

Ijraset Journal For Research in Applied Science and Engineering Technology
Skin Cancer Detection and Classification using GUI and Deep Neural Network
Authors: Afsha Hamid, Dr. Satish Saini
DOI Link: https://doi.org/10.22214/ijraset.2022.41337
Certificate: View Certificate
Abstract
Due to the good diversity in the pattern of lesion, classification of skin disease by photographs is tough. Deep networks (CNNs) have always shown promise in a variety of quite ok item categorization for a wide range of applications with significant variability. [6–11]. We illustrate how to categorise skin lesions using just pixels and disease labels as inputs, using a single CNN that was trained end-to-end from pictures. Early detection Malignant and other types of skin carcinoma focal cell carcinoma is crucial and can help prevent the progression of numerous forms of skin cancer. Regardless, there are several variables that reduce the accuracy of detection. In recent years, the usage in especially in the medical uses of image recognition and object recognition has skyrocketed. Based on previous clinical imaging data, we employed Convolutional Neural Networks (CNN) to detect and categorise cancer groups in this study. Some of our study objectives include developing a CNN model to detect skin cancer with an accuracy of >80%, keeping the false negative rate in the prediction below 10%, achieving a precision of >80%, and visualising our data. The suggested technique outperforms the other options under consideration, according to simulation results.
Introduction
I. INTRODUCTION
One of the biggest systems of the human body is the epidermis., and it controls our body temperature while also protecting us from extremes of heat and light. It's also the location of fat and water storage. When skin cells are damaged, for as by overexposure to ultraviolet (UV) light, skin cancer can develop [13]. In countries like Canada, the United States, and Australia, skin cancer is on the rise [14][15]. The danger of infection, which may lead to skin cancer, is one of the most significant difficulties with skin in the body. Skin cancer begins in the cells, which are the most basic components of the skin. Skin cells divide and develop at the same time, resulting in the formation of new cells. Skin cells die every day as we age, and new cells emerge to take their place. This meticulous technique may fail on occasion. When the skin doesn't need them, new cells are generated, and old cells are eliminated when they're no longer needed. A tumour, which is a mass of tissue, is formed when these extra cells multiply. Malignant seems to be the most common and lethal malignant neoplasm., as well as the one with the greatest death rate.
Melanoma has no known origins; however, it is believed that variables such as paternal heredity and UV exposure have a role in its development. Even though this disease has a good probability of being cured, it is nonetheless seen as a big issue owing to its pervasive prevalence. Melanoma is a cancer that affects our bodies mostly through the lymphatic and occasionally the circulatory systems, and it can spread to other sections of the body. According to study, finding melanoma early may help to reduce the risk of mortality, however it is a sad reality that detecting melanoma early is a challenging task even for specialists.
Therefore, using a strategy that can automate the diagnostic process and so remove manual errors will be advantageous. As indicated by various studies over the last several years, computer vision approaches and digital image processing are becoming increasingly popular in areas such as healthcare and many others. Therefore, using these techniques can speed up diagnostics and decrease human error.
Artificial Neural Networks (ANNs) are a sort of AI technology In latest years, it has found a lot of application in areas including computer vision, digital image processing, and image categorization techniques (ANN) Human barons contain numerous neural layers and perceptron, therefore artificial neural networks are built on these. Deep learning methods (CNNs) [1] are both a sort of perceptron that will be used to analyse images, classify objects, and identify them.
Using excisional visual photos, the strategy's efficacy was demonstrated to 21 sheet physicians. Due of their great value, and effective performance, CNNs are used in a range of medical imaging procedures, including lesion classification, MR image fusion, breast cancer and tumour detection, and panoptic analysis [3]..
