

Ijraset Journal For Research in Applied Science and Engineering Technology
Techniques for Secure Data Contribution and Retrieval in Social Networks Using Effective Privacy-Preserving Data Mining
Authors: Kotha Nikhil Reddy, Mohammed Nasser Hussain, Talla Vivek Sagar, Prathapagiri Harish Kumar, Kale Srinitha
DOI Link: https://doi.org/10.22214/ijraset.2022.46969
Certificate: View Certificate
Abstract
The major area of data-mining methods that focuses on protecting personal information from unauthorised or unsolicited exposure is called Privacy Preserving Data-Mining (PPDM). The most valuable information is analysed and predicted using data-mining methods. The security of confidential information from unwanted access is at the core of PPDM abstraction. The Secure Data Contribution Retrieval Algorithm (SDCRA), Enhanced-Attribute Based Encryption (E-ABE), Level by Level Security Optimization and Content Visualization (LSOCV) algorithm, and Privacy Preserved Hadoop Environment are just a few of the proposed methods in this research work to increase privacy and security (PPHE). To address the immediate difficulties, the proposed SDCRA is first taken into consideration. Based on specifications and application compatibility, the SDCRA algorithm determines a privacy policy and sets up security. The accuracy requirements for numerous datasets may be met by this approach. Online social networks (OSNs) are presently favoured interactive medium for establishing communication, sharing, and disseminating a sizable quantity of data on human existence.
Introduction
I. INTRODUCTION
The practise of obtaining non-trivial, potentially beneficial, previously unidentified, implicit, and eventually followed information or patterns from massive amounts of data is known as data-mining. It makes it easier for users to look at information from a variety of sources, including social networks, bioterrorism applications, medical database mining, transportation, web cameras, identity theft, video surveillance, genomic privacy, etc [1]. Before using any data mining approach, it is important to summarise and explore the data in order to have a clear understanding of the information and determine the knowledge that should be retrieved and the subsequent techniques that should be used. Descriptive data mining techniques, such as association rules, clustering, and sequence discovery, and predictive data mining techniques, such as classification, regression, prediction, and time-series analysis, may be roughly divided into two categories [2]. By adding labels to the measurements and observations of training data that identify the kind of observation that was used to build the models, supervised learning is used to analyse the data. This model represents mathematical formulas, decision trees, and categorization rules. This model is used to forecast the category of unidentified data tuples [3]. Credit clearance, target marketing, medical diagnosis, and future detection are examples of applications for supervised learning that are often employed. The model may be used to get the labels of fresh data. The training data in an unsupervised learning process contains unidentified class labels. In this case, a collection of measurements and observations are provided with the intention of proving the existence of classes or clusters in the data. The well-known unsupervised approach, which is employed in pattern recognition, geographical data analysis, image processing, document classification, etc., groups things together that have similar properties [4].Data mining is a critical first stage in the KDD process. the numerous data sources, including text files, database files, etc., from which data may be mined. The typical KDD process phases are shown in Figure 1. It is an interdisciplinary process that is impacted by various domains, including statistics, AI, machine learning, soft computing, the Internet of Things, information retrieval, etc. and is described below. The list of processes that are included in this iterative model is as follows. Some databases tend to be insufficient and inconsistent. A technique for translating unification into such databases is preprocessing of data. As a result, the database becomes more cohesive and integrated, proving that it should be extracted. It involves data cleansing, user and session identification, knowledge discovery, and pattern analysis [5].
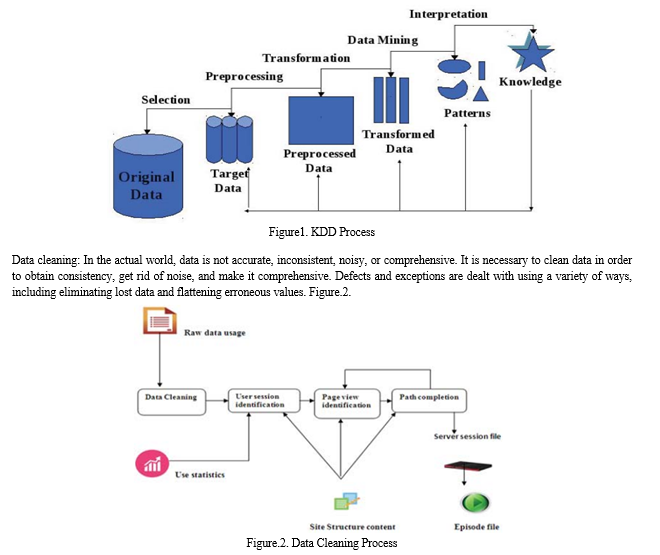
Data integration: This technique gathers data from many sources. The data source is accessible in several discrete databases with varied data definitions. Data is added to a single coherent-data storage unit in this method from these multiple-data information.
- Data-Selection: This is the process of retrieving data from the central data repository that is pertinent to the job at hand for data-mining strategies. • Data-Transformation: This process transforms source data into an actual format needed by mining techniques. Important data management processes such as aggregate, attributes generation, generalisation, smoothing, and normalisation are involved in data transformation. • Data mining is the application of algorithms to perform tasks like classification, clustering, logistic regression, and prediction on a set of chosen data.
