

Ijraset Journal For Research in Applied Science and Engineering Technology
Soil Testing Prediction System
Authors: Rachit Sharma, Tushar Mittal, Ritik Chauhan, Dr. Ranjeet Kumar
DOI Link: https://doi.org/10.22214/ijraset.2022.40864
Certificate: View Certificate
Abstract
Soil Testing Prediction is aimed to predict the soil functional properties (Calcium, Phosphorus, pH, Sand and Soil Organic Carbon) of a soil sample. Soil Testing Prediction finds its application in the field of agriculture, farming and research. It can help in economic crop management and better yield of crops. We have worked to find out how traditional soil testing methods can be replaced with modern Machine Learning techniques that can result in more economic , time efficient methods with no or little to no adverse effects on the environment. It trains to reduce the technical expertise required at users end, and aims to bring the labs to the user instead of taking the user to the lab.
Introduction
I. INTRODUCTION
In these modern days agricultural land is shrinking day after day so it is the need of the hour to test the soil before beginning with the agricultural activity to achieve best possible yield. The preemptive methods known have proved to be time consuming, costly and not so accurate. Hence, in this fast paced world we need a better testing system that can help us to overcome the mentioned issues.
In the near future, we need to explore new areas for farming due to the enormous development in the country area and we need to check the quality of our soil to make the best products. So, here comes the role of soil testing prediction which will help in:
- Determining whether a particular type of soil would be good enough to use.
- Predicting the best possible assessment of the soil’s fertility to make fertilizer recommendations.
- The diagnosis of plant problems and in the quality plant production etc.
- The measurement can be typically performed in seconds, instead of the preemptive methods that are being used , they are slow and cost a hefty amount of money.
This soil testing could be done with the help of the traditional methods. These methods are generally known as WET Tests, that makes the use of some chemicals and are quite time consuming and leads to make these tests quite expensive ones. The reason for these tests to be that expensive is, there high cost of test kit as well as the requirement of professional expertise. So, here comes the role of machine learning. In order to train our machine learning models , we will use Africa soil Infrared Spectroscopy data with dimension 3600 features and 1157 samples. This data will solely help us to train and cross validate the data , Apart from that the data will be tested upon on a new unseen data to avoid overfitting .
II. BACKGROUND
A. Traditional WET Test
WET tests are the traditional testing methods that use chemical based techniques they are time consuming and expensive. Moreover they require high technical expertise and a slight deviation from ideal conditions can result in high error. This problem can be solved using automation and helps us to remove humans out of equation which results in more effective ways.
B. Possibility of Kit
The existing possible method till now to test the soil is the WET Test, that could be done with the help of WET Testing kit. The major problem with this kit is that it requires a high level of expertise in order to use this kit as well as, this kit is quite expensive so this would not be available to be used for its direct consumers.
So the idea to use the kit directly by the consumers needed to be replaced with our proposed Machine Learning Model that would not require that much technical expertise as well as that much large amount of money by the direct consumers. They could easily use our friendly User Interface for the prediction of required content. This model will enable hassle free procedures in order to get the required values and these values will help them to make better decisions quickly and generate the best out of it.
Another possible aspect could be to use IOT based infrastructure that can generate onsite real time data. That can be piped into real time processing systems and resulting in real time predictions.
C. Limitations
- Current methods used for the soil testing can’t be directly used by most of the small scale end consumers as well as some of the large consumers too.
- This current method for the soil testing prediction can’t be easily used by the novice.
- This current method used for the soil testing can’t exist without making use of harmful chemicals, that would anyhow cause environmental disruption.
- Conventional Methods these days require ample amount of time to generate the test results , Considering the size of indian consumer market this time constraint proves out to be crunching.
III. PROPOSED METHODOLOGY
The Project aims to predict the following :
- SOC: Soil organic carbon
- pH: pH values
- Ca: Mehlich-3 extractable Calcium
- P: Mehlich-3 extractable Phosphorus
- Sand : It is the percentage of sand present within soil.
IV. DATA WRANGLING
Wrangling refers to cleaning data i.e making it more normal and removing any outlier or unscaled features.
A. Outlier Removal
Outliers are the data points that do not follow the general trend within the data i.e They will impact the result in the wrong manner and fluctuate the result from the actual one and can increase the error i.e deviation from the predicted behavior..
? Scaling
? Normalization
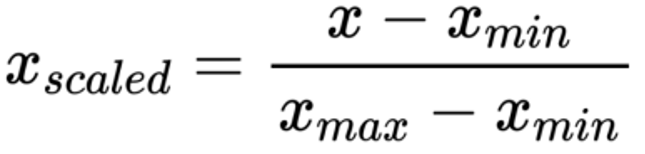
Where
x is the sample point
xminis the minimum value over the domain
xmaxis the maximum value over the domain
B. Dimensionality Reduction
Since the dimension of the data set were high hence in order to reduce it to a feasible number PCA is used.
Principal component analysis is used for reducing the dimensionality(Feature set) of a dataset , it creates a projection of a higher dimension feature set to a lower dimension it generates a set of new features with higher variance resulting in better predictive power as expected it makes us loose some amount of knowledge as compared to original dataset.
C. Feature Selection
For extracting the required number of features (50 Features to be precise)we’ve used recursive feature elimination and Random forest Regressor.
