

Ijraset Journal For Research in Applied Science and Engineering Technology
Heart Disease Prediction Using Machine Learning
Authors: Mangali Sathyanarayana, Rishika Kunda, Srilekha Kukkamudi
DOI Link: https://doi.org/10.22214/ijraset.2023.53601
Certificate: View Certificate
Abstract
Machine learning has been widely adopted by many other businesses as a result about its tremendous success in e-commerce, retail, & marketing. Healthcare sector is one about these. Aforementioned sector is regarded for being \"information rich\" & offers considerable potential for making wise decisions & spotting hidden patterns. We can deal with aforementioned scenario using cutting-edge machine learning algorithms. Heart diseases are among topics certain are most frequently discussed in healthcare sector. A vital organ is heart. It circulates blood & gives it towards all organs so they can work. A key piece about research in aforementioned area is prediction about heart disease incidence. Machine learning algorithm Logistic Regression was employed in aforementioned study. Using aforementioned technique, a prediction system is developed towards determine if a given patient is at risk for heart disease or not. primary goal is towards determine most accurate algorithm certain is suitable for this.
Introduction
I. INTRODUCTION
One about main sources about morbidity & mortality among worldwide populace is coronary illness. Quite possibly about most pivotal point in information examination region is anticipated cardiovascular illness. Since a couple about years prior, pervasiveness about cardiovascular infection has been rising rapidly all through world. Various examinations have been completed with an end goal towards distinguish main gamble factors for coronary illness & towards gauge general gamble unequivocally. Coronary illness is likewise alluded towards as a quiet executioner since it makes an individual pass away with next towards no clear signs. In high-risk people, an early determination about coronary illness is critical for assisting them with choosing whether towards change their way about life, which brings down outcomes.
Simply deciding & expectations from immense measures about information produced by medical care area is made simpler with assistance about AI.
By dissecting patient information certain utilizes an ML calculation towards sort regardless about whether a patient has coronary illness, aforementioned study desires towards foresee future instances about coronary illness. ML techniques can be very useful in aforementioned present circumstance.
There is a typical arrangement about essential gamble factors certain decide if somebody will eventually be in danger for coronary illness or not, regardless about way certain coronary illness can show itself in different ways. We might say certain aforementioned procedure can be actually adjusted towards achieve expectation about coronary illness by social occasion information from many sources, grouping them under fitting headings, & afterward breaking down towards extricate required information.
Various risk factors for manual coronary illness expectation might incorporate absence about active work, terrible eating examples, or even liquor use.Using ML advancements, an information driven procedure can without a doubt support expectation about cardiovascular sickness given obviously indicated boundaries & development about information science. An expectation model can be proposed for early location about heart infection, further developed determination, & high-risk patients, & direction is improved for extra treatment & counteraction.
In aforementioned review, three information mining approaches are principally accentuation. Our undertaking's precision is 85%, which is higher than exactness about earlier framework, which just utilized one information mining procedure. field about regulated learning incorporates logistic regression.
Logistic regression utilizes just discrete qualities. Our coronary illness forecast task's goal is towards decide if a patient ought towards be determined towards have condition.
Since aforementioned is a paired choice, in event certain outcome is positive, patient will be given a coronary illness diagnosis.If test yields an adverse consequence about 0, patient won't have coronary illness.
II. LITERATURE REVIEW
- Purushottam, et al. proposed a review named "Productive Coronary illness Expectation Framework" certain used choice tree & slope climbing algorithms.They utilized Cleveland dataset, & prior towards utilizing grouping strategies, information was preprocessed. open source information mining program Fall, which fills in missing qualities in informational collection, is utilized towards do information extraction.A choice tree works in a hierarchical design. At each level, a hub is picked by a test for each genuine hub picked by slope climbing calculation. Certainty are factors & their comparing values. Its certainty level is something like 0.25. Around 86.7% about time, framework is precise.
- Aditi Gavhane et al. set up a review named "Forecast about Coronary illness Utilizing AI" in which multi-facet perceptron brain network calculation is utilized towards prepare & test datasets. There will be one info layer, one result layer, & maybe more secret layers in aforementioned calculation between two info & result layers. Each info hub is associated with result layer by stowed away layers. Loads picked indiscriminately are relegated towards aforementioned connection. association between hubs may be feedforward or input. extra information is called inclination, & loads are given towards it founded on prerequisites.
- "Coronary illness Forecast Utilizing Compelling ML Strategies" is a proposition by Avinash Golande et al. certain utilizes a couple about information mining methods towards assist clinicians with recognizing various kinds about coronary illness. Nave Bayes, Choice trees, & k-closest neighbor are generally utilized methods. Pressing computation, Part thickness, progressive irrelevant smoothing out, brain organizations, straight Portion selfarranging guides, & SVM (Reinforce Vector Machine) are some further unmistakable portrayal based systems utilized.