II. LITERATURE REVIEW
Xie et al. [14] created a technique for classifying skin conditions among two main categories: harmless and dangerous. There are 3 parts to the system model. To eliminate lesions from photos, a self-generating NN was first utilised. Information such as disease borders, size, and coloration were retrieved in the phase two. A total of 57 traits were retrieved by the algorithm, included 7 novel traits related with lesion boundary definitions. The information' complexity was reduced using hierarchical clustering (PCA), leading the best set of features to be picked. A NN predictor was used to diagnose cancers in the final phase. By merging training algorithm (BP) NN and fuzzy neural networks, Synthesis NN enhances classi?cation accuracy. The classified results of the proposed system were also examined to those of current loaders such as SVM, KNN, randomized forests, Adaboot, among others..
Mumford–Shah and Harris Stephen algorithms were used to extract a mole's asymmetry and limitations. The proposed technique classified any colour different than black, cinnamon, or brown as melanoma since usual moles are black, cinnamon, or brown. Because melanoma moles typically have a diameter higher than that, the melanoma detection threshold was established at 6 mm. The suggested system uses a backpropagation feed-forward ANN to accurately classify moles into one of three categories: common mole, rare mole, or melanoma mole, with an accuracy of 97.51 percent. [12] It was suggested that an automated skin cancer diagnosis system based on backpropagation ANNs be built.
III. OBJECTIVES
This paper expands on a research on the topic of Transfer Learning regarding the influence of generating synthetic samples by dividing original images and shuffling the resulting slices, and training a model on two classes training samples then combining them to get a deep model and GUI that can classify all eight (8) classes, as a way to overcome the problem of unbalanced data sets that the skin lesions dataset from the ISIC archive is known for all the baseline models to meet the ai requirements..:
IV. METHODOLOGY
A. Convolutional Neural Networks
Convolution (ConvNets) are a special type of Artificial Neural Network that concentrates on the concept of convolution. ConvNets are particularly well-suited to image processing, but the same ideas may be applied to other domains like as audio and video. This section describes how to utilise ConvNets to process images. Many convolution and pooling layers make up a ConvNet. There is normally a fully linked layer at the end. After one or more convolution layers, a pooling layer is added. The purpose of the The purpose of convolutional is to gather insights from the output.resulting in a variety of feature maps. The spatial size of these feature maps is reduced due to the pooling layer. Convolution is widely used in image processing. It edits photographs and pulls information from them. As a result, there are a wide range of filters available, each with a distinct kernel size. The Sobel filter, for illustration, has a block size if 33% and so will be employed with fourier on an image. The end effect is a snapshot that reveals the edges of the actual picture.. Feature extraction filtering are the foundation of ConvNets. Rather of employing pre-programmed filters, the ConvNet learns them. However, in order to apply this to neural networks, the topologies of neural networks must be changed. The convolution and pooling layers will be discussed in the following sections. The ConvNets were constructed utilising material from Goodfellow et albook[5] and the Stanford Lecture...
1. Convolution Layer
A convolution layer has the same units as a typical neural network, but they are organised differently, and the connectionism is different. The key distinctions between neural networks and artificial intelligence are as follows:
Instead of a single dimension, the units are arranged in three dimensions.
The three-dimensional arrangement is built on the base of the image. A two-dimensional matrix defines every one of the triple RGB (red, green, and blue) connections in a vivid picture. The ConvNet's input is two half matrices as a result. A multi grid containing as double feature maps and x occasions the number of inputs is the result of a convnet. A feature map is created by each filter. The use of the same weights across several output units is referred to as weight sharing. As a result, the ConvNet acquires the property of feature invariance against translation. This means that a feature may be discovered across the whole input. The weights, in contrast to the Sobel filter, are the filter that will be applied to the whole input to generate the output. Figure 1 shows the connection between input and output layers
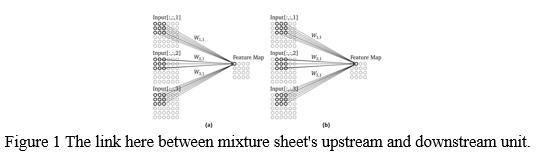
However, the output of the convolutional only has one subset of features. For clarity, the signal and partiality have been eliminated. In the two photographs, the local connectivity is shown with a scaling factor of 33. The feature map is computed using the same weights in both (a) and (b). For another feature map, new weights would be used. Wi,o connects the input channel I to the output channel 'o' using a 33-weight matrix. The output channel's name is Feature Map. [7] was the source of this illustration's inspiration.
