

Ijraset Journal For Research in Applied Science and Engineering Technology
Sentiment Analysis on Covid-19 Using Deep Learning
Authors: Soni Mehta, Shruti Pednekar
DOI Link: https://doi.org/10.22214/ijraset.2022.45872
Certificate: View Certificate
Abstract
The social media has immense popularity among all the services today. Twitter is one of the widely used platform by people to express their opinions and display sentiments on different occasions. Sentiment Analysis is a classification task in order to identify public reviews about different issues like reviews about movies, restaurants and other current issues by extracting the public reviews from social media. As we all know the world was hit by a global pandemic of COVID-19 and it is still a global issue. Due to rapid increase in the infection people were expressing their emotions, thoughts, and were having mixed feelings regarding the situation. The main objective of this research paper is to analyze the emotions expressed by people using twitter data. The corona specific tweets are collected from twitter and pre-processing is done to clean the data and later word embedding pre-trained model is used and finally CNN, LSTM and CNN-BiLSTM hybrid deep learning approaches are applied. The mode l is evaluated using accuracy, precision and recall techniques.
Introduction
I. INTRODUCTION
The rise of Internet technology has played an unprecedented role in increasing the number of social media and e-commerce platforms. In addition, users are now accustomed to the idea of expressing their feelings and emotions with others by using these platforms either by text or multimedia data. This phenomenon has resulted in the production and generation of a large variety of data, which can be analysed for assessing sentiment. It is beneficial for individuals and organizations to analyze sentiment, especially given this immense production of data.
Sentiment Analysis has attracted a lot of attention from researches from recent times. Nowadays, a massive amount of information exchange through web-based technologies and Internet-based users are expressing their emotions through social media, microblogging sites, and other media with the help of the Internet. The Sentiment Analysis is the most important methodology to classify the user’s opinions, emotions to determine whether the particular outlook is positive, negative, or neutral feedback on certain issues like movie reviews, political opinions, global pandemics, and other economic crises.
Deep learning involves applying artificial neural networks to learn different tasks using networks that are attributed to different layers. The search primarily takes inspiration from the way that the human brain is structured, as it contains a large number of entities (neurons) that are used for processing the information. The use of neural networks plays an important role at different levels for analyzing sentiment, including the document level, aspect level, and sentence level.
In this paper, we have proposed CNN, LSTM and CNN-BiLSTM method for the sentiment analysis of twitter data having 1.7 lakh tweets. The approach mainly consists of extracting the tweets, pre-processing of the tweets, applying word embedding model to extract word embedding for words using Glove and FastText pre-trained models and finally comparing the deep learning approaches.
II. RELATED WORK
Sentiment analysis involves investigating the approach of a writer toward a particular subject or the overall contextual polarity of an entire document. With the major increment in the amount of online data generated, Numerous studies have used sentiment analysis to classify texts based on sentiment or opinion using various machine learning and deep learning approaches. In recent times, sentiment analysis has involved a substantial amount of work and is growing rapidly.
Akshat Shrivastava [2] this paper utilized the live twitter dataset where the pre-processor is applied to the crude sentences. Further, the diverse ML strategies prepare the dataset with highlights and afterward the semantic investigation offers an enormous arrangement of equivalent words and comparability which gives the extremity of the substance. Naïve bayes, maximum entropy and support vector machine algorithm is used to classify data.
Sani Kamis [3], This study presents a comparison of different deep learning methods used for sentiment analysis in Twitter data.
Particularly, two categories of neural networks are utilized, convolutional neural networks (CNN) and recurrent neural networks (RNN). Additionally, different word embedding systems such as the Word2Vec and the global vectors for word representation (GloVe) models are compared. Various tests and combinations are applied and best scoring values for each model are compared in terms of their performance.
Manoj Sethi [4] in this study, the sole focus is to analyze the emotions expressed by people using social media such as Twitter etc. Corona specific tweets are acquired from twitter platform. After gathering the tweets, they are labelled and a model is developed which is effective for detecting the actual sentiment behind a tweet related to COVID-19. The substantial assessments are performed in bi-class and multi-class setting over n-gram feature set along with cross-dataset evaluation of different machine learning techniques like logistic regression, XG boost, SVM in order to develop the model.
Nikhil Yadav[5], This paper emphasizes the different techniques utilized for classifying the product critiques (which can be within the form of tweets) according to critiques expressed in tweets to analyze whether or not the massive behaviour is positive, negative or neutral and use of that analysis for the evaluation of product market. Data used in this look at our online product critiques gathered from twitter and used to rank the satisfactory classifier for sentiments.
