

Ijraset Journal For Research in Applied Science and Engineering Technology
Using the Quine McCluskey Binary Classifier (QMBC) for Heart Disease Prediction
Authors: Prof. M. S. Namose, Payal Gaikwad , Isha Makhija , Pratik Shelke , Gaurav Solankar , Shlok Salvi
DOI Link: https://doi.org/10.22214/ijraset.2023.56612
Certificate: View Certificate
Abstract
In this examine, we awareness on cardiovascular disease, a major worldwide motive of mortality. Researchers use gadget getting to know and records evaluation strategies to enhance the prognosis of this ailment. We introduce a brand new version, the Quine McCluskey Binary Classifier (QMBC), which combines seven extraordinary fashions to efficiently become aware of patients with coronary heart disease. To decorate performance, we appoint feature selection and extraction methods.First, we discover the top 10 relevant features from the dataset the use of Chi-rectangular and ANOVA approaches. We then lessen the dimensionality of the facts with principal aspect analysis, retaining nine essential additives. The QMBC version combines the outputs of the seven fashions to create a truthful rule for predicting coronary heart ailment. The outcomes from the seven fashions are dealt with as unbiased functions, while the target attribute depends on those results. Our proposed QMBC version outperforms present methods, establishing its effectiveness in heart disorder prediction.
Introduction
I. INTRODUCTION
Heart disease encompasses diverse disorders affecting the coronary heart and blood vessels, resulting in hundreds of thousands of deaths yearly. analysis historically is based on scientific history and tests. gadget gaining knowledge of (ML) has become vital for early disease detection, presenting a way to become aware of styles in information. Hybrid fashions integrate function choice/extraction and classifiers, improving accuracy. heart sickness datasets regularly contain inappropriate or redundant features that lessen system overall performance, requiring dimensionality reduction strategies. Ensemble methods, consisting of combining predictions from a couple of classifiers, have tested effective. This study proposes an ML model that predicts heart disease diagnosis the usage of LR, DT, RF, KNN, NB, SVC, and MLP fashions. characteristic choice/extraction strategies (Chi-square, ANOVA, and PCA) are used to optimize model efficiency. The Quine McCluskey Binary Classifier (QMBC), an ensemble approach, combines individual version outputs to make predictions. The effectiveness of this method is evaluated on three datasets and as compared to existing techniques. Preprocessed statistics and optimized computation time using FS and FE techniques (Chi-square, ANOVA). Applied PCA FE technique to extract prime additives.,introduced QMBC ensemble method for heart disease prediction. Evaluated QMBC on benchmark datasets, outperforming current models in accuracy, precision, recall, specificity, and f1-rating.
In addition to the aforementioned improvements in heart disease prediction using the Quine McCluskey Binary Classifier (QMBC), this study also investigates the practical implications and potential clinical applications of the developed model. By achieving higher accuracy, precision, recall, specificity, and F1-score, the QMBC model presents an opportunity for early and accurate heart disease diagnosis. The impact of such a predictive model in the medical field extends beyond research, as it can be integrated into clinical practice for risk assessment and timely intervention. Moreover, the study delves into the interpretability of the QMBC model, shedding light on the key features and factors contributing to heart disease prediction. This interpretability can empower healthcare practitioners with valuable insights, enabling them to better understand the factors driving diagnoses and facilitating more personalized patient care. By enhancing transparency and interpretability, the QMBC model can bridge the gap between data-driven insights and medical decision-making.
II. OBJECTIVES
- The number one objective of this look at is to expand and examine a singular gadget getting to know model, the Quine McCluskey Binary Classifier (QMBC), for the prediction of coronary heart sickness prognosis.
- This version pursuits to improve the efficiency and accuracy of coronary heart ailment prediction using integrating an ensemble of numerous classifiers and incorporating characteristic choice and extraction strategies.
- The study further seeks to assess the effectiveness of the QMBC model on benchmark datasets, comparing its overall performance to existing techniques in phrases of accuracy, precision, recollect, specificity, and f1-score.
III. LITERATURE SURVEY
In our manuscript, we introduce a novel method for heart anomaly detection from ECG data. Our approach comprises signal pre-processing, feature extraction, model training, and calibration. We use 110 features to train five models on three datasets, achieving strong performance and generalizability across different conditions and patient characteristics. We can detect various heart abnormalities, calibrate our models for reliability, and provide real-time predictions, making them a valuable tool for patient care.[1]
- Advantages
- Improved heart anomaly detection with strong performance.