- "Cellular modem" means that by not all source units are joined here to decoder.
- The filter size describes the size of something like the wired network..
The pictures depict the link seen between upstream and downstream units of the feature map. Four segments display the input. That may be a picture's R, G, and B colour regions, or the feature maps from a preceding layer. A muti matrix is used to symbolise the input. One feature map is presented as a result. The behaviour is similar for other feature space. In this case, the signal and bias have been eliminated, but they would still be performed to the units. All units in an unique cnn model are given the same bias weight, meaning that the bias is shared. Wi,o is a 33-dimensional matrix that depicts one kernel between Input[:,, I + Output[:,, I]..
B. ???????????????????????????? ????????????
The weights W:o are used to define a single filter and are shared across several feature maps. This indicates that when all subunits in a previous layer are computed, the same weights are utilized.
The spatially size of the convolution layers is less than the incoming networks' spatial size. So initial temporal size is 66 part in our case, however the convolution layer is just 44 percentage. The system can now be sent to 16 separate spots in the transmitter side due to its size.The input must be zero-padded to remove this influence and guarantee that the feature map has the same spatial size. The spatial dimension of the input The unit in the output is determined by the number of filters. The variety of different maps that should be constructed is determined by the number of filters. The input, on the other hand, sets the feature map's feature space and, as a result, the quantity of the product.
When contrast to a had some layers with about the same number of troops, the number of data points decreases significantly based on the weight splitting and local interconnection. Let K represent the width and elevation of a kernel, I represent the number of input channels, and F show the number of filters, which is equal to the number of input mappings. After that, the layer only contains k2 I F weights. In our case,, K = 3, I = 3, and F = 1. (Figure 3.9). As a result, there are 32 3 1 = 27 total weights. A totally linked network will have 6 6 3 4 4 = 1728 weights, which is a lot more.
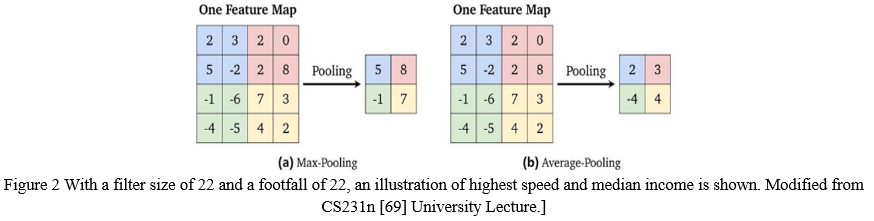
This is seen in Figure 2. In order to increase the amount of filtration and filter size, the stride seems to be another component for a convolution operation. The footfall is the time required to move the decision - making and problem across. The pace is (1,1) in our case, and that the next outgoing unit is associated regionally by moving one unit to the correct side or up. If we raise this gait to, we then construct that this next item by shifting the device that is connected two spaces to the side or below (2,2). As a result, the spatial dimension of the feature map is reduced.
From the prior perspective, it's unknown where the recursion is used. Is from the other side, the fusion is done theoretically combining Input[:,, I and the parameters Wi,o. Let's pretend that Input[:,, I = Vi, where Vi is an as double matrix representing each input's i-th stream. Z0, an as double matrix, describes the o-th output band, popularly called as the dataset.
????0 = σ(∑????=0 ???????? ∗ ????i,o + ????0 1)
The asterisk ′ ′ represents the layering, the training algorithm, and indeed the associated bias for dataset, which is described by a single vector, and b0 represents the pooled bias for the previous layer, which seems described by just a scalar value. The solution above is not a scalar! 2D matrices are used in Vi, Wi, o, and 1. For two equations, sporadic 2D-convolution is obtained..
