

Ijraset Journal For Research in Applied Science and Engineering Technology
Traffic Sign Board Detection Using Single Shot Detection (SSD)
Authors: R. Krishna Paavani , V. Indraja, V. Neelimajyothi , S. Sai, Mr. M. Sriramulu
DOI Link: https://doi.org/10.22214/ijraset.2022.43336
Certificate: View Certificate
Abstract
Traffic sign board detection (TSBD) is a significant portion of intelligent transportation system (ITS). Being able to identify traffic signals more accurately and effectively can improve safe driving .Due to increase in technology there are autonomous vehicles . The traffic sign recognition process includes two parts: detection and classification. In this paper, we use an object detection algorithm called SSD to detect the traffic signs. This convolutional neural network uses multiple feature maps to detect objects. For the traffic sign is very small to the whole picture, the SSD model has been improved to have a better detection result of traffic signs. In the experiments, the model has been simplified and the size of the prior box has been modified. The improved network has a good detection effect on small targets. The results on the test data set show that the proposed algorithm performs well for single-target, multi-target and dark-light images. The precision and recall on the test data set are 91.09%, and 88.06%.
Introduction
I. INTRODUCTION
In highly populated areas we have different zones like school zones,hospital zones etc.There is a chance of frequenjt occurrence of accidents in these zones due to ignorance of the signboards All road signs are placed in specific areas to ensure the safety of all drivers. These markers let drivers know how fast to drive. They help to create order on the roadways and are employed to provide essential information to drivers. Traffic signs include many useful environmental information which can help drivers learn about the change of the road ahead and the driving requirements. They also tell drivers when and where to turn or not to turn. In order to be a terrific driver, you need to have an understanding of what the sign mean. Road signs are designed to make sure that every driver is kept safe.
Our system will able to detect, recognize and infer the road traffic signs would be a prodigious help to the driver. Traffic signboard detection is an important part of driver assistant systems. The basic idea of proposed system is to provide alertness to the driver about the presence of traffic signboard at a particular distance apart in order to ensure pedestrian safety.
The system provides the driver with real time information from road signs, which consist the most important and challenging tasks. In this base paper we provide alertness to the driver about the presence of traffic signboard at a particular distance apart. Next generate an acoustic warning to the driver in advance of any danger. This warning then allows the driver to take appropriate corrective decisions in order to mitigate or completely avoid the event. Image processing technology is mostly used for the identification of the signboards. The alertness to the driver is given as text output.
A. SINGLE-SHOT Detection Algorithm
This time, SSD (Single Shot detector) is reviewed. By using SSD, we only need to take one single shot to detect multiple objects within the image, while regional proposal network (RPN) based approaches such as R-CNN series that need two shots, one for generating region proposals, one for detecting the object of each proposal. Thus, SSD is much faster compared with two-shot RPN-based approaches. SSD algorithm works well in detecting large objects but is less accurate in detecting smaller objects. Hence, we modify the SSD algorithm to achieve acceptable accuracy for detecting smaller objects.
This model mainly consists of a base network followed by several multiscale feature map blocks. The base network is for extracting features from the input image, so it can use a deep CNN.SSD has two components and they are the Backbone Model and the SSD Head. Backbone Model is a pre-trained image classification network as a feature extractor. Usually, the fully connected classification layer is removed from the model. SSD Head is another set of convolutional layers added to this backbone and the outputs are interpreted as the bounding boxes and classes of objects in the spatial location of the final layer's activations.
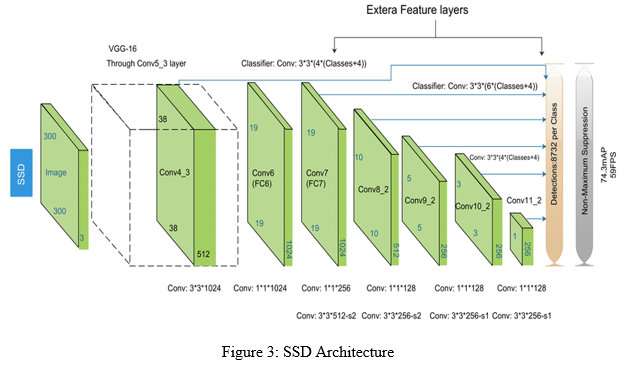
II. LITERATURE REVIEW
Deep CNN-based methods have become the leading method for high-quality general object detection, including vehicle detection. Single shot detection (SSD) defined a region proposal network (RPN) for generating region proposals and a network using these proposals to detect objects. And removes the background objects . RPN shares full-image convolutional features with the detection network, thus enabling nearly cost-free region proposals. SSD framework skips the region proposal stage and directly uses multiple feature maps with different resolutions to perform object localization and classification.