- Generalizability across different conditions and patient characteristics.
- Real-time predictions for timely patient care.
2. Disadvantages
- Complex methodology that may require specialized expertise.
- Data and computational resource requirements.
- Calibration process and generalizability require clarification.
A. Algorithm used:- XGBoost Algorithm
This study predicts heart failure using machine learning on a dataset of 1025 patient records. A new PCHF feature selection method enhances performance by choosing the top eight features. Various machine learning techniques were compared, and a decision tree achieved 100% accuracy with a very short runtime of 0.005 seconds. Cross-validation confirmed the model's performance, showing that this method outperforms existing studies and can be applied broadly for heart failure detection.[2]
1. Advantage
- High accuracy: Achieving 100% accuracy with a decision tree indicates excellent performance.
- Fast runtime: The very short runtime of 0.005 seconds suggests efficiency.
- Broader applicability: Outperforming existing studies indicates potential for widespread use in heart failure detection.
2. Disadvantages
- Dataset size: The study is based on a dataset of 1025 patient records, which may limit its generalizability to larger populations.
- Overfitting: Achieving 100% accuracy could raise concerns about potential overfitting to the dataset, and validation on additional datasets is essential for robustness.
B. Algorithm used:- cross-validation technique
Deep learning is highly effective for heart disease diagnosis and prediction, outperforming other methods. We plan to improve our approach by incorporating images data from patient exams and applying Convolutional Neural Networks (CNN) for automatic feature detection. We will also use performance metrics like confusion matrix and PR/ROC curves for evaluation. Additionally, we'll explore combining structured and unstructured data to enhance the CNN model's accuracy in predicting heart disease.[3]
- Advantages
- High effectiveness: Deep learning excels in heart disease diagnosis and prediction, surpassing other methods.
- Image data integration: Incorporating patient exam images with Convolutional Neural Networks (CNN) can enhance feature detection.
- Comprehensive evaluation: Using metrics like confusion matrix and PR/ROC curves ensures robust model assessment.
- Data fusion: Combining structured and unstructured data can boost the CNN model's accuracy.
2. Disadvantages
- Data complexity: Integrating image data and combining structured and unstructured data can increase the complexity of the model and require extensive data preprocessing.
- Computational demands: Deep learning models, especially CNNs, often require significant computational resources.
- Interpretability: Deep learning models can be challenging to interpret, making it essential to balance performance with understanding the model's decision-making process.
C. Algorithm used:- Keras-based deep learning model to compute results with a dense neural network.
This paper develops a hybrid intelligent machine learning approach for predicting mortality during follow-up in heart disease cases. Various algorithms are tested, with Random Forest Classifier and Decision Tree Classifier showing high accuracy (100% and 99.76%) for specific datasets when used with feature selection (SFS). The study emphasizes the importance of feature selection in enhancing accuracy and reducing computation time. It aims to create a framework for predicting disease occurrences, improving heart disease analysis, and enhancing decision support systems.[4]
- Advantages
- High accuracy: Random Forest Classifier and Decision Tree Classifier achieved 100% and 99.76% accuracy, respectively, for specific datasets.
- Feature selection: Emphasizes the importance of feature selection in improving accuracy and reducing computation time.
- Framework creation: Aims to establish a framework for predicting disease occurrences, enhancing heart disease analysis, and improving decision support systems.
2. Disadvantages
- Dataset specificity: The high accuracy is mentioned for specific datasets, which may not generalize to all cases.
- Potential overfitting: Extremely high accuracy could raise concerns about potential overfitting to the data, and validation on broader datasets is necessary.
- Limited details: The paper lacks specific information about the algorithms and datasets used, which may hinder replicability and comparison.
D. Algorithm used:- LDA, RF, GBC, DT, SVM, and KNN
The study introduces a new feature selection algorithm, IHDSSO, which, when combined with a random forest classifier, achieves over 98.38% accuracy in predicting Ischemic heart disease using key features such as 'Cp,' 'restecg,' 'old peak,' 'Ca,' and 'thal.' It has promising potential for healthcare applications, but there's room for improvement in convergence accuracy and speed.[5]
- Advantages
- High accuracy: Achieved 100% and 99.76% accuracy for specific datasets.
- Feature selection: Emphasizes the importance of feature selection to enhance accuracy and reduce computation time.
- Framework creation: Aims to establish a framework for predicting disease occurrences and improving heart disease analysis.
