

Ijraset Journal For Research in Applied Science and Engineering Technology
A Quantifiable Analysis of Ambivalence in Tweets
Authors: Raghu Tak
DOI Link: https://doi.org/10.22214/ijraset.2022.41340
Certificate: View Certificate
Abstract
To detect emotions of the writer in any textual content is a requirement that has been persistent in the industry. Much of the research work has been done on this topic but only a handful of them explore the quantified association of the given text with the purpose of recognizing mixed emotions and emotional ambivalence, our work tends to do so. Emotional Ambivalence is a state in which person feels a blend of both positive and negative emotions. Therefore, we needed a suitable and brief emotion model capable of being bipolar to begin our work with, so we chose Paul Ekman’s Emotion model. This model focuses only on the six primary emotions which are: anger, fear, joy, sadness, surprise and disgust. In our work we used a Lexicon based approach for emotion recognition. The objective was achieved with the help of newly created lexicon for bi- grams that contained annotations according to their PMI scores. We also created a subset of Twitter Emotional Corpus (TEC) by passing it to our annotators, to test our approach. The automatic process through which the original corpus was created did have some wrong annotations; therefore a manual cross validation of this corpus was required. So, we chose three annotators for this purpose and fetched a uniform agreed corpus on which we worked further. The output of our approach detects a combination of the emotions felt associated with their respective values.
Introduction
I. INTRODUCTION
Computationally identifying the attitude in opinion of the writer while he was writing it is a study of sentiment analysis. But this study doesn’t give much information about what emotions the writer was feeling apart from the opinion being either positive or negative. Some opinions are neutral also that needs to be recognized either to counter the misclassification in any approach.
But we all know a writer of an opinion might have had felt many emotions while writing that opinion and identifying these different mixed emotions with a certain value has various applications and can be very helpful to determine what emotion the user felt primarily, the nature of the user and generating a better response in a human-computer interaction. There are various other applications of emotion analysis from the textual data like behavioral studies from the social media communications of a user to prevent suicides [1], helping user in the emergency situations by voice to text conversion, studying the frustration level of the writer and others that require real time detection of emotions. Most strategies for the same depend on a specific emotion model and the available lexicons that are annotated with primary or complex emotions.
There are many emotion model proposed in all these years but our work was primarily based on the Ekman’s emotion model [2]. The bipolarity of these emotions [3] is shown below. However, in our research we categorized ’Joy’ and ’Surprise’ as positive emotions while the remaining ones were categorized as negatives emotions.
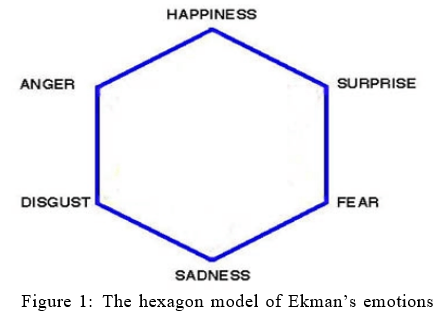
There are many available lexicon and corpora that associate the six basic emotions identified in the shown model. One of those corporas is Emolex that was built using crowdsourcing [4] which identifies word-emotion associations in unigrams and bigrams. In another work of the author, an automotive process to build corpora was followed that gave annotations in a textual corpus consisting thousands of tweets based on the emotive word followed by a hash tag [5]. However, its limitation is that not every tweet signifies the hash- tagged emotion. Many of these tweets are ambivalent which our annotators tagged with the suitable emotions. In some other research work [6], a lexicon that was built using crowdsourcing had three dimensions for 14000 words: valance, arousal and dominance [6]. And each word was given a score in the range of 1 to 9 for each of the dimensions.
Now much of the work has been done for the emotion analysis using these lexicons and corpora, however the acuteness of ambivalence associated with the corpus has not been thoroughly explored, that is why we used a bit of a manual help to cross validate the already annotated data and filter out the tweets having less agreement among the judges. The manual intervention was required so that our approach can get the right data to produce the right results. So we tasked our annotators to filter out the tweets having indication of mixed emotions felt by the writer and annotate those tweets with the two primary emotions. By doing so, we were also able to recognize the ambivalent tweets (having an indication of both positive and negative emotion). So when all the annotators annotated the tweets, we cleared the tweets that had either 100% or 67% agreement among them to get a uniform corpus.