- Pattern Evaluation: This involves selecting intriguing patterns to use in a pattern-set assessment. It is often used to filter out undesirable information and show consumers patterns that are interesting to them. At first, the storage server removes the models or rules of less importance. Therefore, it does comparison mining and analysis using OLAP technology. The system discovers information that is available to the public. The features of services for business websites are provided as a last point. • Knowledge Description: The use of the visualisation techniques included in it to interpret knowledge for consumers. A wide range of industries, including banking, biotechnology, e-commerce, etc., use data mining
Various people have different goals when they analyse data. To make it easier for multiple users, data-mining jobs are categorised into description and prediction. Unknown values are discovered by making predictions based on known results [6]. Regression analysis, categorization, and time series are frequent prediction tasks in data mining. The description model investigates the existing patterns and data attributes. The three major descriptive goals in data mining are clustering, sequence finding, and association rules. Healthcare, medical, banking, marketing, insurance, and other industries all employ data-mining techniques. Figure.3. demonstrates the key data mining techniques [7]. It is referred to as the broad description of the target data or class's properties or qualities. In this method, it is possible to extract representative data that is connected to the database. In order to create a smaller collection and offer a broad overview of the data with aggregate information, the data pertinent to a certain set of tasks is condensed and abstracted.
It is the process of finding connections that are concealed in the data. It is a particular kind of data-mining job for investigating correlations between a group of objects found in transactional databases, common patterns, and relational databases. The retail sales team uses these broad relationships to categorise the products that are usually bought together. By examining client transaction data from a supermarket, the association rules are discovered. Some applications, such as telephony, may forecast the switch failure while employing this association procedure.
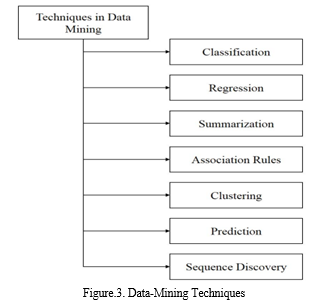
The classification of data is the focus of clustering. When it comes to consumer data, this is especially desired since it makes sense to group together customers who have similar characteristics, for example, to employ targeted advertising. Clustering is an experimental exercise for various issues. As in the instance of the well-known K-means technique, data miners often want to cluster the data into a certain number of clusters. It is the process of dividing data into different groups or categories (referred to as clusters) depending on how similar the input data is. This method, which is based on unsupervised learning, explores the links between pattern collections by grouping them into homogenous clusters. The relative-density or relative-distance between the clustering items is used as the similarity metric. The clustering approach is carried out according to the maximisation of intra-cluster similarity and minimization of inter-cluster similarity. The approach based on clustering is being used in many domains or regions. For instance, the department store chain creates specialised catalogues for various demographic groups depending on factors like the clients' location, physical characteristics, and income. For defining the different catalogues' targeted mailings and aiding in the production of particular-catalogs, the execution of the clustering is done on recognised attribute values. K-means is a popular clustering method used in data mining, and it performs better than other clustering methods. Classification is the process of grouping data into certain classes or groupings. This approach is known as supervised learning since the class labels are established prior to data processing. The training dataset is examined to develop the model for class label-based categorization, which later aids in the facilitation of unlabeled records. Applications range from identifying risk to obtaining a bank loan to predicting sickness based on a patient's symptoms.
The creation of "classifiers" that may be used to classify "unseen" data into groups is what classification is all about (classes). In order to build classifiers, classification needs prelabelled training data. The needed classifiers may be implemented in a variety of ways, including decision trees, Support Vector Machines (SVMs), and others. Despite the similarities between classification and clustering. There are significant variations however; clustering is regarded as unsupervised learning whereas classification is called supervised learning.
Regression analysis is the process of converting data into a real-valued predictive characteristic. By making the initial premise that the known function first matches the output data, this analysis determines the optimum function for modelling the input data. The formula utilised is (A=mB+q), and it describes regression in its most basic form, known as Linear-Regression. Regression is the process of converting a data item into a real-valued prediction attribute. Additionally, the supplied data is modelled by selecting the optimal function using the regression approach, where the beginning assumption is the known function. By first assuming a known function that matches the target data, it finds the optimum function to represent the provided data. In the simplest version of linear regression, the straight-line formula (y=mx + b) is utilised, and the necessary values are established for predicting the value of y from b for the given value of x. In order to create more complicated models, such as quadratic equations, the sophisticated approach known as Multiple Regression is employed.
It is referred to be the data analysis job for creating an effective model that is utilised to forecast continuous values for the given data. Numerous data-mining tools are used to forecast future data values based on historical and present-day data. The function of continuous values is processed by the prediction model, and the categorical labels are predicted using the classification model. Data mining techniques vary from prediction models, which exclusively forecast the future rather than the present.
Any often recurring grouping of things entities, events, objects, etc. is referred to as a pattern. Finding patterns in data has been a major emphasis of data-mining throughout its history. These patterns may come in a variety of forms, including subgraphs that commonly appear in graph data, alternative patterns that might represent trends in temporal or longitudinal data, and so on.
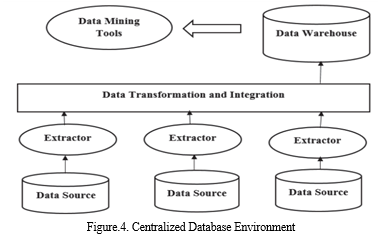
The methods and procedures that fall within the purview of data mining might be described as a synthesis of statistical and machine learning techniques. This perspective makes it clear that statistics and a number of machine learning fields have "grown out" of data mining. Additionally, the combination of statisticians and computer scientists dominates the data-mining organisations. The European Conference on Machine Learning (ECML) and Practice of Knowledge Discovery in Databases (PKDD) joined forces in 2001 and have been together ever since the development of [8]. Data mining, which may be seen as an application area, focuses on data in various forms, while machine learning uses the typical learning techniques of computers (for example, playing chess is earlier development of machine learning concept that only focused by computer programmers). The learning approach is considered as the newest technology, while KDD's data-mining is recognised as an application. The database may be found in this environment in a single repository. When this information is communicated and the demands of the consumer are recognised, the organization's revenues grow. The owner of the organisation does not want to share their data since it poses a privacy risk. The database is transformed to conceal the sensitive information and utility is preserved, which is known as the dataset use after transformation, in order to handle this problem in a variety of ways. This transformation has been made available for data mining analysis. Figure.4. outlines the environment's overall architecture for centralised databases.
