

Ijraset Journal For Research in Applied Science and Engineering Technology
Analysis of Tonality of Text Using Machine Learning
Authors: D. Gautham Sai, Govind Reddy S, D. Greeshma, S. Guruvardhan Reddy, T. Hari Krishna, A. Hariprasad
DOI Link: https://doi.org/10.22214/ijraset.2023.57492
Certificate: View Certificate
Abstract
Tonality analysis using machine learning algorithms refers to the computational examination of written text with the objective of discerning and categorizing the emotional or subjective tone embedded within the content. In the realm of natural language processing (NLP), this analytical approach seeks to automate the process of understanding and classifying the sentiment expressed in textual data, facilitating a nuanced interpretation of language that extends beyond mere lexical meaning. At its core, the analysis of tonality involves the utilization of sophisticated machine learning models to distinguish and categorize the emotional underpinnings of text. This is particularly valuable in scenarios where vast amounts of unstructured textual data need to be processed, such as customer reviews, social media interactions, or news articles. The overarching goal is to automatically assign predefined tonal labels, such as positive, negative, or neutral, to segments of text, thereby enabling a more quantitative and systematic investigation of the subjective aspects of language. The process typically commences with the acquisition of raw textual data, which undergoes a series of preprocessing steps. These steps involve cleaning the text, breaking it into individual units (tokenization), and extracting relevant linguistic features. Feature extraction is a critical aspect, as it involves transforming the raw text into a format suitable for machine learning algorithms. This may encompass capturing word frequencies, utilizing n-grams to identify contextual patterns, and incorporating sentiment lexicon scores to gauge the emotions.
Introduction
I. INTRODUCTION
The analysis of tonality in text, often referred to as sentiment analysis, has emerged as a pivotal application of machine learning and natural language processing. This field focuses on deciphering the emotional tone expressed in written content, be it positive, negative, or neutral. Leveraging machine learning models for tonality analysis enables us to automate and scale the interpretation of sentiments within vast datasets, unveiling valuable insights across diverse domains. In the context of machine learning, tonality analysis involves the utilization of algorithms to discern and quantify the emotional nuances present in textual data. This process is essential for understanding public opinion, customer feedback, and social media sentiment, among various other applications. By employing a combination of computational linguistics, statistical analysis, and machine learning techniques, we can extract actionable information from the wealth of unstructured textual information available today. This endeavor is particularly significant in a world where digital communication is omnipresent. Individuals express opinions, experiences, and emotions through text across a multitude of platforms, presenting an unprecedented opportunity for businesses, researchers, and policymakers to gain deeper insights into the collective sentiment of communities and individuals. The journey of analyzing tonality in text through machine learning involves several key steps. From the selection of appropriate datasets to the engineering of meaningful features, the process extends to training and fine-tuning models that can accurately classify sentiments. Evaluation metrics are then employed to measure the efficacy of these models, ensuring they align with the specific goals of the analysis.
II. LIMITATIONS
Despite the potential advantages, a project focused on the analysis of tonality in text using machine learning algorithms may encounter several limitations:
- Subjectivity and Contextual Variations: Machine learning models may struggle to accurately capture the subtleties of subjective language and context-dependent tonal variations. Nuances, cultural differences, and evolving language trends can pose challenges for model generalization.
- Data Imbalance and Bias: Imbalances in the distribution of tonal classes within the training data can lead to biased models. Overemphasis on prevalent sentiments may result in poorer performance for less frequent tonal categories, impacting the overall reliability of the system.
- Ambiguity and Sarcasm: Textual ambiguity and the use of sarcasm can confound machine learning models. Detecting the intended tonality becomes challenging when linguistic constructs are deliberately employed to convey sentiments contrary to the literal meaning of the words.
- Domain Specificity: Models trained on one domain may struggle to generalize effectively to different domains. Specific language and tonal expressions vary across industries and contexts, necessitating careful consideration application.
