

Ijraset Journal For Research in Applied Science and Engineering Technology
Prognosis of Determined Cardiovascular Illnesses using Machine Learning Techniques
Authors: Varkala Satheesh Kumar, G Nithish Chandra, S Vishwanath
DOI Link: https://doi.org/10.22214/ijraset.2023.53036
Certificate: View Certificate
Abstract
Prognostic of determined cardiovascular illness is one similar perpetration of machine literacy algorithms in the field of healthcare. Medical installations need to be advanced so that better opinions for patient opinion and treatment options can be made. Machine literacy in healthcare aids humans to reuse huge and complex medical datasets and also assaying them into clinical perceptivity. This can further be used by croakers in furnishing medical care. Hence machine literacy when enforced in healthcare can lead to increased case satisfaction. This design focuses on enforcing functionalities of machine literacy in healthcare in a single system. rather of opinion, when a complaint vaticination is enforced using certain machine learning prophetic algorithms also healthcare can be made smart. This proposed design uses the Machine Learning Algorithm K-Fold cross-confirmation algorithm and other libraries to make the design. The favored language is Python due to its total libraries and easy-to-use syntax. In this design, we trained Machine Learning models with colorful bracket algorithms and chose the stylish model which has good delicacy and perfection and overcomes the two main problems they\'re overfitting and underfitting similar that they\'ve low friction and bias.
Introduction
I. INTRODUCTION
Cardiovascular illnesses (CVI) are a group of diseases that affect the heart and blood vessels and are the leading cause of morbidity and mortality worldwide. Early detection and accurate prognosis of CVI are crucial for effective management and prevention of disease progression. Prognosis is the process of predicting the likely outcome of a disease, and it is widely used to predict the risk of future events, such as death or hospitalization, for patients with CVI. Traditional prognostic models use clinical and demographic factors to predict the risk of future events, but these models have limited accuracy and fail to capture the complex relationships between various factors. In recent years, machine learning (ML) has emerged as a promising approach for the prognosis of CVI. ML is a subfield of artificial intelligence that allows computers to learn from data and make predictions. ML algorithms can automatically identify relevant features and build a predictive model without the need for explicit modeling of the underlying relationships. The use of ML for the prognosis of CVI has the potential to improve the accuracy of prognostic models and enable personalized treatment plans for patients. The objective of this study is to propose an ML-based approach for the prognosis of determined CVI using clinical and imaging data. The proposed approach aims to improve the accuracy of CVI prognosis by overcoming the limitations of traditional prognostic models based on clinical and demographic factors. Specifically, the objectives of this study are to identify relevant clinical and imaging features that are predictive of the prognosis of CVI using feature selection techniques, develop an ML-based predictive model that integrates the identified features and accurately predicts the risk of future events, validate the performance of the proposed approach using a large and diverse dataset of patients with determined CVI, and evaluate the clinical utility of the proposed approach and its potential to enable personalized treatment plans for patients with determined CVI. The ultimate goal of this study is to provide clinicians with a reliable and accurate tool for the prognosis of CVI that can aid in making informed decisions about patient care and contribute to improving patient outcomes. The use of ML-based approaches in the prognosis of CVI has significant potential for advancing the field of cardiology and improving public health outcomes.
II. LITERATURE
In the time 2015, Authors Purushottam, Prof.(Dr.) Kanak Saxena and Richa Sharma have introduced Effective Heart Disease Prediction System using Decision Tree. In this study, we've designed a system that can efficiently discover the rules to prognosticate the threat position of cases grounded on the given parameter about algorithms for Data Mining problems.
In the time 2018, Authors Gihun Joo, Yeongjin Song, Hyeonseung, and Junbeom Park introduced the Clinical Recrimination of Machine Learning in Predicting the circumstance of Cardiovascular Disease Using Big Data.
In this study, we developed ML- grounded vaticination models for CVD similar to atrial fibrillation ( AF), coronary roadway complaint( CAD), heart failure( HF), and strokes by assaying the Medical Check-up Cohort DB ver1.0 handed by Korean National Health Insurance Service( 15),( 16) (NHIS-2016-2-263).