For the supplied dataset, the object is represented for each row and each column as an attribute. Individuals' address, name, home address, age, credit card number, and other details are provided under the characteristics. The values of the property are linked to the potential more sensitive object, necessitating projection. The privacy of personal information shouldn't be jeopardised throughout the data mining application procedure. To safeguard data privacy, a dataset is distorted in some manner using PPDM methods. After transformation, the dataset is distinct from the original and is utilised by the analyst for mining purposes. The data-mining approaches maintain the privacy safeguards' essential qualities.
For simulating the interactions between the different players, a number of sites have emerged in the last ten years. Social networks include places like Myspace, Facebook, Twitter, and LinkedIn, among others. Additionally, certain websites, such as YouTube and Flickr, are used for sharing the contents of online media and may be seen as auxiliary types of social networks since they permit user interactions at a deeper level. In this instance, a particular interaction service like content sharing is the focus, and it incorporates social network characteristics. It is obvious that these social networks are very rich in terms of the vast quantity of information they include, including audio, photos, video, and text. This has the greatest benefit for a variety of reasons.
It is a sort of data-mining technology that safeguards the confidentiality of private information or an individual's data without disclosing the data's intended use. Most Privacy Preserving Data Mining (PPDM) solutions modify high-quality data-mining algorithms and include cryptographic mechanisms as mitigation to maintain the application's needed privacy. In a number of instances, the privacy requirements are upheld while the PPDM restrictions are retained for model correctness and mining process efficiency. It is also known as privacy sensitive or privacy-enhanced data-mining dealing with getting valid results without studying the data values that underlies.
II. LITERATURE REVIEW
To achieve PPDM, a number of different strategies may be used, including data dissemination, change of the mining algorithm, management of rules, and privacy protection. First, the dimension deals with how data is disseminated. Centralized data are those that are kept in one location, while distributed databases are those that are spread around. Data may be dispersed across computers horizontally or vertically in a distributed database. In order for the user to avoid the de-identification of sensitive data, the term "data-modification" refers to the change of the original data to other forms. Actual data is somewhat altered by adding noise or increasing the noise. Data manipulation techniques include swapping, anonymity, randomization, blocking, and sampling. The third dimension in which data mining is carried out is the data-mining algorithm. The used has the power to invade people's privacy. Data pieces that are taken and retained in a concealed condition are referred to as the fourth dimension in terms of data hiding. The purpose of the fifth dimension is to ensure privacy when data mining.
The primary goal is to disseminate the most widely used technique for protecting data-mining privacy, which enables calculation of useful statistics for the whole dataset without disclosing the privacy of the user's datasets. There are various effective techniques for PPDM that were subsequently developed with a thorough data-mining investigation in more recent decades. The majority of solutions change the original data in some way to ensure privacy preservation. In this instance, the scenario is more significant for keeping the benefit of privacy protection even after the dataset that was used for mining was modified. The following are examples of categorization techniques: [9] examined the distribution of the original data and developed a simple reconstruction strategy to estimate properly. Authors compared the accuracy of the sanitised and original data using classifiers. Additionally, the accuracy of this prediction model is questionable when perturbing the data of a large number of users. Authors did, however, advise looking into the randomization strategy for categorical data reconstruction. A hierarchal model for the classification process utilised in PPDM was developed by [10]. Additionally, the author expanded the analysis and grouping of several PPDM techniques. Additionally, only certain data-mining methods are thought to be useful for assessing privacy problems. Through the use of a heuristic framework and a variety of sanitization techniques, [11] investigated a technique for concealing the frequent item sets. Several techniques for preventing noise addition and limiting real-dataset removal employ the item-restriction concept. The authors also recommended looking into the context of data-mining privacy in association rule and patterning regulations, as well as the new sanitising optimum algorithms. [12] used the SIF-IDF technique to give each transaction a weight, and they then carried out the sanitization procedure from the transaction with the highest score to the one with the lowest score. The authors of this study hypothesised that by combining clever techniques, the performance of the strategy they offered may be enhanced. By using a genetic algorithm (GA) and analysing the decision rule's True Positive Rate (TPR) result in relation to False Positive Rate (FPR), [13] present a safe technique for discovering the optimal set of rules that don't leak their individual private data. However, the author suggests that combining the presented model with a few optimization strategies might increase efficiency.