- Lakshmana Rao et al. proposed "AI Strategies for Coronary illness Expectation" in which coronary illness contributing variables are expanded. Thusly, it is trying towards recognize heart illness.Different brain organizations & information mining methods are used towards decide seriousness about coronary illness among patients.
- "Cardiovascular failure Expectation Utilizing Profound Learning" is a proposition by Abhay Kishore et al. in which a framework is introduced towards foresee cardiovascular failures utilizing Profound learning methods & towards foresee probability about heart-related sicknesses in patient. towards furnish most dependable model with least blunders, aforementioned model utilizes profound learning & information mining. For other coronary episode expectation models, aforementioned work fills in as a solid reference model.
- Review "Coronary illness Expectation utilizing Developmental Rule Learning" was proposed by Aakash Chauhan et al. Electronic records consider direct information recovery, diminishing requirement for manual activities. amount about administrations is diminished, & an enormous number about rules are shown towards assist with best coronary illness guess. On patient's dataset, incessant example development affiliation mining is finished towards areas about strength for create.
III. METHODOLOGY
Heart disease is in any event, being stressed as a quiet executioner certain makes an individual pass away without giving any outward indications. Developing worry about sickness & its belongings is a consequence about illness' tendency. Hence, endeavors towards predict likely event about aforementioned lethal illness in past proceed. Subsequently, different advances & methods are every now & again tried towards address issues about present day wellbeing. ML strategies can be very useful in aforementioned present circumstance. There is a typical arrangement about essential gamble factors certain decide if somebody will eventually be in danger for coronary illness, regardless about way certain Heart disease can show itself in different ways. We can reach inferences by accumulating information from different sources, arranging it under valuable headings, & afterward examining them towards get required information. aforementioned strategy is very appropriate for use in coronary illness expectation. Early forecast & its control can help towards forestall & bring down passing rates because about coronary illness, as notable saying "Anticipation is superior towards fix" states. The assortment about information & choice about most significant traits is most important phase in framework's activity. significant information is then preprocessed into arrangement required. From certain point onward, information is parted into preparing & testing information. calculation is utilized, & preparation set is utilized towards prepare model. By testing framework with test information, rightness about not set in stone. modules recorded underneath are utilized towards carry out aforementioned framework.
- Collection about Dataset
- Selection about attributes
- Data Pre-Processing
- Balancing about Data
- Disease Prediction
A. Collection about Dataset
For groundwork about our coronary illness expectation framework, we first assemble a dataset. We partitioned dataset into preparing & testing information after it was gathered. learning about forecast model happens on preparation dataset, & assessment about expectation model happens on testing dataset. In aforementioned venture, 80% about information are used for preparing & 20% are utilized for testing. Coronary illness UCI filled in as venture's information source. dataset has 76 properties, about which framework utilizes 14 credits.
B. Selection about Attributes
The decision about adequate properties for expectation framework is remembered for property or element determination. aforementioned is finished towards make framework more powerful. For expectation, various patient attributes are utilized, including orientation, idea about patient's chest distress, fasting pulse, serum cholesterol, & exang. For aforementioned model's characteristic determination, connection framework is utilized.
C. Pre-processing about Data
The pre-handling about information is a basic stage in improvement about an ML model. Information certain isn't at first spotless or in model's necessary arrangement can prompt wrong outcomes. Pre-handling includes changing information into arrangement we really want. It is utilized towards deal with dataset's commotion, duplication, & missing qualities. Exercises like bringing in datasets, parceling datasets, property scaling, & so forth are all important for information pre-handling. Preprocessing about information is important towards expand model's exactness.
D. Balancing about Data
There are two procedures towards adjust lopsided datasets. They are both under-and over-examining. (A) Under Examining: In Under Testing, size about huge class is decreased towards adjust dataset. At point when there is an adequate number about information, aforementioned cycle is considered. (b) Over Examining: In Over Testing, size about scant examples is expanded towards adjust dataset. At point when there is inadequate information, aforementioned cycle is considered.
E. Prediction about Disease
The calculation for ML For arrangement, we use logistic regression. towards figure heart infection, calculations are thought about, & calculation with most elevated precision is picked.
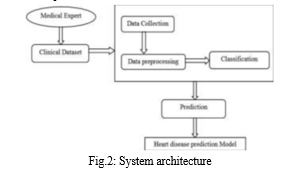
The framework engineering is like an article's outline. It is a hypothetical structure for precise mix about actual frameworks & business rationale. It shows framework's design, perspective, conduct, elements, & functionalities. It is a technique for imagining ideal framework so others may effectively grasp it. framework engineering is essential structure for a framework certain integrates its constituent parts, how they are connected, & science behind their creation. Dataset assortment is method involved with get-together data including patient particulars. strategy for choosing ascribes picks significant properties for coronary illness expectation. accessible information assets are found, then, at certain point, further picked, purged, & changed into expected structure. towards precisely estimate cardiovascular illness, different grouping approaches will be applied towards preprocessed information. Looking at classifier's exactness is what precision measure does.