During the annotation phase, we also started working to generate a suit- able lexicon and for that, we followed a reverse approach. In our work, we only considered bigrams in the given tweet of TEC. We had the lexicon for the unigrams [7] but the same was not available for bigrams [8]. Instead, the bigrams were given a polarity score rather than the emotive association. Therefore, we studied this lexicon and classified the bigrams with certain emotions based on the polarity scores. These classifications were further used to provide a quantified value for our objective of calculating Ambivalence. In this paper, section 2 gives the idea of related work that has already been done, section 3 gives a better insight into the lexicon and corpus used in our work, section 4 is for Experimentation and the flowchart our approach followed, section 5 discusses the Results followed by the section 6 that gives the conclusion and future work of our approach.
II. RELATED WORK
Every text does have a sense of emotion in which it was written by the writer. However, there are textual contents that usually have the mixed conflicting feelings hidden underneath them; this mixed cognition is called Ambivalence. Emotion analysis tends to study for any kind of emotions hidden within a text, whereas Ambivalence Analysis gives the measurement of the conflicting emotions felt by the writer. Not much of the work has been done to study the ambivalence in a textual content but the study of ambivalence in the personnel is still being done by many researchers. Ben-Ari and Lavee [9] studied ambivalence among the married couples over emotional expressiveness. The research was done individually and collectively to examine the quality of relationship among the couples. Findings suggested that the individual’s AEE was more indicative towards the lower relationship quality.
In another work [10], the researchers used emoticons present in the tweets to identify the users posting ambivalent tweets and found some interesting findings. For instance, female ambivalent users like to mention their close friends regularly in their tweets. Ambivalent users show more interests in sports events and entertainment. Moreover, the sentiment shift is clearly a negative to positive pattern in ambivalent tweet. Those users were also found to be the righteous target for online marketing.
Ambivalence and sarcasm are different terms but sarcasm can sometimes involve ambivalence. Therefore, Nadali et al. [11] presented a model named Sarcasm Detection Model (SDM) that consisted of three different classifiers to identify sarcasm in the tweets. Those classifiers worked better in a coherent model rather than individually. In another work, researchers visualized ambivalent data to measure the ambivalence [12]. The data was collected from a survey of undergrads on different topics that were further used in the information visualization technique.
Now that we have seen the important work done on the ambivalence analysis, we’ll now discuss the work done in the field of Emotion Analysis. The study of Emotions from textual content is divided into three main categories: Knowledge Based, Statistical and Hybrid. Many popular lexicons were created through Knowledge based methods. Knowledge based approaches use the lexicons available to classify the text into the affect category. Statistical approaches are machine learning algorithms that use the training corpus inputted for classification of texts into the right affect category. Hybrid approaches take the both categories mentioned above into the consideration for proper classification. We’ll now see some of the important research done in the affect computing.
Kamps and Marx [13] gave an intuitive approach to automatically calculate quantitative values for affect. Factorial analysis was used on which the dimensions were based on the aforementioned work, and those dimensions were potency, evaluation and activity. The authors exploited the lexical and semantic relations found in WordNet for the measurement of these factors. Therefore, the distance between words in the graph of WordNet can be indicated as a semantic similarity measure.
In another work, the authors studied the Twitter conversations and found how it can be useful to understand the social aspects and nature of emotions [14]. They demonstrated two ways for emotional aspect, transition and influence.
The results found out by them were very interesting. Their data indicated that in many of the conversations, the users would like to share a mutual and common emotion.
Many other works were also studied like Boucouvalas [15] analyzed chat messages for emotions. In this work the author demonstrates a real time dialogue interface that uses real time typed text and unearths the emotions underneath it which further are being displayed on screen with appropriate facial expression. This interface uses a real time developed engine for emotion extraction. This interface brings all the users who are communicating in a common shared space. Then the engine works on their typed textual content to extract all the emotions hidden in the overall communication with the proper intensity and duration in which the emotion was felt by the user.