- Transfer Learning
Transmission machine learning approach that involves repurposing a process model for one task for another.
When analyzing the second task, boosting is an enhancement that helps in the process progression or greater performance.
Because of it's massive necessary funds to build deep learning techniques or the large and sophisticated datasets on which deep learning models are trained, proposed method is popular in pattern recognition.
In pattern recognition, classifier only succeeds if the model attributes gained in the first task are generic..
2. How to Use Transfer Learning
Cnns are related to computer vision to discover edges in the first layer, forms in the middle layer, and endeavour characteristics during the latter layers. Our early as well as mid layers use deep learning, although the subsequent layers are essentially reintegrated. It allows us to make use of the tagged data first from task on which it was learned.
We strive to integrate as much information as possible from the prior task on which the model was built to the current problem in Data Augmentation. Depending on the details and facts, this knowledge might take many different forms. It's possible that the way models are constructed, for one, aids us in detect malicious features more quickly....
3. ConvNets for Image Classification
Convolutional, ReLU, and Pooling layers (also known as hidden layers) are composed of repeats (thus the name machine learning ( ml), with fully linked layers following (Figure 3). A classifier is the name given to the ensuing volume organization (in the case of images, it has a two-dimension volume). Transfer learning [8] is a weight-optimization method used in the educational process (also known as network training)...
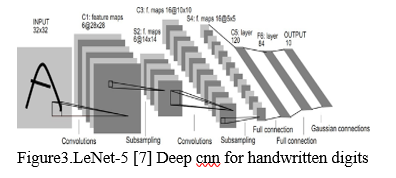
4. ConvNets for Image Classification of Skin Lesions
In the identification of skin lesions, deep learning methods have shown promise. Here are a few illustrations of deep learning research on the topic: [62] Kawahara et al. Consider utilising a learning algorithm with a fully convolutional ConvNet to identify between ten classified into non skin photos. Using transfer learning and fine-tuning the weights of a deep CNN, Liao [65] attempts to establish a worldwide skin disease classification.
V. SYSTEM ARCHITECTURE
The following will be the sequence of execution:
A. Classification of skin lesions.
The job will automatically classify each lesion into one of eight categories. This task will be broken into three subtasks in order to determine the best classification model:
B. Lesion categorization
with enhanced pictures that is balanced. The four (4) models will classify the enhanced skin RGB pictures in the ISIC dataset, and the procedure will follow the steps
C. Data Augmentation.
With synthetic pictures, a balanced lesion categorization may be achieved. The VGG16 model will classify synthetic skin RGB pictures derived from the ISIC dataset. The procedure will use the same hyperparameters for each experiment in the first task:
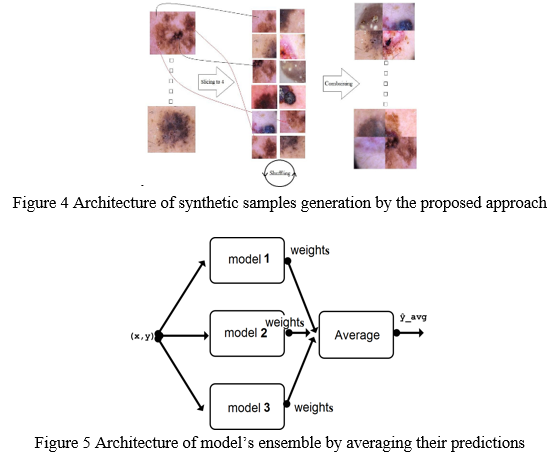
After slicing the picture into four slices, the dimensions of each slice will be 224, which is consistent with the pretrained model.