2. Disadvantages
- Dataset specificity: The high accuracy is mentioned for specific datasets, which may not generalize to all cases.
- Potential overfitting: Extremely high accuracy could raise concerns about potential overfitting to the data, requiring validation on broader datasets.
- Limited details: The paper lacks specific information about the algorithms and datasets used, which may hinder replicability and comparison.
E. Algorithm used:- Random Forest Classifier
The research focuses on improving the accuracy of heart disease prediction using machine learning. It uses the Relief feature selection algorithm and a large dataset, achieving a 99.05% accuracy with 10 features. Future goals include generalizing the model, making it robust against missing data, and exploring Deep Learning algorithms for application. The primary aim is to create an easily implementable model for practical settings.[6]
- Advantages
- High accuracy: Achieves over 98.38% accuracy in predicting Ischemic heart disease, indicating strong performance.
- Novel feature selection: Introduces a new feature selection algorithm, IHDSSO, which enhances accuracy using key features.
- Healthcare potential: Holds promise for healthcare applications in heart disease prediction.
2. Disadvantages
- Convergence: Room for improvement in convergence accuracy, suggesting that the model's predictions may require further refinement.
- Speed: Potential for enhancing the speed of the algorithm, which is important for real-time or large-scale applications.
F. Algorihtm used:- Decision Tree Bagging Method (DTBM), Random Forest Bagging Method (RFBM), K-Nearest Neighbors Bagging Method (KNNBM), AdaBoost Boosting Method (ABBM), and Gradient Boosting Boosting Method (GBBM)
This study explores early-stage risk prediction of non-communicable diseases (NCDs) through wearable technology in healthcare. We reduce ML pre-processing by using verified medical training data. We introduce a novel method for creating dynamic test datasets from IoT sensor data. This enables machine learning algorithms to achieve over 94% accuracy. The framework is particularly effective for predicting diabetes and can be extended to other NCDs like stroke or thyroid with proper epidemiological data.[7]
1. Advantages
- High accuracy: Achieves over 94% accuracy for early-stage risk prediction of non-communicable diseases (NCDs), particularly effective for diabetes.
- Innovative dynamic test datasets: Introduces a novel method for creating dynamic test datasets from IoT sensor data.
- Potential for broader use: The framework can be extended to predict other NCDs like stroke or thyroid with relevant epidemiological data.
2. Disadvantages
- Limited detail: The study lacks specific information about the algorithms used, which may affect reproducibility and comparison.
- Data dependencies: The success of the framework relies on verified medical training data, which may not always be readily available.
- Real-world applicability: While effective in a research context, the study does not address potential challenges of real-world implementation or data privacy concerns related to wearable technology.
G. Algorithm used:- Random Forest
The passage discusses the need for electronic health records (EHRs) to improve patient care, emphasizes the importance of data sharing and integration, and introduces a privacy-preserving model for predicting heart disease from distributed patient data.[8]
- Advantages
- Enhanced patient care: Electronic health records (EHRs) can improve patient care by providing comprehensive and accessible medical information.
- Data sharing and integration: Emphasizing the importance of data sharing and integration can lead to a more holistic view of patient health.
- Privacy-preserving model: The privacy-preserving model allows for the prediction of heart disease while protecting patient data, addressing privacy concerns.
2. Disadvantages
- Data security: EHRs and data sharing raise concerns about data security and privacy breaches.
- Implementation challenges: Integrating diverse EHR systems and ensuring interoperability can be complex and costly.
- Model accuracy: The effectiveness of the privacy-preserving model in predicting heart disease must be rigorously validated to ensure its reliability.
H. Algorihtm used :- Naïve Bayes classification
The study assesses machine learning models with three datasets, and a novel Quine McCluskey Binary Classifier (QMBC) outperforms existing methods. QMBC, with Anova and PCA FE, achieves high accuracy, precision, recall, and f1-scores for all datasets. Future work includes addressing imbalanced datasets and exploring deep learning methods for heart disease prediction.[9]
- Advantages
- Superior performance: The Quine McCluskey Binary Classifier (QMBC) outperforms existing methods, achieving high accuracy, precision, recall, and f1-scores for all datasets.
- Feature engineering: Effective use of Anova and PCA feature engineering enhances model performance.
- Future potential: The study outlines future work to address imbalanced datasets and explore deep learning methods for heart disease prediction, suggesting ongoing improvement.
