

Ijraset Journal For Research in Applied Science and Engineering Technology
Sign Language Recognition using Deep Learning
Authors: Dhruv Sood
DOI Link: https://doi.org/10.22214/ijraset.2022.40627
Certificate: View Certificate
Abstract
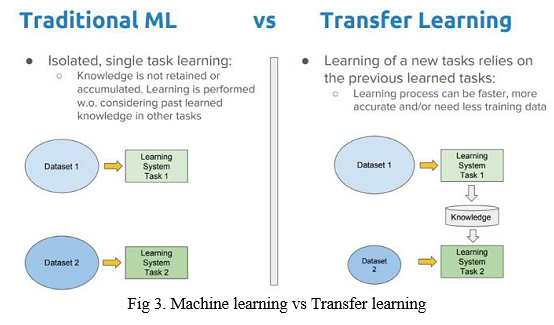
Millions of people with speech and hearing impairments communicate with sign languages every day. For hearing-impaired people, gesture recognition is a natural way of communicating, much like voice recognition is for most people. In this study, we look at the issue of translating/converting sign language to text and propose a better solution based on machine learning techniques. We want to establish a system that hearing-impaired people may utilise in their everyday lives to promote communication and collaboration between hearing-impaired people and people who aren\'t trained in American Sign Language (ASL). To develop a deep learning model for the ASL dataset, we\'ll use a technique called Transfer Learning in combination with Data Augmentation.
Introduction
I. INTRODUCTION
Sign language is used to communicate by those who are deaf or hard of hearing. People employ nonverbal communication such as sign language movements to communicate their thoughts and emotions. Non-signers, on the other hand, have a hard time understanding it, which is why skilled sign language interpreters are required for medical and legal consultations, as well as educational and training sessions. Over the last few years, the demand for translation services has significantly increased. Other methods have been devised, such as video remote human interpreting using high-speed Internet connections. As a result, they will provide a simple sign language translating service that may be used but has significant restrictions.
In the literature, certain studies [1]–[3] for automated ASL recognition have previously been published. Some of these algorithms have only been tested on a small sample dataset, while others rely on the typical shallow neural network approach to classification. Shallow neural networks need feature identification and appropriate feature selection by hand. Deep learning (DL) approaches have considerably enhanced the performance of classic shallow neural networks for machine learning applications, particularly for image recognition and computer vision issues.
The rest of this paper is organised as follows: A brief summary of comparable investigations described in the literature is provided in section II. A brief overview of the dataset utilised in this study is provided in section III. In section IV, the proposed approach is described. The study's findings are provided in part V, and the study's primary findings are summarised in section VI.
II. BACKGROUND
To develop a deep learning model for the ASL dataset, we'll use a technique called Transfer Learning in combination with Data Augmentation. Transfer learning is a machine learning approach in which a model developed for one task is utilised as the foundation for another task's model. Given the massive computing and time resources necessary to construct neural network models for these challenges, as well as the significant leaps in skill that they give on related problems, pre-trained models are a common strategy in deep learning for computer vision and natural language processing applications.
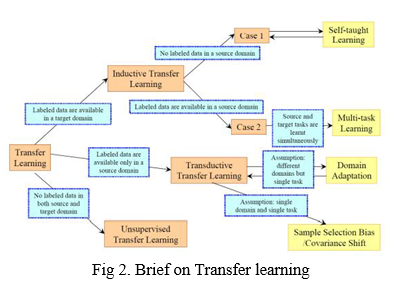
Two common approaches are as follows:
- Develop Model Approach
a. Choose a source task. You must choose a relevant predictive modelling issue with a large amount of data in which the input data, output data, and/or ideas learnt throughout the mapping from input to output data have some link.
b. Create a source model. The next step is to create a skilled model for this initial assignment. To ensure that any feature learning has occurred, the model must be better than a naïve model.
c. The Reuse Model: The model fit on the source job can then be utilized to build a model for the second task of interest. Depending on the modelling approach employed, this may include utilizing all or sections of the model.
d. Adjust the model. On the input-output pair data available for the job of interest, the model may need to be altered or enhanced.
