

Ijraset Journal For Research in Applied Science and Engineering Technology
Self-Driving Car
Authors: Mihir M Parmar, Rokhi R Rawlo, Jaywant L Shirke, Dr. Savita Sangam
DOI Link: https://doi.org/10.22214/ijraset.2022.41786
Certificate: View Certificate
Abstract
Every person in this world is concerned about being safe. Increasing safety and reducing road accidents, thereby saving lives are of great interest in the context of Advanced Driver Assistance Systems. Among the complex and challenging tasks of future road vehicles is road lane detection or road boundaries detection. In driving assistance systems, obstacle detection especially for moving object detection is a key component of collision avoidance. Many sensors can be used for obstacle detection and lane detection, such as laser, radar and vision sensors. The most frequently used principal approach to detect road boundaries and lanes using a vision system on the vehicle. Detecting all kinds of obstacles on the road, mainly include the IPM (Inverse Perspective Mapping) method. The system acquires the front view using a camera mounted on the vehicle then applying a few processes in order to detect the lanes and objects. A versatile methodology is used in order to detect the lanes and objects. In our research we have developed a simple heuristic method which is more robust in both lane detection object detection and tracking in video. In this method we use clustering methodology to group the detected points in case of lane detection. Heuristic gives effective results in detection and tracking of multiple vehicles at a time irrespective to the distance.
Introduction
A. INTRODUCTION
Everybody in this world is concerned about safety. The people who go out from one place to another, expect to reach safely. Without any sudden incidents which may come through externally by road accidents while traveling. We can avoid road accidents by using improved driving assistance. Vehicle crashes remain the leading cause of accidental death and injuries in most traffic congested countries e.g. UK, USA, and Asian countries claiming tens of thousands of lives and injuring millions of people each year. Most of these transportation deaths and injuries occur on the nation’s highways. Therefore, a system that provides a means of warning the driver of the danger has the potential to save a considerable number of lives.
One of the main technologies involved in these tasks is computer vision, which has become a powerful tool for sensing the environment and has been widely used in many applications by the intelligent transportation systems (ITS). In order to increase safety and reduce road accidents, people are spending lots of money for the advancement in driving techniques which ensures safety. Technology makes men think more to improve safety to save lives. Automobiles are more conscious of providing safety features like seat belts, air bags and strong body structures which provide the passive safety that may reduce the effects of an accident. Avoiding accidents and saving lives are one of great interests that all researchers and Automobile companies work on.
In Advanced Driver Assistance Systems in order to achieve the desired safety on roads, the complex and challenging tasks of future road vehicles are road lanes detection or boundaries detection (white and black lines on roads) and Obstacles detection (cars, pedestrians, trees, etc) especially for moving object detection is a key component of collision avoidance in driving assistance systems. Many sensors can be used for lane detection and obstacle detection, such as laser, radar and vision sensors. Detecting all kinds of obstacles on the roads mainly includes the IPM (inverse perspective mapping) method.
The system acquires the front view using a camera mounted on the vehicle, then applying a few processes in order to detect the lanes and objects. A versatile methodology is used in order to detect the lanes and objects. Cars equipped with intelligent systems like road lane detection and obstacle detection makes vehicles safer, which is vital in decreasing the number of victims or injured people by car accidents. Principal approaches to detection are using a vision system on the vehicle. In our research we have developed a simple heuristic method to improve the robustness of lane detection and object detection and tracking in relation to intelligent transportation systems. In the Heuristic method, clustering methodology is used to group the detected points and a best fit line in the mean square sense to detect the lanes. Which, cmpared with other methods, gives better lane detection.
II. OVERVIEW OF THE PROPOSED SYSTEM
A. Lane Detection
Self-Driving Cars are one of the most disruptive innovations in AI. Fueled by Deep Learning algorithms, they are continuously driving our society forward and creating new opportunities in the mobility sector. An autonomous car can go anywhere a traditional car can go and does everything that an experienced human driver does. But it’s very essential to train it properly. One of the many steps involved during the training of an autonomous driving car is lane detection, which is the preliminary step.
B. Object Detection
When it comes to the implementation of an Object Detection system, most of us are aware of state-of-the-art architectures like RCNN, Faster RCNN, RFCN, Yolo, etc. If you want to test them then you have to go through lots of dependencies, and those modules itself contains a huge number of files and maybe you need to break your head to fix many dependencies issues. The good news is that we have many TensorFlow pre-trained models based on those object detection frameworks in the form of ckpt files and pb files. The TensorFlow training model is derived from a .pb binary file, which holds the topology of the network training (topology) consisting of the model structure and weights. Now, let us follow the following steps to build an object detection model.
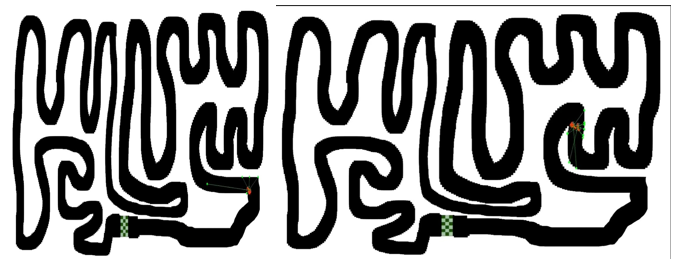
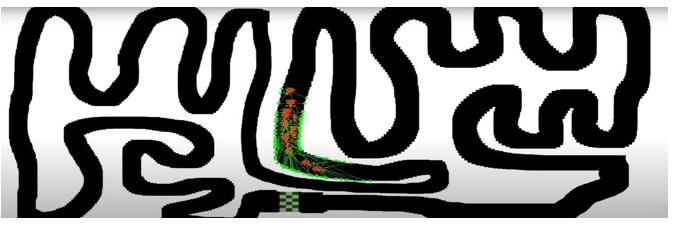
C. Self-Driving car Through NEAT
The NEAT algorithm chooses a direct encoding methodology because of this. Their representation is a little more complex than a simple graph or binary encoding, however, it is still straightforward to understand. It simply has two lists of genes, a series of nodes and a series of connections. Input and output nodes are not evolved in the node gene list. Hidden nodes can be added or removed.
III. IMPLEMENTATION
A. For Real Time Lane Line Detection
- Capturing and Decoding Video File: We will capture the video using the Video Capture object and after the capturing has been initialized every video frame is decoded.
- Grayscale Conversion of Image: The video frames are in RGB format, RGB is converted to grayscale because processing a single channel image is faster than processing a three-channel color image.