Prediction Using mongrel Machine Learning ways the conclusion is about relating the processing of raw healthcare data of heart information will help in
the long-term saving of mortal lives and early discovery of abnormalities in heart conditions. Machine literacy was used in this work to reuse raw data and give a new and new perceptiveness toward heart complaints. In the time 2020, Authors LiYang, HaibinWu, Xiaoqing Jin, PinpinZheng, Shiyun Hu, XiaolingXu, WeiYu & JingYan introduced a Study of a cardiovascular complaint vaticination model grounded on arbitrary timber in eastern China. farther population- grounded studies of the CVD vaticination model proposed in this study with further population, longer follow-up time, covering further places in China with external confirmation is demanded.
There is a growing body of literature on the use of machine learning (ML) for the prognosis of cardiovascular diseases (CVDs). In this section, we will review some of the existing studies and systems related to the use of ML for the prognosis of CVDs. One study by Khan et al. (2020) used a machine learning algorithm to predict the 10-year risk of atherosclerotic cardiovascular disease (ASCVD) using data from the Multi-Ethnic Study of Atherosclerosis (MESA). The algorithm used demographic, clinical, and laboratory data to predict ASCVD risk, and the results showed that the algorithm outperformed traditional risk prediction models in terms of accuracy and discrimination. Another study by Elshawi et al. (2020) used machine learning to predict the incidence of major adverse cardiovascular events (MACE) in patients with type 2 diabetes mellitus (T2DM) and established cardiovascular disease (CVD). The algorithm used demographic, clinical, and laboratory data to predict the risk of MACE, and the results showed that the algorithm had good discrimination and calibration.
III. METHODOLOGY
The Prognosis of determined cardiovascular illnesses (CVI) using machine learning (ML) is an important area of research aimed at improving the accuracy of prognosis for patients with CVI and enabling personalized treatment plans. This project aims to propose an ML-based approach for the prognosis of determined CVI using clinical and imaging data. The proposed approach aims to improve the accuracy of CVI prognosis by overcoming the limitations of traditional prognostic models based on clinical and demographic factors. The project comprises several stages, including data collection, preprocessing, feature selection, model development, validation, and clinical utility evaluation. Each stage is essential for the successful development of the proposed approach.
- Data Collection: Data collection is the first stage of the project, and it involves collecting clinical and imaging data from patients with determined CVI. The data collected includes demographic information, clinical history, medication history, and imaging data such as echocardiography, electrocardiography, and angiography. The data collected is crucial for the development of the ML-based predictive model.
- Preprocessing: After data collection, the data undergoes preprocessing to ensure that it is accurate and complete. Preprocessing involves removing missing or incorrect data, normalizing the data, and standardizing the data to ensure that it is in a consistent format. The processed data is then used for feature selection and model development.
- Feature Selection: Feature selection involves selecting relevant clinical and imaging features that are predictive of the prognosis of CVI using feature selection techniques. Feature selection techniques include statistical methods, such as t-tests and correlation analysis, and ML-based methods, such as recursive feature elimination and Lasso regression. The selected features should be relevant, informative, and non-redundant to ensure the accuracy of the model.
- Model Development: Model development involves developing an ML-based predictive model that integrates the identified features and accurately predicts the risk of future events, such as death or hospitalization, for patients with determined CVI. ML algorithms used in the development of the model include decision trees, random forests, support vector machines, artificial neural networks, and deep learning algorithms. The selected algorithm should be appropriate for the data and have high accuracy, sensitivity, and specificity.
- Validation: Model validation involves validating the performance of the proposed approach using a large and diverse dataset of patients with determined CVI and comparing it with traditional prognostic models. Model performance is evaluated using metrics such as accuracy, sensitivity, specificity, precision, and area under the curve. The validation dataset should be independent of the training dataset and should represent the population of interest.