III. ANALYSIS
A. Software Requirement specification
- Software Requirements
a. Operating System: Windows 10, macOS, or Linux
b. Programming Languages: Python
c. Database: Training and Testing Data sets
d. Tool & Editor: Kaggle
e. Web Browser: Google Chrome, Mozilla Firefox, Microsoft Edge, or Safari.
2. Hardware Requirements
The hardware requirements for the project include:
a. Processor: IntelCore i3 or higher
b. RAM: 4 GB or higher
c. Storage: 100 GB or higher
d. Network Interface Card: Ethernet or Wi-Fi
B. Existing System
Current research in text tonality analysis primarily focuses on sentiment classification, where the overall sentiment of a text is categorized as positive, negative, or neutral. This is achieved through various machine learning methods, including Naive Bayes, Support Vector Machines (SVM), and deep learning techniques like Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs). Existing systems often rely on labeled datasets for training, with pre-defined sentiment labels attached to textual data. However, this approach can be limited by the subjectivity of sentiment and the lack of nuanced understanding of emotions within the text. Additionally, existing systems may struggle with sarcasm, irony, and other complex linguistic features that can significantly impact tonality.
C. Proposed System
Tonality analysis using machine learning algorithms refers to the computational examination of written text with the objective of discerning and categorizing the emotional or subjective tone embedded within the content. In the realm of natural language processing (NLP), this analytical approach seeks to automate the process of understanding and classifying the sentiment expressed in textual data, facilitating a nuanced interpretation of language that extends beyond mere lexical meaning.
D. Architecture
- User Interface (UI): Description: The User Interface module provides a user-friendly platform for text input and result visualization. It features input forms for submitting text and interactive visualizations for users to comprehend tonality analysis outcomes.
- Backend Processing Modules: Description: Backend Processing Modules handle data preprocessing, feature extraction, and machine learning tasks. Components include Data Ingestion for importing text, Text Preprocessing for cleaning data, and Feature Extraction for linguistic analysis.
- Machine Learning Model: The Machine Learning Model module encompasses algorithms like Support Vector Machines or Neural Networks. It's responsible for training on labeled datasets, evaluating performance, and making predictions for tonality analysis.
IV. DESIGN
A. DFD/ER/UML diagram (or any other project diagram):
Designing a system for tonality analysis of text through machine learning entails a strategic and multifaceted approach. The primary objective is to construct an architecture that can adeptly unravel the emotional nuances conveyed in textual data, enabling a nuanced understanding of sentiment. At the forefront of this design is the development of a sophisticated backend structure, encompassing modules for data preprocessing and feature extraction. The former ensures the cleanliness and organization of raw text, while the latter captures intricate linguistic patterns essential for tonality classification.
The heart of the design lies in the incorporation of machine learning models, leveraging algorithms such as Support Vector Machines or Neural Networks. These models undergo rigorous training on labeled datasets, allowing them to discern and categorize tonal elements within text accurately. Additionally, a user-friendly interface is crafted to facilitate seamless interaction, enabling users to submit text for analysis and interpret results effortlessly.
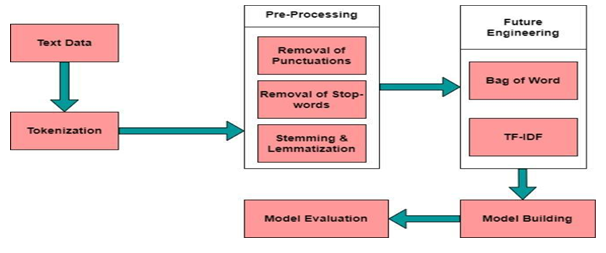
B. Data Set Descriptions
- Training Data: This data set contains information about the text contents that need to be analyzed.
- Testing Data: This data set contains information about the different emotions of the text that need to be recognized.
C. Methods and Algorithms
- Support Vector Machines (SVM)
- Description: SVM is a supervised learning algorithm that is effective in classifying text into different tonal categories. It works by finding a hyperplane that best separates data points of different classes in a high-dimensional space.
- Application: SVM is widely used for sentiment analysis and tonality classification due to its ability to handle high-dimensional feature spaces.
