

Ijraset Journal For Research in Applied Science and Engineering Technology
Soil Analyser - Revolutionizing Agriculture through Wireless Sensor Networks and Machine Learning
Authors: Dr Kalaivani D, Nikhil Kamate, Om Gawade, Pinaki Matruprasad, Vamsi Krishna Sai
DOI Link: https://doi.org/10.22214/ijraset.2024.58248
Certificate: View Certificate
Abstract
Crop yield analysis, traditionally dependent on the experiential knowledge of farmers, has undergone a transformative revolution with the advent of machine learning. Anticipating yields stands as a critical concern for farmers eager for insights into their upcoming harvests. In the past, such predictions relied on a farmer\'s intimate familiarity with their specific field and crop. However, the challenge has persisted in effectively leveraging available data. Enter machine learning-a rapidly advancing field with compelling solutions. This research introduces a system that utilizes historical agricultural data to forecast crop yields. By employing sophisticated machine learning algorithms such as Support Vector Machine and Random Forest, this system not only predicts yields but also recommends optimal fertilizers for each crop. At its core, the emphasis is on constructing a robust predictive model that reliably anticipates future crop production. The paper meticulously delves into the realm of crop yield prediction, exploring the subject through the lens of advanced machine learning techniques.
Introduction
I. INTRODUCTION
Ancient Indian culture has long thrived on the foundation of agriculture, with communities cultivating crops uniquely suited to their specific lands. However, the introduction of modern technologies in agriculture has gradually shifted this traditional practice. The widespread adoption of these innovations has led people toward cultivating artificial or hybrid products, contributing to an unhealthy lifestyle. In the present era, there is a notable lack of awareness among individuals regarding optimal crop cultivation timing and suitable locations. These evolving cultivation techniques have also disrupted seasonal climatic patterns, adversely affecting essential resources like soil, water, and air, ultimately posing a threat to food security. Machine learning operates through various paradigms: supervised, unsupervised, and reinforcement learning, each with its own significance and limitations. Supervised learning involves constructing a mathematical model from data containing both inputs and desired outputs, allowing the algorithm to learn correlations. Unsupervised learning builds models solely from input data without explicit output labels, focusing on uncovering patterns within the data. Semi-supervised learning addresses incomplete training data, where some inputs lack associated labels, aiming to enhance model robustness by leveraging both labeled and unlabeled data. In the agricultural sector, the integration of wireless sensor networks and crop yield prediction has had a profound impact. The primary objective of this paper is to elevate crop yield through diverse methodologies within the realm of machine learning. The study seeks to recommend specific fertilizers tailored to individual crops, harnessing the power of these machine-learning techniques. By employing these algorithms, the research aims to optimize crop production and drive advancements in agricultural practices, striving for enhanced yield outcomes. paper must emphasize concepts and the underlying principles and should provide authentic contributions to knowledge. If your paper does not represent original work, it should have educational value by presenting a fresh perspective or a synthesis of existing knowledge. The purpose of this document is to provide you with some guidelines. You are, however, encouraged to consult additional resources that assist you in writing a professional technical paper.
II. RELATED WORK
Shivnath Ghosh, et al. (2014) In this paper machine learning system is divided into three steps, first sampling (Different soil with same number of properties with different parameters) second Back Propagation Algorithm and third Weight updating.
P.Vinciya, et al. (2016) This paper mainly focused on analyzing the agriculture analysis of organic farming and inorganic farming, time cultivation of the plant, profit and loss of the data and analyzes the real estate business land in a specific area. This work goes for finding reasonable information models that accomplish a high precision and a high consensus as far as yield expectation abilities.
Zhihao Hong, et al. (2016) This paper proposes an information driven approach on structure PA answers for gathering and information demonstrating frameworks. Soil dampness, a key factor in the yield development cycle, is chosen for instance to exhibit the viability of our information driven methodology. On the accumulation side, a responsive remote sensor hub is built up that expects to catch the elements of soil dampness utilizing soil dampness sensor. The prototyped gadget is tried on field soil to show its usefulness and the responsiveness of the sensors. On the information examination side, a one of a kind, site-explicit soil dampness expectation system is based over models produced by the AI procedures Support Vector Machine and Relevance Vector Machine. The structure predicts soil dampness on n days dependent on similar soil and natural characteristics that can be gathered by our sensor hub. Explains responsive sensor hub for soil moisture data collection and AI techniques.
