

Ijraset Journal For Research in Applied Science and Engineering Technology
Real Time Face Mask Recognition
Authors: Neetika Tripathi, Priyag Raj Sharma, Saumya Gupta, Shrishti Singh
DOI Link: https://doi.org/10.22214/ijraset.2022.43023
Certificate: View Certificate
Abstract
This project depicts the use of Real Time Face Mask Recognition in the global pandemic. During COVID-19, WHO made wearing face masks a necessity so that people could protect themselves from the deadly virus. Real Time Face Mask Recognition is used to identify if a user is not wearing a face mask or not. Real Time Face Mask Recognition had seen crucial progress in the fields of Image processing and Computer vision, since the rise of the deadly pandemic. Many face mask detection models have come up which were made using various algorithms and techniques. The suggested approach in this paper uses Keras, Deep Learning, TensorFlow and OpenCV to do Real Time Face Mask Detection. This model can be used to take precautions in various public places as it can help in restricting the spread of virus. Face masks have become an essential element of our daily lives, hence it is important to wear one for the safety of ourselves and others.
Introduction
I. INTRODUCTION
The most trending topic in the field of image processing and computer vision is object detection. Ranging from small personal applications to large scale industrial applications, object recognition and detection is implemented in a broad range of industries. Some examples include OCR, security, image retrieval, agricultural monitoring, etc. In the year 2001, Viola and Jones then developed object recognition algorithm and it was named the Viola Jones detector. Digital image features were used to do object recognition which made it an optimized technique. However, it failed because it did not perform well on non-frontal faces and people standing in dark areas. Since then, researchers and scientists are eager to develop new algorithms based on deep learning to improve the object recognition model. Deep Learning is a sub part of Machine Learning that allows understanding features of any model in full length and eliminates the need to do feature extractions.
II. LITERATURE REVIEW
In object detection, an image is read and objects in that image are categorized. Bounding box is a boundary that specifies the location of those objects. This makes object recognition an important technology against prevention from deadly disease. several large scale serious respiratory diseases, which occurred in the past few years such as severe acute respiratory syndrome (SARS) and the Middle East respiratory syndrome (MERS). the reproductive number of COVID-19 is higher compared to the SARS as reported by Liu et al. Hence, more and more people are concerned about their and their family’s health. Moreover the top most priority for the government of any country is the health of its citizens. If the people are not healthy then the country will not be able to make progress in any sector. Hence its important to protect them and the surgical face masks could cut the spread of the deadly corona virus. WHO has strictly recommended people to wear face masks if they have respiratory symptoms, or they are taking care of the people with covid symptoms. Furthermore, many public services let customers use their services only if their customers wear face masks properly. As a result, face mask detection has become a pivotal computer vision task to help the global society to fight dangerous respiratory diseases. It has been observed that the research related to real time face mask detection is limited and there is a lot of scope of improvement in this domain. The world health organization (WHO) presented that corona virus disease 2019 (COVID-19) has globally infected over 2.7 million people and caused over 180,000 deaths in its report 96.
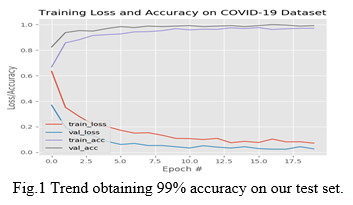
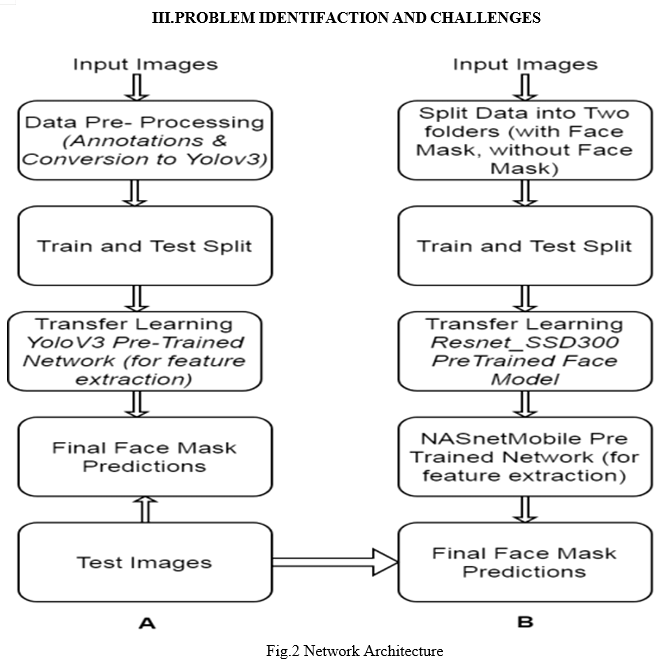
A. Stage 1- Face Detector
The face detector serves as the first phase of our system. Raw RGB image is transmitted as input to this section. The face detector removes and removes all the faces found in the image with their connecting box links. The process of getting a face accurately is very important to our makeup. Training a highly accurate face detector requires a lot of labelled data, time, and calculation resources. For these reasons, we have selected a pre-trained database on a large database to make it easier and more stable to access. Three different models were tested in this category is showed in Fig.2.