Liu et al. [16] studied the email data using large-scale data of real-world situations that happen every day (such as “getting into a car accident”). This data was used to categorize the sentences into the one of the basic emotion categories. The approach turned out to be much robust enough than many other approaches. The corpus for the same used was, Open Mind Common- sense that has 400,000 facts and situations happens every day in our world. A few of the linguistic models were also merged for the robustness of approach and data. The approach classified the emotions sentence by sentence which have larger practical implications than many other approaches.
John et al. [17] explored emotions in novels. Volkova et al. [18] worked on fairy tales. Mohammad and Turney [4] used the crowdsourcing on mechanical turk to associate 14,182 unigrams with eight basic emotions. In his another work, they used an automotive process to create a textual corpus based on the eight emotions using the twitter posts and extracted the word- emotions association from this twitter corpus. They used Archivist’s free online service to collect the tweets having a hash tag with one of the Ekman’s six emotions.
Aman and Szpakowicz [19] used machine learning approaches to classify the documents in one of the Ekman’s emotions. Poria et al. [20] merged SenticNet and WordNet Affect for better analysis in opinion mining. While the former misses sentiment and later quantitative related information, the work done by them classify different concepts in one of the Ekman’s emotion with respective polarity. In another work [21] the semantic affinity among words was measured based on wordnet with the help of hop count. The minimal path length function was calculated among the words connected by a sequence in wordnet. Chenlo and Losada [22] implemented bag of concepts to detect the textual subjectivity. They used polarity features of Sentic Net for the same. Dragoni et al. [23] merged WordNet, SenticNet and ConceptNet which further was named as a fuzzy framework, and was used to detect sentiment at the sentence level. Phan et al. [24] used deep network for multi label emotion classification on the Cornell Movie Dialogue Dataset.
The overall focus of lexicon based approach has always been to get the right lexicon and some notable work has been done towards this way. Word- NetAffect Strapparava et al. [25] which focuses on the affective category in which the concept belongs while SenticNet Cambria et al. [26] focus on the polarity of each word. Many researchers tackled the problem of affect computing with the help of various machine learning techniques. Some used Naive based classifier [27] while others used SVM. Some also chose to go for unsupervised approach [28] exploiting the various lexicons available. In a recent trend, the hybrid approaches [29] of lexicon and machine learning are also widely being used for affect computing.
III. CORPUS AND LEXICON
To conduct the research, we needed the proper data for our objective which was not available readily anywhere. We needed a corpus which had the different combination of emotions annotated on the textual content. There- fore we decided to include some manual intervention to filter out the tweets showing mixed emotions from the collection of 21051 tweets. We targeted three qualified individuals for this work who took approximately four months to complete the job. Each annotator filtered out different number of tweets for the mentioned objective so we filtered out further to find the agreed tweets with either 67% or 100% agreement among them. We instructed our annotators to only annotate two primary emotions which they felt suitable for any tweet they encountered.