2. Pre-trained Model Approach
a. Choose a source model. From the available models, a pre-trained source model is picked. Many research institutes produce models based on vast, difficult datasets, which may be included in the pool of candidate models to pick from.
b. The Reuse Model The pre-trained model may then be utilized to build a model for the second job of interest. Depending on the modelling approach employed, this may include utilizing all or sections of the model.
c. Fine-tune the model: On the input-output pair data available for the job of interest, the model may need to be altered or enhanced. This second type of transfer learning is common in the field of deep learning.
III. DATASET
This Kaggle dataset of ASL Alphabet was used to train the network. The dataset consists of 87,000 200x200 pixel photos organised into 29 types (26 English Alphabets and 3 additional signs of SPACE, DELETE, and NOTHING).
IV. PROPOSED ALGORITHM
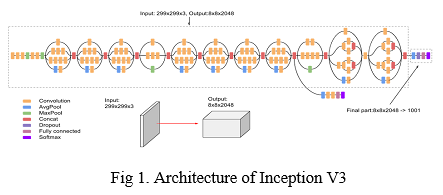
To develop a deep learning model for the ASL dataset, we'll use a technique called Transfer Learning in combination with Data Augmentation. Adding to the data: - We updated the data with brightness shift (range in 20 percent dimmer lighting conditions) and zoom shift to train the model for better real-world scenarios (zooming out up to 120 percent ). Google's Inception v3 model serves as the foundation for the transfer learning network. The first 248 layers of the model are locked (up to the third final inception block), leaving just the last two inception blocks for training. At the top of the Inception network, the Fully Connected layers are likewise deleted. After that, we construct our own set of Fully Connected layers and add them after the inception network to tailor the neural network for our purpose (consists of 2 Fully Connected layers, one consisting of 1024 ReLu units and the other of 29 Softmax units for the prediction of 29 classes). The model is then trained on a new set of photos from the ASL Application.
After the model has been trained, it is integrated into the application. OpenCV is used to grab frames from a video feed. The application provides an area (within the green rectangle) where the indicators for detection or recognition can be shown. The signs are then photographed in frames, which are then processed for the model and supplied to the model. Based on the sign created, the model predicts the sign captured. If the model predicts a sign with a confidence of greater than 20%, the prediction is presented to the user (LOW confidence sign predictions are predictions with a confidence of 20% to 50% and are presented with a Maybe [sign] - [confidence] output, and HIGH confidence sign predictions are predictions with a confidence of greater than 50% and are presented with a [sign] - [confidence] output, where [sign] is the model predicted sign a [sign] - [confidence] output, and HIGH confidence sign predictions areconfidence for that sign). Else, it will display “Nothing”.
V. EXPERIMENTAL RESULTS
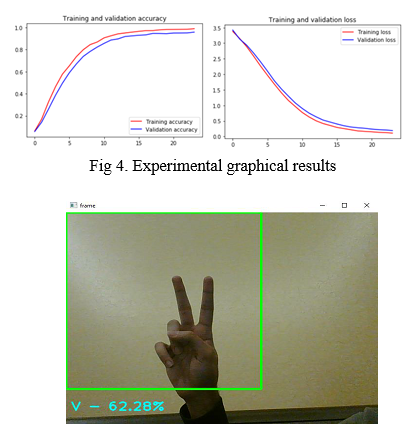
To train our model, we utilized Categorical Cross entropy to assess the loss and a Stochastic Gradient Descent optimizer (with a learning rate of 0.0001 and a momentum of 0.9). The model is trained over a period of 24 epochs. The following are the outcomes:
TABLE I
|
Metric |
Value |
|
Training accuracy |
0.9888 (98.88%) |
|
Training loss |
0.1100 |
|
Validation accuracy |
0.9576 (95.76%) |
|
Validation loss |
0.1926 |
|
Test accuracy |
96.43% |
VI. COMPARITIVE STUDY
In this paper, the authors split the dataset into two halves, one for training and the other for testing [12]. 70% of the aggregate data is utilized in the training set, whereas 30% is used for testing. They also did experiments on the same dataset (30% or 70%) for KNN classifier training and testing. The correctness of the outcomes of these trials was 100%. This implies that if the person who will be working on this project has previously contributed to this dataset, the algorithm will guarantee a 100% recognition rate. In another research, the system didn't perform particularly well, but it did show that a first-person sign language translation system can be developed using simple cameras and convolutional neural networks [13].
