

Ijraset Journal For Research in Applied Science and Engineering Technology
Sign Language Recognition System Using Neural Networks
Authors: Senthilkumar K, Prabakaran R
DOI Link: https://doi.org/10.22214/ijraset.2022.43787
Certificate: View Certificate
Abstract
Sign language is that the only tool of communication for the one who isn\\\'t ready to speak and listen to anything. Language could be a boon for the physically challenged people to precise their thoughts and emotion. During this work, a unique scheme of signing recognition has been proposed for identifying the alphabets and gestures in linguistic communication. With the assistance of computer vision and neural networks we will detect the signs and provides the respective text output
Introduction
I. INTRODUCTION
Sign Language may be a language that has gestures with bodily movements made with the hands including facial expressions and postures. it's mainly utilized by those who are deaf and dumb. There are many alternative sign languages like British, Indian and American sign languages.
People with disabilities like deaf and dumb use linguistic communication as a tool to precise their emotions and thoughts to folk around them. Yet the final public finds it hard to know the sign and so such a trained system like signing recognition is required during medical and legal appointments, educational and training sessions and for the world meetings being held. some years ago, there has been a rise in demand for such systems which are formed as video remote human interpreters using high-speed internet connectivity which provided a straightforward thanks to translate the language that has been used and benefited from yet had a various number of limitations.
To overcome this, we use an extended STM (LSTM) model to detect the actions in signing. A neural network of six layers is made using LSTM deep learning model within which three are LSTM layers and also the other three are Dense layers. The dataset we use contains the actions as a selected number of sequences stored as frames which are captured using OpenCV with an interval of your time.
II. SYSTEM ANALYSIS
A. Existing System
in the existing systems, many of us used two handed signs where many felt that it's easy to try to to single hand gestures instead of two hands. From the past few years many approaches are implemented like Artificial Neural Network, mathematical logic, Genetic Algorithm et al. like PCA, Canonical Analysis, Matlab, SVM. With these algorithms we'll process the background image also which creates a conflict between the particular image and therefore the background.
B. Proposed System
Initially, the video of the person is captured using OpenCV which is taken as an input therefore the info is collected using MediaPipe holistic which detects the face, pose and hand landmarks as key points. The dataset to be stored as several sequences put in frames as video format where the key points are pushed into a NumPy array.Hereafter, the system is trained and built using Long STM (LSTM) deep learning model which is formed using three LSTM layers and three Dense layers.
This model was trained for 2000 epochs on a batch size of 128 using the dataset extracted. The model was trained using the dataset to attenuate the loss by categorical cross-entropy using the Adam optimizer.Finally, after building the neural network, real-time language recognition is performed using OpenCV where the gestures are recognized and displayed as text within the highlighted section.
The working of the proposed system is shown as a spec below:
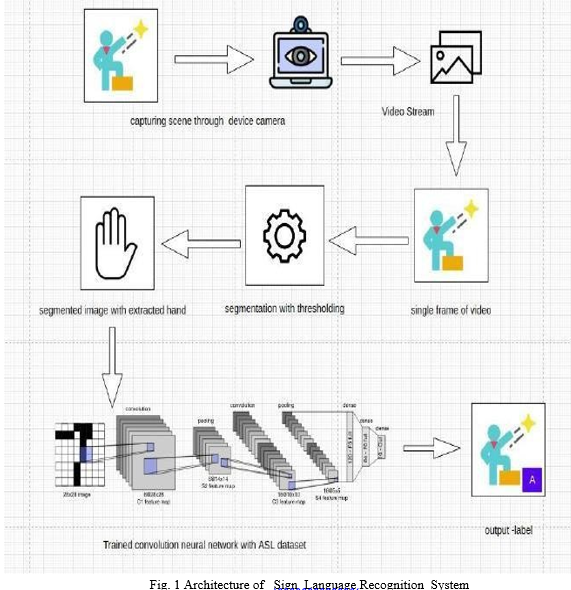
III. DESIGN
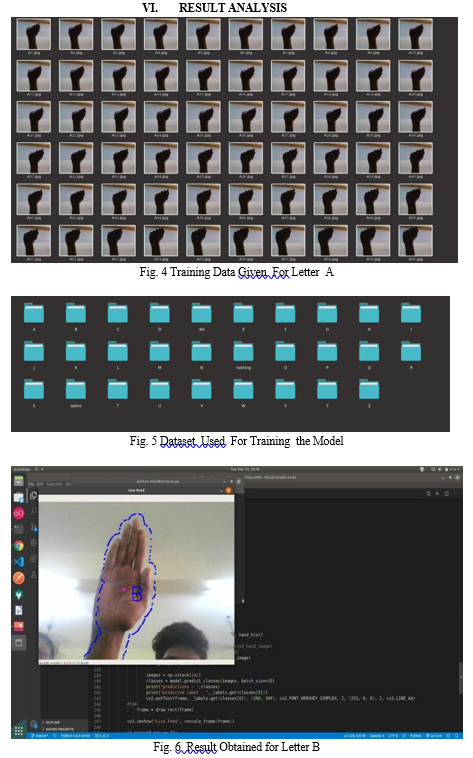
In order to implement our project, we've got to form a dataset. The dataset contains hundred of images which are captured by different people. After creating the dataset, whether dataset into training data and test data. The training data is employed to coach the algorithms and test data is employed to check the efficiency of the algorithm.Our system contains two modules. the primary one is general mode. Here the user shows the gesture and therefore the system will display the related text and provides a speech of that sign. The other helps mode. during this mode the system will display a sentence and also makes a speech. The sentences are the fundamental need for somebody, associated with the sign showed by the user.In order to spot the signs, the system start capturing the photographs by employing a camera. The captured images are going to be pre-processed and can be tested against the training model. If the image match with the dataset images, then the system will switch to either helping mode. In both the modes the system will display the text and offers the speech. If the gesture isn't recognised, then the image are going to be again given to training model. The follow the figures
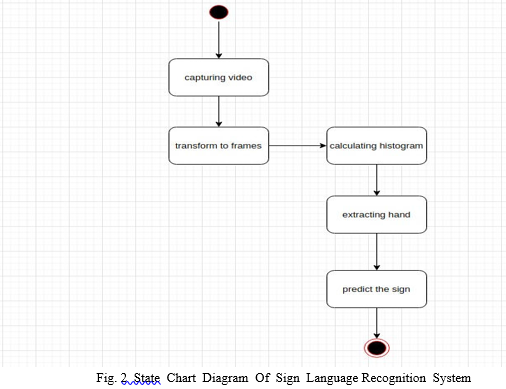
IV. SYSTEM MODULES
- Install and Import Dependencies: Here we do install all the desired tools i.e. TensorFlow, OpenCV, MediaPipe, Sklearn, matplotlib and import dependencies of NumPy, os, time and pyplot from matplotlib.
