ingredient" matrix.,The length of the matrix of the total amount of cosmetic product in the data. The width of the matrix is ??the sum of the total number of ingredients.after starting this matrix.

D. Counter Function
Before we complete the matrix, let's create a token count function (i.e., a list of ingredients) for each line. Our final goal is to fill the matrix by 0 to 1: if the ingredient is cosmetics, the value is 1. Otherwise, it is always 0, the names of this function, oh_encoder, will be clear next.
E. Cosmetics-Ingredient Matrix
Now we’ll the oh_encoder() function to the tokens in corpus and set the values at each row matrix. So the result will tell us what ingredients each item is composed of for example, if a cosmetics item contain water,niacin,decyl aleate and sh-polypeptide-1 the outcome of this item
III. PLATFORM AND TECHNOLOGY
A. Size Reduction By T-SNE
The size of the existing matrix is ??(190,2233), which means that there are 2233 elements in our data. Visually, we must reduce this to two dimensions. We will use T-SNE to reduce data size.
T-distributed Stochastic Neighbor Embedding (t-SNE) is an indirect size reduction method - well-suited or embedded high-resolution data to visualize a low-density area - two or three sizes, in particular, this process can reduce size. of data while maintaining similarity within the model. this enables us to conspire in the interconnected plane, which can be said to be vectorizing. All of these cosmetic items in our data will be displayed in two-dimensional links, as distances between points will reflect similarities between objects.
B. Let's Talk About Things About Bokeh
Now we are ready to start building our building. With T-SNE values, we can arrange all our items on an integrated aircraft. And the coolest part here is that it will also show us the name, type, price and quality of each item. Let’s make a bokeh of a scatter plot and add a navigation tool at the top to reflect that information. Note that we want to display the structure and we will make some addition
Why not add a Hover tool? The navigation tool allows us to check the information of each item whenever the cursor is above the glyph. we will add tips for each product name, product, price, and, level (ratings)
Mapping cosmetic items
It's finally show time! let's see what the map 'made' looks like. Now what do the axes mean here? t-SNE axes are a visual aid for arranging high-resolution data instead of low-magnitude data. Therefore, it is not desirable to translate the t-sne structure in bulk.
Instead, we can find in this map the distance between the points (which objects are closed and partially). Where the distance between the two objects is very similar to the shape they have, so it is the same as their shape. So this allows us to compare an object without having a chemical background
C. Comparing The Two Products
With so many cosmetics and ingredients, the plot doesn’t have so many obvious patterns that simple T-SNE sites can have our sites that need to dig something to get details but that’s okay!
Say we enjoyed a particular product, we are more likely to enjoy another product like chemical composition.say we enjoy the amorepacific compact color pillow Broad Spectrum spf 50+ we can find this product in the building and see that the same product (S0 exists .and it turns out that it is! we look at the far left points oh = n structure, we see the pillow of LANEIGE'S BB Hydra Radiance SPF 50 actually overlaps with the Amorepacific product.
It is not perfect, but it is useful. In real life we ??can use our little inrident-based complimentary engine to help us make informed choices about buying cosmetics.
Conclusion
The technological development achieved in the last decade has led to an overwhelming progress for different types of software technologies. This revolution offers to all those who are interested, all the resources that are necessary to develop professionally and develop innovative applications such as the one presented in this project.
References
[1] Gatys, Ecker, Alexander S.; Bethge, Matthias (26 August 2015). \"A Neural Algorithm of Artistic Style\". [2] Bethge, Matthias; Ecker, Alexander S.; Gatys, Leon A. (2016). \"Image Style Transfer Using Convolutional Neural Networks\" [3] P. Rosin and J. Collomosse, Image and video-based artistic stylisation. Springer Science & Business Media, 2012. [4] Golnaz Ghiasi, Honglak Lee ( August 27 2017). \"Exploring the structure of a real-time, arbitrary neural artistic stylization network\" [5] Yellow Labrador Looking, from Wikimedia Commons by Elf. License CC BY-SA 3.0 [6] Wassily Kandinsky\'s Composition 7 [7] Bethge, Matthias; Ecker, Alexander S.; Gatys, Leon A. et.al 2016
Copyright
Copyright © 2022 Harshit Gautam, Vishal Singh, Deepak Kumar, Sukhpreet Kaur. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET43745
Publish Date : 2022-06-02
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online