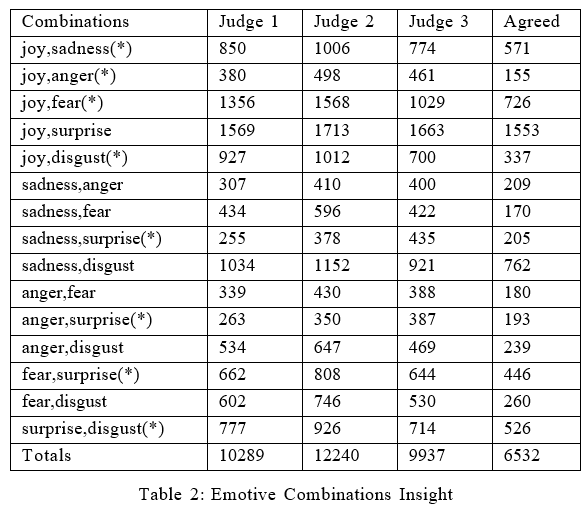
Initially after the completion of the annotations, Annotator 1 filtered out 10289 tweets and annotated them with the corresponding mixed emotions. Similarly Annotator 2 filtered out 12240 and Annotator 3 filtered out 9937 tweets. Then we filtered out the mutually agreed tweets among our annotators and that gave us a uniform corpus of 6532 tweets hiding mixed emotions among them. This corpus was our final corpus on which we worked in our research. The following table gives us a better insight into the corpus:
|
Annotators |
Number of tweets |
Mutual Disagreement |
|
Annotator 1 |
10289 |
3757 |
|
Annotator 2 |
12240 |
5708 |
|
Annotator 3 |
9937 |
3405 |
Table 1: Number of Annotations
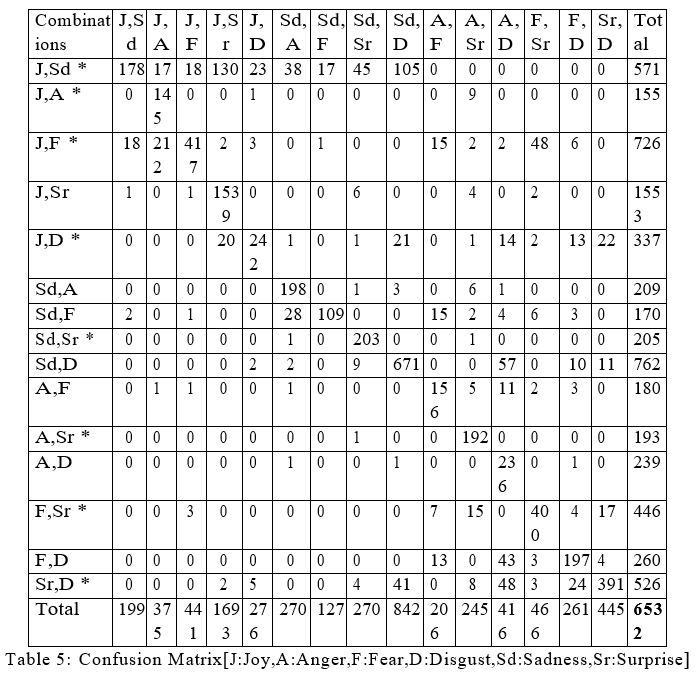
Among these 6532 tweets, 2459 tweets were found to be having 100% agreement and the remaining 4073 tweets had 67% agreement among our annotators. Out of these 4073 tweets, Annotator 1 and 2 agreed upon 1176 tweets. Similarly, Annotator 1 and 3 agreed upon 1423 tweets and Annotator 2 and 3 agreed upon 1474 tweets. Table 2 that is shown below gives a better insight into all the combinations of emotions which our judges annotated and agreed upon.
It is notable that there are 15 different combinations of mixed emotions that a person may feel and out of these 15 combinations, only 8 combination qualifies to belong in the Ambivalence category because as stated earlier, we are considering only ’Joy’ and ’Surprise’ as positive emotions. Therefore, only eight conflicting combinations can be formed from positive and negative emotions that will belong to the Ambivalence class. These 8 combinations are starred in the above table. It is clearly observable that the size of final corpus is 6532. Out of these 6532 tweets, 3159 tweets were Ambivalent.
Next, we will see if our corpus is uniformly distributed or not and for that we will compute Shannon Entropy [30]. Shannon Entropy is computed with the following formula:
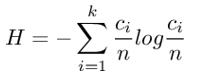
Here k is number of classes and ci is number of instances of the ith class. The measurement for the same comes out to be 3.5250 and the property of this equation states that if it is 0, than our data is poorly distributed while if it is log k, it is a balanced data in which the size of each class is n/k. Now the Log k for the same turns out to be 3.90689 which is slightly greater than the measured entropy. Therefore, we can state that our corpus is quite balanced and uniformly distributed. Similarly, we will see if the corpus is balanced or not targeting only eight classes of Ambivalence starred in Table 2. The measurement for the same comes out to be 2.8232 which is quite close to 3, therefore the data considering the specific ambivalent classes in our final corpus is also quite balanced.