We shuffled the slices such that when we combined them, we received a different image from the one we started with. Combining the photographs while keeping the size for one slice in mind (224) + the slices + the original photos
The goal is to see how well this method is in preserving relevant information in photos. The following diagram depicts a summary of the input photos to be categorised (Figure 4.). Three experiments were used to achieve this goal: first, I fine-tuned the VGG16 model and retrained it on sliced data only, then on blended images only (synthetic), then on combined images + the original images + the slices, and finally on combined images + the original images + the slices. All three experiments used original images as a validation data set.
D. Model Averaging
Model averaging is an ensemble strategy in which numerous sub-models each contribute equally to the overall forecast.
Models with various hyperparameters and architectures should be trained.
Individual models must be loaded For each model, make a forecast the average of the forecasts.
- Downgrade classification: The VGG16 model will conduct classification over one of the best methods above, with the following operations and hyperparameters applied to each experiment: Train four (4) models, each with two (2) active classes and six (6) non-active classes (have one Image).
By averaging the weights of the models, you may create an ensemble (Figure 5). The new model was then retrained, with the goal of improving information extraction from the photos.
The four (4) classification models will be evaluated adequately under the identical settings, and the hypotheses of this study will be confirmed or rejected.
E. Datasets
Dermoscopy Images Assessment for Dermoscopy Images was performed using the ISBI 2019 Contest collection [7].. The collection, which comprises 25,332 RGB photos, is open to the public. One form of skin lesion is labelled on each photograph (Table .1).
Table 1 ISIC Dataset 2019 [7] distribution

2. Preprocessing
This project takes use of ConvNet's input preprocessing characteristics, requiring only a few preceding processing approaches. Even though certain simple preparation forms are carried out:
Mean subtraction: To centre the fog of Rgb images from input information near zero in any and every size of the image, an actually imply removal is performed out across pictorial attributes.
Image normalization: By decreasing each RGB feature of raw photographs by its error margin, a normalisation as from basic 0- and 255-pixel data to 1 and 0 normalised values is obtained. This method of preparing will eliminate potential incidents induced by photographs with poor contrast..
Agriculture and cropping of input photographs: For all types, input pics are parsed to meet the technology's requirements by trimming them to the desired aspect ratio and scaling them to 224224 digits.
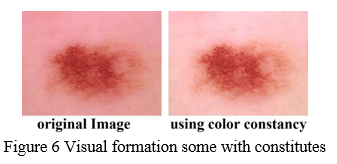
Color Constancy: One of the most essential properties of computer-aided diagnostic systems for dermoscopy pictures is robustness. However, if the systems work with multisource pictures gathered under multiple settings, it is impossible to assure this property. Changes in lighting and acquisition devices modify the color of pictures and, in many cases, degrade the system's performance. As a result, normalizing the colors of dermoscopy pictures is critical before training and testing any system [80].
To decrease luminosity and colour variance, we used colour faithfulness and the white patch retinex approach to normalise original pictures in my application. The contrast between top image and the version adjusted using the colour uniformity approach is shown in Figure 6.
F. Data Augmentation
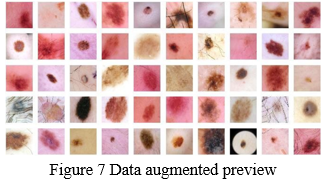
The ISIC dataset was enriched with several random changes to make the most of our limited training samples and improve the model's accuracy. Size rescaling, 180-degree x and y direction movements, visual enlargement, and vertical and lateral rotates vertical flips were among the data augmentation techniques used. Furthermore, data augmentation is intended to aid in preventing Trying to predict (a fundamental issue in computer science with minimal resources in which the transition occurs tendencies that don't apply to fresh data) and,as a result, enhancing the model's capacity to generalize. Figure 7 shows data augmentation preview
G. Neural Network Architectures used in the experiments
Several convolutional neural network designs have recently gained popularity in the deep learning field after achieving great Assessment tests such as in the ImageNet Dataset Contest (ILSVRC) [48] proved to be capable.