3. Reduce Noise: Noise can create false edges, therefore before going further, it’s imperative to perform image smoothening. A Gaussian filter is used to perform this process.

4. Canny Edge Detector: It computes gradients in all directions of our blurred image and traces the edges with large changes in intensity.

5. Region of Interest: This step is to take into account only the region covered by the road lane. A mask is created here, which is of the same dimension as our road image. Furthermore, bitwise AND operation is performed between each pixel of our canny image and this mask. It ultimately masks the canny image and shows the region of interest traced by the polygonal contour of the mask.
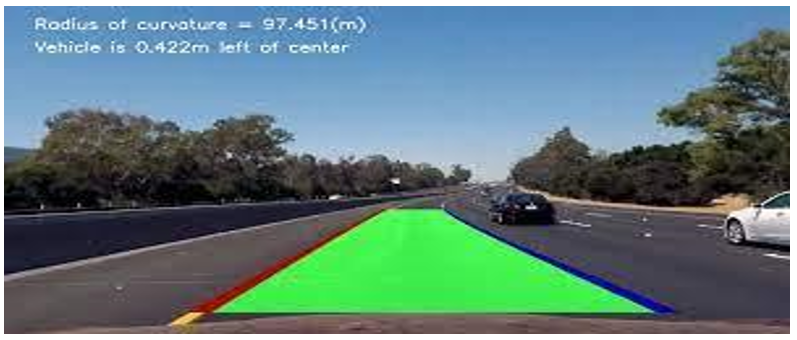
6. Hough Line Transform: The Hough Line Transform is a transform used to detect straight lines. The Probabilistic Hough Line Transform is used here, which gives output as the extremes of the detected lines