- Collecting key points from MediaPipe holistic: We detect Hand Landmarks and extract all the key points detected using MediaPipe holistic.
- Collecting and Pre-processing Data: We create folders to export the information to be stored as NumPy arrays and build labels.
- Training and Testing: Using TensorFlow and Keras we build and train the model using an LSTM deep learning neural network where the model summary and accuracy are defined and tested in real-time.
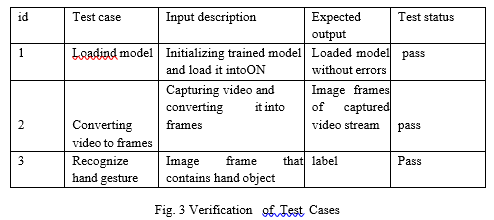
V. TESTING
Software testing is an important element of the software quality assurance and represents the ultimate review of specification, design and coding. The increasing feasibility of software as a system and the cost associated with the software failures are motivated forces for well planned through testing.
VII. FUTURE ENHANCEMENTS
- The proposed linguistic communication recognition system wont to recognize language letters are often further extended to acknowledge gestures facial expressions.
- Rather than displaying letter labels it'll be more appropriate to display sentences as more appropriate translation of language.
- This project can further be extended to convert the signs to speech.
VIII. ACKNOWLEDGMENT
This Research Article was supported by Department of MCA, Karpagam College of Engineering, Coimbatore. I have great satisfaction in presenting this article on "Sign Language Recognition System Using Convolution Neural Networks". I take this opportunity to express my sincere thanks to my guide, Prof Mr. k. Senthilkumar, for providing the technical guidelines and suggestions regarding the line of this work. I want to convey my gratitude for his constant encouragement, support and guidance throughout the project's development. I am grateful to Dr. K. Anuradha (Director In-Charge, Department of MCA); my project would not have shaped up without their support. I wish to express my deep gratitude toward all my Professor at Karpagam College of Engineering, Coimbatore, for their encouragement.
Conclusion
Nowadays, applications need several styles of images as sources of information for elucidation and analysis. Several features are to be extracted so on perform various applications. When an image is transformed from one form to a special like digitizing, scanning, and communicating, storing, etc. degradation occurs.Therefore the output image should undertake a process called image enhancement, which contains of a bunch of methods that seek to develop the visual presence of an image. Image enhancement is fundamentally enlightening the interpretability or awareness of knowledge in images for human listeners and providing better input for other automatic image processing systems. Image then undergoes feature extraction using various methods to form the image more readable by the pc.Sign language recognition system may be a robust tool to preparae an expert knowledge, edge detect and so the mixture of inaccurate information from different sources.The intend of convolution neural network is to induce the suitable classification.
References
[1] S. Sonkusare, N. B. Chopade, R. Sor, and S. L. Tade, \\\"A Review on Gesture Recognition System,\\\" 2015 Int. Conf Comput. Commun. Control Autom., pp. 790-794,201 [2] A. Thorat, V. Satpute, A. Nehe, T. Atre Y. Ngargoje, \\\"Indian Sign Language Recognition System for Deaf People,\\\" Int.J.Adv. compt. comm. engg. IJARCCE, pp.5319-5321 ,2014. [3] McInnes J M and Treffry J A 1993 Deaf-blind Infants and Children: A Developmental Guid (Toronto : University of Toronto Press). [4] Chen L, Lin H, Li S (2012) Depth image enhancement for Kinect using region growing and bilateral filter. In: Proceedings of the 21st international conference on pattern recognition (ICPR2012).IEEE, pp 3070–3073 [5] Meena, S.,2011.A Study on hand Gesture Recognition. Doctoral dissertation, National Institute Of Technology, Rourkela. [6] Van den Bergh, M., 2010. Visual body pose analysis for human-computer interaction. Diss, Eidgenössische Technische Hochschule ETH Zürich, Nr. 18838.
Copyright
Copyright © 2022 Senthilkumar K, Prabakaran R. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET43787
Publish Date : 2022-06-03
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online