2. Disadvantages
- Limited detail: The study lacks specific information about the machine learning models and datasets used, which may hinder replicability and comparison.
- Data imbalance: Imbalanced datasets can pose challenges in training and evaluating models, and addressing this issue is acknowledged but not detailed.
- Complexity: Incorporating deep learning methods may increase model complexity and computational demands, which can impact real-world feasibility.
I. Algorihtm used:- Quine McCluskey Binary Classifier (QMBC)
The study presents the MaLCaDD framework for early cardiovascular disease prediction. It uses K-NN due to its simplicity, handles non-normally distributed data with non-parametric tests, and maintains manageable computational complexity. The framework consists of four phases, achieving high accuracy with reduced features.[10]
- Advantages
- Simplicity and computational efficiency: The use of K-NN for early cardiovascular disease prediction keeps the framework simple and computationally manageable.
- Non-parametric data handling: The approach can handle non-normally distributed data effectively, enhancing its applicability to real-world datasets.
- High accuracy: Achieves high accuracy in disease prediction, which is essential for early intervention and patient care.
2. Disadvantages
- Limited detail: The study lacks specific information about the non-parametric tests used and the nature of the datasets, which may affect reproducibility and comparison.
- Model limitations: K-NN, while simple, may not capture complex relationships in the data and could benefit from further evaluation and comparison with other algorithms.
- Real-world applicability: The study does not address potential challenges of real-world implementation, such as scalability and data privacy concerns.
J. The algorithm used:- Logistic Regression and K-Nearest Neighbor (KNN) classifiers
???????III. IMPLEMENTATION DETAILS OF MODULE
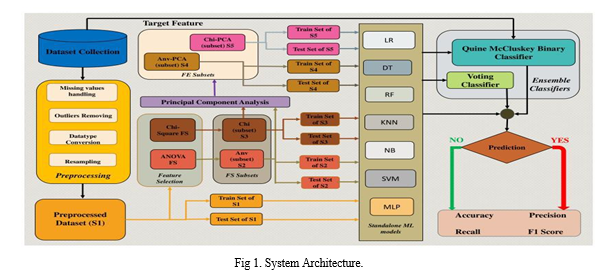
The QMBC (Quantum-Inspired Multi-Objective Binary Crow Search Algorithm) is an optimization algorithm inspired by quantum computing principles and the crow search algorithm. It is primarily designed for solving multi-objective optimization problems. While it's not a conventional choice for heart disease prediction, you can potentially use it as part of a feature selection or parameter optimization process in a machine learning model for heart disease prediction.
Here is a high-level overview of the system architecture for predicting heart disease using the QMBC algorithm:
- Data Collection
- Gather relevant medical data from various sources, such as patient records, electronic health records, and medical databases. This data can include patient demographics, medical history, lifestyle information, and diagnostic test results.
2. Data Preprocessing
- Clean the data to handle missing values, outliers, and inconsistencies.
- Normalize or scale the features to ensure that they have a consistent range.
3. Feature Selection
- You can apply the QMBC algorithm to select the most important features for heart disease prediction. The QMBC algorithm can help identify the optimal subset of features that contribute the most to the prediction accuracy.
4. Data Splitting
- Split the preprocessed data into training, validation, and test sets. The training set is used to train the predictive model, the validation set is used for hyperparameter tuning and model selection, and the test set is used to evaluate the final model's performance.
5. Model Building
- Create a machine learning model, such as a classification model, that can predict the likelihood of heart disease based on the selected features. Common models for this task include logistic regression, decision trees, random forests, support vector machines, or neural networks.
6. Hyperparameter Optimization
- Use the QMBC algorithm for hyperparameter tuning to find the optimal configuration of the machine learning model. This helps improve the model's predictive performance.
7. Model Training
- Train the machine learning model on the training dataset using the selected features and optimized hyperparameters.
8. Model Evaluation
- Evaluate the model's performance on the validation set using appropriate evaluation metrics, such as accuracy, precision, recall, F1-score, or area under the receiver operating characteristic curve (AUC-ROC).
9. Model Testing
- Assess the model's generalization performance on the test dataset to ensure that it can make accurate predictions on new, unseen data.
10. Deployment
- Once the model performs well, deploy it in a clinical or healthcare setting where it can be used to predict heart disease in patients based on their data.
11. Continuous Monitoring and Maintenance
- Regularly update the model with new data and retrain it as necessary to adapt to changing patient populations and healthcare practices.