The VGG-16 oversaw classification tasks for prominent architectures as AlexNet [22] and Google Net [53].
VGG-16: Baseline Model, Inception v3, DenseNet210, and MobileNet will be employed in addition to VGG-16: Baseline Model.
- Baseline Model
We create a tiny CNN to quantify the complexity of categorizing skin lesions before fine-tuning DCNNs. The CNN's architecture is as follows:
a. First: A convolutional layer with 16 kernels of size 3 each with padding to keep the picture size consistent.
b. Second: A maximum pooling layer with a 2x2 window. The result is feature maps with a 2x reduction in spatial activation size.
c. Third: A convolutional layer with 32 kernels of size 3 each with padding to keep the size consistent.
d. Fourth: A maximum pooling layer with a 2x2 window. The result is feature maps with a 2x reduction in spatial activation size.
e. Fifth: A convolutional layer with 64 kernels of size 3 each with padding to keep the size consistent.
f. Sixth: A maximum pooling layer with a 2x2 window. The result is feature maps with a 2x reduction in spatial activation size.
This model's architecture is built on heuristics. In order to maintain relatively constant hidden dimensions, we use the shortest (3x3) convolutional layers and double the number of filters in the output whenever the spatial activation size is halved. Data augmentation is used to train this model. The idea behind this strategy is to slightly alter the training dataset in each epoch to add variety and ensure that the model never sees the same image twice. The learning rate is set to 0.01 and the Adam optimizer is employed. When the validation accuracy plateaus for three epochs, learning rate decay is utilised to reduce the learning rate by half. A total of 35 epochs are used to train the baseline model..
The top five layers have been deleted to fine-tune Mobilenet, and a new dropout layer with a 0.25 rate and one softmax activation layer for eight (8) kinds of skin lesions) for our classification tasks have been added. Freeze the first convolutional blocks and fine-tune the model for 30 epochs by retraining the following 23 layers. The Adam optimizer and a learning rate of 0.001 are employed throughout the training procedure.
H. GUI Application in Instantaneously
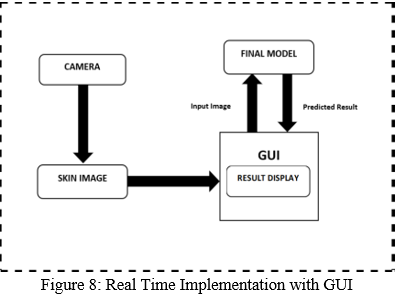
The addition of an interface makes the model much more appealing to everyone. It consisted of a sophisticated assisting website that allowed the person/patient to submit the photograph in real time. The image that has to be uploaded can come from any imaging equipment that focuses on the patch/lesion on the skin, as long as the image file is in.jpeg format. Without first being transferred to the Cnns, the supplied image is first sent it to the prototype, in which it is also before the. On during learning phase, the program's research can contribute to the outputs.. The resulting result is then sent to the GUI, where it is shown as follows in figure 8: 'The image submitted reveals no signs of malignancy.' Nothing to Worry About!' if the image is projected to be benign and 'The image submitted indicates some cancer indications!' If the picture is projected to be malignant, you should consult an expert.’.
Page End of a Homepage The GUI got created using Basic, a CSS foundation that makes it simple to construct webpages in Python.. Figure8 displays the Home HTML page, which is where the target picture may be uploaded.
VI. RESULTS
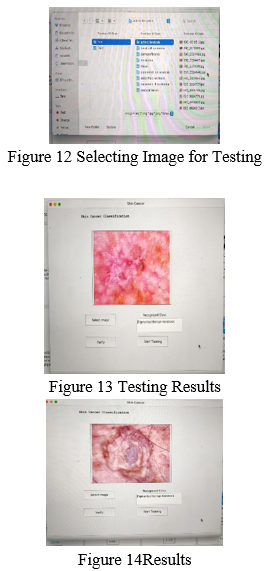
This chapter shows how to get answers in a step-by-step manner. Test photos of datasets yielded the following results: The system was put to the test by giving it photos combined from several databases. During the most basic level, the system distinguishes either cancers that spread (malignant) and cancers that do not propagate (benign). In both situations, the network predicts whether the input picture is neoplastic. The anticipated outcomes for specimens from the validation set are shown in Figures 13 and 14.