By segregating the victim's transaction, [14] offered a number of GA-based approaches, such as pGA2DT, cpGA2DT, and sGA2DT, for concealing the crucial information. The group of options is taken into account for encoding the chromosome, and the victim of any future detection is predicted to be a gene transaction inside the chromosomes. By creating the fitness function for the assessment utilising the previously established weights for demonstrating the chromosomal ability, three side effects are taken into consideration. For the present algorithms to be effective in locating the best transactions for deletion that have an impact on the created techniques' assessed findings, pre-defined weights are still necessary. Because of this, authors advised using suitable PPDM approaches to enhance performance. The Evolutionary Multiobjective-Optimization Rule Mining (EMO-RH) method was introduced by [16] and is used to remove the EHO-based itemset in order to conceal the key itemsets. This technique is examined utilising a multi-objective approach, whereby errors in judgement are caused by transactions that were not completed in order to establish a medical diagnosis. This article also suggests using EMO and other blocking-based strategies in the future to make even more advancements. When compared to single-objective techniques, the current state-of-the-art in PPDM, the meta-heuristic strategy is described by [15] employing the NSGAII structure for data-sanitization and demonstrates desirable side-effects. Additionally, the author suggested using the multiobjective PSO approach for future advancement. The authors proposed more research on the privacy of mobile and data-stream mining in light of the expansion of geographic and geographical data. [17] conducted a two-level analysis of PPDM approaches, focusing on the acquisition of sensitive and critical raw data from data collectors that shouldn't be used directly for mining and the exclusion of sensitive and critical mining results from decision-making. The suggested approach was taken into consideration by the authors for use in a number of fields of pattern mining, including maximum and closed, differential privacy, and anonymization. In an effort to stop the leaking of sensitive information, [18] created the FPUTT method, which is built on a tree structure and performs database perturbation. The sensitive item sets in this case are limited to the HUI mining technique for the specified transaction database. This suggested model uses the FPUTT-tree tree structure and two index tables called the Intensive Itemset-table (II-table) and Sensitive Itemset-table (SI-table) to minimise database searches. The two-table structures and tree-based structure are also employed to reduce database scans by three times, according to the performance assessment. Data mining methods for the preservation of privacy utilising the randomization strategy for each customer's data were examined by [19]. Despite the fact that the accuracy of the suggested model is lower, these strategies are used to protect the privacy of customers' sensitive data. The suggested method may also be used to address non-binary data types and expand the work to address additional data-mining issues. [20] used classification methods to ensure client data privacy without sacrificing forecast accuracy. The classification technique, which is more effective than secure multiparty computing, is developed using completely distributed additive homomorphic encryption of the ElGamal public key. This strategy works well for discrete variables as opposed to continuous features and is protected against n-2 corrupted and miner customers. Combining randomization methods with the given model is recommended for future study, and combining cryptographic models may further increase efficiency. [21] examined the privacy-preserving capabilities of the Nave Bayes classifier for high performance with little communication cost. Only discrete data are handled using this suggested paradigm. The use for replicating or including near homomorphic encryption by the current ideas of automated envelope approach for accomplishment of shared information-mining while preventing the disclosure of private information during social occasions was visually studied by [22]. The suggested technique is offered for many applications with rich effects. In addition, as a future improvement, the suggested approach should be used to assess the medical data. In order to validate the protection that relies on mutilation, rules stowing, information conveyance, and mining calculations without end, [23] presented some of the current approaches of information excavation. Roadmaps for PPDM, Sanitization, Rule Hiding Approaches, Perturbation Techniques, and Reconstruction Approaches performance improvement are provided by the authors. Information mining methods' protective properties were examined and broken down by [24]. It is not made clear what precise techniques may be used to prevent the intended use of information mining. In their 2010 proposal, [25] included data focuses, databases, and consumers for each location. Due to the data emphasis being entirely indifferent, the website and customer database components are interchangeable. The perturbation approach was just briefly addressed by the author using some chosen data. [26] developed a technique that consists of numerous unique approaches for affecting each database component. The simulation results show that this suggested strategy is quite effective at maintaining privacy for the specified dataset. Additionally, the framework experiment uses EGDAP and CGADP to enhance perturbation approaches. The passionate analysis based on creative notion for the PPDM vulnerable components was described by [27]. Additionally, under grouped-fragile, which uses a swapping mechanism to ensure data privacy, the incentive is modified by the data owner. The assured computation of sensitive affiliation rules (SAR) based on Fast-Hiding Sensitive Association-Rules (FHSAR) was less favourably evaluated by [28]. In order to analyse the problems caused by updating the framework execution, the well-known two-heuristic method is applied.
By adding using the heuristic capability for selecting successful requests of revised exchanges for each specific trade, the previous weight is determined. Analyzing the updated information might be difficult but should be investigated as the author suggests for future development of this work. In order to settle the advantage of protection in fewer laps, [29] examined the strategy of neighbour grouping based on storage room, which is based on Secure Multiparty-Computation (SMC) technique. The determination of pf is protection closetneighbor safeguarding and classifying the preserving protection. With respect to execution, productivity, and security protection, the suggested solution is uniform. This paradigm may be used in a variety of situations to achieve the goal of unique improvement. The authors recommended employing several categorization approaches to enhance performance. The order technique for effective and seamless information security in the cloud was described by [30]. For the K-NN arrangement, the nearest neighbour assessment is performed using a measurement based on Jaccard comparability, and the transferred balance set is employed to make sense of the two scrambled records. The suggested approach at each hub ensures the computation of a close neighbour, and hidden data are organised using a K-NN weighted plot. The authors recommended combining the method with other perturbation approaches to increase efficiency. Classification Correction-Rate (CCR), a heuristic computation method for the specific database's security, was suggested by [31]. Based on the suggested model, the strategy is laid out, and simulation results are accepted. Heuristics are calculated in a very persuasive and effective manner. The authors provide recommendations to expand the dataset and examine time consumption decrease. [12] underlined the challenges that are associated with the rise in data situation and the need to safeguard the security of mining strategy and grouping. The data is modified in accordance with the polynomial-time computation used to maintain the so-called knameless standard security. This paper also advocated for employing distributed systems to address the issue of stored data rather than a single repository. In an assignment looking for an organisational security for system saving, [13] discussed the challenges relating to affiliation control of outsourcing. By creating an attack model that prevents outsourcing mining that depends on figure exchange of objects, the information is safeguarded. The authors also proposed enhancing the RobFrugal algorithm to reduce misleading patterns. By leaving out the computational escalated-operations of bilinear mapping, [14] conducted an analysis of the execution paradigm mentioned above. This suggested paradigm improves security and efficacy by thoroughly scrutinising execution. Information Square is included, but it is not dynamic. The authors conducted an analysis of the issue of inefficiency and created a dynamic and safe public auditing system for cloud environments.