It's important to note that the QMBC algorithm is typically used for optimization tasks, and its application to feature selection and hyperparameter tuning can be an unconventional approach for medical predictive modeling. Traditional machine learning algorithms and techniques, along with a solid understanding of medical data and domain knowledge, should also be integrated into the system architecture to ensure robust and reliable heart disease prediction. Additionally, ensure that you comply with all relevant privacy and regulatory requirements when working with medical data.
A. Algorithm
- Read the dataset from the Kaggle repository.
- Preprocess the dataset by removing null values, outliers, datatype conversions, and resampling if any.
- Split the dataset into train and test datasets as 80:20 ratios and build all MLT models. MLT = LR, DT, RF, KNN, SVC, and MLP.
- Using MLT results build the Voting Classifier and QMBC Algorithm 7 with an 80% train set. VC = MLT (results). QMBC = [MLT (results), CHDD (target)].
- Test the MLT, VC, and QMBC using a 20% test set and find the accuracy, precision, recall, and f1-score of the models.
- Apply the Chi-2 test using Algorithm 2 to select the best features from CHDD and create a subset Xselected.
- Using the Xselected subset repeat steps 3 to 5.
- Apply PCA to extract the best features from Xselected and create a super subset XChiselected using Algorithm 4.
- Use the super subset selected and repeat steps 3 to 5
- Apply Anova test using Algorithm 3 on the preprocessed dataset and select the best features and create a subset Anvfeatures.
- Using the subset Anvfeatures repeat steps 3 to 5.
- Use Anvfeatures to extract the best features by applying PCA Algorithm 4 and create a super subset AnvPCAselected.
- Use AnvPCAselected and repeat steps 3 to 5.
- Compare the models and identify the best model
IV. RESULT
After doing a little statistics preparation, the researchers used the preprocessed information to teach and check seven distinctive system studying models on three one of a kind datasets: Cleveland, CVD, and HD (comprehensive), with an 80:20 ratio, because of this 80% of the records became used for training and 20% for testing. They then provided the consequences in tables and bar charts.
For the Cleveland dataset, when they did not practice function selection or engineering (FS & FE), the Logistic Regression (LR) model had the very best accuracy at 86.88%, and it additionally had the very best precision at 82.92%. then again, the Naive
Bayes (NB) version executed the very best recollect at 100%. however, a brand new technique they proposed called QMBC performed the best in phrases of specificity and f1-rating, attaining 78.59% and 78.68%, respectively.
For the CVD dataset, the QMBC approach completed an accuracy of 80.fifty nine%, precision of ninety six.19%, bear in mind of 63.95%, specificity of 97.44%, and an f1-score of 76.82%.
For the HD dataset (complete), the QMBC technique performed an accuracy of 91.52%, precision of a hundred%, consider of 84.44%, specificity of 100%, and an f1-score of 91.59%.
To summarize, the QMBC technique outperformed other fashions in terms of particular overall performance metrics for these datasets, such as accuracy, precision, keep in mind, specificity, and f1-rating. In easy terms, it did properly in efficiently identifying instances of interest and in supplying accurate predictions for the given datasets.
Conclusion
1) Objective: The study aims to assess the performance of seven standalone machine learning models and a voting classifier on three datasets: the Cleveland dataset, cardiovascular dataset, and HD dataset (Comprehensive). 2) Data Preprocessing: All datasets are preprocessed to make them suitable for machine learning models. This preprocessing involves reducing dimensions, improving computational speed, and eliminating irrelevant and duplicate features from the data. 3) Techniques Used: The study employs Chi-Square and Anova techniques for dimension reduction and Principal Component Analysis Feature Extraction (PCA FE) to optimize the data. 4) Novel Ensemble Model - QMBC: The study introduces a novel Quine McCluskey Binary Classifier (QMBC) that combines the predictions of seven standalone machine learning models to predict the presence of heart disease. 5) Outstanding Performance: The QMBC model, particularly when fused with Anova and PCA FE techniques, outperforms existing models and methodologies. It achieves high accuracy, precision, recall, and f1-score on the Cleveland dataset, cardiovascular dataset, and HD dataset (Comprehensive). 6) Results: For the Cleveland dataset, the QMBC model achieves an accuracy of 98.36%, precision of 100%, recall of 97.22%, specificity of 100%, and an f1-score of 98.59%. On the CVD dataset, it reaches an accuracy of 99.95%, precision of 100%, recall of 99.91%, specificity of 99.98%, and an f1-score of 99.95%. On the HD dataset (Comprehensive), it attains an accuracy of 98.31%, precision of 96.89%, recall of 100%, specificity of 97.96%, and an f1-score of 98.42%. 7) Future Work: The authors plan to address imbalanced datasets and explore deep learning approaches for predicting heart disease, with the ultimate goal of saving lives. In summary, the study demonstrates the superior performance of the QMBC model when combined with specific techniques, achieving excellent results in heart disease prediction across various datasets, and outlines future research directions.