Conclusion
The proposed strategy involves dividing the multi-class problem (8 classes) into binary classification, with each two classes classified separately, yielding four (4) trained models that specialise in two classes. When these models are combined, you have a multi-class model that can categorise all eight (8) of our classes. By averaging their weights and then retraining the model, this technique tries to increase information extraction from photographs and hence improve the model\'s accuracy. Unfortunately, correctness may not convey the whole story, and in a health emergency, it\'s not always the optimal source of performance. In the healthcare field, responsiveness is often seen as a more essential requirement. When accurate intervention is crucial, it is better to create a false affirmative rather than a false alarm — otherwise, the project\'s prognosis would be excessively pessimism rather than hopeful, and a class graded algorithm was used to accomplish this.. To fulfil the project\'s aim, future work will focus on adopting some of the tactics we learnt about while reading relevant books. Because one of the most serious problems with Convolutional neural networks is their computational capacity, there is a pressing need to minimise the amount of training memory required. Up to 50% of the GPU RAM required to train deep neural network models can be saved with In Place-ABN [8].
References
[1] W. Sterry and R. Paus. Thieme clinical companions’ dermatology. In Thieme Verlag. Stuttgart, New York., 2006. [2] Yolanda Smith, “Human Skin structure,”. [online]. https://fr.scribd.com/document/313500758/Lit-SkinStruct-Bensouillah-Ch01-pdf [Accessed: March 14, 2019] [3] Matthew Hoffman, “Picture of the skin and skin cases,”. [online]. http://www.webmd.com/skin-problems-and-treatments/picture-of-the-skin#1 [Accessed: March 14, 2019]. [4] Skin Cancer Foundation. Skin cancer facts and statistics. [online]. http://www.skincancer.org/skin-cancer-information/skin-cancer-facts, 2019. [Accessed: March 15 2019]. [5] American Cancer Society. Skin cancer prevention and early detection. [online]. https://www.cancer.org/cancer/skin-cancer/prevention-and-early-detection.html, 2015. [Accessed: march 15 2019]. [6] Jones and Bartlett \"Basic Biology of the Skin,\" . http://samples.jbpub.com/9780763761578/03ch_pg029-032_Wiles.indd.pd [7] ISIC Archive. International skin imaging collaboration: Melanoma project website. [online]. https://isic-archive.com, 2019 [8] J. Kawahara, A. BenTaieb, and G. Hamarneh. Deep features to classify skin lesions. In IEEE International Symposium on Biomedical Imaging (IEEE ISBI), 2016 [9] Liao, Haofu. “A Deep Learning Approach to Universal Skin Disease Classification.” (2015). https://pdfs.semanticscholar.org/af34/fc0aebff011b56ede8f46ca0787cfb1324ac.pdf [10] N. Codella, Q.B. Nguyen, S. Pankanti, D. Gutman, B. Helba, A. Halpern, and J.R. Smith. Deep learning ensembles for melanoma recognition in dermoscopy images. In arXiv preprint arXiv:1610.04662, 2016. [11] Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097-1105), 2012 [12] ISBI. Ieee international symposium on biomedical imaging. [online]. http://biomedicalimaging.org/, 2019 [13] International Symposium on Biomedical Imaging. Isbi 2016: Skin lesion analysis towards melanoma detection. [online] [14] https://challenge2019.isic-archive.com/, 2019. [15] Python Software Foundation. Python programming language. [online]. https://www.python.org, 2019.
Copyright
Copyright © 2022 Afsha Hamid, Dr. Satish Saini. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET41337
Publish Date : 2022-04-09
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online