

Ijraset Journal For Research in Applied Science and Engineering Technology
Towards Contrastive and Data Driven Cloud Data Center Energy Prediction using Regression Analysis
Authors: G.S. Devi Lakshmi, K Kavitha, Abhinaya Premchand
DOI Link: https://doi.org/10.22214/ijraset.2024.61234
Certificate: View Certificate
Abstract
Data centers are the backbone of todays Internet and cloud computing systems. Due to the increasing demand for electrical energy by data centers, it is necessary to account for the vast amount of energy they consume. Energy modeling and prediction of data centers plays a pivotal role in this context. In this study, we address the challenge of predicting energy consumption in cloud data centers, crucial for managing their significant electricity demand. Despite numerous existing methods, there remains a lack of robust methodologies. To fill this gap, we propose a novel approach that incorporates aleatoric uncertainty estimation. Our method utilizes regression distributions to model this uncertainty, with parameters derived from regressive techniques. This yields energy consumption predictions as random variables drawn from these distributions. Additionally, we illustrate how these random variables can be aggregated to form probabilistic forecasts for diverse data center portfolios. Our methodology achieves three key advancements: 1) introducing a simple multiple linear regression model for fundamental series; 2) devising a unique method that combines quantile regression and empirical copulas to estimate joint distribution; 3) enhancing prediction accuracy through a weighted correction technique based on constrained quantile regression.
Introduction
I. INTRODUCTION
Data centers are large scale, mission-critical computing infrastructures that are operating around the clock, to propel the fast growth of IT industry and transform the economy at large. The criticality of data centers has been fueled mainly by two phenomenon. First, the ever increasing growth in the demand for data computing, processing and storage by a variety of large scale cloud services, such as Google and Facebook, by telecommunication operators such as British Telecom, by banks and others, resulted in the proliferation of large data centers with thousands of servers (sometimes with millions of servers). Second, the requirement for supporting a vast variety of applications ranging from those that run for a few seconds to those that run persistently on shared hardware platforms has promoted building large scale computing infrastructures. As a result, data centers have been touted as one of the key enabling technologies for the fast growing IT industry and at the same time, resulting in a global market size of 152 billion US dollars by 2016 .
Data centers, being large scale computing infrastructures have huge energy budgets, which have given rise to various energy efficiency issues. Energy efficiency of data centers has attained a key importance in recent years due to its (i) high economic, (ii) environmental, and (iii) performance impact. First, data centers have high economic impact due to multiple reasons. A typical data center may consume as much energy as 25,000 households. Data center spaces may consume up to 100 to 200 times as much electricity as standard office space. Furthermore, the energy costs of powering a typical data center doubles every five years. Therefore, with such steep increase in electricity use and rising electricity costs, power bills have become a significant expense for today’s data centers,. In some cases, power costs may exceed the cost of purchasing hardware. Second, data center energy usage creates a number of environmental problems,. For example, in 2005, the total data center power consumption was 1% of the total US power consumption and created as much emissions as a mid-sized nation like Argentina. In 2010 the global electricity usage by data centers was estimated to be between 1.1% and 1.5% of the total worldwide electricity usage, while in the US the data centers consumed 1.7% to 2.2% of all US electrical usage.