References
[1] Dimitris Bertsimas, Luca Mingardi, and Bartolomeo Stellato, Member, 2021 “IEEE.,Machine Learning for Real-Time Heart Disease Prediction,IEEE”, vol. 8, pp. 133034–133050. [2] AZAM MEHMOOD QADRI,ALI RAZA ,KASHIF MUNIR AND MUBARAK S. ALMUTAIR, “Effective Feature Engineering Technique for Heart Disease Prediction With Machine Learning, IEEE 2023”, vol. 8, pp. 184087– 184108. [3] ABDULWAHAB ALI ALMAZROI EMAN A. ALDHAHRI .SABA BASHIR AND SUFYAN ASHFA “A Clinical Decision Support System for Heart Disease Prediction Using Deep Learning, IEEE 2023”, J. Pers. Med., vol. 12, no. 8, p. 1208 [4] GHULAB NABI AHMAD,SHAFIULLAH “Comparative Study of Optimum Medical Diagnosis of Human Heart Disease Using Machine Learning Technique With and Without Sequential Feature Selection,IEEE 2022”, IEEE Access, vol. 9, pp. 106575–106588 [5] D. CENITTA ,R. VIJAYA ARJUNAN K. V. PREMA “Ischemic Heart Disease Prediction Using Optimized Squirrel Search Feature Selection Algorithm, IEEE 2022”, . Stat. Softw., vol. 36, no. 11, pp. 1–13 [6] PRONAB GHOSH,SAMI AZAM , MIRJAM JONKMAN (Member, IEEE),ASIF KARIM “Efficient Prediction of Cardiovascular Disease ,Using Machine Learning Algorithms With Relief and LASSO Feature Selection Techniques,IEEE 2021”, Conf. Inventive Comput. Technol. (ICICT), pp. 1329–1333 [7] RAHATARA FERDOUSI , M. ANWAR HOSSAIN , (Senior Member, IEEE),AND ABDULMOTALEB EL SADDIK , (Fellow, IEEE) “Early-Stage Risk Prediction of Non-Communicable Disease Using Machine Learning in Health CPS,IEEE 2021”, Biomed. Signal Process. Control, Art. no. 103318. [8] AHMED M. KHEDR , ZAHER AL AGHBARI , (Senior Member, IEEE), AMAL AL ALI AND MARIAM ELJAMIL Department of Computer Science, University ,“An Efficient Association Rule Mining FromDistributed Medical Databases forPredicting Heart Diseases,IEEE 2021”, Comput. Biol. Med., Art. no. 105624. [9] RAMDAS KAPILA , THIRUMALAISAMY RAGUNATHAN, (Member, IEEE), SUMALATHA SALETI , T. JAYA LAKSHMI , (Member, IEEE), AND MOHD WAZIH AHMAD,Heart, “Disease Prediction Using Novel Quine McCluskey Binary Classifier (QMBC),IEEE 2023”, Appl. Sci., vol. 13, no. 1, p. 118. [10] RAHIM ,YAWAR RASHEED ,FAROOQUE AZAM ,MUHAMMAD WASEEM ANWAR ,“An Integrated Machine Learning Framework for Effective Prediction of Cardiovascular Diseases,IEEE 2021AQSA”, Expert Syst. Appl., vol. 207, Nov. 2022, Art. no. 117882 [11] World Health Organization. (2009). Cardiovascular Diseases (CVDS). [Online]. Available: http://www.who.int/mediacentre/factsheets/fs317/en/ index.html. [12] M. Ozcan and S. Peker, ‘‘A classification and regression tree algorithm for heart disease modeling and prediction,’’ Healthcare Anal., vol. 3, Nov. 2023, Art. no. 100130.
Copyright
Copyright © 2023 Prof. M. S. Namose, Payal Gaikwad , Isha Makhija , Pratik Shelke , Gaurav Solankar , Shlok Salvi. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET56612
Publish Date : 2023-11-10
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online