Sabri Arik, et al.(2016) In this paper, we propose a method for predicting functional properties of soil samples from a number of measurable spatial and spectral features of those samples. The method used is based on Savitzky- Golay filter for pre-processing and a relatively recent evolution of single hidden-layer feed-forward network(SLFN) learning technique called extreme learning machine (ELM) for prediction.
Vaneesbeer Singh, et al. (2017) This work presents an approach which uses different Machine Learning techniques in order to predict the category of the yield
based on macro-nutrients and micro- nutrients status in
dataset. The dataset considered for the crop yield prediction was obtained from Krishi Bhawan (Talab-Tillo) Jammu. The parameters present in the data are Macro-Nutrients (ph,Oc,Ec,N,P,K,S) and Micro Nutrients(Zn,Fe,Mn,Cu) present in samples collected from different regions of Jammu District .After analysis Machine learning algorithms are applied to predict the category of yield . The category, thus predicted will specify the yield of crops. The problem of predicting the crop yield is formulated as Classification where different classifier algorithms are used.
E.Manjula et al.(2017) This paper chooses Nitrogen, Phosphorus, Potassium, Calcium, Magnesium, Sulphur, Iron, Zinc, and so forth, nutrients for investigating the soil supplements utilizing Naïve Bayes, Decision Tree and hybrid approach of Naïve Bayes and Decision Tree. The performance of the classification algorithms are compared based on accuracy and execution time.
Rohit Kumar Rajak et al. (2017) This method is characterized by a soil database collected from the farm, crop provided by agriculture experts, achievement of parameters such as soil through soil testing lab dataset. The. data from soil testing lab dataset given to recommendation system it will use the collect data and do ensemble model with majority voting technique using support vector machine and ANN as learners to recommend a crop for a site specific parameter with high accuracy and efficiency.
III. PROBLEM DEFINITION
The agricultural production in India is significantly influenced by various climate factors, encompassing meteorological parameters (such as humidity, wind speed, temperature, and moisture), precipitation parameters (including rainfall, region-wise rainfall, and irrigation), and soil parameters (like pH, organic carbon, phosphorus, and fiber). The continual changes in climate conditions, exacerbated by global warming and other factors, pose a significant challenge to traditional farming practices inherited from ancestors.
While farmers in India still rely on age-old technologies, the evolving climate has disrupted the once-predictable patterns. The lack of seasonal rainfall, excessive humidity, and alterations in the winter season adversely affect Rabi crops. Recent years have witnessed unexpected variations in rainfall during the winter season. To address these challenges, there is a pressing need to develop a system leveraging data analytics techniques on agriculture production-based datasets. This system aims to uncover hidden facts, patterns, and insights to empower farmers in making informed decisions about crop selection, helping them adapt to the changing climate and ultimately maximizing their benefits.
IV. PROPOSED SYSTEM
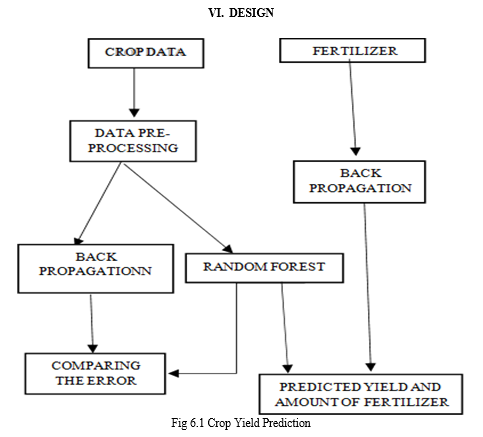
A. Crop Yield Prediction
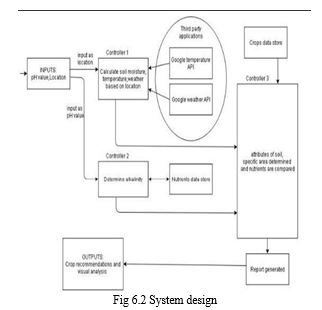
The outcome of crop yield primarily depends on parameters such as variety of crop, seed type, and environmental parameters such as sunlight (Temperature), soil (ph.), water (ph.), rainfall, and humidity. By analyzing the soil and atmosphere a particular region's best crop in order to have more crop yield and the net crop yield can be predicted. This prediction will help the farmers. To choose appropriate crops for their farm according to the soil type, temperature, humidity, water level, spacing depth, soil PH, season, fertilizer, and months.