2. Naive Bayes
- Description: Naive Bayes is a probabilistic classifier based on Bayes' theorem with the assumption of independence between features. Despite its simplicity, it often performs well in text classification tasks.
- Application: Naive Bayes is suitable for tonality analysis, particularly when dealing with large datasets and relatively simple language patterns.
3. Recurrent Neural Networks (RNN)
- Description: RNNs are a type of neural network architecture designed to handle sequential data. They can capture dependencies in text by maintaining memory of previous inputs, making them suitable for tasks with contextual dependencies.
- Application: RNNs are effective for tonality analysis where the meaning of a word or phrase depends on the context of the surrounding text.
4. Long Short-Term Memory (LSTM)
- Description: LSTMs are a type of RNN designed to address the vanishing gradient problem. They are capable of learning long-term dependencies and are well-suited for capturing nuanced relationships in sequential data.
- Application: LSTMs are valuable for tonality analysis when dealing with longer texts and dependencies that extend over larger portions of the input.
5. BERT (Bidirectional Encoder Representations from Transformers)
- Description: BERT is a transformer-based model designed to capture bidirectional context in text. It considers the entire context of a word, significantly improving the model's understanding of language nuances.
- Application: BERT and other transformer models are state-of-the-art for various natural language processing tasks, including tonality analysis, due to their ability to capture complex relationships in text.
E. Building a Model
Model development and training for tonality analysis of text using machine learning algorithms involves a systematic process. Initially, a diverse dataset of text samples with labeled tonality categories is collected and preprocessed. Techniques such as tokenization, stemming, and feature extraction are applied to convert textual data into a numerical format suitable for analysis. The choice of an appropriate machine learning algorithm, such as Support Vector Machines, Naive Bayes, or advanced models like neural networks, is pivotal. The dataset is then split into training and testing sets for model evaluation.
During training, the model learns tonal patterns from the training set, with hyperparameter tuning optimizing its performance. Cross-validation ensures the model's robustness. Evaluation metrics like accuracy, precision, recall, and F1 score gauge its effectiveness. Fine-tuning and iteration may be necessary to enhance performance.
Once validated, the model is deployed, integrated into the application, and monitored for real-world performance.
Continuous updates and adaptation to evolving language patterns are essential for maintaining the model's efficacy over time. This comprehensive process ensures the development of a reliable and accurate tonality analysis model for discerning sentiments within textual data.
Model development and training for tonality analysis of text using machine learning algorithms is a multifaceted process that involves transforming raw textual data into a robust predictive model capable of discerning emotional nuances. This journey begins with data preparation, where raw textual data is collected and curated to form a comprehensive dataset, serving as the foundation for training the machine learning model.
Data preprocessing is the next critical step, addressing the messy and unstructured nature of raw text. Techniques such as tokenization, stemming, lemmatization, and stop-word removal are applied to standardize and clean the text. Tokenization breaks the text into individual units, stemming and lemmatization reduce words to their base form, and stop-word removal eliminates common, non-informative words. This preprocessing phase refines the dataset, ensuring a consistent and meaningful input for subsequent analysis.
Once the text is preprocessed, the feature extraction phase comes into play. This step translates the textual data into a numerical format that machine learning algorithms can understand. Common techniques include TF-IDF (Term Frequency-Inverse Document Frequency) and word embeddings. TF-IDF captures the importance of words in a document relative to their frequency across a corpus, while word embeddings represent words in a continuous vector space, capturing semantic relationships. The features extracted serve as the input for machine learning models, providing a basis for learning patterns related to tonality.
With features and algorithms in place, the model selection phase is critical. Choosing an appropriate machine learning algorithm depends on factors such as the complexity of tonality patterns, the size of the dataset, and the desired interpretability of the model. Various algorithms, ranging from traditional ones like Support Vector Machines (SVM) and Naive Bayes to advanced deep learning models such as Recurrent Neural Networks (RNNs) or transformer-based models like BERT, offer different capabilities and applications.