By using linking attacks that include open and semi-open sections, the intriguing model known as K-anonymity by [16] examined the identification of small-scale information. The technique and combination of information recognition, information mining, and K-anonymity have been noted as the main problems with this approach. On the basis of new models, efficiency improvement is proposed. Before developing the techniques that are overlooked for secure protection or information usage, [18] offered the K-anonymity augmentation and enhancement meanings with the complicated relations and shown. The author contemplated researching random schemes with several private entries. The challenges for the safe outsourcing of ongoing multi-cloud item set mining were examined by [11]. The suggested approach divided the vast amount of data into manageable chunks and freely dispersed each chunk to several clouds using the pseudo-scientific categorization and anonymization method known as KAT. The authors advised examining the proposed approach for extensive and ongoing cloud data.
In order to divide the network sensing area into three sections, [12] presented the Sleep-Awake Energy-Efficient Distributed (SEED) algorithm, which directly connects the cluster head with base station. This technique extends the network's life while reducing the amount of transmissions to the base station. Reversible Data Transform (RDT) technique is created for restoring and disrupting data, and it was first presented by [10] for the field of picture processing. The RDT has improved performance and successfully minimises privacy disclosure and data loss. To retrieve the original data from disturbed data, [16] introduced the Singular-Value Decomposition based Data Perturbation (SVD+DP) model. By making all samples' data disturbed, the privacy is preserved. By using the perturbation approach, various records are allowed for different degrees. The SVD+DP approach improves the perturbation, which is used for various privacy with varying degrees. During data processing, which is based on attribute weights for data categorization, certain records are discarded. As a result, this approach is used to rate the qualities. By assessing the privacy computation, the example records are made visible. Misclassification errors and data losses that weren't maintained are prevented. The matrix decomposition is the basis for the operation of the singular value decomposition (SVD) approach. To create the patterns for medical data, [13] investigated decision trees for k-anonymity. The Electronic Health Record system, which is used to release the privacy of micro data and often eliminates explicit identifiers such social security numbers, names, and IDs, prevents connecting attacks. In general, data de-identification fails when anonymization is not guaranteed. First, the information repository is cleaned up of the erratic and noisy. The design merges several source data into a single integration. This paradigm satisfies the privacy needs of sensitive data. This system uses cryptographic methods to guarantee security.
Additionally, this strategy does not ensure effective privacy for web-based and huge environmental data. Connecting Heterogeneous Social Networks with Local and Global Consistency (COSNET), a model based on energy, was introduced by [12] to solve the issue between various networks. In decentralised multi-hop mobile-social networks, [10] created a design mechanism that prioritises user-submitted profiles while searching for people based on profile-matching. The intended technique, which prevents participant profiles and preferences from being disclosed, is called privacy preservation. By revealing the publicly supplied, public qualities about themselves, [1] examined the dependable matching profile based on the practical knowledge across real-world social platforms. The profile qualities Availability, Consistency, Non-Impressionability, and Discriminability (ACID), which are adequate and essential for establishing the trustworthiness of the matching-scheme, are specified in the properties set. In order to analyse advantage structure, sex differences, and security math, [3] examined the informal organisational administrations based on composed area. The influence of benefits seen generally has a little impact on the advantages, and communication between these security risks is taken into consideration. [5] examined how the content and structure of whispers for social links changed. A strange informal community that uses three month hints for the arrangement of whisper that spans 2 million and is composed by 1 million of the customers is the subject of a large-scale simulation inquiry that is displayed. Influencing the lack and obscurity of social ties is how the customer is managed. Due to the registration of lightweight asset requirements, [4] develop the Quick Community Adaptation (QCA) as an acceptable approach for the examination of substantial-scale dynamic informal communities. The system community is updated for the supplied history in addition to the groups being identified as power organisations, rather than pre-processing being done with outside assistance. Wei et aldescription .'s of the Twitter message components for component construction in 2019 focused primarily on experts' wellbeing and determining whether or not their tweets were in excellent shape. The linked and similarly described tweets about well-being are based on the justification provided. Tweets that are near to home or the clients claimed would wish are given some significant considerations by various tiers of theoretical proofs. The leakage of area protection is evaluated from MSNs by the clients' coordination and influenced to the actual follows of variety in [18]. The attack is also known for allowing the outside adversary to summarise socioeconomic factors like sexual orientation, age, and education in the customers who are looking for the exposed area profiles.
Getting information when required from a variety of information resources is referred to as information retrieval (IR) in [12] discussion. Information has to be presented by users in a way that the retrieval system can interpret it in order to find potentially relevant documents fast. However, the variety, quantity, and dynamic nature of the information available from internet sources make it incredibly difficult to find precise information. Information retrieval tasks focus on a specific feature of IR that is derived from the perspective of the user. [13] examined data encryption as a technique for maintaining data secrecy. Data access patterns, on the other hand, might expose client information. For instance, if the outsourced data includes encrypted information, the vendor could be able to get the information throughout the user's analysis and information retrieval processes. Information leaking was one of the security and privacy issues that IR was intended to address. In other words, IR gives users the option of accessing data from a server-based database without disclosing which item is accessed. The retrieval methods currently in use for effectively delivering secure data are described in this section. Recent development in a variety of applications, information from data mining that is commonly categorised as association rules or frequent patterns, High Utility Patterns (HUPs), sequential patterns, clustering, and classification, among others [14]. Among these, the data that clients have bought may be routinely examined utilising ARM's foundational expertise. In addition, the itemset is evaluated to determine if a transaction should be executed. Real-world applications include a variety of variables including profit, risk, quantity, weight, and other metrics. High Utility Item Set Mining (HUIM), a recent development that takes into account both separate profit and buy quantity variables, has brought to light a crucial problem. Researchers have looked closely at a number of PPUM-related methods, including the High and High Utility Item set Mining (HHUIF) strategy for concealing SHUIs and the Maximum Sensitive Item sets Conflict First (MSICF) algorithm for sensitive item sets. However, there aren't enough NP-hard problems that fall under PPUM or PPDM. The decision-making process is where the sensitive information is concealed but is more important. The HUIM and PPUM concerns had come into prominence by [15].