III. METHODOLOGY
A. Dataset Description
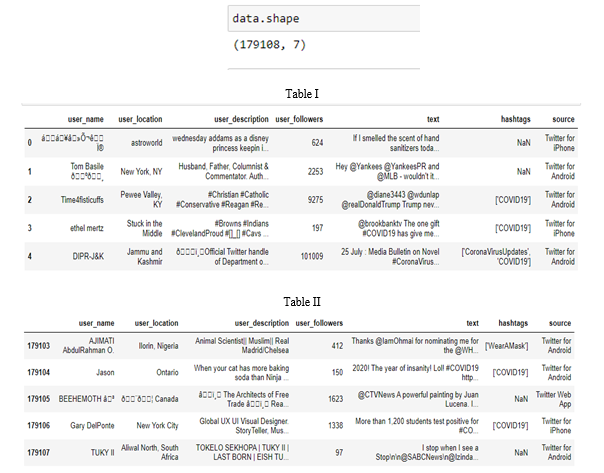
Twitter is used as the primary data source in order to gather tweets specific to corona virus. The data used in this work is comprised of a large number of tweets collected from GitHub repository [1]. The collected data is in form of positive, negative and neutral tweets. We have total of 1.79 lakh tweets. The dataset has 7 attributes. The attribute details are shown in Table I and Table II.
B. Pre-Processing Dataset
Raw tweets scratched from the twitter contain lots of noise data, misspelt words, include various abbreviations, emojis and so on this is because of the easy-going ideas of individuals utilization of social media. These words often disturb the sentiments of the tweets and might not give perfect accuracy. Therefore, tweets are pre-processed before performing word embedding techniques. Pre-processing basically means cleaning and removing of non-textual substances from the dataset to improve the performance of the proposed model. Below are the steps used for pre-processing of tweets:
- Converting upper case to lower case.
- Strip spaces and quotes ("and’) from the ends of tweet.
- Removal of re-tweets, URL, Hashtags, Mentions.
- Stopword Removal: Stop words that don’t affect the meaning of the text or the sentences are removed for example and, or, still, the, which etc…
- Tokenization and lemmatization: Tokenization is method of separating the text into the words which are called tokens and lemmatization are used to break these words into typical root word for instances, the word “troubling” “troubled” “troubles” will be diminished into a root word “trouble”.

5. Word Embedding
Word embedding is a method of a feature extraction which will help in boosting the accuracy of deep learning, machine learning and natural language processing task by converting each word into its corresponding vector represented using pre-trained model and our dataset.
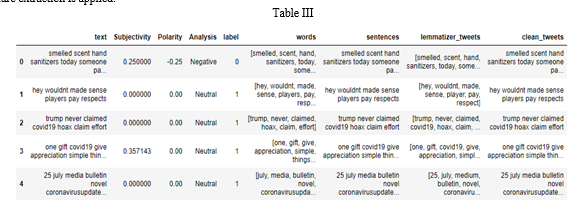
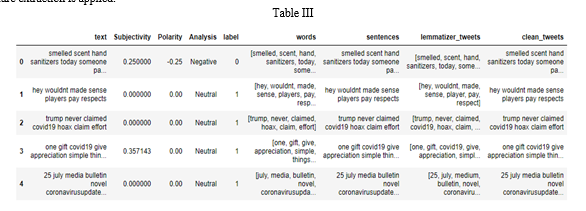
Feature extraction in the case of sentiment analysis is used to analyze sentiments from subjective texts and to find the polarity by classifying the data into positive, negative, and neutral. Table III shows us the cleaned data after the pre-processing is done and feature extraction is applied.
The two basic pre-trained models we will be using are FastText and Glove(Global Vectors for word representation).
- Glove: GloVe is an unsupervised learning algorithm to learn vector representation i.e word embedding for various words. The model was proposed by Pennington et al. (2014). The GloVe is a pre-trained word embedding method used for solving deep learning. It is a modified version of word2Vec embedding techniques in order to solve the problem of word2Vec weakness. We have used the 6B version of the GloVe vector with 200 billion tokenized web data with 200-dimensional wordvectors in this project.
- FastText: FastText is an NLP library developed by the Facebook research team for text classification and word embeddings. FastText is popular due to its training speed and accuracy. There are two frameworks of FastText Text Representation (fastText word embeddings)and Text Classification. In FastText each word is represented as a bag of character n-gram. FastText word embeddings supports both Continuous Bag of Words (CBOW) and Skip-Gram models For this project, we will use Gensim fastText library to train fastText word embeddings in Python.
E. Convolution Neural Network (CNN)
We used keras with TensorFlow backend to implement the Convolutional Neural Network model. We used the dense vector representation of the tweets to train our CNN models. The function of CNN is to extract effective features from sequences. The first step is using the word vector matrix as the input to CNN model; the second step is to use convolution kernel to construct local n-gram features from word vector matrix; the third step is the maximum pool of the result of each convolution kernel; We perform temporal convolution with a kernel size of 64 and zero padding. After the convolution layer, we apply relu activation function and then perform Max Pooling over time to reduce the dimensionality of the data. We also added dense and dropout layers after the embedding layer and the fully connected layer to regularize our network and prevent it from overfitting-Pooling is a way of feature processing in convolution neural network, usually after convolution operation. The purpose of pooling is to calculate the local sufficient statistics. Max-pooling can extract the most important features from the convolution layer.