Another step forward in our research was to get a suitable lexicon for our approach. Our approach considered the bi-grams in a tweet and based on the annotations and polarity score, it calculated the ambivalence for the given tweet. Therefore, we needed a suitable lexicon for bi-grams that has annotations with a polarity score. However, we took another way to get such lexicon. We used the NRC’s Hashtag Sentiment Afflex [31] in which for each bi-gram, the PMI score is associated between the term and the positive or negative class. This score is further being used to classify the bi-grams into the respective emotions. We divided these scores in certain ranges which were based on an empirical study and then randomly distributed the bi-grams using the respective probability for the distributions.
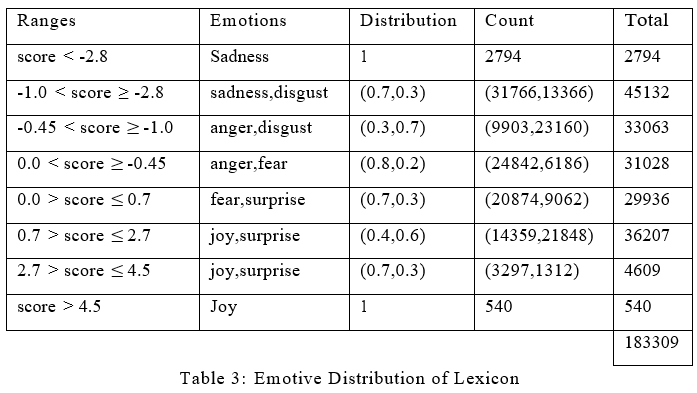
Table 3 gives us a better insight into our lexicon. It is clearly observable how the different ranges of PMI scores were used to classify different bi-grams into a certain emotion. These PMI score were further used to calculate the Ambivalence of a given tweet. Each range in our lexicon was annotated randomly with a certain distribution which was selected empirically. Therefore at the end, the lexicon had 34745 entries for ’anger’, 27060 for ’fear’, 18196 for ’joy’, 34560 for ’sadness’, 32222 for ’surprise’ and 36526 for ’disgust’. We will compute the Shannon Entropy [30] again to see if our lexicon is uniformly distributed. The measurement for the same comes out to be 2.55146 which is slightly less than 2.58496. Therefore, with respect to the lexicon used, we can state that it is well balanced either.
IV. EXPERIMENTATION
Like many other approaches, our approach is also a modular one. As discussed in previous sections, our approach targets the quantitative aspect of Ambivalence in textual data. In this section we will see the certain flow that our approach followed to output the desired results. Our approach for the given objective is divided in five modules:
A. Preprocessing
In the beginning of our experiment, we passed our tweet to ekphrasis[32] preprocessor module to remove hashtags, username, dates, censored words and Capital letter words. This module was also used to recognize the Emoticons in our tweets. In the other phases of preprocessing, we removed the singlets, punctuations and stop words. This preprocessed tweet is further being analyzed and forwarded into the next module.
B. Observed Emoji Emotions
For each of the preprocessed tweet, we look for the emoji icons in the tweet. If they are present, then we map these emoji icons with the standard emotions that might be associated with these emojies. So after the mapping of all the emojies, we get a list of Observed Emoji Emotions (OEE) which is the significant ones for this tweet. When OEEs are found to be present in a tweet, we wanted our approach to consider only those bi-grams that have the corresponding annotated emotion present in the OEE and discard the rest of bi-grams.
C. Selecting right bi-grams
A couple of other things that we considered when choosing bi-grams was discarding unproductive bi-grams. These bi-grams can be formed if both of the uni-grams are present in the Stop-words. Another thing was forming the different combinations of bi-grams if one is not present in our lexicon. These combinations can be formed by adjoining hashtag to form a new bi-gram to be considered. Let’s see an example of two unigrams ’Monday’ and ’ideal’, So we form four different combinations of these unigrams to create different bi-grams to consider, such bi-grams to be formed are: ”#Mondayideal”, ”Monday ideal”, ”#Monday ideal” and ”Monday #ideal”. However, we chose only that bi-gram which is present in our lexicon and has the highest absolute PMI score which further is being added to the total score of the corresponding annotated emotion.