Two evolutionary strategies were proposed by the authors to mine HUIs and conceal the delicate high-utility itemsets found in PPUM. An innovative evolutionary algorithm for HUIM was presented in the initial section of this paper. The Particle Swarm Optimization (PSO) based approach required less runtime than the previous algorithm based on the proposed Maximal-Pattern tree (MP-tree). A GA-based PPUM method was presented in the second section of this paper. The decrease in calculations was also included in the pre-large idea. The planned method outperforms the naïve GA-based methodology by a factor of two. Although data mining has mainly been effective in its use, creating compromising circumstances for sensitive information is a severe danger to privacy. The primary goal of PPDM models and algorithms is to avoid information exposure during certain mining activities.
As a result, subsequent KDD processes, such data preparation and the application of extracted patterns, might sometimes be overlooked by PPDM. Data preparation, for instance, might reveal the identity of the original data owners and create vulnerabilities that could result in either purposeful misuse of data patterns or inadvertent improper usage that could damage personal privacy or even national security. The Rampart framework was developed by [13], which gave the term to the concept: a wall that prevents incursion from the outside. While anonymization techniques assist in removing the privacy risk in data preparation, provenance approaches analyse information reliability and assist in addressing security concerns in providing mining results. The agreement and trade techniques assist balance the interests of various parties participating in the KDD process by using economic tools to construct agreements or trades between parties engaged in data mining operations. Only anonymization and manipulation of the experimental outcomes were explored; investigations omitted provenance procedures and analysis based on game theory. Future iterations of this study widened the scope of Rampart to keep up with the expanding understanding of privacy concerns associated with data mining.
III. PROPOSED METHODOLOGY
Sensitive information must be secured and kept private during data exchange across several unreliable parties, which is a crucial feature of data mining. Numerous apps deal with problems including data leakage, sensitive data exposure, vulnerability, and data abuse. PPDM employs a number of ways to preserve sensitive data's privacy without sacrificing accessibility. The suggested SDCRA approach to protect privacy during data mining is described in this section. This approach uses rule-based categorization approaches to promote system privacy. The suggested approach secures the data depending on the application to boost the technique of data mining's compatibility. This section analyses and explains the proposed SDCRA algorithm and presents the retrieval and contribution of secure data in online settings. In Figure 5, the suggested SDCRA framework is shown.
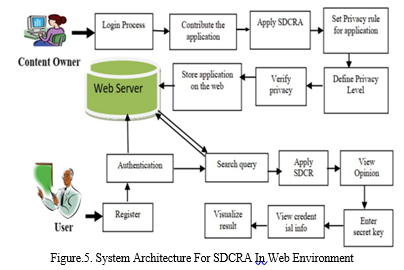
The suggested system is broken down into many categories, including privacy definition, result visualisation, online environment matching, security compatibility identification, input data processing, and application. Here, the data owner should choose their own application to define the privacy level. The suggested method implements privacy based on the application's requirements. The user may finally search the web for the query, and the user can obtain the results with the least amount of execution time and categorization error. The SDCRA approach analyses the application once the data owner logs into the system and provides the data with compactable privacy preservation. The suggested SDCRA technique has assigned the privacy rule for the provided data. After that, a privacy level is determined depending on how important the data is. The system has a high degree of protection for sensitive data, such as banking information. The SDCRA approach is used in the system to verify privacy while storing data in the cloud. The user tries to get the needed data from the cloud server on the other end. In order to get the data, the user applies the key to the system, and the SDCRA technique analyses the key for verification. Investigate the outcome once the secret key has been applied to the credential data. Following successful authentication, the user's query is used to search the web server for data mining. In the shortest amount of calculation time, the user is given the pertinent information that was obtained.
In the beginning, the table stores the various tuples in relation to the data owners and the data. The SDCRA technique bases its definition of the privacy rules on the application. The data owner for the application must set the privacy level for the application. To safeguard the data and ensure compatibility, the privacy rules are then applied to the tuples in the table. The privacy level has been applied to the data and placed in the table if the rules are compactable to the application. The system's data are once again examined for privacy standards. The index has been applied to the attribute, and the data attributes have been categorised for authentication. Finally, the findings' credibility is confirmed, and the method's calculation time is likewise short. Using the suggested method, the compatibility of privacy is checked across application services inside a composition. The suggested approach is processed using the concepts of privacy and cost model. By specifying a threshold, the privacy compatibility for the application services is provided. There are three stages, including the secure-item preferences, privacy-policy management, and preference services for secure mining based correlations of items and items, as well as these. The suggested method for providing level-by-level privacy for the categorised datasets is used to construct a multi-agent based mechanism of privacy.
IV. RESULTS AND DISCUSSIONS
The accuracy requirements for various datasets are satisfied by the suggested SDCRA approach. The effectiveness of the method was evaluated in comparison to more established ones like perturbation, singular value decomposition (SVD), K-anonymity with Decision Tree (KADT), and SVD Data Perturbation (SVD+DP). The simulation environment consists of an Intel Dual-Core Processor with 4GB of RAM, Windows 7, Net Beans 8.5, JDK 2.1, MySQL 5.6, and Apache Tomcat 8.1.4. In this study, the suggested system is assessed using current methodologies utilising the open source Java-based Weka 3.8.2 library. The Secure Data-Contribution Retrieval Algorithm for data privacy level without efficiency and quality of application in Web environments is used in this part to depict the mathematical model. Additionally, this model's metrics include the system's execution time, success rate, and error rate. The query retrieval probability in the successful query-hit at least once is known as the SR. One may assume that the resources for the query are distributed evenly throughout the network with replication-ratio (R). When patient data is retrieved from a database, this ratio shows the amount of uncluttered or unclassified data. Furthermore, a statistical calculation shows the error rate for the whole clustered data set.