A recent study done by Van Heddeghem et al. has found that data centers worldwide consumed 270 TWh of energy in 2012 and this consumption had a Compound Annual Growth Rate (CAGR) of 4.4% from 2007 to 2012. Due to The amount of energy consumed by these two subcomponents depends on the design of the data center as well as the efficiency of the equipment. For example, according to the statistics published by the Infotech group (see Fig. 1), the largest energy consumer in a typical data center is the cooling infrastructure (50%) , , while servers and storage devices (26%) rank second in the energy consumption hierarchy. Note that these values might differ from data center to data center (see for example). In this paper we cover a broad number of different techniques used in the modeling of different energy consuming components. these reasons data center energy efficiency is now considered chief concern for data center operators, ahead of the traditional considerations of availability and security. Finally, even when running in the idle mode servers consume a significant amount of energy. Large savings can be made by turning off these servers. This and other measures such as workload consolidation need to be taken to reduce data center electricity usage. At the same time, these power saving techniques reduce system performance, pointing to a complex balance between energy savings and high performance. The energy consumed by a data center can be broadly categorized into two parts: energy use by IT equipment (e.g., servers, networks, storage, etc.) and usage by infrastructure facilities (e.g., cooling and power conditioning systems). Modern cloud data centers rack-mounted servers can consume up to 1000 watts of power each and attain peak temperature as high as 100 °C. The power consumed by a host is dissipated as heat to the ambient environment, and the cooling system is equipped to remove this heat and keep the host’s temperature below the threshold. Increased host temperature is a bottleneck for the normal operation of a data center as it escalates the cooling cost. It also creates hotspots that severely affect the reliability of the system due to cascading failures caused by silicon component damage. The report from Uptime Institute shows that the failure rate of equipment doubles for every 10°C increase above 21°C. Hence, thermal management becomes a crucial process inside the data center Resource Management System (RMS). Therefore, to minimize the risk of peak temperature repercussions, and reduce a significant amount of energy consumption, ideally, we need accurate predictions of thermal dissipation and power consumption of hosts based on workload level. In addition, a scheduler that efficiently schedules the workloads with these predictions using certain scheduling policies. However, accurate prediction of a host temperature in a steady-state data center is a nontrivial problem,. This is extremely challenging due to complex and discrepant thermal behavior associated with computing and cooling systems. Such variations in a data center are usually enforced by CPU frequency throttling mechanisms guided by Thermal Design Power (TDP), attributes associated with hosts such as its physical location, distance from the cooling source, and also thermodynamic effects like heat recirculation, . Hence, the estimation of the host temperature in the presence of such discrepancies is vital to efficient thermal management. Sensors are deployed on both the CPU and rack level to sense the CPU and ambient temperature, respectively. These sensors are useful to read the current thermal status. However, predicting future temperature based on the change in workload level is equally necessary for critically important RMS tasks such as resource provisioning, scheduling, and setting the cooling system parameters.
II. LITERATURE SURVEY
Renewable energy supply is a promising solution for datacenters increasing electricity monetary cost, energy consumption and harmful gas emissions. However, due to the instability of renewable energy, insufficient renewable energy supply may lead to the use of stored energy or brown energy. To handle this problem, in this paper, the existsing system propose an instability-resilient renewable energy allocation system. The existsing system define a jobs service-level-objective (SLO) as the successful running probability by only using supplied renewable energy. The system allocates jobs with the same SLO level to the same physical machine (PM) group, and powers each PM group with renewable energy generators that have probability no less than its SLO to produce the amount no less than its energy demand. We use a deep learning technique to predict the probability of producing the amount no less than each value of each renewable energy source, and predict the energy demands of each PM area. The existsing system formulate an optimization problem to match renewable energy resources with different instabilities to different PM groups for supply, and use reinforcement learning method and linear programming method to solve it. We further propose an energy-driven computing resource assignment method, which adjusts the amount of computing resource of each job based on job deadline and failure probability in each PM group, and a failure prediction based energy saving method. Real trace driven experiments show that our methods achieve much lower SLO violations, total energy monetary cost and total carbon emission compared to other methods and the effectiveness of individual methods. The existsing system use long short term memory (LSTM) deep learning model to predict the tail distribution of the amount of generated renewable energy of each energy source represented, i.e., the probability that it will generate no less than each certain amount of energy at each time slot of the next time period. Second, the existsing system use LSTM to predict the energy demand of each PM area.