F. Long-Short Term Memory (LSTM)
Next, we use LSTM model for training our dataset. Here, the embedding layer is followed by an LSTM layer where we experimented with different number of LSTM units. The LSTM layer is followed by a fully-connected layer with 128 units and relu activation. In this configuration a single LSTM layer is used with a dropout of 60%. LSTM consists of two states: hidden state and cell state. At a particular time, step t, LSTM decides which information must be taken from the state of the cell. The decision is made by a sigmoid function layer called the forget gate.

G. Convolution Neural Network with Bidirectional Long-Short Term Memory (CNN-BiLSTM)
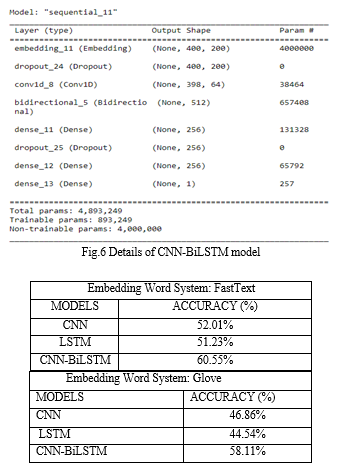
In CNN-BiLSTM approach, First embedding layer passes features into drop out layer with the rate to 0.2 to avoid over fitting. The output feds into first 1-Dimensional CNN layer. Further, we will define 64 filters. This allows us to train 64 different features on the second layer of the network. The result will be fed into the Bi-LSTM layer of size 64 to capture long range dependencies to extract feature and then feed into the Fully Connected Dense layer. Next, the output of Dense Layer passes to drop out with a rate of 256, the purpose of which to drop some randomly weights of the matrix. Finally, we get the fully connected dense layer with sigmoid function.
Conclusion
Sentiment Analysis is a task to realize the expression of public feelings expressed on social media about different issues to detect whether the people’s outlook is positive, negative, and neutral. The main objective of this project was to detect and classify the public emotion, which is talked about the COVID-19 global pandemic using a deep learning (CNN, LSTM, CNN-BiLSTM) model with the help of open sources pre-trained (FastText and GloVe) models in order to get good accuracy. The Overall experiments shows 58% accuracy of CNN-BiLSTM model obtained using Glove pre-trained model and 60% accuracy obtained using FastText pre-trained model of CNN-BiLSTM model. It is seen that the hybrid model provides better result and accuracy than the single CNN and LSTM approach. In future work, we can try to extract more dataset and apply more hybrid deep learning approaches to get better accuracy and better classification results.
References
[1] https://www.kaggle.com/gpreda/covid19-tweets. [2] Akshat Shrivastava, Anurag Sen, Amritansh Shrivastava, Sachin Singh, Nagesh Jadhav, “Collective Intelligence Sentiment Analysis of Tweets using Machine Learning”, International Journal of Scientific & Engineering Research Volume 11, Issue 6, June-2020. [3] Sani Kamis , Dionysis Goularas, “Evaluation of Deep Learning Techniques in Sentiment Analysis from Twitter Data”, 2019 International Conference on Deep Learning and Machine Learning in Emerging Applications (Deep-ML). [4] Manoj Sethi , Sarthak Pandey , Prashant Trar, Prateek Soni, “Sentiment Identification in COVID-19 Specific Tweets”, Proceedings of the International Conference on Electronics and Sustainable Communication Systems (ICESC 2020). [5] Nikhil Yadav, Omkar Kudale, Srishti Gupta, Aditi Rao, \"Twitter Sentiment Analysis Using Machine Learning For Product Evaluation\",Proceedings of the Fifth International Conference on Inventive Computation Technologies (ICICT-2020). [6] Vishu Tyagi, Ashwini Kumar, Sanjoy Das, “Sentiment Analysis on Twitter Data Using Deep Learning approach”, 2020 2nd International Conference on Advances in Computing, Communication Control and Networking (ICACCCN). [7] Anu J Nair, Veena G, Aadithya Vinayak,\"Comparative study of Twitter Sentiment On COVID - 19 Tweets\",Proceedings of the Fifth International Conference on Computing Methodologies and Communication (ICCMC 2021). [8] Bhumika Gupta, Monika Negi, Kanika Vishwakarma, Goldi Rawat, Priyanka Badhani, \"Study of Twitter Sentiment Analysis using Machine Learning Algorithms on Python\",,International Journal of Computer Applications (0975 – 8887)Volume 165 – No.9, May 2017.
Copyright
Copyright © 2022 Soni Mehta, Shruti Pednekar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET45872
Publish Date : 2022-07-21
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online