Table.1. offers the patient's success rate for diabetes, HIV, and cancer in terms of error rate (ER) in percentage and set expressed in seconds, and shows the average values for the relevant parameters together with the relevant data. Here, the SR, ER, and SET parameters of the SDCRA algorithm are compared to those of other methods like perturbation and SVD.
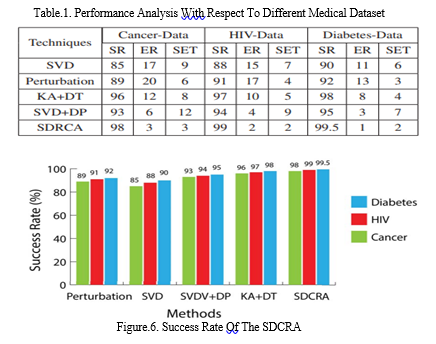
In the same setting, the suggested approach and the current methods are compared. The suggested SDCRA approach and current methods to quantify the success rate were applied to the data for diabetes, HIV, and cancer, and the results were compared in Fig. 6. When compared to alternative privacy-preserving methods, the suggested SDCRA approach has a greater success rate. The success percentage of the suggested SDCRA approach is 99.5%, whereas the success rate of other methods, such KA+DT, is 98%. Compared to other current approaches, the suggested SDCRA method has a reduced error rate. For the cancer data, it has an error value of 3, compared to the previous KA+DT method's error value of 12. The Success Rate (SR) measure, the most accurate of the three performance metrics, is crucial. All of the learning algorithms that have been used, including Perturbation, Singular Value Decomposition (SVD), Singular Value Decomposition with Data Perturbation (SVD+DP), and K-Anonymity with Decision Tree (KA+DT), have performed optimum in terms of Success Rate. When compared to the suggested method, the KA+DT strategy is the one that produces the closest results. Singular Value Decomposition with Data Perturbation (SVD+DP), a method that combines Singular Value Decomposition with Data Perturbation, produces superior results despite their lower success rates when used alone. As demonstrated in Fig. 6, the suggested SDCRA technique here has a greater success rate of 98%. This approach calculates each attribute's rate and visualises the outcome based on that rate, however it is unable to reduce the rate of data prediction inaccuracy. Systems that execute queries and get results from systems where perturbation is the closest approximation. The technique is often used to maintain privacy and distort data, but it is unable to reconstruct the original data and takes more time for data visualisation. The proposed strategy improves success rate by 1.83%, lowers error rate by 2.33%, and shortens system execution time by 2 seconds.
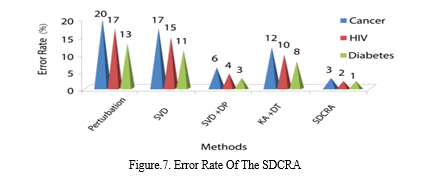
Figure.7. compares the Error Rate (ER) % for the datasets for diabetes, HIV, and cancer using the current methods. K-Anonymity with Decision Tree (KA+DT) approach yields the third-worst outcome in this situation. Individually Singular Value Decomposition and Data Perturbation are similarly unpromising in terms of the Error Rate. However, the nearest rival to the suggested SDCRA technique is the SVD+DP combo (SVD+DP). It is important to note that the Cancer datasets have a greater error rate than the other two datasets when comparing the findings of the supplied datasets.
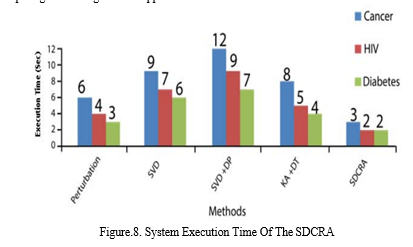
Figure.8 compares and calculates the execution times of the various privacy protection strategies. The suggested SDCRA method takes the least amount of time to execute in comparison to the other techniques. For diabetic data, the conventional technique takes four seconds to execute compared to two seconds for the suggested SDCRA method. As a result, the suggested SDCRA approach for protecting privacy in data mining has a greater success rate, a lower mistake rate, and a shorter execution time. Because of this, the performance of the privacy-preserving strategy may be improved by using the SDCRA method.
Conclusion
The suggested SDCRA method did a good job of supplying all-around security in the online environment. The algorithm tests if the programme and its operating environment are compatible with privacy. The technique uses a new feature to apply privacy by making advantage of application compatibility. This SDCRA algorithm is not only committed to enhancing data security; it also takes into account how security is effectively employed to contribute and retrieve the data with the least amount of processing time. The suggested approach also reduced the system execution time by 2 seconds while increasing success rates by 1.83% and error rates by 2.33%. The need for a method to secure and privacy-preserving approaches to protecting user data across online social networks remains because the proposed SDCRA method is not very effective in ensuring the validity of relationships between the sender and receiver because it is designed for a web-based environment.