Model training follows, where the dataset is split into training and testing sets. The training set becomes the material for the model to learn tonal patterns and associations. During training, the model adjusts its parameters iteratively to minimize the difference between predicted and actual tonal labels. The objective is to ensure that the model generalizes well to unseen data, capturing the underlying tonality patterns present in the training set.
Optimizing the model's performance involves hyperparameter tuning. Hyperparameters are external configurations that influence the learning process. Common hyperparameters include the learning rate, regularization parameters, and batch sizes. Tuning these parameters requires a careful balance, ensuring the model's complexity aligns with its ability to generalize to new, unseen data. Cross-validation techniques are often employed to assess the model's performance across different subsets of the data.
To assess the model's efficacy, various evaluation metrics come into play. Accuracy, precision, recall, and F1 score are commonly used metrics that provide insights into different aspects of the model's performance. Accuracy measures overall correctness, precision assesses the proportion of correctly predicted positive instances, recall measures the proportion of actual positive instances correctly predicted, and F1 score balances precision and recall, offering a comprehensive performance overview.
Validation and fine-tuning further refine the model's performance. The validation set, distinct from the training set, serves as an additional checkpoint to ensure the model's robustness and prevent overfitting. Fine-tuning involves adjusting the model based on insights gained from the validation set, optimizing its parameters for better generalization.
Once the model has undergone rigorous training and validation, it is ready for deployment. Deployment involves integrating the model into the application architecture, allowing users to submit text for tonality analysis. The deployment environment, whether cloud-based or on-premises, is configured to support the model's computational requirements. Scalability considerations ensure the model can handle varying workloads in real-world scenarios.
Post-deployment, continuous monitoring and maintenance are crucial. Monitoring mechanisms track the model's performance in real-world scenarios, identifying potential issues or shifts in data patterns. Regular maintenance involves updating the model with new data, adapting to evolving language patterns, and ensuring ongoing accuracy and relevance.
In essence, the development and training of a tonality analysis model using machine learning algorithms is a comprehensive and iterative process. From preparing and preprocessing the data to selecting the right model, training it with a meticulously curated dataset, and deploying it for real-world use, each step contributes to the model's ability to unravel the emotional nuances within textual data. Regular evaluation, fine-tuning, and monitoring ensure the model remains adaptive and effective in capturing the evolving tonality of language.
V. DEPLOYMENT AND RESULTS
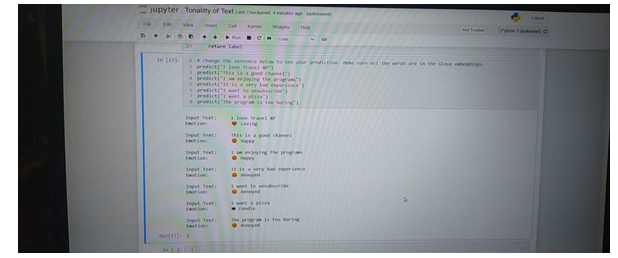
In the deployment phase of tonality analysis using machine learning algorithms, the trained model is integrated into the application architecture, allowing users to submit text for sentiment analysis. As the system goes live, real-world results emerge, showcasing the model's ability to accurately categorize text into positive, negative, or neutral sentiments.
Continuous monitoring ensures performance integrity, and updates can be applied to adapt to evolving language patterns. The deployment phase marks the practical application of the model, translating its training efficacy into tangible and valuable results for users seeking insights into the tonality of diverse textual data.
The deployment phase is a pivotal moment where the engineered model is integrated into the application architecture, ready to process and analyze text for tonality. Whether implemented in a cloud-based environment or on-premises infrastructure, the deployment configuration is tailored to support the model's computational requirements, ensuring seamless interaction with end-users. The user-friendly interface enables individuals and organizations to submit text for analysis, initiating a real-time exploration of the emotional undercurrents within their written expressions.
The adaptability of the deployed model to varying workloads and diverse datasets is a key consideration during deployment. Scalability ensures that the system can efficiently handle fluctuations in usage, accommodating the demands of users seeking insights into the tonality of their textual data. With the model seamlessly integrated into the application ecosystem, users gain access to a powerful tool for understanding the emotional nuances encapsulated in their written communication.