The instability-resilient renewable energy allocation system conducts the mapping between renewable energy generators and PM areas to solve the above assignment problem. Therefore, it incorporates the following components: 1) It predicts the tail distribution of each renewable energy source and the energy demand in each PM area at each time slot in the next time period (Section IV-A). 2) Based on the predicted renewable energy generation and predicted energy demand, it assigns renewable energy sources to PM areas using RL-based method and linear programming method
III. PROPOSED SYSTEM
Energy consumption monitoring and prediction are part of the main research areas aiming at reducing carbon footprint, which also include areas focusing on energy-harvesting. This study aims to present a detailed analysis of how regression learning can predict energy demand in a cloud data center to improve the integration of energy sources. Accurately predicting energy demand is crucial for managing the cloud data center, as it allows for the optimal distribution and use of energy sources. The primary objective of this strategy is to improve the integration of energy sources by providing accurate energy demand forecasts that can aid in the administration of the cloud data center. Beginning with data collection, pre-processing, and model development, the proposed method continues with model evaluation and deployment. The joint distribution of random variables is estimated by combining quantile regression and empirical copulas. Without forecasting the mean demand for all nodes, the joint distribution that is used to exploit possible dependencies between associated nodes can be directly evaluated by using predicted quantiles at the lower level. It requires a small number of mathematical requirements and decreases the number of iterations necessary to get the optimal solution. Also, it employs stochastic random searches, so the derivative information is unwarranted.
The model is trained on relevant features and evaluated by comparing actual and predicted values. To avoid the overfitting of the models, we adopt kfold cross-validation where the value of k is set to 10. Furthermore, to evaluate the goodness of fit for different models, we use the Root Mean Square Error (RMSE) metric which is a standard evaluation metric in Regression-based problems.
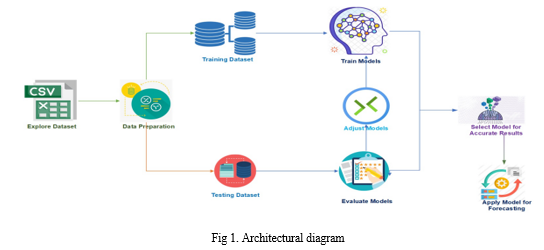
IV. DEEP LEARNING ALGORITHMS FOR PREDICTIONS
Linear regression is a foundational algorithm in statistics and machine learning, valued for its simplicity, interpretability, and versatility. Its advantages stem from its straightforward approach to modeling relationships between variables.
One significant advantage of linear regression is its interpretability. The output coefficients directly indicate the relationship between the independent variables and the target variable. Each coefficient represents the change in the target variable for a unit change in the corresponding independent variable, holding all other variables constant. This transparency enables practitioners to understand the impact of each predictor on the outcome, facilitating insights into the underlying data generating process.
Moreover, the linear nature of the model allows for clear interpretation of predictions. By representing predictions as a weighted sum of the input variables, linear regression provides a transparent mechanism for understanding how the model arrives at its forecasts. This visibility into the prediction process is particularly valuable in scenarios where interpretability is essential, such as in policy-making or decision support systems.
Additionally, linear regression offers mechanisms for addressing overfitting, a common challenge in machine learning. Overfitting occurs when a model learns to capture noise in the training data, leading to poor generalization performance on unseen data. Regularization techniques, such as Ridge regression or Lasso regression, can be employed to mitigate overfitting in linear regression models. These techniques introduce a penalty term to the objective function, constraining the magnitude of the coefficients and promoting simpler models. By controlling the complexity of the model, regularization helps prevent overfitting and improves the model's ability to generalize to new data.
Overall, the advantages of linear regression—interpretability, transparency in prediction, and mechanisms for addressing overfitting—make it a valuable tool in various domains, ranging from economics and finance to healthcare and social sciences. Despite its simplicity, linear regression remains a powerful and widely used algorithm, offering insights into relationships between variables and facilitating informed decision-making.