7. Dataset: The dataset consists of the video file of a road. Now let’s start the implementation process:
8. NumPy: It comes by default with anaconda
9. Matplotlib: To install matplotlib, type – “pip install matplotlib” into your command line
10. OpenCV: It can be installed in two ways, using anaconda or using pip. To install using anaconda, type- “conda install -c conda-forge opencv”, or to install using pip, type-“pip install opencv-python” into your command line.
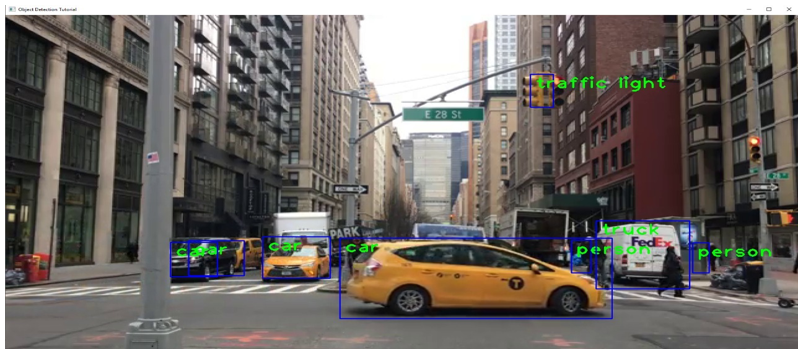
B. Real Time Object detection using COCO Model
COCO stands for Common Objects in Context, as the image dataset was created with the goal of advancing image recognition. The COCO dataset contains challenging, high-quality visual datasets for computer vision, mostly state-of-the-art neural networks.
For example, COCO is often used to benchmark algorithms to compare the performance of real-time object detection. The format of the COCO dataset is automatically interpreted by advanced neural network libraries.
C. Implementation of NEAT Algorithm
NEAT is an evolutionary method. This is a black box approach to optimization of functions. In this case - performance of the neural net (which can be easily measured) to its architecture (which you alter during evolution).
Reinforcement learning is about agents, learning policies to behave well in the environment.
Thus they solve different, more complex problems. In theory you could learn NEAT using RL, as you might pose the problem of "given a neural network as a state, learn how to modify it over time to get better performance". The crucial difference will be - NEAT output is a network, RL output is a policy, strategy, algorithm. Something that can be used multiple times to work in some environment, take actions and obtain rewards.
IV. RESULT ANALYSIS
Self-driving cars are regarded as the future of transportation. In the near future, self-driving cars will ferry passengers from one place to another, like driverless taxis, and transport packages and raw materials from city to city. However, for all the optimism surrounding self-driving cars, there is also an equal amount of skepticism and concern. Many people believe that self-driving vehicles will be “no safer” than human-controlled vehicles. Therefore, the willingness of the public to ride in a fully self-driving vehicle will be very low due to nonzero accident rates.
A lot more data and testing are required to influence the public’s beliefs on self-driving vehicles being ready for the road. Collecting more datasets will help to improve self-driving car modeling using data analysis; however, an incremental approach has to be taken for in-depth exploration of data analysis techniques applied to self-driving cars.
Conclusion
The lane detection techniques play a significant role in intelligent transport systems. In this paper, lane detection methods have been studied. Most of them resulted in inaccurate results. Therefore, further improvements can be done to enhance the results. In the near future, one can modify the existing Hough Transformation so that it can measure both the curved and straight roads. Various steps should be taken to improve the results in different environmental conditions like sunny day, foggy day, rainy day etc. For checking the effectiveness and detection of the scheme, we have used COCO datasets. We have compared the values of different metrics such as mAP, loss function, aspect ratio, and FPS with other previous models, which indicates that the proposed algorithm achieves a higher mAP, uses more frames to gain good speed, and obtains acceptable accuracy for detecting objects from color images.
References
[1] Aly, M. Real time detection of lane markers in urban streets. In Proceedings of the IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008. [2] Kumar, A.M.; Simon, P. Review of Lane Detection and Tracking Algorithms in Advanced Driver Assistance System. Int. J. Comput. Sci. Inf. Technol. 2015, 7, 65–78. [CrossRef] [3] Daigavane, P.; Bajaj, P. Road Lane Detection with Improved Canny Edges Using Ant Colony Optimization. In Proceedings of the 3rd International Conference on Emerging Trends in Engineering and Technology, Goa, India, 19–21 November 2010. [4] Kim, Z. Robust lane detection and tracking in challenging scenarios. IEEE Trans. Intell. Transp. Syst. 2008, 9, 16–26. [CrossRef]
Copyright
Copyright © 2022 Mihir M Parmar, Rokhi R Rawlo, Jaywant L Shirke, Dr. Savita Sangam. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET41786
Publish Date : 2022-04-23
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online