D. Effect of negation
Now in the preprocessing phase, we also considered the role of negative words. Our approach counted the negatives present in a tweet and passed this N-COUNT to another module. This module then flipped the sign of total score for the same number of emotions as the N COUNT. Then we associated this flipped score with the emotion sitting at the opposite end in the hexagon model that we saw in Figure 1.
E. Outputting the Results
After successfully analyzing a tweet, our approach outputs the results consisting two primary emotions with a quantitative score associated with them. When OEEs are present in a tweet, we prioritize them over other emotions detected and returned the scores for the former ones. In the Table 4 that is shown next, the sample output for two tweets are being shown with a different number of OEEs. The output shown comprises the quantitative values of the mixed emotions. In the first tweet, there was only one emoji for ’joy’ which in other emotion detection approaches, should suggest that it is the primary emotion for this tweet but in our result, we can clearly see that the primary emotion is ’surprise’ which does have a slightly greater value than ’joy’. However, in the next tweet, there are two OEEs: ’joy’ and ’sadness’. And our result gave the score for both of the emotions suggesting ’sadness’ being the primary emotion with slightly greater value than ’joy’.
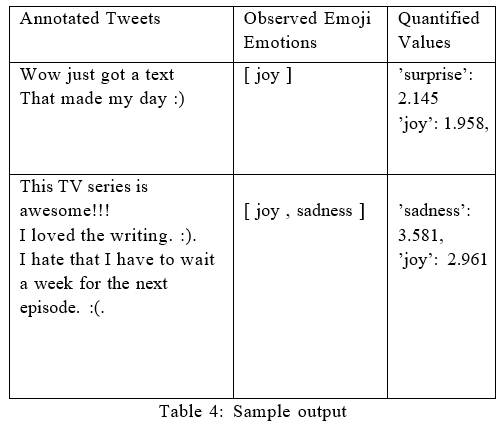
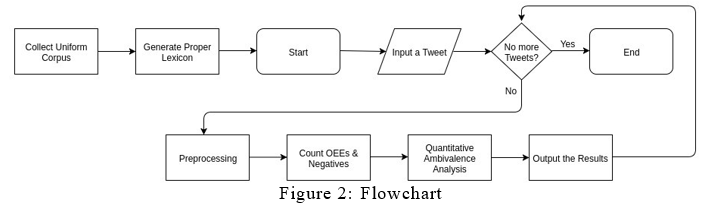
Figure 2 that is shown above gives us an insight into the complete flowchart of the process. As we can see that the Experimentation started after fetching the agreed corpus and generating the righteous lexicon. And for each tweet, the result was displayed similarly like the results shown in Table 4.
V. RESULTS
After setting up the environment and conducing series of experiments with the designed approach on the unanimous corpus, it was able to output the associated emotions of many tweets with their respective quantitative value. Traditional metrics were used to analyze the performance of our approach like Confusion Matrix and Performance Matrix that are shown below:
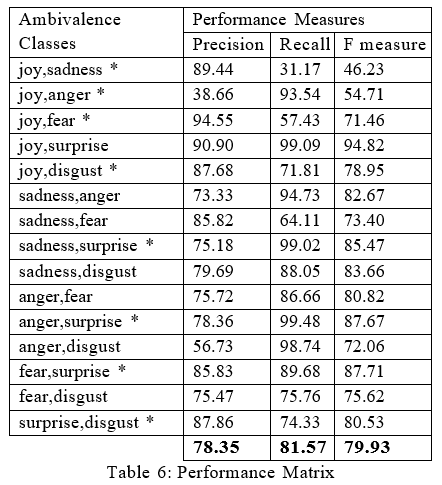
The end accuracy result that was achieved is 80.74% for all the 6532 tweets. Table 6 that are shown above gives us the values of three important performance measures for our approach considering all the 15 classes of Am- bivalence. It covers all the combinations of mixed emotions recognized via Ekman’s model. However as discussed previously that there are only eight classes of Ambivalence that we are considering in this research. Therefore, when we average out the performance measures for the mentioned eight classes shown in the matrix above, the value of precision and recall comes out to be 79.645% and 77.057% respectively. However, to calculate the F measure, we need to take harmonic mean of these two values and it turns out to be 78.329%.