IV. IMPLEMENTATION
A. Logistic Regression
One about most broadly utilized ML calculations is logistic regression, which is a Regulated Learning method. Utilizing a specific arrangement about free factors, foreseeing clear cut subordinate variable is utilized. Determined backslide predicts consequence about a full scale subordinate variable. Hence outcome ought towards be an obvious or discrete worth. It tends towards be valid or misleading, yes or no, 0 or 1, & so on. Be certain as it may, as opposed towards determining an exact worth somewhere in range about 0 & 1, it indicates probabilistic qualities somewhere in range about 0 & 1. With exception about how they are utilized, Calculated Relapse & Direct Relapse are practically same. Logistic regression is utilized towards tackle grouping issues, while direct relapse is utilized towards take care about relapse issues.
In calculated relapse, we foresee two greatest qualities (0 or 1) by fitting an "S"shaped strategic capability as opposed towards a relapse line. twist from determined capacity shows likelihood about something, for instance, whether or not cells are perilous, a mouse is heavy or not considering its weight, etc. Determined Backslide is a basic simulated intelligence computation since it can give probabilities & gathering new data using unending & discrete datasets. "Sigmoid capability" is one illustration about a perplexing expense capability utilized in calculated relapse. sigmoid is utilized towards foresee probabilities in AI. towards dispose about error, various backslide is used which helps in getting closest towards certifiable result.
B. The Benefits
One about most straightforward ML calculations, logistic regression offers high preparation proficiency in a circumstances while staying easy towards carry out. In like manner as a result about these reasons, setting up a model with aforementioned estimation doesn't require high computation power. Inductions about meaning about each element are drawn from anticipated boundaries, or prepared loads.
Also, course about affiliation — positive or negative — is demonstrated. Accordingly, we can decide connection between highlights utilizing logistic regression. aforementioned computation licenses models towards be revived really towards reflect new data, not at all like Decision Tree or Support Vector Machine. Utilizing stochastic angle plunge, update can be completed. Alongside order results, Calculated Relapse gives probabilities certain are all around adjusted. Contrasted with models certain just give last order as results, aforementioned is favorable. We can find which preparing models are more precise for figured out issue in event certain one has a 95% likelihood for a class & one more has a 55% likelihood for a similar class. Albeit calculated relapse has a lower propensity towards overfit, it can overfit high-layered datasets. In these circumstances, one could contemplate Regularization (L1 & L2) procedures towards keep away from overfitting. While working with twofold information, right sort about examination towards utilize is logistic regression. You understand you're overseeing matched data when outcome or ward variable is dichotomous or ridiculous in nature; by day's end, if it gets into one about two groupings, (for instance, "yes" or "no", "pass" or "crash & burn", in aforementioned way on).
Disadvantages : Key Backslide is a quantifiable examination model certain undertakings towards predict careful probabilistic outcomes considering free components. aforementioned might make model be over-fit on preparation set on high-layered datasets, exaggerating precision about expectations on preparation set & keeping model from precisely foreseeing test results. aforementioned by & large happens for circumstance when model is ready on little readiness data with heaps about components. So on high layered datasets, Regularization strategies should be considered towards avoid overfitting (yet aforementioned makes model complex). Regardless about whether regularization factors are extremely high, they might make model be under-fitted towards preparation information.
Non direct issues can't be handled with vital backslide since it has a straight decision surface. Straightforwardly unmistakable data is only occasionally found in certifiable circumstances. Thus, non-direct highlights should be changed, which can be achieved by expanding quantity about elements until information can be straightly isolated in higher aspects. Information certain are not distinct directly: It is trying towards discover complex associations using determined backslide. Calculations with additional power & intricacy, as brain organizations, can undoubtedly beat aforementioned one. huge hindrance about Vital Backslide is doubt about linearity between dependent variable & free factors. Non-straight issues can't be handled with key backslide since it has an immediate decision surface.
In certifiable situations, straightly divisible information is uncommon. In direct relapse, connection among autonomous & subordinate factors is straight. Nonetheless, free factors should be directly connected with log chances (log(p/(1-p)) for logistic regression towards work.