Conclusion
The development of accurate energy demand prediction models is essential for attaining multiple sustainable development objectives relating to affordable and clean energy, innovation and infrastructure, and climate action. Predictive models for energy demand can help mitigate the adverse effects of climate change and promote a more sustainable and environmentally benign energy system by reducing reliance on fossil fuels and promoting the use of renewable energy sources. Our proposed model represents a significant contribution to ongoing efforts to develop sustainable energy systems that can support a more equitable and environmentally favourable future. Estimating the energy in the data center is a complex and non-trivial problem. Existing approaches for temperature prediction are inaccurate and computationally expensive. Optimal thermal management with accurate temperature prediction can reduce the operational cost of a data center and increase reliability. Data-driven energy estimation of hosts in a data center can give us a more accurate prediction than simple mathematical models as we were able to take into consideration CPU and inlet airflow temperature variations through measurements. Our study which is based on physical host-level data collected from cloud data center has shown a large thermal variation present between hosts including CPU and inlet temperature. To accurately predict the host energy, we explored several ensemble learning algorithms. As our future work, we plan to focus on net-zero smart buildings with renewable energies, where we aim to investigate the combination of deep learning methods and optimization algorithms such as the Sine Cosine Algorithm, Genetic Algorithm, and Wolf Pack Algorithm. We also plan to consider load scheduling problems and use additional factors such as user satisfactions.
References
[1] Mohammed Elnawawy, Assim Sagahyroon, Michel Pasquier Power Prediction in Register Files Using Machine Learning IEEE Access, [2] Lianpeng Li,Jian Dong,Decheng Zuo,Jin Wu SLA-Aware and Energy-Efficient VM Consolidation in Cloud Data Centers Using Robust Linear Regression Prediction Model IEEE Access, [3] Congfeng Jiang,Yeliang Qiu,Honghao Gao,Tiantian Fan,Kangkang Li,Jian Wan An Edge Computing Platform for Intelligent Operational Monitoring in Internet Data Centers IEEE Access, 2019. [4] Leila Ismail,Eyad H. Abed Linear Power Modeling for Cloud Data Centers: Taxonomy, Locally Corrected Linear Regression, Simulation Framework and Evaluation IEEE Access, 2019 [5] Seyed Azad Nabavi,Naser Hossein Motlagh,Martha Arbayani Zaidan,Alireza Aslani,Behnam Zakeri Deep Learning in Energy Modeling: Application in Smart Buildings With Distributed Energy Generation IEEE Access, 2021 [6] Yufeng Guo,Qi Wang,Jie Wan,Donghui Yang,Jilai Yu,Kaiwen Zeng Provincial Energy Efficiency Prediction in China Based on Classification Method IEEE Access, 2019 [7] Khushboo Jain,Arun Agarwal,Ajith Abraham A Combinational Data Prediction Model for Data Transmission Reduction in Wireless Sensor Networks IEEE Access, 2022 [8] Fagui Liu,Zhenjiang Ma,Bin Wang,Weiwei Lin A Virtual Machine Consolidation Algorithm Based on Ant Colony System and Extreme Learning Machine for Cloud Data Center IEEE Access, 2019 [9] Zhou Zhou,Jemal H. Abawajy,Fangmin Li,Zhigang Hu,Morshed U. Chowdhury,Abdulhameed Alelaiwi,Keqin Li Fine-Grained Energy Consumption Model of Servers Based on Task Characteristics in Cloud Data Center IEEE Access, 2017 [10] A. Rayan and Y. Nah, Energy-aware resource prediction in virtualized data centers: A machine learning approach, Proc. IEEE Int. Conf. Consum. Electron.-Asia (ICCE-Asia), pp. 206-212, Jun. 2018. [11] J. Zhao, T. Liang, S. Sinha and W. Zhang, Machine learning based routing congestion prediction in FPGA high-level synthesis, Proc. Des. Autom. Test Eur. Conf. Exhib., pp. 1130-1135, 2019. [12] X. Guan and Y. Fei, Reducing power consumption of embedded processors through register file partitioning and compiler support, Proc. Int. Conf. Appl.