- Clinical Utility Evaluation: The clinical utility evaluation involves evaluating the clinical utility of the proposed approach and its potential to enable personalized treatment plans for patients with determined CVI. The proposed approach should be easy to use, and interpretable, and should provide actionable insights that can aid in making informed decisions about patient care. The proposed approach should also have a positive impact on patient outcomes, such as reducing mortality, and hospitalization, and improving quality of life. Overall, the project aims to develop an ML-based approach for the prognosis of determined CVI that overcomes the limitations of traditional prognostic models and improves the accuracy of CVI prognosis. The proposed approach has the potential to enable personalized treatment plans for patients with determined CVI and contribute to improving patient outcomes. The use of ML-based approaches in the prognosis of CVI has significant potential for advancing the field of cardiology and improving public health outcomes.
IV. SYSTEM DESIGN
System design is the transition from a user-acquainted document to a programmer or database labor force. The design is a result, specifying how to approach the creation of a new system. This is composed of several ways. It provides the understanding and procedural details necessary for administering the system recommended in the feasibility study. Designing goes through logical and physical stages of development. Logical design reviews the present physical system, prepares input and affair specifications, and details of the performance plan, and prepares a logical design walkthrough. The database tables are designed by assaying functions involved in the system and the format of the fields is also designed. The fields in the database tables should define their part in the system. The gratuitous fields should be avoided because it affects the storage areas of the system. also, in the input and affair screen design, the design should be made user-friendly. The menu should be precise and compact.
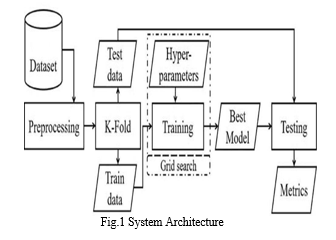
A. Flow Of The System
- The Machine Learning pipeline starts with Data collection, all our Datasets are taken from Kaggle and after importing Datasets, every dataset is checked for null values, improper values, standard scaling, normalization of features, removing correlated attributes, and outliers. for every HTTP request detected as sensitive by the classifier.
- To remove data leakage, we use K-Fold cross-validation which makes k-number training and testing clusters.
- After splitting of the data into trained data and the test data, trained data will undergo some operations with the algorithms.
- Here we use K-Neighbour classification, Random Forest classification, and Logistic Regression to train data for best accuracy.
B. Software Design
In designing the software, the following principles are followed
- Modularity and partitioning software are designed in such a way that; each system should correspond to the scale of modules and serve to partition into a separate function.
- Coupling modules should have little reliance on the other modules of a system.
- Cohesion modules should carry out the operations in a single processing function.
- Shared use avoids duplication by allowing a single module which is called by another, that needs the function it provides.
C. Input Design
Considering the conditions, procedures are espoused to collect the necessary input data in the utmost efficiently designed format. The input design has to be done keeping in view that, the commerce of the stoner with the system should be in the most effective and simplified way. Also, the necessary measures are taken for the following
- Controlling the quantum of input
- Avoid unauthorized access to the druggies
- barring the redundant way
- Keeping the process simple
- At this stage the input forms and defenses are designed
D. Output Design
All the defenses of the system are designed with a view to give the stoner easy operations in a simpler and more effective way, with minimal crucial strokes possible. Important information is emphasized on the screen. nearly every screen is handed with no error and important dispatches and option selection facilitates. Emphasis is given to faster processing and speedy deals between the defenses. Each screen is assigned to make it as important stoner friendly as possible by using interactive procedures.
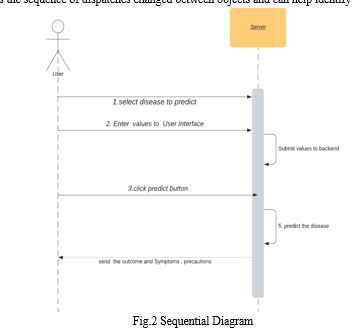
E. UML Diagram
A sequence illustration is a type of UML (Unified Modeling Language) illustration that models the relations between objects in a software system. It shows the sequence of dispatches changed between objects and can help identify implicit performance issues.