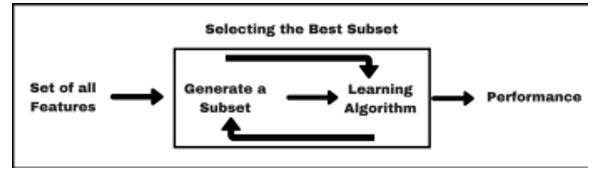
D. Recursive Feature Elimination
Recursive feature elimination (RFE) is a feature selection method it helps us to get the best subset of features from the feature set. To do so , it fits the model on the given data and tries to remove the least significant feature one at a time. The process is repeated until the desired number of features is reached or the desired accuracy is achieved.
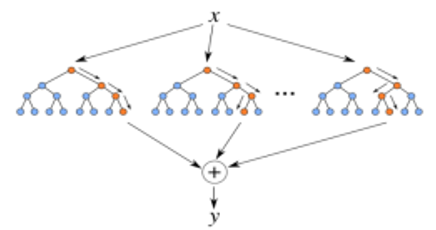
E. Random Forest Regressor
A random forest regressor as the name suggest it uses a number of Random trees in order to generate a random forest based on the random forests regression scores it tries to fetch out the best possible features for the model in order to predict the targets, it is one of the most popular feature selection technique it is available for bout classification task and regression task . It trains each tree on the subset of a given dataset and increasing accuracy by sampling.
V. MODEL TRAINING
For making model we’ve used two algorithms namely ordinary least square regression and light gradient boosting machine.
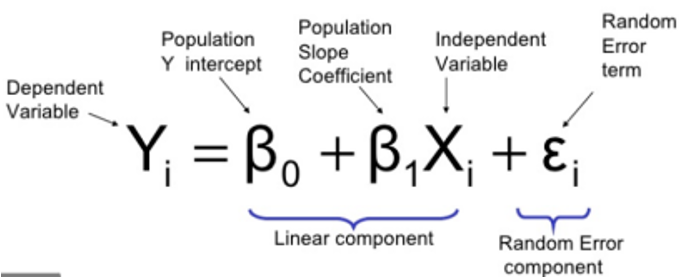
A. Ordinary Least Square Regression
Ordinary Least Square Regression, also known as simple linear regression, is one of the many techniques that have been adopted from the field of statistics in the field of machine learning . It works on the assumption that there is linear relation between the target value and the features. It estimates the best fit line for the feature - target relation, although simple but this technique has proven to give exceptional accuracy.
B. Light Gradient boosting Machine
LightGBM, short for Light Gradient Boosting Machine, is a free and open source distributed gradient boosting framework for machine learning originally developed by Microsoft. It is based on decision tree algorithms and used for ranking, classification and other machine learning tasks.
VI. ACCURACY MEASURES
The Predictions are scored upon Mean Column wise root mean squared error (MCRMSE).
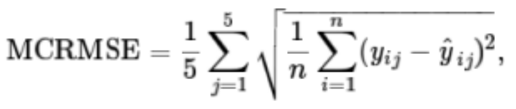
VII. RESULT DISCUSSION
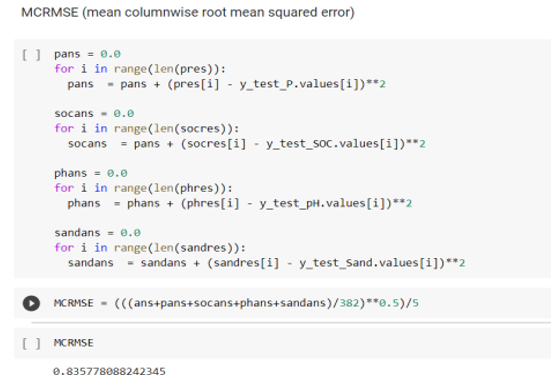
Accuracy for OLSR - 0.83577
Accuracy for LGBM - 0.46892
VIII. ADVANTAGES
- Cost Efficient
- Fast processing and predictions in real time
- Better Accuracy
- Minimal or no use of Chemicals
Conclusion
As we all know that soil testing has been an essential need for today’s world. But doing that with the help of traditional methodology takes almost 5 to 6 business days while our model proposes to give the almost same result within seconds with a Mean column wise root mean square error of 0.83577 and 0.46892 for OLSR and LGBM respectively.
References
[1] “Carge`le Nduwamungu , Noura Ziadi , Le´on-E´tienne , Gae¨tan F. Tremblay , and Laurent Thurie`s (2009) Opportunities for, and limitations of, near infrared reflectance spectroscopy applications in soil analysis: A review” [2] sklearn.linear_model.LinearRegression [3] “Soil Analysis using Mehlich 3 Extractant Technique for Sample Preparation . ÚKZUZ (Úst?ední kontrolní a zkušební ústav zem?d?lský) Central Institute for Supervising and Testing in Agriculture Hroznová 2, CZ-65606 Brno, Czech Republik L. Vlk, M. Horová, R. Krej?a; R. Špejra Chromservis S.R.O., Jakobiho 327, CZ-10900 Praha-10, Petrovice, Czech Republik” [4] https://flask-doc.readthedocs.io/en/latest [5] https://docs.aws.amazon.com/ec2/index.html
Copyright
Copyright © 2022 Rachit Sharma, Tushar Mittal, Ritik Chauhan, Dr. Ranjeet Kumar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET40864
Publish Date : 2022-03-19
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online