-Specific Syst. Archit. Process., pp. 269-274, Jul. 2008 [13] Rui Shi,Chunmao Jiang Three-Way Ensemble Prediction for Workload in the Data Center IEEE Access, [14] Mohammed Elnawawy,Assim Sagahyroon,Michel Pasquier Power Prediction in Register Files Using Machine Learning IEEE Access, 2022 [15] Microsoft, “What is automated machine learning (AutoML)?” https://docs.microsoft.com/en-US/azure/machine-learning/concept-automated-ml, (Accessed: July 2021). [16] Bouguettaya, A., Zarzour, H., Kechida, A. et al. Deep learning techniques to classify crops through UAV imagery: a review. Neural Comput & pplic 34, 9511– 9536 (2022). Zhong L, Hu L, Zhou H (2019) Deep learning based multi-temporal crop classification. Remote Sens Environ 221:430–443. Adrian J, Sagan V, Maimaitijiang M (2021) Sentinel sar-optical fusion for crop type mapping using deep learning and Google Earth engine. ISPRS J Photogramm Remote Sens 175:215–235. [17] Bah MD, Hafiane A, Canals R (2019) Crownet: deep network for crop row detection in UAV images. IEEE Access 8:5189–5200. [18] Bayraktar E, Basarkan ME, Celebi N (2020) A low-cost UAV framework towards ornamental plant detection and counting in the wild. ISPRS J Photogramm Remote Sens 167:1–11. Bhosle K, Musande V (2020) Evaluation of CNN model by comparing with convolutional autoencoder and deep neural network for crop classification on hyperspectral imagery. Geocarto International 1–15Bochkovskiy A, Wang CY, Liao HYM (2020) Yolov4: Optimal speed and accuracy of object detection. arXiv preprint [19] Chamorro Martinez JA, Cué La Rosa LE, Feitosa RQ et al (2021) Fully convolutional recurrent networks for multidate crop recognition from multitemporal image sequences. ISPRS J Photogramm Remote Sens 171:188–201 [20] Der Yang M, Tseng HH, Hsu YC, et al (2020) Real-time crop classification using edge computing and deep learning. In: 2020 IEEE 17th Annual Consumer Communications & Networking Conference (CCNC), IEEE, pp 1–4, Duong-Trung N, Quach LD, Nguyen MH, et al (2019) A combination of transfer learning and deep learning for medicinal plant classification. In: Proceedings of the 2019 4th international conference on intelligent information technology. Association for computing machinery, New York, NY, USA, ICIIT ’19, p 83-90, [21] Fawakherji M, Potena C, Bloisi DD, et al (2019) Uav image-based crop and weed distribution estimation on embedded GPU boards. In: International conference on computer analysis of images and patterns, Springer, pp 100–108, [22] RanganathanKrishnamoorthy; RanganathanThiagarajan; ShanmugamPadmapriya; Indiran Mohan; SundaramArun; ThangarajuDineshkumar, \"Applications of Machine Learning and Deep Learning in Smart Agriculture,\" in Machine Learning Algorithms for Signal and Image Processing, IEEE, 2023, pp.371-395, doi: 10.1002/9781119861850.ch21.doi = {10.35860/iarej.848458} [23] Cynthia, Shamse& Hossain, Kazi& Hasan, Md&Asaduzzaman, Md& Das, Amit. (2019). Automated Detection of Plant Diseases Using Image Processing and Faster R-CNN Algorithm. 1-5. 10.1109/STI47673.2019.9068092. [24] Bal, Fatih&Kayaalp, Fatih. (2023). A Novel Deep Learning-Based Hybrid Method for the Determination of Productivity of Agricultural Products: Apple Case Study. IEEE Access. PP. 1-1. 10.1109/ACCESS.2023.3238570. [25] Meshram, Vishal &Patil, Kailas. (2021). FruitNet: Indian fruits image dataset with quality for machine learning applications. Data in Brief. 40. 107686. 10.1016/j.dib.2021.107686. [26] Koklu, Murat &Ünler?en, Muhammed &Ozkan, Ilker Ali & Aslan, Muhammet&Sabanci, Kadir. (2022). A CNN-SVM Study based on selected deep features for grapevine leaves classification. Measurement. 188. 1-10. 10.1016/j.measurement.2021.110425. [27] Behera, Santi &Rath, Amiya &Mahapatra, Abhijeet&Sethy, Prabira. (2020). Identification, classification & grading of fruits using machine learning & computer intelligence: a review. Journal of Ambient Intelligence and Humanized Computing. 10.1007/s12652-020-01865-8.
Copyright
Copyright © 2024 G.S. Devi Lakshmi, K Kavitha, Abhinaya Premchand. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET61234
Publish Date : 2024-04-29
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online