References
[1] Attrapadung, N., Libert, B. and De Panafieu, E. (2011), Expressive key-policy attributebased encryption with constant-size ciphertexts, in ‘International Workshop on Public Key Cryptography’, Springer, pp. 90–108. [2] Backstrom, L., Dwork, C. and Kleinberg, J. (2007), Wherefore art thou r3579x?: anonymized social networks, hidden patterns, and structural steganography, in ‘Proceedings of the 16th international conference on World Wide Web’, ACM, pp. 181–190. [3] Bahri, L., Carminati, B. and Ferrari, E. (2018), ‘Decentralized privacy preserving services for online social networks’, Online Social Networks and Media 6(1), 18–25. [4] Bethencourt, J., Sahai, A. and Waters, B. (2007), Ciphertext-policy attribute-based encryption, in ‘2007 IEEE symposium on security and privacy (SP’07)’, IEEE, pp. 321– 334. [5] Bhavsar, H. and Ganatra, A. (2012), ‘A comparative study of training algorithms for supervised machine learning’, International Journal of Soft Computing and Engineering (IJSCE) 2(4), 2231–2307. [6] Bhuyan, H. K. and Kamila, N. K. (2015), ‘Privacy preserving sub-feature selection in distributed data mining’, Applied soft computing 36, 552–569. [7] Chakraborty, R., Vishik, C. and Rao, H. R. (2013), ‘Privacy preserving actions of older adults on social media: Exploring the behavior of opting out of information sharing’, Decision Support Systems 55(4), 948–956. [8] Chakraborty, S. and Tripathy, B. (2016), ‘Alpha-anonymization techniques for privacy preservation in social networks’, Social Network Analysis and Mining 6(1), 29. [9] Chamikara, M., Bertok, P., Liu, D., Camtepe, S. and Khalil, I. (2019), ‘An efficient and scalable privacy preserving algorithm for big data and data streams’, Computers and Security 87, 101570. [10] Chase, M. and Chow, S. S. (2009), Improving privacy and security in multi-authority attribute-based encryption, in ‘Proceedings of the 16th ACM conference on Computer and communications security’, ACM, pp. 121–130. [11] Chen, M.-S., Park, J. S. and Yu, P. S. (1996), Data mining for path traversal patterns in a web environment, in ‘Proceedings of 16th International Conference on Distributed Computing Systems’, IEEE, pp. 385–392. [12] Dubey, S. and Rathod, S. (2016), ‘Implementation of privacy preserving methods using hadoop framework’, International Research Journal of Engineering and Technology (IRJET) 3(5), 1268–1272. [13] Erkin, Z., Veugen, T., Toft, T. and Lagendijk, R. L. (2013), ‘Privacy-preserving distributed clustering’, EURASIP Journal on Information Security 2013(1), 4–14. [14] Erola, A., Castella-Roca, J., Viejo, A. and Mateo-Sanz, J. M. (2011), ‘Exploiting so- ` cial networks to provide privacy in personalized web search’, Journal of Systems and Software 84(10), 1734–1745. [15] Fan, K., Wang, X., Suto, K., Li, H. and Yang, Y. (2018), ‘Secure and efficient privacypreserving ciphertext retrieval in connected vehicular cloud computing’, IEEE Network 32(3), 52–57. [16] Goyal, V., Pandey, O., Sahai, A. and Waters, B. (2006), Attribute-based encryption for fine-grained access control of encrypted data, in ‘Proceedings of the 13th ACM conference on Computer and communications security’, Acm, pp. 89–98. [17] Han, S. and Ng, W. K. (2007), Privacy-preserving genetic algorithms for rule discovery, in ‘International conference on data warehousing and knowledge discovery’, Springer, pp. 407–417. [18] Harnsamut, N. and Natwichai, J. (2008), A novel heuristic algorithm for privacy preserving of associative classification, in ‘Pacific Rim International Conference on Artificial Intelligence’, Springer, pp. 273–283. [19] Hay, M., Miklau, G., Jensen, D., Weis, P. and Srivastava, S. (2007), ‘Anonymizing social networks’, Computer science department faculty publication series p. 180. [20] Huai, M., Huang, L., Yang, W., Li, L. and Qi, M. (2015), Privacy-preserving naive bayes classification, in ‘International conference on knowledge science, engineering and management’, Springer, pp. 627–638. [21] Ibrahim, Y. and Weikum, G. (2019), Exquisite: Explaining quantities in text, in ‘The World Wide Web Conference’, WWW ’19, ACM, New York, NY, USA, pp. 3541– 3544. URL: http://doi.acm.org/10.1145/3308558.3314134 [22] Islam, M. Z. and Brankovic, L. (2011), ‘Privacy preserving data mining: A noise addition framework using a novel clustering technique’, Knowledge-Based Systems 24(8), 1214–1223. [23] Kamakshi, P. and Babu, A. V. (2012), Automatic detection of sensitive attribute in ppdm, in ‘2012 IEEE international conference on computational intelligence and computing research’, IEEE, pp. 1–5. [24] Kosinski, M., Bachrach, Y., Kohli, P., Stillwell, D. and Graepel, T. (2014), ‘Manifestations of user personality in website choice and behaviour on online social networks’, Machine learning 95(3), 357–380. [25] Krumholz, H. M. (2014), ‘Big data and new knowledge in medicine: The thinking, training, and tools needed for a learning health system’, Health Affairs 33(7), 1163– 1170. [26] Li, G. and Wang, Y. (2012), ‘A privacy-preserving classification method based on singular value decomposition.’, Int. Arab J. Inf. Technol. 9(6), 529–534. [27] Li, H., Zhu, H., Du, S., Liang, X. and Shen, X. (2018), ‘Privacy leakage of location sharing in mobile social networks: Attacks and defense’, IEEE Transactions on Dependable and Secure Computing 15(4), 646–660. [28] Li, M., Yu, S., Cao, N. and Lou, W. (2013), ‘Privacy-preserving distributed profile matching in proximity-based mobile social networks’, IEEE Transactions on Wireless Communications 12(5), 2024–2033. [29] Liang, K., Fang, L., Susilo, W. and Wong, D. S. (2013), A ciphertext-policy attributebased proxy re-encryption with chosen-ciphertext security, in ‘2013 5th International Conference on Intelligent Networking and Collaborative Systems’, IEEE, pp. 552–559. [30] Liben-Nowell, D. and Kleinberg, J. (2007), ‘The link-prediction problem for social networks’, Journal of the American society for information science and technology 58(7), 1019–1031.
Copyright
Copyright © 2022 Kotha Nikhil Reddy, Mohammed Nasser Hussain, Talla Vivek Sagar, Prathapagiri Harish Kumar, Kale Srinitha. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Download Paper
Paper Id : IJRASET46969
Publish Date : 2022-10-03
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online