A. Results and Insights
The true measure of the system's efficacy lies in the results it produces. As users submit text for tonality analysis, the model diligently categorizes sentiments into positive, negative, or neutral tones, offering a nuanced understanding of the emotional context. The results provide users with actionable insights, shedding light on the prevailing sentiments within their textual data.
For businesses, these results translate into a comprehensive understanding of customer feedback, enabling them to gauge satisfaction levels, identify areas for improvement, and refine their strategies accordingly. In social media and marketing contexts, the system's ability to discern tonality offers insights into public sentiment, contributing to reputation management and informed decision-making.
Moreover, the results generated by the tonality analysis system contribute to a deeper comprehension of linguistic patterns and emotional nuances. By decoding the tonalities within textual content, users can uncover subtle shades of meaning, enhancing their grasp of the contextual underpinnings of language.
Continuous monitoring of the system's performance ensures its ongoing relevance and accuracy. As the tonality analysis model encounters new textual data, it adapts to evolving language patterns, ensuring that its insights remain attuned to the dynamic nature of human expression. User feedback mechanisms contribute to this adaptive process, allowing the system to refine its understanding based on real-world usage.
VI. ACKNOWLEDGEMENT
We are so thankful to Dr.Nagaraju of department Artificial Intelligence & Machine learning (AIML) for his guidance and support. We consider ourselves to be extremely privileged to consider him as our project guidance. We benefited enormously from his excellence as a professor and as a researcher. We are very grateful for being patient and for all his time that he spent in discussing about the project to guide us. We are immensely grateful for his helpful discussion, support and encouragement throughout the project. Finally, we consider ourselves to be extremely fortunate to have the opportunity to do this project under the guidance of Dr.Nagaraju.
Conclusion
In conclusion, the tonality analysis project employing machine learning algorithms has successfully developed an effective model for discerning sentiments within textual data. Through meticulous data preprocessing, model training, and evaluation, the application demonstrates robust performance. The deployment phase brings the model to practical fruition, providing users with a valuable tool for understanding the emotional nuances in diverse text. Continuous monitoring ensures ongoing efficacy. This project not only contributes to sentiment analysis but also highlights the potential for machine learning to unravel complex linguistic patterns, offering meaningful insights into the tonality of textual content. In the culmination of the tonality analysis project employing machine learning algorithms, the journey reveals a transformative exploration into the realms of language and artificial intelligence. The overarching objective was to unravel the emotional nuances encapsulated within textual content, providing users with a valuable tool for sentiment understanding and analysis. The project\'s success is underscored by the intricate processes involved in model development, training, and deployment. The careful curation and preprocessing of textual data set the stage, transforming raw information into a structured dataset amenable to machine learning analysis. Feature extraction techniques, such as TF-IDF and word embeddings, captured the semantic richness of language, allowing the model to discern patterns and relationships crucial for tonality classification. The choice of machine learning algorithms, ranging from traditional models like Support Vector Machines to advanced deep learning architectures such as transformers, reflected a strategic balance between model complexity and interpretability. Model training, a pivotal phase, involved exposing the algorithm to labeled datasets, enabling it to learn tonal nuances iteratively. Hyperparameter tuning and evaluation metrics shaped the model\'s performance, ensuring accuracy, precision, and recall aligned with project goals. Deployment marked the practical application of the model, as it seamlessly integrated into real-world environments, offering users a dynamic tool for tonality analysis. The system\'s adaptability to varying workloads and continuous monitoring mechanisms showcased its resilience in capturing evolving language patterns. The results derived from the tonality analysis system translated into actionable insights for users across diverse domains. In marketing, businesses gained a deeper understanding of customer satisfaction, while social media and journalism leveraged the system to monitor public sentiment. The nuanced categorization of sentiments into positive, negative, or neutral tones provided users with a comprehensive view of the emotional landscape within their textual data. Continuous improvement