It was discovered that the model had a tendency to mix up various signs, such as U and W. However, after some consideration, it may not be necessary to achieve flawless performance because the use of an orthography corrector or a word predictor will improve translation accuracy. The next stage is to evaluate the solution and look for ways to make it better. Collecting additional high-quality data, experimenting with more convolutional neural network topologies, or revamping the vision system might all help.
But we could get an accuracy of 96% we could improve the accuracy by training the model for more epochs but that would require a better computer and a big data platform to accommodate the dataset and run the model sufficiently.
Conclusion
We used many technologies to go through an autonomous sign language gesture detection system in real-time in this project. Despite the fact that our suggested study aimed to identify sign language and convert it to text that we will try to implement in the future, there is still a lot of room for future research.
References
[1] V. Bheda and D. Radpour, “Using deep convolutional networks for gesture recognition in american sign language,” arXiv:1710.06836, 2017. [2] B. Garcia and S. A. Viesca, “Real-time american sign language recognition with convolutional neural networks,” Convolutional Neural Networks for Visual Recognition, vol. 2, 2016. [3] A. Barczak, N. Reyes, M. Abastillas, A. Piccio, and T. Susnjak, “A new 2d static hand gesture colour image dataset for asl gestures,” 2011. [4] https://machinelearningmastery.com/transfer-learning-for-deep-learning/ [5] K. Bantupalli and Y. Xie, \"American Sign Language Recognition using Deep Learning and Computer Vision,\" 2018 IEEE International Conference on Big Data (Big Data), 2018, pp. 4896-4899, doi: 10.1109/BigData.2018.8622141. [6] R. Fatmi, S. Rashad and R. Integlia, \"Comparing ANN, SVM, and HMM based Machine Learning Methods for American Sign Language Recognition using Wearable Motion Sensors,\" 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), 2019,pp.0290-0297, doi: 10.1109/CCWC.2019.8666491. [7] M. M. Rahman, M. S. Islam, M. H. Rahman, R. Sassi, M. W. Rivolta and M. Aktaruzzaman, \"A New Benchmark on American Sign Language Recognition using Convolutional Neural Network,\" 2019 International Conference on Sustainable Technologies for Industry 4.0 (STI),2019,pp.1-6,doi: 0.1109/STI47673.2019.9067974. [8] http://cs231n.stanford.edu/reports/2016/pdfs/214_Report.pdf [9] Sharma, S., Kumar, K. ASL-3DCNN: American sign language recognition technique using 3-D convolutional neural networks. Multimed Tools Appl 80, 26319–26331 (2021). https://doi.org/10.1007/s11042-021-10768-5 [10] Y. Ye, Y. Tian, M. Huenerfauth and J. Liu, \"Recognizing American Sign Language Gestures from Within Continuous Videos,\" 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2018, pp. 2145-214509, doi: 10.1109/CVPRW.2018.00280. [11] C.K.M. Lee, Kam K.H. Ng, Chun-Hsien Chen, H.C.W. Lau, S.Y. Chung, Tiffany Tsoi, American sign language recognition and training method with recurrent neural network, Expert Systems with Applications, Volume 167, 2021, 114403 [12] M. Taskiran, M. Killioglu and N. Kahraman, \"A Real-Time System for Recognition of American Sign Language by using Deep Learning,\" 2018 41st International Conference on Telecommunications and Signal Processing (TSP), 2018, pp. 1-5, doi: 10.1109/TSP.2018.8441304. [13] https://www.irjet.net/archives/V7/i3/IRJET-V7I3418.pdf [14] https://towardsdatascience.com/sign-language-recognition-using-deep-learning-6549268c60bd.
Copyright
Copyright © 2022 Dhruv Sood. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET40627
Publish Date : 2022-03-04
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online