Dlib - The Dlib Deep Learning face detector offers the best performance has its predecessor, a face detector based on Dlib HOG.MTCNN - Uses a three-phase cascade architecture for CNN locally detecting and performing facial expressions and important facial features. FACENET: - The model we use to get the face of the frame. FaceNet is a face recognition program developed in 2015 by Google researchers.
B. Stage 2- Face Mask Classifier
The second phase of our system is face mask classifier. This section takes the processed ROI from Intermediate Processing Block and classified it as Mask or No Mask. A CNN-based classifier for this section was trained, based on these three different models of image classification: MobileNetV2, DenseNet121, These models have a lightweight structure that provides high performance with low delay, which should analyse the video. The result of this category is a photo (or video frame) with localized faces, classified as masked or unmasked.
IV. PROBLEM SOLUTION
A. Dataset
The dataset we used consists of 3835 images, of which 1916 faces are masked and 1919 are unmasked faces. We need to split the data set into three parts: the training data set, the test data set, and the validation data set. The purpose of data segmentation is to focus on trivial details/noise that are not needed and avoid overfitting, which only optimizes the accuracy of the training data set. We want a model that works well with a dataset we've never seen(test data), called generalization. The training set is an actual subset of the data sets we use to train our model. The model observes of this data, learns it, and then optimizes the parameters. When the model performs well enough on the test dataset, you can stop training using the training dataset. The test set is the remaining subset of data used to provide an unbiased assessment of the fit of the final model to the training data set. The data is partitioned according to the partitioning factors that are highly dependent on the type of model that the is being built on and the dataset itself. If you need training with many datasets and models, use larger data chunks for training.

B. CNN
Convolutional Neural Networks (CNNs) are a key component of modern Computer Vision tasks such as pattern object detection, image classification, and pattern recognition tasks. The CNN uses a convolutional kernel to extract higher levels along with the original image or feature map. The result is a very powerful tool for working with Computer Vision.
C. Single-Stage Detector
The one-step detector performs direct one-step detection on a dense sample of possible locations. These algorithms skip the region suggestion step used in multi-step detectors and, are therefore generally considered to be faster at the cost of loss of accuracy. One of the most popular single-step algorithms, You Only Look Once (YOLO) was introduced in 2015 and achieved near real-time performance. Single Shot Detector (SSD) is another popular algorithm used for object detection that gives excellent results.
D. Modern Object Detection Algorithm
CNN-based object detection algorithms can be divided into two categories: multi-stage detectors and single-stage detectors. The Multistage Detector divides the detection process into several stages. A two-stage detector such as RCNN first evaluates and proposes a set of regions of interest using selective search. CNN feature vectors are independently extracted from each region. Multiple algorithms based on Regional Proposal networks that provide higher accuracy and better results than most single stage detectors.
V. FUTURE SCOPE
More than sixty countries around the world have started to wear face masks compulsory. People need to cover their faces in public, supermarkets, public transports, offices, and stores. Various companies often use software to count the number of people entering their stores. They may also take necessary measures to get rid of covid-19. We aim to improve our Face Mask Detection tool so that we can release it as an open-source project for the benefit of society. Our software can be used to any IP cameras, existing USB, and CCTV cameras to detect people without a mask. This detection live video feed can be implemented in web and desktop applications so that the operator can see notice messages.
Software system can also get an pic or vision in case someone does not wear a mask. Furthermore, an sound or alarm system can also be embedded so that there is a beep when enters the area someone without a mask. This software can also be connected to the entrance gate only people wearing face masks can come in.
References
[1] MOREP. Viola and M. Jones, “Rapid object detection using a boosted cascade of simple features, ”in Proceedingsofthe2001IEEEcomputersocietyconferenceoncomputervisionandpatternrecognition. CVPR 2001,vol.1. IEEE,2001. [2] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich featurehierarchiesforaccurateobjectdetectionandsemanticsegmentation,” in Proceedings of the IEEE conference on computervisionand pattern recognition, 2014, pp.580–587. [3] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towardsreal-timeobjectdetectionwithregionproposalnetworks,”inAdvances in neural information processing systems, 2015, pp. 91–99. [4] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu,and A. C. Berg, “SSD: Single shot multibox detector,” in Europeanconferenceon computervision.Springer, 2016, pp.21–37. [5] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “Youonlylookonce:Unified,real-timeobjectdetection,”inProceedings of the IEEE conference on computer vision andpatternrecognition, 2016, pp.779–788. [6] T.-Y.Lin,P.Goyal,R.Girshick,K.He,andP.Dollar,“Focalloss fordenseobject detection,” 2017.´ Haddad,J.,2020.HowIBuiltAFaceMaskDetectorForCOVID-19. [7] Rosebrock,A.,2020.COVID-19:FaceMaskDetectorWithOpenCV,Keras/TensorFlow, And DeepLearning-Pyimagesearch.[online] PyImageSearch.Availableat:https://www.pyimagesearch.com/2020/05/04/covid19-face-mask-detector-with-OpenCV-keras-TensorFlow-and-deep-learning/. [8] W.Liu,D.Anguelov,D.Erhan,C.Szegedy,S.Reed,C.-Y.Fu,and A. C. Berg, “SSD: Single shot multibox detector,” in Europeanconferenceon computervision.Springer, 2016,pp.21–37.
Copyright
Copyright © 2022 Neetika Tripathi, Priyag Raj Sharma, Saumya Gupta, Shrishti Singh. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET43023
Publish Date : 2022-05-21
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online