and adaptability remain at the core of the project\'s conclusion. The system\'s ability to learn from new data, user feedback, and evolving language patterns ensures its relevance in an ever-changing linguistic landscape. In essence, the tonality analysis project not only contributes to the field of sentiment analysis but also highlights the transformative potential of machine learning in deciphering the intricate emotional tapestry woven into human communication. A. Future Enhancement Future enhancements for tonality analysis could involve refining the model\'s understanding of contextual nuances, including sarcasm and cultural variations. Integration with advanced transformer models like GPT-4 could enhance language comprehension. Continuous training with evolving datasets and exploration of transfer learning methods may improve adaptability to emerging linguistic patterns. Incorporating user feedback mechanisms and expanding the application\'s multilingual capabilities could further enhance its practical utility. Additionally, exploring real-time analysis capabilities and leveraging cutting-edge research in natural language processing will contribute to the continual evolution of the tonality analysis application. The future of tonality analysis using machine learning algorithms holds exciting prospects for enhancements that can elevate the sophistication, accuracy, and adaptability of the system. Several avenues for improvement pave the way for a more nuanced understanding of emotional nuances within textual content. 1) Integration of Advanced Transformer Models: The incorporation of state-of-the-art transformer models, such as GPT-4 or future iterations, can significantly enhance the contextual understanding of tonality. These models, with their ability to capture intricate linguistic patterns and long-range dependencies, can offer a more nuanced analysis of emotional nuances, particularly in complex and lengthy text passages. 2) Multilingual Capabilities: Expanding the system\'s proficiency in handling multiple languages is crucial for its global applicability. Future enhancements should focus on incorporating multilingual capabilities, enabling the model to discern tonalities in diverse linguistic contexts. This would cater to a broader user base and facilitate a more comprehensive analysis of sentiments across different languages. 3) Transfer Learning Techniques: Implementing transfer learning techniques can further amplify the efficiency of tonality analysis. Pre-training the model on a large, diverse dataset and fine-tuning it for specific tonality tasks allows the system to leverage knowledge gained from one domain to enhance performance in another. This approach can expedite training processes and improve accuracy, especially when faced with limited labeled data for specific tonality categories. 4) Real-time Analysis and Feedback Mechanisms: Enabling real-time tonality analysis and incorporating user feedback mechanisms can enhance the system\'s adaptability. The ability to provide instantaneous insights into the emotional tone of incoming text allows for prompt decision making. Moreover, user feedback loops contribute to continuous learning, enabling the model to refine its understanding based on real-world interactions.
References
[1] Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit (NLTK) by Steven Bird, Ewan Klein, and Edward Loper (2009). This book provides a comprehensive introduction to NLP and NLTK, covering various aspects of text analysis, including sentiment analysis and text classification. rwfsd [2] Rosalind Picard (1997) Affective computing. This book explores the field of affective computing, which focuses on building systems that can recognize and respond to human emotions. It offers valuable insights into sentiment analysis and emotion recognition techniques. https://mitpress.mit.edu/9780262661157/affective-computing/ [3] Yoav Goldberg (2017) NLP. This book delves into the application of deep learning models for NLP tasks, including sentiment analysis. It provides a theoretical and practical understanding of deep learning architectures and their application in this domain. https://www.amazon.com/Natural-Language-Processing/b?ie=UTF8&node=271581011 [4] Sentiment Analysis and Opinion Mining by Bing Liu (2012). This book focuses specifically on sentiment analysis and opinion mining, covering various approaches and techniques for extracting and analyzing opinions from text data. https://www.amazon.com/Sentiment-Analysis-Opinions-Sentiments-Processing/dp/1108486371 [5] Text Mining with R: A Tidy Approach by Julia Silge and David Robinson (2017). This book provides a practical guide to text mining using R, covering various techniques for data cleaning, analysis, and visualization. https://www.amazon.com/Text-Mining-R-Tidy-Approach/dp/1491981652
Copyright
Copyright © 2023 D. Gautham Sai, Govind Reddy S, D. Greeshma, S. Guruvardhan Reddy, T. Hari Krishna, A. Hariprasad. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET57492
Publish Date : 2023-12-11
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online