A. Dataset
- Tensorflow: TensorFlow is a Python library for fast numerical computing created and released by Google. It is a foundation library that can be used to create Deep Learning models directly or by using wrapper libraries that simplify the process built on top of TensorFlow. TensorFlow is the open-source library for a number of various tasks in machine learning. TensorFlow provides both high-level and low-level APIs TensorFlow is an open source library for fast numerical computing. Unlike other numerical libraries intended for use in Deep Learning. TensorFlow was designed for use both in research and development and in production systems. It can run on single CPU systems, GPUs as well as mobile devices and large scale distributed systems of hundreds of machines. It is an open source artificial intelligence library, using data flow graphs to build models. It allows developers to create large-scale neural networks with many layers. TensorFlow is mainly used for Classification, Perception, Understanding, Discovering, Prediction and Creation.
B. Proposed System
SSD is designed for object detection in real-time. Faster R-CNN uses a region proposal network to create boundary boxes and utilizes those boxes to classify objects. While it is considered the start-of-the-art in accuracy, the whole process runs at 7 frames per second. Far below what real-time processing needs. SSD speeds up the process by eliminating the need for the region proposal network. To recover the drop in accuracy, SSD applies a few improvements including multi-scale features and default boxes. These improvements allow SSD to match the Faster R-CNN’s accuracy using lower resolution images, which further pushes the speed higher. According to the following comparison, it achieves the real-time processing speed and even beats the accuracy of the Faster R-CNN. (Accuracy is measured as the mean average precision mAP: the precision of the predictions.)
The SSD object detection composes of 2 parts:
- Extract feature maps, and
- Apply convolution filters to detect objects.
C. Performance Evaluation
- Runs a convolutional network on input images at just one time and computes a feature map.
- Takes 50 to 59 fps (frames per second).
- Robust and high performance.
- Reduce cost in terms of memory.
- It’s also detects the objects in dark.
- Results in text format.
- Lowest test time latency
Conclusion
In this project, the SSD object detection algorithm based on feature fusion was proposed. By constructing a feature fusion architecture, the object detection performance of the algorithm is effectively improved, and especially for the detection effect of small-scale objects. First, a framework for efficiently integrating image texture features and global feature depth models is designed. Then, the feature information extracted from each layer of the structure is transformed to the detector of the network, and further mining the semantic information of network features. Finally, using the dataset, experiments are made for testing and verifying the performance of the proposed algorithm. The experimental results show that the mAP of the proposed SSD object detection algorithm based on feature fusion is 78.0%, which is both higher than that of the SSD and Faster RCNN algorithms, and further verifies the advancement and effectiveness of the algorithm. And the future work will optimize the network parameters, increase the number of training samples, and improve the robustness and adaptability of the model to achieve better detection performance
References
[1] YOLO et al introduces improvements of batch normalization, high-resolution classifier, convolutional with anchor boxes, and dimension clusters compared to original YOLO. Comparing to YOLO, YOLOv2 achieves higher accuracy. A fast and simple approach to detecting real time images was introduced in this paper as You Only Look Once.2007 [2] Chu et al proposed a vehicle detection scheme based on multitask deep CNN in which learning is trained on four tasks.2004 [3] Zhang et al detection of specific instances versus the detection of broad categories. The first type aims to detect instances of a particular object (such as Donald Trump’s face, the Eiffel Tower, or a neighbor’s dog), essentially a matching problem.2013 [4] Krizhevsky et al proposed a Deep Convolutional Neural Network (DCNN) called Alex Net which achieved record breaking image classification accuracy in the Large Scale Visual Recognition Challenge (ILSVRC).2012 [5] Girshicket et al Breakthrough image classification results obtained by CNNs and the success of the selective search in region proposal for handcrafted features.2014 [6] He et al Mask RCNN to tackle pixelwise object instance segmentation by extending Faster RCNN.A RoIAlign layer was proposed to preserve the pixel level spatial correspondence.2017 [7] Li et al proposed a multivehicle detection method which consists of YOLO under the Dark net framework. To make the full use of the advantages of the depth information of lidar and the obstacle classification ability of vision.2008 [8] Szegedy etalwere among the first to explore CNNs for object detection. DetectorNet formulated object detection a regression problem to object bounding box masks.2013
Copyright
Copyright © 2022 R. Krishna Paavani , V. Indraja, V. Neelimajyothi , S. Sai, Mr. M. Sriramulu . This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET43336
Publish Date : 2022-05-26
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online