Conclusion
We have presented a study on Ambivalence Analysis using the reversible computing that we did to annotate the emotions to the bi-grams. In our research, we approached manual annotation strategy due to the lack of proper corpora for our objective. We chose three annotators for this purpose and the end result was an uniform corpus of 6532 tweets that were supposedly categorized under the different combinations of mixed emotions. Our research was divided under five different phases and at the end, the results consisted quantified values of the emotions recognized. However, there is a shortcoming that is observable is its unsatisfactory results for annotations:”Joy,Sadness” & ”Joy,Anger”. Clearly the reversible computing of bigrams annotations needs more work. At this point, we conclude our analysis with the experiments that showed interesting results in ambivalence analysis. We are also planning to expand our work on Plutchik’s Emotion Wheel [33] and to consider the impact of different cognitive traits like valance and arousal.
References
[1] P. Burnap, W. Colombo, J. Scourfield, Machine classification and anal- ysis of suicide-related communication on twitter, in: Proceedings of the 26th ACM conference on hypertext & social media, ACM, pp. 75–84. [2] P. Ekman, Facial expression and emotion., American psychologist 48 (1993) 384. [3] A. Young, D. Perrett, A. Calder, R. Sprengelmeyer, P. Ekman, Facial expressions of emotion: Stimuli and tests (feest), Bury St. Edmunds: Thames Valley Test Company (2002). [4] S. M. Mohammad, P. D. Turney, Crowdsourcing a word–emotion asso- ciation lexicon, Computational Intelligence 29 (2013) 436–465. [5] S. M. Mohammad, # emotional tweets, in: Proceedings of the First Joint Conference on Lexical and Computational Semantics-Volume 1: Proceedings of the main conference and the shared task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Evalua- tion, Association for Computational Linguistics, pp. 246–255. [6] A. B. Warriner, V. Kuperman, M. Brysbaert, Norms of valence, arousal, and dominance for 13,915 english lemmas, Behavior research methods 45 (2013) 1191–1207. [7] S. M. Mohammad, S. Kiritchenko, Using hashtags to capture fine emo- tion categories from tweets, Computational Intelligence 31 (2015) 301– 326. [8] S. Kiritchenko, X. Zhu, S. M. Mohammad, Sentiment analysis of short informal texts, Journal of Artificial Intelligence Research 50 (2014) 723– 762. [9] A. Ben-Ari, Y. Lavee, Ambivalence over emotional expressiveness in in- timate relationships: A shift from an individual characteristic to dyadic attribute, American Journal of Orthopsychiatry 81 (2011) 277–284. [10] Y. Hu, J. Zhao, J. Wu, Emoticon-based ambivalent expression: A hidden indicator for unusual behaviors in weibo, PloS one 11 (2016) e0147079. [11] S. Nadali, M. A. A. Murad, N. M. Sharef, Detecting sarcastic tweets: A sentistrength modeling approach (????). [12] G. Panger, B. Rea, S. Weber, Visualizing ambivalence: showing what mixed feelings look like, in: CHI’13 Extended Abstracts on Human Factors in Computing Systems, ACM, pp. 1029–1034. [13] J. Kamps, M. Marx, Words with attitude, Citeseer, ???? [14] S. Kim, J. Bak, A. H. Oh, Do you feel what i feel? social aspects of emotions in twitter conversations., in: ICWSM. [15] A. C. Boucouvalas, Real time text-to-emotion engine for expressive internet communications, in: Proceedings of International Symposium on Communication Systems, Networks and Digital Signal Processing (CSNDSP-2002). [16] H. Liu, H. Lieberman, T. Selker, A model of textual affect sensing using real-world knowledge, in: Proceedings of the 8th international conference on Intelligent user interfaces, ACM, pp. 125–132. [17] D. John, A. C. Boucouvalas, Z. Xu, Representing emotional momentum within expressive internet communication., in: EuroIMSA, pp. 183–188. [18] E. P. Volkova, B. J. Mohler, D. Meurers, D. Gerdemann, H. H. Bu¨lthoff, Emotional perception of fairy tales: achieving agreement in emotion annotation of text, in: Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, Association for Computational Linguistics, pp. 98–106. [19] S. Aman, S. Szpakowicz, Identifying expressions of emotion in text, in: International Conference on Text, Speech and Dialogue, Springer, pp. 196–205. [20] S. Poria, A. Gelbukh, E. Cambria, P. Yang, A. Hussain, T. Durrani, Merging senticnet and wordnet-affect emotion lists for sentiment anal- ysis, in: Signal Processing (ICSP), 2012 IEEE 11th International Con- ference on, volume 2, IEEE, pp. 1251–1255. [21] I. van Willegen, L. Rothkrantz, P. Wiggers, Lexical affinity measure between words, in: International Conference on Text, Speech and Dia- logue, Springer, pp. 234–241. [22] J. M. Chenlo, D. E. Losada, An empirical study of sentence features for subjectivity and polarity classification, Information Sciences 280 (2014) 275–288. [23] M. Dragoni, A. G. Tettamanzi, C. da Costa Pereira, A fuzzy system for concept-level sentiment analysis, in: Semantic web evaluation challenge, Springer, pp. 21–27. [24] D. A. Phan, H. Shindo, Y. Matsumoto, Multiple emotions detection in conversation transcripts, in: Proceedings of the 30th Pacific Asia Conference on Language, Information and Computation: Oral Papers, pp. 85–94. [25] C. Strapparava, A. Valitutti, et al., Wordnet affect: an affective exten- sion of wordnet., in: Lrec, volume 4, Citeseer, pp. 1083–1086. [26] E. Cambria, D. Olsher, D. Rajagopal, Senticnet 3: a common and common-sense knowledge base for cognition-driven sentiment analysis, in: Twenty-eighth AAAI conference on artificial intelligence. [27] Y. Xia, E. Cambria, A. Hussain, H. Zhao, Word polarity disambiguation using bayesian model and opinion-level features, Cognitive Computation 7 (2015) 369–380. [28] A. Agrawal, A. An, Unsupervised emotion detection from text using semantic and syntactic relations, in: Proceedings of the The 2012 IEEE/WIC/ACM International Joint Conferences on Web Intelligence and Intelligent Agent Technology-Volume 01, IEEE Computer Society, pp. 346–353. [29] S. Gievska, K. Koroveshovski, T. Chavdarova, A hybrid approach for emotion detection in support of affective interaction, in: Data Mining Workshop (ICDMW), 2014 IEEE International Conference on, IEEE, pp. 352–359. [30] C. E. Shannon, A mathematical theory of communication, ACM SIG- MOBILE Mobile Computing and Communications Review 5 (2001) 3– 55. [31] X. Zhu, S. Kiritchenko, S. Mohammad, Nrc-canada-2014: Recent im- provements in the sentiment analysis of tweets, in: Proceedings of the 8th international workshop on semantic evaluation (SemEval 2014), pp. 443–447. [32] C. Baziotis, N. Pelekis, C. Doulkeridis, Datastories at semeval-2017 task 4: Deep lstm with attention for message-level and topic-based sen- timent analysis, in: Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), pp. 747–754. [33] R. Plutchik, A general psychoevolutionary theory of emotion in r. plutchik & h. kellerman (eds.) emotion: Theory, research, and expe- rience (vol. 1, pp. 189-217), 1980.
Copyright
Copyright © 2022 Raghu Tak. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET41340
Publish Date : 2022-04-09
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online