V. IMPLEMENTATION AND RESULTS
In supervised knowledge, categorical variables are modeled in type. Logistic regression is a fairly easy but important machine-learning algorithm that uses a logistic function to model a double response variable. Since our response variable “target” is a categorical variable that has two levels0 and 1, we can apply a logistic regression algorithm. The KNeighbor algorithm(k- NN) is an anon-parametric system first developed by Evelyn Fix and Joseph Hodges in 1951, and subsequently expanded by Thomas Cover. It's used for type and Regression. In both cases, the input consists of the k closest training samples in the dataset. The affair depends on whether k- NN is used for type or regression. The arbitrary timber is a type of algorithm conforming to multitudinous opinions trees. It uses bagging and point randomness when erecting each individual tree to try to produce an uncorrelated timber of trees whose prophecy by the commission is more accurate than that of any individual tree.

Conclusion
It is designed to solve the issues of existing systems. We have used Machine Learning concepts for building models. The system performs satisfactorily in different variations of inputs. In the future, this system needs updating because it is certain only for predicting diseases but in the future, we must implement a specified button to book appointments with doctors seamlessly in the application. Machine learning (ML) has shown great promise in predicting the prognosis of various cardiovascular illnesses. ML algorithms can analyze large datasets and identify patterns that can help clinicians make better decisions regarding patient care. For example, ML models can predict the likelihood of a patient having a future cardiovascular event, such as a heart attack or stroke, based on their medical history, lifestyle factors, and other relevant data. These predictions can help clinicians tailor treatment plans and interventions to reduce the risk of such events occurring. Additionally, ML algorithms can aid in the early detection and diagnosis of cardiovascular illnesses, allowing for earlier interventions and improved outcomes for patients. Overall, the use of ML in predicting the prognosis of cardiovascular illnesses has the potential to improve patient outcomes and reduce healthcare costs. However, it is important to note that these models are not perfect and should be used in conjunction with clinical expertise and judgment. Further research is also needed to improve the accuracy and generalizability of these models.
References
[1] National Heart Lung and Blood Institute Fact Book, Fiscal Year 2006. Bethesda, Md National Heart Lung and Blood Institute, National Institutes of Health; 2006. ( 12 April 2011). Last penetrated at HTTP// www.nhlbi.nih. gov/about/factbook-06/toc.htm on. [2] Hayden M, Pignone M, Phillips C, et al. Aspirin for the primary forestallment of cardiovascular events is a summary of the substantiation for theU.S. Preventive Services Task Force. Ann Intern Med. 2002; 136( 2) 161 – 72 [3] Pearson TA, Blair SN, Daniels SR, et al. AHA Guidelines for Primary Prevention of Cardiovascular Disease and Stroke 2002 Update. Rotation. 2002; 106( 3) 388 – 91 [4] Chatellier G, Blinowska A, Menard J, et al. Do croakers estimate reliably the cardiovascular threat of hypertensive cases? Medinfo. 1995; 8( Pt 2) 876 – 9. [5] Grover SA, Lowensteyn I, Esrey KL, et al. Do croakers directly assess the coronary threat in their cases? primary results of the Coronary Health Assessment Study. BMJ. 1995; 310( 6985) 975 – 8. [6] Remote Health Monitoring Outcome Success Prediction Using Baseline and First Month Intervention Data | IEEE Journals & Magazine | IEEE Xplore [7] Efficient heart disease prediction system using decision tree | IEEE Conference Publication | IEEE Xplor [8] API Reference - Streamlit Docs [9] API reference — seaborn 0.11.2 documentation (pydata.org) [10] Machine Learning Deployment as a Web Service | SpringerLink [11] https://ieeexplore.ieee.org/abstract/document/874899 2/ [12] The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction – Google Research
Copyright
Copyright © 2023 Varkala Satheesh Kumar, G Nithish Chandra, S Vishwanath. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET53036
Publish Date : 2023-05-26
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online