B. Fertilizer Prediction
India is a highly populated country and random changes in climatic conditions are needed to secure the world's food resources. Framers face serious problems in drought conditions. The type of soil plays a major role in the crop yield. Suggesting the use of fertilizers may help the farmers to make the best decision for their cropping situation. Based on soil type and soil PH we suggest what kind of fertilizer should be used for particular crops.
V. METHODOLOGY
A. Random Forest
The Random Forest algorithm is a supervised classification algorithm that creates an ensemble of decision trees in a random manner. The algorithm builds a forest by constructing multiple trees, and the relationship between the number of trees and accuracy is direct – more trees generally lead to more accurate results. Notably, the process of creating the forest involves randomness, distinguishing it from traditional decision tree construction methods based on information gain or gain index approaches.
B. SVM (Support Vector Machine)
Support Vector Machine (SVM) constructs a hyperplane or multiple hyperplanes in a high-dimensional space for tasks like classification or regression.
The key objective is to achieve optimal separation by placing the hyperplane with the maximum distance to the nearest training data points of any class, reducing the classification error. SVM employs mappings to ensure efficient computation, using a kernel function (e.g., k(x, y)) chosen for optimal computational efficiency. This approach is designed to handle small objects in terms of the variables in the original space while managing the computational burden effectively.
Conclusion
In conclusion, the project introduces an innovative approach to harnessing wireless sensors within agriculture. It maximizes the potential of sensor-generated data, employing a mobile application to facilitate data retrieval. Focusing on vital variables such as temperature, soil quality, and humidity, this method aims to leverage this data to predict crop yield. Aggregating a database comprising information from multiple users serves as a training resource for a model. The overarching objective of precision farming is to aid farmers in optimizing yield by recommending the most suitable crop based on local weather patterns, soil attributes, and other pertinent factors. This proposed design, incorporating machine learning algorithms like Random Forest and SVM, is envisioned to enable precise crop yield predictions with an accuracy exceeding 97 percent. By leveraging data provided through sensors utilized in Precision Farming, this model stands to significantly enhance farmers\' ability to achieve higher-quality and bountiful harvests.
References
[1] Rushika G., Juilee K, Pooja M, Sachee N, and Priya R.L.(2018). Prediction of Crop Yield using Machine Learning, Issue 02 IRJET (pg 2337-2339). [2] Ruchita T, Shreya B, Prasanna D, and Anagha C (2017). Crop Yield Prediction using Big Data Analytics, Volume 6, Issue 11, IJCMS. [3] Monali P, Santosh K, Vishwakarma, and Ashok V (2015). Analysis of Soil Behaviour and Prediction of Crop Yield using Data Mining Approach, ICCICN 2015. [4] Mrs. N. Hemageetha, and Dr. G.M. Nasira (2016). Analysis of Soil Condition based on pH value using Classification Techniques, IOSR-JCE, Issue 6, (pp.50-54). [5] E. Manjula, and S. Djodiltachoumy (2017). Data Mining Technique to Analyze Soil Nutrients based on Hybrid Classification. IJARCS. [6] Rohit Kumar Rajak, Ankit Pawar, Mitalee Pendke, Pooja Shinde, Suresh Rathod, and Avinash Devare (2017). Crop Recommendation System to maximize Crop yield using Machine Learning. Issue 12 IRJET. [7] S. Veenadhari, Dr. Bharat Misra, Dr. CD singh (2014). Machine Learning Approach for Forecasting Crop Yield based on Climatic Parameters. ICCCI-2014. [8] Sadia A, Abu Talha K, Mahrin Mahia, Wasit A, and Rashedur M.R.(2018). Analysis of Soil Properties and Climatic Data To Predict Crop Yields and Cluster Different Agricultural Regions of Bangladesh, IEEE ICIS 2018 (pp.80-85). [9] Arun K, Navin K, and Vishal V (2018). Efficient Crop Yield Prediction using Machine Learning, (pp.3151-3159), IRJET. [10] Subhadra M, Debahuti M, Gour, H. S.(2016). Applications of Machine Learning Techniques in Agricultural Crop Production: A Review Paper, Vol 9(38), DOI:10.17485/ijst/2016/v9i38/95032 IJST.
Copyright
Copyright © 2024 Dr Kalaivani D, Nikhil Kamate, Om Gawade, Pinaki Matruprasad, Vamsi Krishna Sai. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET58248
Publish Date : 2024-01-31
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online