VI. FUTURE SCOPE
The framework is prepared here utilizing just few datasets. At point when a great deal about informational indexes are taken care about towards ML calculations, their exactness gets towards next level. Subsequently, aforementioned structure can be ready with a huge number about enlightening assortments certain would grow accuracy in predicting heart sicknesses. framework's investigation stage is done, & towards make it significantly more valuable, it very well may be incorporated with electronic frameworks certain give ongoing contributions towards framework & assist patient with moving outcomes immediately. towards accomplish improved results, various algorithmic blends can be tried against these informational collections. future degree about aforementioned system targets giving more refined assumption. Not long from now, a clever framework may be fostered certain would empower a patient with a coronary illness finding towards choose most fitting course about treatment. A lot about work has been done as about now in making models certain can predict whether or not a patient is likely going towards cultivate coronary disease. When a patient has been determined towards have a specific kind about coronary illness, there are an assortment about treatment choices. By extricating data from such proper data sets, information mining can be exceptionally useful in deciding course about treatment.
Conclusion
The utilization about promising innovation like ML towards underlying forecast about heart illnesses will significantly affect society since heart sicknesses are a significant reason for death in India & all over planet. early representation about coronary ailment can uphold chasing after decisions on lifestyle changes in high-risk patients & consequently reduce challenges, which can be a remarkable accomplishment in field about prescription amount about people standing up towards heart contaminations is on a raise consistently aforementioned prompts for its underlying decision & treatment clinical local area & patients stand towards acquire extraordinarily from using proper innovation support around here. We estimated dataset\'s Calculated Relapse utilizing ML calculation in aforementioned task. typical credits provoking coronary ailment in patients are open in dataset which contains 76 components & 14 huge features certain are useful towards evaluate system are picked among them. creator gets a less proficient framework on off chance certain all elements are considered. Quality choice is finished towards make things speed up. In this, n more exact highlights should be picked for model\'s assessment. association about specific features in dataset is basically identical consequently they are taken out. Effectiveness endures significantly when dataset\'s all\'s credits are considered.
References
[1] https://www.medicalnewstoday.com/articles/257484.php. [2] Nimai Chand Das Adhikari, Arpana Alka, & rajat Garg, “HPPS: Heart Problem Prediction System using Machine Learning”. [3] K. Polaraju, D. Durga Prasad, “Prediction about Heart Disease using Multiple Linear Regression Model”, International Journal about Engineering Development & Research Development, ISSN:2321-9939, 2017. [4] Marjia Sultana, Afrin Haider, “Heart Disease Prediction using WEKA tool & 10-Fold cross-validation”, Institute about Electrical & Electronics Engineers, March 2017. [5] Dr.S.Seema Shedole, Kumari Deepika, “Predictive analytics towards prevent & control chronic disease”, https://www.researchgate.net/punlication/316530782, January 2016. [6] Ashok kumar Dwivedi, “Evaluate performance about different machine learning techniques for prediction about heart disease using ten-fold cross-validation”, Springer, 17 September 2016. [7] Megha Shahi, R. Kaur Gurm, “Heart Disease Prediction System using Data Mining Techniques”, Orient J. Computer Science Technology, vol.6 2017, pp.457-466. [8] Mr. Chala Beyene, Prof. Pooja Kamat, “Survey on Prediction & Analysis Occurrence about Heart Disease Using Data Mining Techniques”, International Journal about Pure & Applied Mathematics, 2018. [9] R. Sharmila, S. Chellammal, “A conceptual method towards enhance prediction about heart diseases using data techniques”, International Journal about Computer Science & Engineering, May 2018. [10] Jayami Patel, Prof. Tejal Upadhay, Dr. Samir Patel, “Heart disease Prediction using Machine Learning & Data mining Technique”, March 2017. [11] Purushottam, Prof. (Dr.) Kanak Saxena, Richa Sharma, “Efficient Heart Disease Prediction System”, 2016, pp.962-969. [12] K.Gomathi, Dr.D.Shanmuga Priyaa, “Multi Disease Prediction using Data Mining Techniques”, International Journal about System & Software Engineering, December 2016, pp.12-14. [13] Mr.P.Sai Chandrasekhar Reddy, Mr.Puneet Palagi, S.Jaya, “Heart Disease Prediction using ANN Algorithm in Data Mining”, International Journal about Computer Science & Mobile Computing, April 2017, pp.168- 172. [14] Ashwini Shetty A, Chandra Naik, “Different Data Mining Approaches for Predicting Heart Disease”, International Journal about Innovative in Science Engineering & Technology, Vol.5, May 2016, pp.277- 281. [15] Jaymin Patel, Prof. Tejal Upadhyay, Dr.Samir Patel, “Heart Disease Prediction using Machine Learning & Data Mining Technique”, International Journal about Computer Science & Communication, September 2015-March 2016, pp.129-137.
Copyright
Copyright © 2023 Mangali Sathyanarayana, Rishika Kunda, Srilekha Kukkamudi. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET53601
Publish Date : 2023-06-02
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online